- [源码解析] TensorFlow 分布式环境(1) --- 总体架构
- 1. 总体架构
- 1.1 集群角度
- 1.1.1 概念
- 1.1.2 示意图
- 1.1.3 创建
- 1.1.3.1 创建集群
- 1.1.3.2 创建任务
- 1.1.3.3 指定设备
- 1.2 分布式角度
- 1.2.1 概念
- 1.2.2 示意图
- 1.3 系统角度
- 1.3.1 概念
- 1.3.2 示意图
- 1.4 图操作角度
- 1.5 通信角度
- 1.1 集群角度
- 2. Server
- 2.1 接口
- 2.2 Python 定义
- 2.3 ServerInterface
- 2.4 GrpcServer
- 2.4.1 定义
- 2.4.2 初始化
- 2.4.3 Env
- 2.5 启动
- 2.6 等待终止服务
- 0xFF 参考
- 1. 总体架构
在具体介绍 TensorFlow 分布式的各种 Strategy 之前,我们首先需要看看分布式的基础:分布式环境。只有把基础打扎实了,才能在以后的分析工作之中最大程度的扫清障碍,事半功倍。
本文代码使用的部分 API 不是最新,但因为我们的目的是了解其设计思想,旧的 API 反而会更加清晰(目前业界很多公司也依然基于较低版本的 TensroFlow,所以旧 API 也有相当的分析意义)。
这里强烈推荐两个大神:
-
[TensorFlow Internals] (https://github.com/horance-liu/tensorflow-internals),虽然其分析的不是最新代码,但是建议对 TF 内部实现机制有兴趣的朋友都去阅读一下,绝对大有收获。
-
https://home.cnblogs.com/u/deep-learning-stacks/ 西门宇少,不仅仅是 TensorFlow,其公共号还有更多其他领域,业界前沿。
本系列其他文章是:
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
1. 总体架构我们从几个不同角度来对分布式模式进行拆分,如何划分不是绝对的,这些角度也不是正交的,可能会彼此有部分包含,这么划分只是笔者觉得更容易从这些方面理解。
1.1 集群角度 1.1.1 概念我们首先从集群和业务逻辑角度来拆分如下,有术语如下:
-
Cluster:TensorFlow 集群定义。
- 一个 TensorFlow 集群包含一个或者多个 TensorFlow 服务端,一个集群一般会专注于一个相对高层的目标,比如用多台机器并行地训练一个神经网络。
- 训练被切分为一系列 job,每个 job又会负责一系列 tasks。当集群有多个 task 时候,需要使用tf.train.ClusterSpec 来指定每一个任务的机器。
-
Job:一个 job 包含一系列致力于完成某个相同目标的 task,一个 job 中的 tasks 通常会运行在不同的机器中。一般存在两种 job:
- ps job:ps 是 parameter server 的缩写,其负责处理存储/更新变量相关的工作。
- worker job:用于承载那些计算密集型的无状态节点,负责数据计算。
-
Task:一个 Task 会完成一个具体任务,一般会关联到某个 TensorFlow 服务端的处理过程。
- Task 属于一个特定的 job 并且在该 job 的任务列表中有唯一的索引 task_index。
- Task 通常与一个具体的 tf.train.Server 相关联,运行在独立的进程中。
- 可以在一个机器上运行一个或者多个 Task,比如单机多 GPU。
我们给出以上三者的关系如下,Cluster 包含多个 Job,Job 包括 1 到多个 Task:
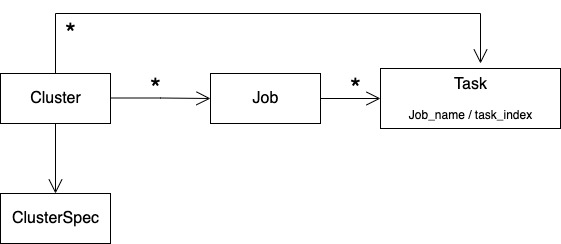
图 1 角色之间关系
对于 Job 两种角色,我们给出一幅经典的参数服务器示意图如下,下图上方就是运行的 ps 集群,中间运行了四个 worker。
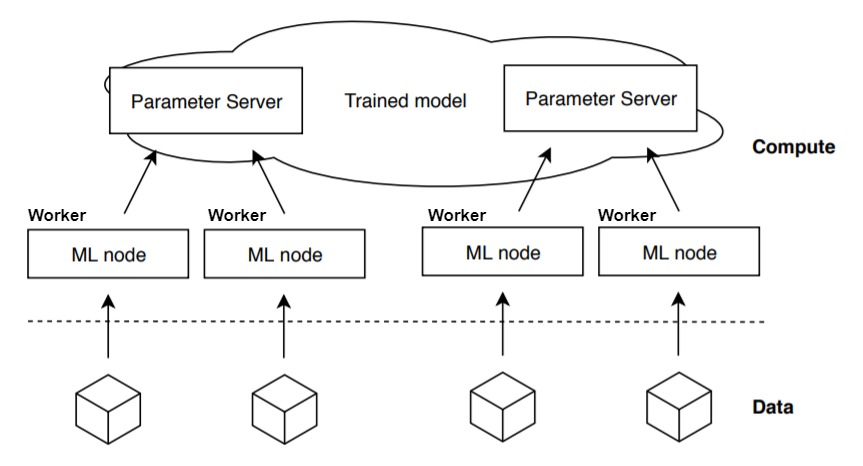
图 2 参数服务器.
来源:"A Survey on Distributed Machine Learning"
1.1.3 创建我们看看用低阶 API 如何实现分布式训练。
1.1.3.1 创建集群我们首先创建集群,集群包括两种角色,参数服务器 ps job 有三个任务(task),worker job 有两个 task。这里每一个 task 是一个机器,也可以在同一个机器之上运行多个 task(比如每个 task 控制不同的 GPU 设备)。
ClusterSpec 以 Job 的方式组织,指定了集群中 Task 如何部署,因为一个 Task 对应了一个进程,所以ClusterSpec 也描述了 TensorFlow 分布式运行时之中进程如何分布。
ps_hosts = ["1.1.1.1:11", "2.2.2.2:22"]
worker_hosts = ["3.3.3.3:33", "4.4.4.4:44", "5.5.5.5:55"]
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
接下来启动若干任务,用户脚本需要在每一个机器上都运行,一共运行 5 次(3 个 ps,2 个 worker)。每个任务之中,都需要使用同一个 tf.train.ClusterSpec 来了解集群之中所有的任务。然后会启动一个 tf.distribution.Server服务。
一个 tf.distribution.Server 实例封装了一组设备和一个 tf.compat.v1.Session 目标,可以参与分布式训练。一个服务属于一个集群(由 tf.train.ClusterSpec 指定),并对应于一个指定作业中的特定任务。该服务可以与同一集群中的任何其他服务通信。
FLAGS = tf.app.flags.FLAGS
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
因为已经启动了 Server,所以每个任务或者说节点的具体执行逻辑就不同了。代码之中根据脚本执行的命令参数不同来决定这个Server执行的是哪个任务。
- 如果 FLAGS.job_name == "ps",程序就执行 join 操作,因为参数服务器是参数更新的服务,只需要等待其他 worker 节点提交更新的参数即可。
- 如果 FLAGS.job_name == "worker",就执行后续的计算任务。TensorFlow 中计算/参数都可以分离,可以在设备上分配计算节点,也可以在每个设备上分配参数。在分布式环境下,依然会使用tf.device()函数将节点/操作放在当前任务下。tf.train.replica_device_setter 函数会依据 job 名,自动将计算分配到 worker 上。
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
我们接下来从分布式业务逻辑/架构角度来具体分析一下。大家知道,Master-Worker 架构是分布式系统之中非常常见的一种架构组织形式,比如:GFS 之中有 Master,ChunkServer,Spanner 有 Zonemaster 和 Spanserver,Spark 有 driver和executor,Flink 有 JobManager 和 TaskManager。此架构下,Master 通常维护集群元信息,调度任务,Workers 则负责具体计算或者维护具体数据分片。
其实,TensorFlow 分布式也是采用了 Master-Worker 架构,为了更好的说明,我们给出一个官方的分布式 TensorFlow 的架构图,图上三个角色都是从逻辑视角来看。
- Client:前面的各种概念术语都是为了搭建一个分布式环境,Client 利用这个分布式环境进行计算。一个 client通常是一段构造 TensorFlow 计算图的程序,通常情况下,客户端通过循环调用 RPC 来让 master 进行迭代计算(例如训练)。
- Master:收到执行计算图的命令之后,Master 负责协调调度,比如对计算图进行剪枝,优化, 把计算图拆分成多个子图,每个子图分配注册给不同的 worker,触发各个 worker 并发执行子图。
- Worker:负责具体计算其收到的子图。当接收到注册子图消息之后,Worker 会将计算子图依据本地计算设备进行二次切分,并把二次切分之后的子图分配到各个设备上,然后启动计算设备并发执行子图。Worker 之间可能通过进程间通信完成数据交换。图中有两个 worker,下方的 worker 的具体 Job 角色是参数服务器,负责维护参数/更新参数等等,上面的 worker 会把梯度发给参数服务器进行参数更新。
图上的集群包括三个节点,每个节点上都运行一个 TensorFlow Server。这里 Master,Worker 每一个都是 TensorFlow Server。
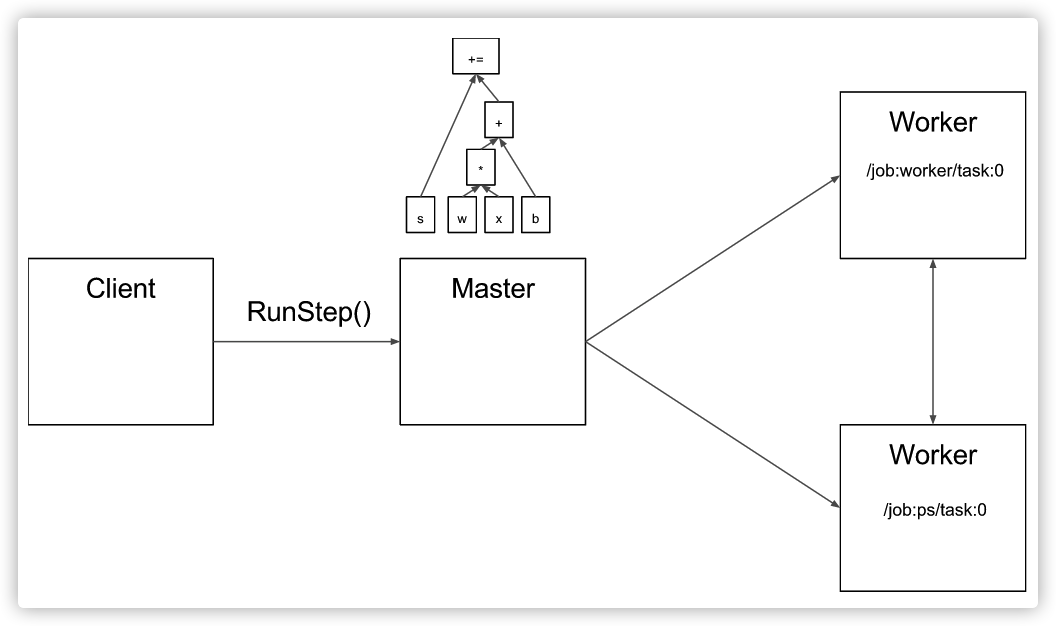
图 3 集群,来自 TensorFlow
1.3 系统角度 1.3.1 概念我们接下来从具体软件实现角度来剖析,在具体实现上可以分解为如下概念:
-
TensorFlow Server :Server 是运行 tf.train.Server 实例的进程,是一个集群中的一员,Server 通常包括 Master Service 与一个 Worker Service。Server 可以和集群中的其他 Server 进行通信。
-
Master Service :一个 GRPC service,用于同一系列远端的分布式设备进行交互,用来协调调度多个 worker service。
- Master Service 对应了 "//tensorflow/core/protobuf/master_service.proto",其内部有 CreateSession,RunStep 等接口,所有的 TensorFlow Server 都实现了 Master Service。
- 客户端可以与 Master Service 交互以执行分布式 TensorFlow 计算。客户端一般通过 RPC 形式与一个 Master 之间保持交互式计算,客户端建立一个客户端会话,连接到某一个 master,该 master 创建一个 master session。
- 一个 Master Service 会包含多个 "主会话(master sessions)"并且维护其状态。每个会话封装了一个计算图及其相关的状态,这些 master session 通常对应于同一个 "客户会话(client session)"(例如一个 tensorflow::Session实例)。
-
Master Session:一个主会话(master session)负责以下工作。
- 起到桥梁的作用,建立 client 与后端运行时的通道,比如可以将 Protobuf 格式的 GraphDef 发送至分布式 Master。
- 使用布局(placement)算法将每个节点分配到一个设备(本地或远程)。放置算法可能会根据从系统中的 worker 收集到的统计数据(例如,内存使用、带宽消耗等)做出决定。
- 为了支持跨设备和跨进程的数据流和资源管理,session 会在计算图之中插入中间节点和边。
- 向 worker 发出命令,让其执行与本 worker 相关的子图。
-
Worker Session: worker 通过 Worker Session 来标识一个执行序列(注册计算图,执行命令),Worker Session 属于一个 Master Session。
-
Worker service:这是一个 GRPC service,代表 MasterService 在一组本地设备上执行数据流计算图。一个 worker service 会保持/跟踪客户计算图的多个子图,这些子图对应了应该在这个 worker 上执行的节点,也包括那些进程间通信所需的任何额外节点。Worker service 对应 worker_service.proto。所有的 TensorFlow server 也都实现了 worker service。
我们现在知道,每个 Server 之上都会运行 MasterService 和 WorkerService 两个服务,这意味着 server 可能同时扮演 Master 和 Worker 两个角色,比如回到上图,图上的集群包括三个节点,每个节点上都运行一个 TensorFlow Server。这里 Master,Worker 每一个都是 TensorFlow Server,每个 server 之上都有两种 service(MasterService 和 WorkerService),只不过在这个系统之中,目前实际有角色意义的分别是 MasterService(Master之上的) 和 WorkerService(两个 worker 之上的),图之中用下划线表示。

图 4 服务
我们接着看一些其他可能。
- 如果 Client 接入到了集群之中的一个 Server A,则此 Server A 就扮演了 Master 角色,集群其他 Server 则就是 Worker,但是 Server A 同时也可以扮演 Worker 角色。
- Client 可以和 Master 位于同一个进程之内,此时 Client 和 Master 可以直接使用函数调用来交互,避免 RPC 开销。
- Master 可以和 Worker 位于同一个进程之内,此时 两者可以直接使用函数调用来交互,避免 RPC 开销。
- 可以有多个 Client 同时接入到一个集群,比如下图,此时集群之中有两个 Server 都可以扮演 Master/Worker 角色,两个 Server 扮演 Worker 角色:

图 5 多个Client 接入
1.4 图操作角度分布式运行的核心也是如何操作计算图,但是计算功能被拆分为 Client,Master 和 Worker 三个角色。Client 负责构造计算图,Worker 负责执行具体计算,但是 Worker 如何知道应该计算什么?TensorFlow 在两者之间插入了一个 Master 角色来负责协调,调度。
在分布式模式下,对于计算图会进行分裂,执行操作。
- 从分裂角度看,TF 对于计算图执行了二级分裂操作:
- MasterSession 生成 ClientGraph,然后通过 SplitByWorker 完成了一级分裂,得到多个 PartitionGraph,再把 PartitionGraph 列表注册到 Worker 们之上。
- WorkerSession 通过 SplitByDevice 把自己得到的计算图进行二级分裂,把分裂之后的 PartitionGraph 分配给每个设备。
- 从执行角度来看,计算图的具体执行只发生在 Worker 之上。
- Master 启动各个 Worker 并发执行 PartitionGraph 列表。
- Worker 在每个设备上启动 Executor,执行 PartitionGraph。
因为执行是按照切分来的,所以我们这里只演示切分如下:

图 6 切分计算图
1.5 通信角度最后,我们从通信角度来对分布式模式进行分析。TF 的消息传输的通信组件叫做 Rendezvous,这是一个从生产者向消费者传递张量的抽象,一个 rendezvous 是一个通道(channels)的表(table)。生产者调用 Send() 方法,在一个命名的通道上发送一个张量。消费者调用 Recv() 方法,从一个指定的通道接收一个张量。
在分布式模式之中,对跨设备的边会进行分裂,在边的发送端和接收端会分别插入 Send 节点和 Recv 节点。
- 进程内的 Send 和 Recv 节点通过 IntraProcessRendezvous 实现数据交换。
- 进程间的 Send 和 Recv 节点通过 GrpcRemoteRendezvous 实现数据交换。
比如下图,左面是原始计算图,右面是分裂之后的计算图,5 个节点被分配到两个 worker 之上。
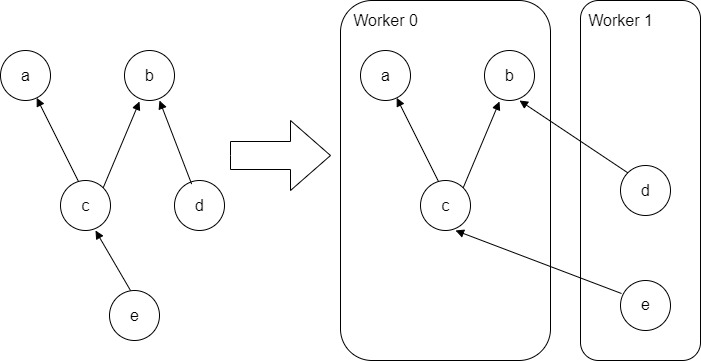
图 7 分裂计算图
我们假设 Worker 0 有两个 GPU,当插入Send 节点和 Recv 节点,效果如下,其中 Worker 1 发送给 Worker 之间的代表进程间通过 GrpcRemoteRendezvous 实现数据交换,Worker 0 内部两个 GPU 之间的虚线箭头代表进程内部通过 IntraProcessRendezvous 实现数据交换。

图 8 通信角度
我们接下来就看看 Server 的总体概况。
2. Server 2.1 接口Server 的接口位于 tensorflow/core/protobuf/tensorflow_server.proto,具体如下:
// Defines the configuration of a single TensorFlow server.
message ServerDef {
// The cluster of which this server is a member.
ClusterDef cluster = 1;
// The name of the job of which this server is a member.
//
// NOTE(mrry): The cluster field must contain a JobDef with a name field
// that matches this name.
string job_name = 2;
// The task index of this server in its job.
//
// NOTE: The cluster field must contain a JobDef with a matching name
// and a mapping in its tasks field for this index.
int32 task_index = 3;
// The default configuration for sessions that run on this server.
ConfigProto default_session_config = 4;
// The protocol to be used by this server.
//
// Acceptable values include: "grpc", "grpc+verbs".
string protocol = 5;
// The server port. If not set, then we identify the port from the job_name.
int32 port = 6;
// Device filters for remote tasks in the cluster.
// NOTE: This is an experimental feature and only effective in TensorFlow 2.x.
ClusterDeviceFilters cluster_device_filters = 7;
}
可以从多个角度来看Server。
- 首先,Server 是一个集群中的一员,负责管理其本地设备集。
- 其次,Server 是基于 gRPC 的服务器,Server 可以和集群中的其他 Server 进行通信。
- 第三,Server是运行 tf.train.Server 实例的进程,tf.train.Server 内部通常包括 Master Service与一个Worker Service,这两个对外的接口就是 Master 和 Worker 这两种"服务"。Server 同时可以扮演这两种角色。
- 第四,Server 的实现是 GrpcServer。
- GrpcServer 内部有一个成员变量 grpc::Server server_ ,这是 GPRC 通信 server,server_ 会监听消息,并且把命令发送到内部两个服务 MasterService 和 WorkerService 之中对应的那个。该服务会通过回调函数进行业务处理。
- 当其是 Master 角色时候,对外服务是 MasterService,MasterService 为每一个接入的 Client 启动一个 MasterSession,MasterSession 被一个全局唯一的 session_handle 表示,此 session_handle 会传递给 Client。Master 可以为多个 Client 服务,一个 Client 只能和一个 Master 打交道。
- 当其是 Worker 角色时候,可以为多个 Master 提供服务,其对外服务是 WorkerService,WorkerService 为每个接入的 MasterSession 生成一个 WorkerSession 实例,MasterSession 可以让 WorkerSession 注册计算图,执行命令。
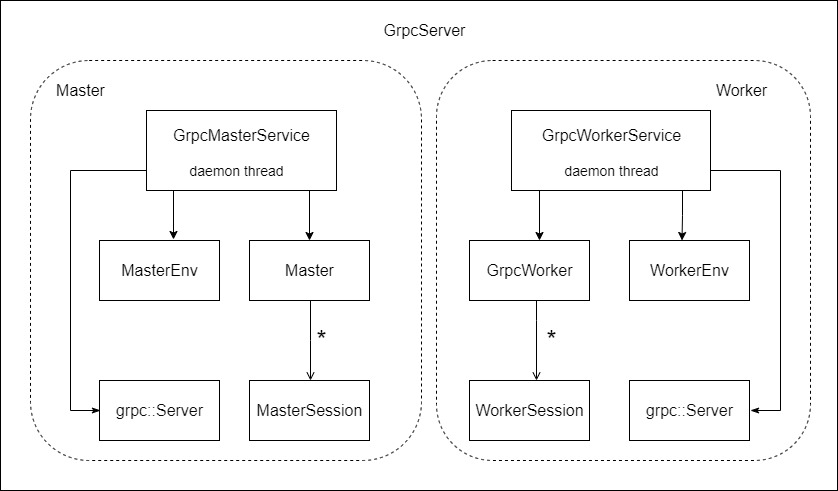
图 9 GrpcServer 结构
具体Python接口定义在 tensorflow/python/training/server_lib.py 之中。
@tf_export("distribute.Server", v1=["distribute.Server", "train.Server"])
@deprecation.deprecated_endpoints("train.Server")
class Server(object):
"""An in-process TensorFlow server, for use in distributed training.
A tf.distribute.Server instance encapsulates a set of devices and a
tf.compat.v1.Session target that
can participate in distributed training. A server belongs to a
cluster (specified by a tf.train.ClusterSpec), and
corresponds to a particular task in a named job. The server can
communicate with any other server in the same cluster.
"""
def __init__(self,
server_or_cluster_def,
job_name=None,
task_index=None,
protocol=None,
config=None,
start=True):
"""Creates a new server with the given definition.
The job_name, task_index, and protocol arguments are optional, and
override any information provided in server_or_cluster_def.
Args:
server_or_cluster_def: A tf.train.ServerDef or tf.train.ClusterDef
protocol buffer, or a tf.train.ClusterSpec object, describing the
server to be created and/or the cluster of which it is a member.
job_name: (Optional.) Specifies the name of the job of which the server is
a member. Defaults to the value in server_or_cluster_def, if
specified.
task_index: (Optional.) Specifies the task index of the server in its job.
Defaults to the value in server_or_cluster_def, if specified.
Otherwise defaults to 0 if the server's job has only one task.
protocol: (Optional.) Specifies the protocol to be used by the server.
Acceptable values include "grpc", "grpc+verbs". Defaults to the value
in server_or_cluster_def, if specified. Otherwise defaults to
"grpc".
config: (Options.) A tf.compat.v1.ConfigProto that specifies default
configuration options for all sessions that run on this server.
start: (Optional.) Boolean, indicating whether to start the server after
creating it. Defaults to True.
Raises:
tf.errors.OpError: Or one of its subclasses if an error occurs while
creating the TensorFlow server.
"""
self._server_def = _make_server_def(server_or_cluster_def, job_name,
task_index, protocol, config)
self._server = c_api.TF_NewServer(self._server_def.SerializeToString())
if start:
self.start()
TF_NewServer 方法就进入到了C++世界,其调用 tensorflow::NewServer 建立了C++ 世界的Server。
TF_Server* TF_NewServer(const void* proto, size_t proto_len,
TF_Status* status) {
#if defined(IS_MOBILE_PLATFORM) || defined(IS_SLIM_BUILD)
status->status = tensorflow::errors::Unimplemented(
"Server functionality is not supported on mobile");
return nullptr;
#else
tensorflow::ServerDef server_def;
if (!server_def.ParseFromArray(proto, static_cast<int>(proto_len))) {
status->status = InvalidArgument(
"Could not parse provided bytes into a ServerDef protocol buffer");
return nullptr;
}
std::unique_ptr<tensorflow::ServerInterface> out_server;
status->status = tensorflow::NewServer(server_def, &out_server);
if (!status->status.ok()) return nullptr;
return new TF_Server(std::move(out_server));
#endif // defined(IS_MOBILE_PLATFORM) || defined(IS_SLIM_BUILD)
}
然后会通过如下代码选择建立何种Server。
// Creates a server based on the given server_def, and stores it in
// *out_server. Returns OK on success, otherwise returns an error.
Status NewServer(const ServerDef& server_def,
std::unique_ptr<ServerInterface>* out_server) {
ServerFactory* factory;
TF_RETURN_IF_ERROR(ServerFactory::GetFactory(server_def, &factory));
return factory->NewServer(server_def, ServerFactory::Options(), out_server);
}
而 GrpcServer 则早就注册到系统之中,GrpcServerFactory 是工厂类,如果 protocol 是"grpc",则生成 GrpcServer。
class GrpcServerFactory : public ServerFactory {
public:
bool AcceptsOptions(const ServerDef& server_def) override {
return server_def.protocol() == "grpc";
}
Status NewServer(const ServerDef& server_def, const Options& options,
std::unique_ptr<ServerInterface>* out_server) override {
return GrpcServer::Create(server_def, Env::Default(),
options.local_device_mgr, out_server);
}
};
因此,我们接下来就看看GrpcServer。
2.3 ServerInterfaceServerInterface 是基础接口,其代表一个输出Master和Worker服务的 TensorFlow Sever。定义在tensorflow/core/distributed_runtime/server_lib.h 之中。 这个库会基于注册/工厂的机制来创建 TensorFlow 服务器对象。每个服务器的实现都必须有一个配套的 ServerFactory,并创建一个静态的 "registrar"对象,用工厂类的一个实例调用 ServerFactory::Register()。具体如下:
class ServerInterface {
public:
ServerInterface() {}
virtual ~ServerInterface() {}
// Starts the server running asynchronously. Returns OK on success, otherwise
// returns an error.
virtual Status Start() = 0;
// Stops the server asynchronously. Returns OK on success, otherwise returns
// an error.
//
// After calling Stop(), the caller may call Join() to block until the
// server has stopped.
virtual Status Stop() = 0;
// Blocks until the server has stopped. Returns OK on success, otherwise
// returns an error.
virtual Status Join() = 0;
// Returns a target string that can be used to connect to this server using
// tensorflow::NewSession().
virtual const string target() const = 0;
virtual WorkerEnv* worker_env() = 0;
virtual MasterEnv* master_env() = 0;
// Update the set of workers that can be reached by the server
virtual Status UpdateServerDef(const ServerDef& server_def) = 0;
// Functions to operate on service-specific properties.
//
// Add master eager context to local eager service in order to handle enqueue
// requests from remote workers.
virtual Status AddMasterEagerContextToEagerService(
const tensorflow::uint64 context_id, EagerContext* context) = 0;
// Set coordination service agent instance to coordination service RPC handler
virtual Status SetCoordinationServiceAgentInstance(
CoordinationServiceAgent* agent) = 0;
private:
TF_DISALLOW_COPY_AND_ASSIGN(ServerInterface);
};
工厂类定义如下:
class ServerFactory {
public:
struct Options {
// Local DeviceMgr to use.
tensorflow::DeviceMgr* local_device_mgr;
};
// Creates a new server based on the given server_def, and stores
// it in *out_server. Returns OK on success, otherwise returns an
// error.
virtual Status NewServer(const ServerDef& server_def, const Options& options,
std::unique_ptr<ServerInterface>* out_server) = 0;
// Returns true if and only if this factory can create a server
// based on the given server_def.
virtual bool AcceptsOptions(const ServerDef& server_def) = 0;
virtual ~ServerFactory() {}
// For each ServerFactory subclass, an instance of that class must
// be registered by calling this method.
//
// The server_type must be unique to the server factory.
static void Register(const string& server_type, ServerFactory* factory);
// Looks up a factory that can create a server based on the given
// server_def, and stores it in *out_factory. Returns OK on
// success, otherwise returns an error.
static Status GetFactory(const ServerDef& server_def,
ServerFactory** out_factory);
};
GrpcServer 是管理当前进程中的 Master 和 Worker 服务的结构,通过 Start()、Stop()、Join() 构成了下面注释之中的状态机,
- New 状态上启动了 grpc::Server,但是没有对外提供服务。
- Started 状态上启动 MasterService 和 WorkerService 两个对外的 RPC 服务。
- Stopped 状态下停止 MasterService 和 WorkerService 两个服务。
// Represents the current state of the server, which changes as follows:
//
// Join() Join()
// ___ ___
// Start() \ / Stop() \ /
// NEW ---------> STARTED --------> STOPPED
// \ /
// \________________________/
// Stop(), Join()
其主要成员变量是:
- MasterEnv master_env_ : 是 Master 工作所使用的环境,环境之中不拥有这些实际指针;
- worker_env_ : WorkerEnv 类型,是worker工作所使用的环境;
- master_impl_ :具体执行业务操作的 Master 类;
- worker_impl_ :具体执行业务操作的 GrpcWorker;
- master_service_ :GrpcMasterService 实例;
- worker_service_ : GrpcWorkerService 实例;
- master_thread_ : MasterService 用来 RPC polling 的线程;
- worker_thread_ : WorkerService 用来 RPC polling 的线程;
- std::unique_ptr<::grpc::Server> server_ :GPRC 通信 server;
具体来说,就是启动了若干个线程,分别执行了 GrpcMasterService,GrpcWorkerService,GrpcEagerServiceImpl。
class GrpcServer : public ServerInterface {
private:
Env* env_;
// The port to which this server is bound.
int bound_port_ = 0;
// The host name of this server
string host_name_;
// Guards server configuration, server, and state.
mutex mu_;
enum State { NEW, STARTED, STOPPED };
State state_ TF_GUARDED_BY(mu_);
// Implementation of a TensorFlow master, and RPC polling thread.
MasterEnv master_env_;
std::unique_ptr<Master> master_impl_;
AsyncServiceInterface* master_service_ = nullptr;
std::unique_ptr<Thread> master_thread_ TF_GUARDED_BY(mu_);
std::map<std::string, AsyncServiceInterface*> extra_services_;
std::vector<std::unique_ptr<Thread>> extra_service_threads_
TF_GUARDED_BY(mu_);
// Implementation of a TensorFlow worker, and RPC polling thread.
WorkerEnv worker_env_;
std::unique_ptr<const DeviceMgr> owned_device_manager_;
std::unique_ptr<GrpcWorker> worker_impl_;
AsyncServiceInterface* worker_service_ = nullptr;
std::unique_ptr<Thread> worker_thread_ TF_GUARDED_BY(mu_);
std::unique_ptr<GrpcWorkerEnv> grpc_worker_env_;
// TensorFlow Eager implementation, and RPC polling thread.
AsyncServiceInterface* eager_service_ = nullptr;
std::unique_ptr<Thread> eager_thread_ TF_GUARDED_BY(mu_);
std::shared_ptr<WorkerSession> worker_session_;
// TensorFlow profiler service implementation.
std::unique_ptr<grpc::ProfilerService::Service> profiler_service_ = nullptr;
// The overall server configuration.
ServerDef server_def_ TF_GUARDED_BY(mu_);
std::unique_ptr<::grpc::Server> server_ TF_GUARDED_BY(mu_);
};
初始化逻辑大致如下:
-
获取各种相关配置,初始化 MasterEnv 和 WorkerEnv;
-
建立Device Manager;
-
构建device列表;
-
创建 RpcRendezvousMgr;
-
建立server必要设置;
-
创建 Master 以及对应的 GrpcMasterService,GrpcMasterService 是对外提供服务的实体,消息到达时候会调用这里的消息处理函数。具体业务则由 Master 提供。
-
创建 GrpcWorker 以及对应的 GrpcWorkerService,GrpcWorkerService是对外提供服务的实体,消息到达时候会调用这里的消息处理函数。具体业务则由 GrpcWorker 提供。
-
调用 builder.BuildAndStart 启动GRPC 通信服务器 grpc::Server,当启动之后,GrpcServer 依然是 New 状态,没有提供对外服务,需要状态机转换到 Started 状态才会对外提供服务;
-
建立grpc 需要的environment;
-
创建 WorkerCache;
-
创建一个 SessionMgr,并随后会在这个 SessionMgr 中创建 WorkerSession;
-
设置 MasterSession 的Factory,如果需要时候就会调用创建MasterSession,因为有的任务比如ps是不需要MasterSession的;
-
注册 LocalMaster;
Status GrpcServer::Init(const GrpcServerOptions& opts) {
mutex_lock l(mu_);
master_env_.env = env_;
worker_env_.env = env_;
// Check parameters before DeviceFactory::AddDevices,
// otherwise if 'task_index=-1' the program will abort.
int requested_port;
TF_RETURN_IF_ERROR(GetHostAndPort(server_def_, &host_name_, &requested_port));
SessionOptions sess_opts;
ConfigProto config = server_def_.default_session_config();
sess_opts.config = config;
// Configure shared devices between master and worker.
string name_prefix =
strings::StrCat("/job:", server_def_.job_name(), "/replica:0",
"/task:", server_def_.task_index());
// 建立Device Manager
if (opts.local_device_mgr == nullptr) {
std::vector<std::unique_ptr<Device>> devices;
TF_RETURN_IF_ERROR(
DeviceFactory::AddDevices(sess_opts, name_prefix, &devices));
worker_env_.device_mgr = new DynamicDeviceMgr(std::move(devices));
owned_device_manager_.reset(worker_env_.device_mgr);
} else {
worker_env_.device_mgr = opts.local_device_mgr;
owned_device_manager_.reset(nullptr);
}
// 构建device列表
worker_env_.local_devices = worker_env_.device_mgr->ListDevices();
master_env_.local_devices = worker_env_.device_mgr->ListDevices();
// 创建了 RpcRendezvousMgr
worker_env_.rendezvous_mgr = opts.rendezvous_mgr_func == nullptr
? new RpcRendezvousMgr(&worker_env_)
: opts.rendezvous_mgr_func(&worker_env_);
string unused;
string default_worker_name;
if (!DeviceNameUtils::SplitDeviceName(master_env_.local_devices[0]->name(),
&default_worker_name, &unused)) {
return errors::Internal("Could not parse worker name.");
}
// 建立server必要设置
::grpc::ServerBuilder builder;
builder.AddListeningPort(strings::StrCat("0.0.0.0:", requested_port),
GetServerCredentials(server_def_), &bound_port_);
builder.SetMaxMessageSize(std::numeric_limits<int32>::max());
bool reuse_port = false;
const Status status =
ReadBoolFromEnvVar("TF_GRPC_REUSE_PORT", false, &reuse_port);
auto server_build_option =
reuse_port
? std::unique_ptr<::grpc::ServerBuilderOption>(new ReusePortOption)
: std::unique_ptr<::grpc::ServerBuilderOption>(new NoReusePortOption);
builder.SetOption(std::move(server_build_option));
// Allow subclasses to specify more args to pass to the gRPC server.
// 创建 Master 以及对应的 GrpcMasterService
MaybeMutateBuilder(&builder, requested_port);
master_impl_ = CreateMaster(&master_env_);
master_service_ = NewGrpcMasterService(master_impl_.get(), config, &builder);
// 创建 GrpcWorker 以及对应的 GrpcWorkerService
worker_impl_ = opts.worker_func ? opts.worker_func(&worker_env_, config)
: NewGrpcWorker(&worker_env_, config);
worker_service_ = NewGrpcWorkerService(worker_impl_.get(), &builder,
opts.worker_service_options)
.release();
eager_service_ = new eager::GrpcEagerServiceImpl(&worker_env_, &builder);
profiler_service_ = profiler::CreateProfilerService();
builder.RegisterService(profiler_service_.get());
// Add any extra services to be started.
extra_services_ = ExtraServices(&builder);
// extra service:
if (opts.service_func != nullptr) {
opts.service_func(&worker_env_, &builder);
}
// 启动 GRPC 通信 server
server_ = builder.BuildAndStart();
// Create the execution environment for the GRPC workers cache.
// 建立grpc 需要的environment
grpc_worker_env_.reset(CreateGrpcWorkerEnv());
// 创建 WorkerCache
WorkerCacheInterface* worker_cache;
WorkerCacheFactoryOptions worker_cache_factory_options(server_def_);
TF_RETURN_IF_ERROR(
WorkerCacheFactory(worker_cache_factory_options, &worker_cache));
CHECK_NE(nullptr, worker_cache);
if (opts.collective_mgr_func) {
worker_env_.collective_executor_mgr.reset(
opts.collective_mgr_func(config, &worker_env_, worker_cache));
} else {
worker_env_.collective_executor_mgr = CreateProdRpcCollectiveExecutorMgr(
config, worker_env_.device_mgr, MaybeCreateNcclCommunicator(),
worker_cache, default_worker_name);
}
// Set up worker environment.
// 创建一个 SessionMgr,并随后会在这个 SessionMgr 中创建 WorkerSession
worker_env_.session_mgr = new SessionMgr(
&worker_env_, SessionMgr::WorkerNameFromServerDef(server_def_),
std::unique_ptr<WorkerCacheInterface>(worker_cache),
[this](const ServerDef& server_def, WorkerCacheInterface** worker_cache) {
WorkerCacheFactoryOptions options(server_def);
return WorkerCacheFactory(options, worker_cache);
});
worker_env_.compute_pool = ComputePool(sess_opts);
// Finish setting up master environment.
master_env_.ops = OpRegistry::Global();
master_env_.worker_cache = worker_cache;
master_env_.collective_executor_mgr =
worker_env_.collective_executor_mgr.get();
StatsPublisherFactory stats_factory = opts.stats_factory;
// 设置 MasterSession 的Factory,如果需要时候就会调用创建MasterSession,因为有的任务比如ps是不需要MasterSession的
master_env_.master_session_factory =
[config, stats_factory](
SessionOptions options, const MasterEnv* env,
std::unique_ptr<std::vector<std::unique_ptr<Device>>> remote_devs,
std::unique_ptr<WorkerCacheInterface> worker_cache,
std::unique_ptr<DeviceSet> device_set,
std::vector<string> filtered_worker_list) {
options.config.MergeFrom(config);
return new MasterSession(options, env, std::move(remote_devs),
std::move(worker_cache), std::move(device_set),
std::move(filtered_worker_list),
stats_factory);
};
master_env_.worker_cache_factory =
[this](const WorkerCacheFactoryOptions& options,
WorkerCacheInterface** worker_cache) {
return WorkerCacheFactory(options, worker_cache);
};
// Provide direct access to the master from in-process clients.
// 注册 LocalMaster
LocalMaster::Register(target(), master_impl_.get(),
config.operation_timeout_in_ms());
return Status::OK();
}
Master
Master 是具体提供业务的对象。上面代码之中,生成master的相关语句如下
master_impl_ = CreateMaster(&master_env_);
LocalMaster::Register(target(), master_impl_.get(),
config.operation_timeout_in_ms());
由以下代码可知,GrpcServer 生成的是 Master。
std::unique_ptr<Master> GrpcServer::CreateMaster(MasterEnv* master_env) {
return std::unique_ptr<Master>(new Master(master_env, 0.0));
}
由以下代码可知,Master在此时对应的target是"grpc://"。
const string GrpcServer::target() const {
return strings::StrCat("grpc://", host_name_, ":", bound_port_);
}
LocalMaster 会把Master注册到自己内部。
// Provide direct access to the master from in-process clients.
LocalMaster::Register(target(), master_impl_.get(),
config.operation_timeout_in_ms());
Worker
初始化代码之中,如下代码创建了worker,默认就是调用了 NewGrpcWorker 创建 GrpcWorker(具体提供业务的对象)。
worker_impl_ = opts.worker_func ? opts.worker_func(&worker_env_, config)
: NewGrpcWorker(&worker_env_, config);
WorkerEnv
WorkerEnv 把各种相关配置归总在一起,供 Worker 使用,可以认为是 Worker 运行上下文,WorkerEnv 与 Server 具有同样生命周期,在 Worker 运行时全程可见,其主要变量如下:
-
Env* env :跨平台 API 接口
-
SessionMgr* session_mgr :管理 WorkerSession 集合。
-
std::vector<Device*> local_devices :本地设备集。
-
DeviceMgr* device_mgr :管理本地设备集和远端设备集。
-
RendezvousMgrInterface* rendezvous_mgr :管理 Rendezvous 实例集。
-
std::unique_ptr
collective_executor_mgr; -
thread::ThreadPool* compute_pool :线程池,每次有算子执行,都从中获取一个线程。
// The worker environment class, which holds a bag of pointers to
// per-worker singletons.
//
// WorkerEnv does not own its member pointers.
struct WorkerEnv {
Env* env = nullptr;
// session_mgr encapsulates state for each session.
SessionMgr* session_mgr = nullptr;
// The local devices of this worker. Devices are owned by the device_mgr.
//
// REQUIRES: !local_devices.empty().
std::vector<Device*> local_devices;
// device_mgr manages local devices (cpu and gpu). The WorkerService
// is the network interface for managed devices.
//
// Note: Please use the device_mgr associated with your session if appropriate
// instead of this one. Using this device_mgr does not support ClusterSpec
// propagated sessions.
DeviceMgr* device_mgr = nullptr;
// A set of rendezvous keyed by step ids.
RendezvousMgrInterface* rendezvous_mgr = nullptr;
// Generates per-step CollectiveExecutors and has access to utilities
// supporting collective operations.
std::unique_ptr<CollectiveExecutorMgrInterface> collective_executor_mgr;
// A pool of threads for scheduling compute work.
thread::ThreadPool* compute_pool = nullptr;
// Coordination service.
CoordinationServiceInterface* coord_service;
};
WorkerEnv 的几个 管理类成员变量都很重要,比如 SessionMgr 类,其为 Worker 管理会话,比如会话的产生和销毁,同时还维护了当前 Worker 的会话句柄到会话的映射。
class SessionMgr {
public:
Status CreateSession(...);
Status DeleteSession(...);
private:
const WorkerEnv* const worker_env_;
const WorkerCacheFactory worker_cache_factory_;
std::map<string, std::unique_ptr<WorkerSession>> sessions_ GUARDED_BY(mu_);
};
MasterEnv
MasterEnv 把各种相关配置归总在一起,供 master 使用,可以认为是 Master 运行时的上下文,在 Master 的整个生命周期都是可见的。其主要成员变量如下:
- Env* env :跨平台 API 接口。
- vector<Device*> local_devices :本地设备集;
- WorkerCacheFactory worker_cache_factory :工厂类,可以创建 WorkerCacheInterface 实例;
- MasterSessionFactory master_session_factory :工厂类,可以创建 MasterSession 实例;
- WorkerCacheInterface :创建 MasterInterface 实例, MasterInterface 用于调用远端 MasterService 服务;
- OpRegistryInterface* ops :查询特定 OP 的元数据;
- CollectiveExecutorMgrInterface* collective_executor_mgr :访问集合操作。
// The master environment class, which holds a bag of pointers to
// per-master state.
//
// MasterEnv does not own its member pointers.
struct MasterEnv {
Env* env = nullptr;
// Object from which WorkerInterface instances can be obtained. Not owned.
WorkerCacheInterface* worker_cache = nullptr;
// The operation definitions to use. Must be filled before use.
const OpRegistryInterface* ops = nullptr;
// Local devices co-located with this master. Devices are not owned
// by the master service.
//
// REQUIRES: !local_devices.empty().
std::vector<Device*> local_devices;
// Factory for creating master sessions, given session options and a
// vector of devices.
//
// The caller of the function takes ownership of the returned
// MasterSession, which may not be null. Ownership of the
// MasterEnv* is retained by the caller.
std::function<MasterSession*(
SessionOptions, MasterEnv*,
std::unique_ptr<std::vector<std::unique_ptr<Device>>>,
std::unique_ptr<WorkerCacheInterface>,
std::unique_ptr<DeviceSet> device_set,
std::vector<string> filtered_worker_list)>
master_session_factory;
std::function<Status(const WorkerCacheFactoryOptions&,
WorkerCacheInterface**)>
worker_cache_factory;
// Generates per-step CollectiveExecutors and has access to utilities
// supporting collective operations. Not owned.
CollectiveExecutorMgrInterface* collective_executor_mgr = nullptr;
};
Python 代码之中,最后是 start 方法的调用。
@tf_export("distribute.Server", v1=["distribute.Server", "train.Server"])
@deprecation.deprecated_endpoints("train.Server")
class Server(object):
def __init__(self,
server_or_cluster_def,
job_name=None,
task_index=None,
protocol=None,
config=None,
start=True):
self._server_def = _make_server_def(server_or_cluster_def, job_name,
task_index, protocol, config)
self._server = c_api.TF_NewServer(self._server_def.SerializeToString())
if start:
self.start()
在调用之前,Server 是 New 状态,调用 start 之后,GrpcServer 的状态从 New 迁移 Started 状态。Start() 方法之中,会启动三个独立线程,分别是 MasterService,WorkerService,EagerService 的消息处理器。至此,GrpcServer 才对外提供 MasterService 和 WorkerService 这两种服务。
Status GrpcServer::Start() {
mutex_lock l(mu_);
switch (state_) {
case NEW: {
master_thread_.reset(
env_->StartThread(ThreadOptions(), "TF_master_service",
[this] { master_service_->HandleRPCsLoop(); }));
worker_thread_.reset(
env_->StartThread(ThreadOptions(), "TF_worker_service",
[this] { worker_service_->HandleRPCsLoop(); }));
eager_thread_.reset(
env_->StartThread(ThreadOptions(), "TF_eager_service",
[this] { eager_service_->HandleRPCsLoop(); }));
for (const auto& kv : extra_services_) {
const std::string& service_name = kv.first;
AsyncServiceInterface* service = kv.second;
std::unique_ptr<Thread> extra_service_thread;
extra_service_thread.reset(env_->StartThread(
ThreadOptions(), service_name,
[service = service] { service->HandleRPCsLoop(); }));
extra_service_threads_.push_back(std::move(extra_service_thread));
}
state_ = STARTED;
return Status::OK();
}
case STARTED:
return Status::OK();
case STOPPED:
return errors::FailedPrecondition("Server has stopped.");
default:
LOG(FATAL);
}
}
启动之后,需要让这几个线程做 Join 操作,因此主线程会挂起直至这两个线程终止,这样可以持久地对外提供 MasterService 服务和 WorkerService 服务。
Status GrpcServer::Join() {
mutex_lock l(mu_);
switch (state_) {
case NEW:
// Prevent the server from being started subsequently.
state_ = STOPPED;
return Status::OK();
case STARTED:
case STOPPED:
master_thread_.reset();
worker_thread_.reset();
eager_thread_.reset();
for (auto& thread : extra_service_threads_) {
thread.reset();
}
return Status::OK();
default:
LOG(FATAL);
}
}
至此,TF 分布式环境总体介绍完毕。
0xFF 参考TensorFlow Internals
TensorFlow架构与设计:概述
TensorFlow内核剖析
TensorFlow架构与设计:OP本质论
[译] TensorFlow 白皮书
2017TensorFlow开发者峰会
https://jcf94.com/2018/02/28/2018-02-28-tfunpacking3/
TensorFlow 拆包(五):Distributed
TensorFlow Architecture
『深度长文』Tensorflow代码解析(五)
什么是in-graph replication和between-graph replication?
[腾讯机智] TensorFlow源码解析(1): 创建会话
05tensorflow分布式会话
第八节,配置分布式TensorFlow
TensorFlow 分布式(Distributed TensorFlow)
tensorflow源码解析之distributed_runtime
Distributed TensorFlow: A Gentle Introduction
一文说清楚Tensorflow分布式训练必备知识
TensorFlow中的Placement启发式算法模块——Placer
TensorFlow的图切割模块——Graph Partitioner
TensorFlow中的通信机制——Rendezvous(一)本地传输
TensorFlow分布式采坑记
TensorFlow技术内幕(九):模型优化之分布式执行
Tensorflow架构流程]