学习爬虫,最好的方式就是自己编写爬虫程序。
爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接、然后下载、最后保存。
但是在实施过程却会遇到一些阻碍。
很多网站为了阻止爬虫程序爬取数据,会对资源路径进行加密、或隐藏等保护操作。
编写爬虫程序的第一关键逻辑就解析资源路径。
2. 静态资源路径什么是静态资源路径?
在下载下来的源代码中可以直接分析并找出资源路径。
向服务器请求 入口(主)页面 时,服务器就已经把主页面中需要展示的资源路径一并返回给请求者。
爬虫任务:爬取王者荣耀网站上的英雄资料。
3.1 下载入口网页找到王者荣耀英雄资料的入口链接:https://pvp.qq.com/web201605/herolist.shtml,打开谷歌浏览器,下载并显示出所有的英雄的图片。
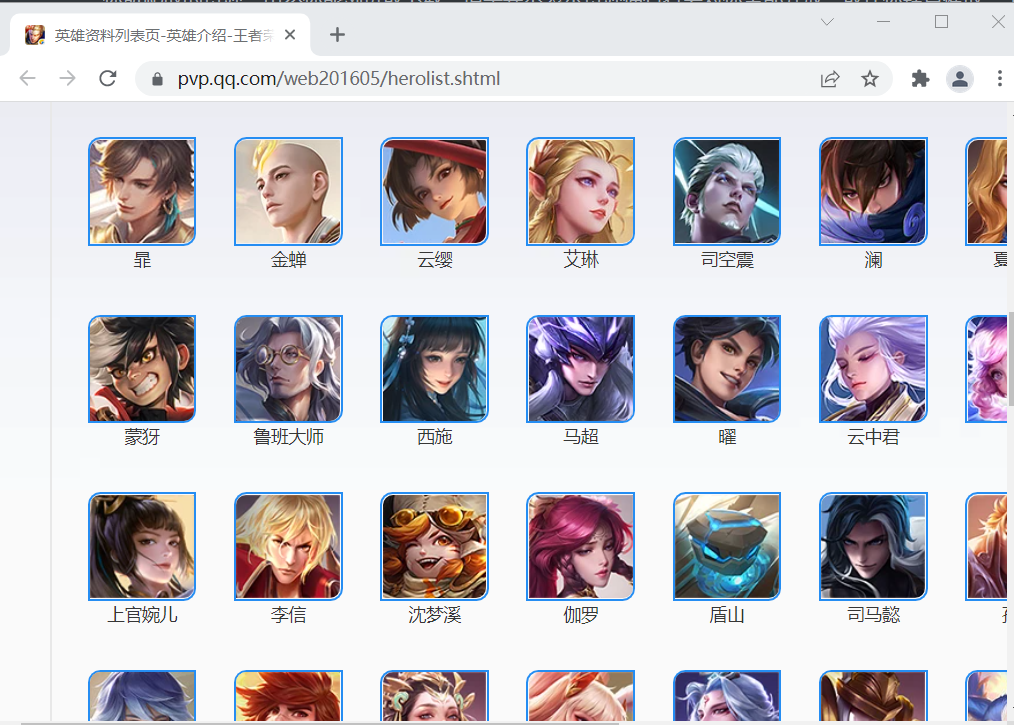
为了下载入口页中的所有英雄图片资源,则需要使用一个统一的规则找到所的资源路径(url),正则表达式是一个不错的选择。
编写正则表达式之前,先分析图片路径的描述规则。
在浏览器中选择任意一张图片,然后右击,再在弹出来的快捷菜单中选择“检查”,便可以看到此图片的路径。
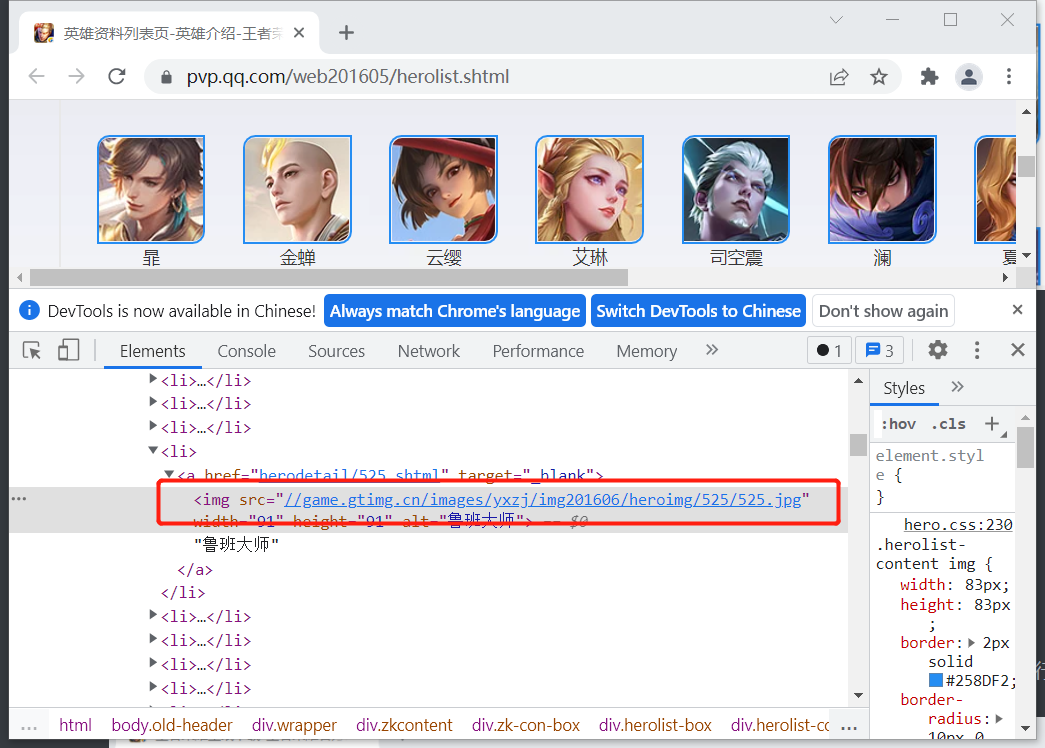
复制出图片路径:
<img src="//game.gtimg.cn/images/yxzj/img201606/heroimg/525/525.jpg" width="91" height="91" alt="鲁班大师">
再选择任意张图片,同理使用浏览器的“检查”功能,获取所选择图片的路径:
<img src="//game.gtimg.cn/images/yxzj/img201606/heroimg/522/522.jpg" width="91" height="91" alt="曜">
<img src="//game.gtimg.cn/images/yxzj/img201606/heroimg/504/504.jpg" width="91" height="91" alt="米莱狄">
<img src="//game.gtimg.cn/images/yxzj/img201606/heroimg/180/180.jpg" width="91" height="91" alt="哪吒">
……
纵观现获取到的图片路径,可以解析出其中规律:
- 服务器地址: game.gtimg.cn/images,可以发现所有图片路径的这部分都是相同的。
- 服务器上图片存储的目录结构: yxzj/img201606/heroimg/数字。对于所有图片,目录结构中的 “yxzj/img201606/heroimg” 是相同的,但每一张图片都有自己的子目录,应该是图片的编号,虽然不相同,但都是数字。
- 图片文件名: 数字.jpg,文件名的格式应该是图片编号+扩展名。
有了如上基础信息后,就可以编写一个用来描述图片资源的正则表达式。
img_re = r"//game.gtimg.cn/images/yxzj/img201606/heroimg/\d+/\d+.jpg"
import requests
import re
# 服务器地址
url = "https://pvp.qq.com/web201605/herolist.shtml"
# 与图片路径匹配的正则表达式
img_re = r"(//game.gtimg.cn/images/yxzj/img201606/heroimg/\d+/(\d+.jpg))"
# 伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
# 发送请求
resp = requests.get(url, headers=headers)
content = resp.text
# 查找所有图片路径
img_urls = re.findall(img_re, content)
print(img_urls)
#下载所有图片,保存到本地
for img_url in img_urls:
resp = requests.get("https:" + img_url[0])
with open("d:/heros/" + img_url[1], "wb") as f:
print("正在保存", img_url[1])
f.write(resp.content)
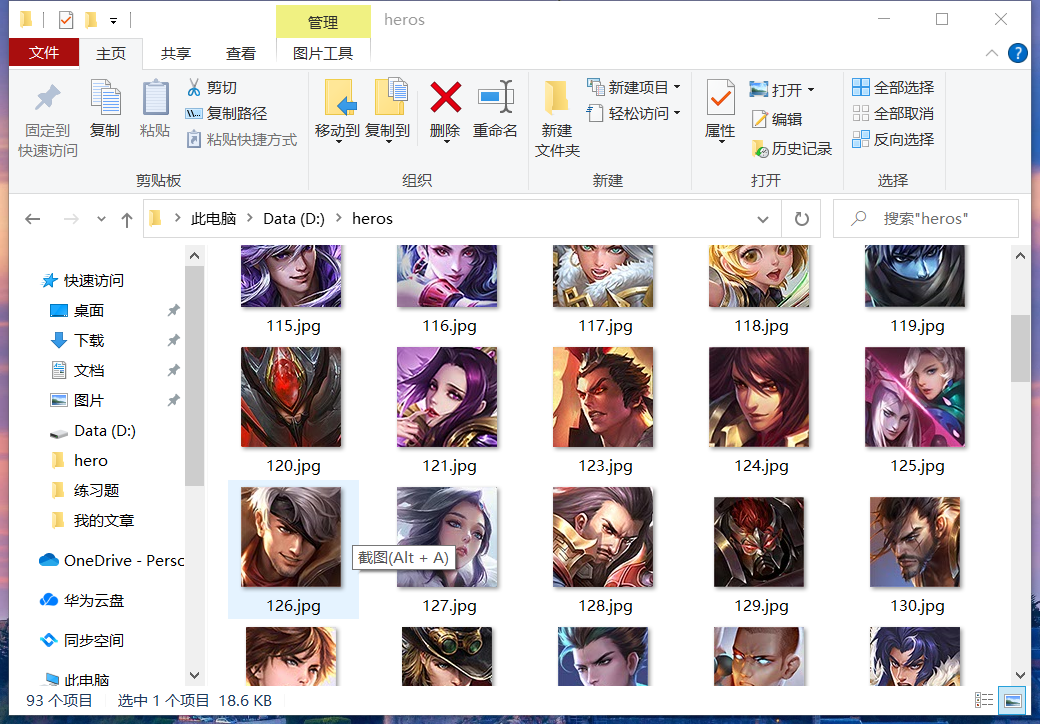
运行程序后,再在本地磁盘中的 d:\heros 目录查看,可以看到英雄图片已经全部下载成功。
静态资源的路径解析相对而言较简单,考核的是正则表达语言的编写能力。
3. 动态资源路径所谓动态资源路径指无法从下载下来的入口页面源代码中直接找出来的资源路径。
当用户请求服务器入口页面时,响应包中并没有直接返回资源路径。而是在用户的后续操作过程通过 ajax 在客户端动态加载。
源代码中没有,在动态运行过程中由逻辑动态产生。
为了更好的理解动态资源路径,现给爬虫一个任务:
下载下载王者荣耀官方网站所提供的大量高清英雄壁纸。
3.1 常 规解析资源路径找到入口 https://pvp.qq.com/web201605/wallpaper.shtml 链接,使用谷歌浏览器打开,可显示出英雄壁纸。
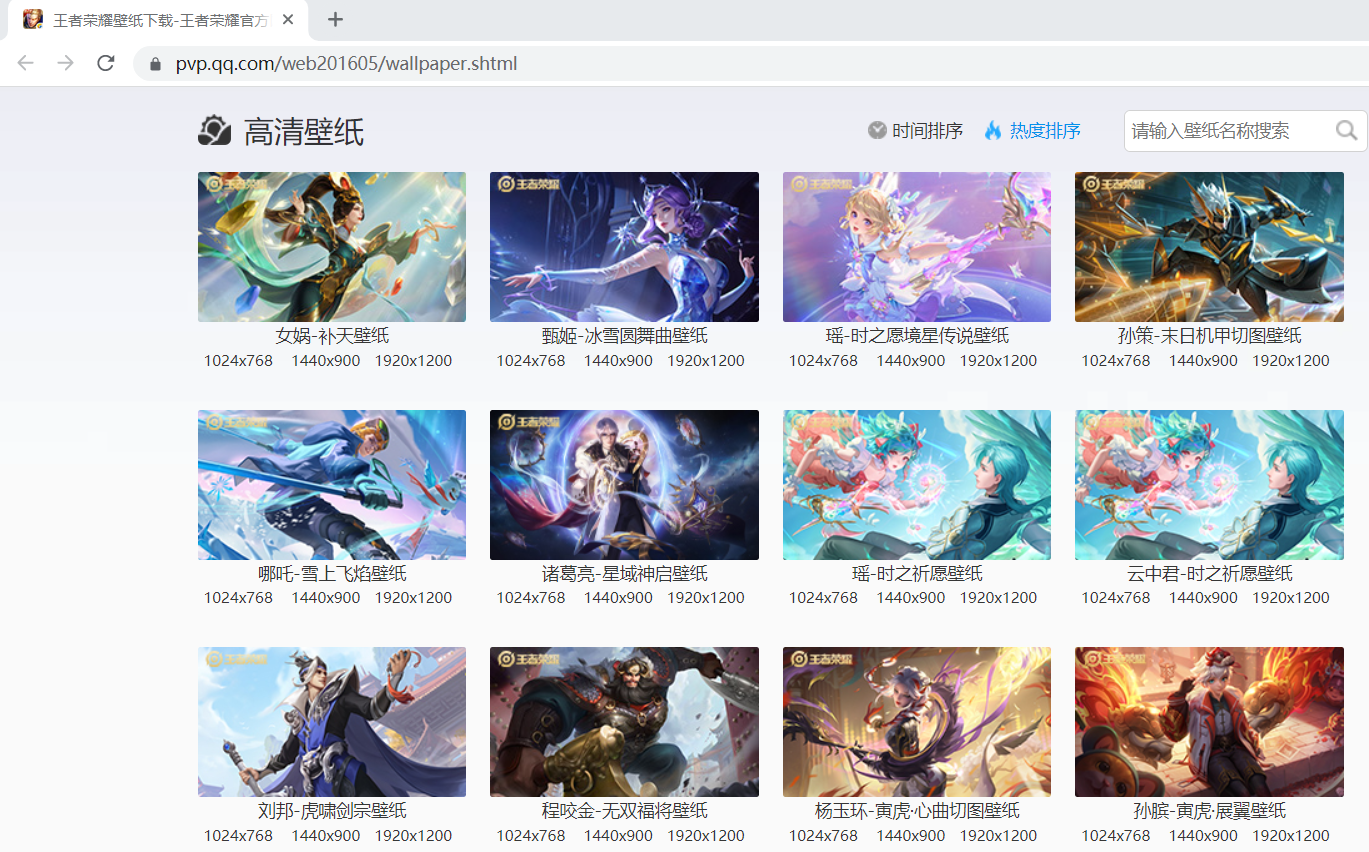
因为已经有了前面下载英雄资料的经验,现在我们如法炮制。
分析图片的路径规则:
选择任一张高清壁纸,然后右击,再在快捷菜单中选择“检查”

可以查阅到此图片的完整路径:
https://shp.qpic.cn/ishow/2735022317/1645610302_1265602313_48245_sProdImgNo_1.jpg/0
再找任意的几张图片,用同样的方法查找出它们的路径。
https://shp.qpic.cn/ishow/2735021517/1644917442_1265602313_38411_sProdImgNo_1.jpg/0
https://shp.qpic.cn/ishow/2735012712/1643257997_1265602313_18054_sProdImgNo_1.jpg/0
https://shp.qpic.cn/ishow/2735010717/1641547765_1265602313_26451_sProdImgNo_1.jpg/0
分析后,可知图片(资源)的路径由几个部分组成:
-
服务器地址: https://shp.qpic.cn ,所有图片都在同一个服务器。
-
图片在服务器上的存储目录: ishow/2735010717/ 目录结构中的 ishow 即父目录是相同的,虽然子目录不相同,但其有一个规律,都是数字。
-
图片名称: 1641547765_1265602313_26451_sProdImgNo_1.jpg 图片名称由如下几部分组成:
-
3 串数字: 1641547765_1265602313_26451, 3 串数字中的第 1 串和第 3 串不相同,第2 串数字是相同的。
-
sProdImgNo_1.jpg: 1 串字符串,这部分所有图片都相同。
-
-
在整个路径的最后还有一个 /0
有了上面的分析基础,编写正则表达式就简单了。
img_url_re = r"(https://shp.qpic.cn/ishow/\d+/(\d+_){3}sProdImgNo_1.jpg/0)"
有了正则表达式,感觉这些壁纸马上就能唾手可得。
然而,使用上面正则表达式在入口页面( https://pvp.qq.com/web201605/wallpaper.shtml )中试图查找出所有图片资源路径时却让我们失望了。
import re
import requests
# 王者荣耀官方壁纸地址
wzry_url = "https://pvp.qq.com/web201605/wallpaper.shtml"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
# 解析图片的正则表达式
img_url_re = r"(https://shp.qpic.cn/ishow/\d+/(\d+_){3}sProdImgNo_1.jpg/0)"
# 访问王者荣耀高清壁纸页面
response = requests.get(wzry_url)
# 获得网站数据
content = response.text
print(content)
# 查找所有图片路径
lst = re.findall(img_url_re, content)
print(lst)
3.2 查找真正的资源入口输出结果是 [ ]。没有查询到任何图片资源路径。
为什么会这样?
因为在我们请求 https://pvp.qq.com/web201605/wallpaper.shtml 入口页面后,在返回的入口数据中没有包含壁纸的路径。
它使用的是动态加载壁纸的方案,也就是 https://pvp.qq.com/web201605/wallpaper.shtml 不是真正的资源入口链接。
相当于给了你一个礼盒,打开没有看到真正的礼物,只有一些线索,需要你通过这个索引再找到礼物。
真正的资源入口链接可能加密,也可能隐藏在一群链接的中间。
开始寻找的旅程。
在谷歌浏览器的开发者工具中选择 ”Network“ 并在面板中选择 ”Fetch/XHR“,会看到了一个 herolist.json 路径,从字面意义上解读,感觉应该是它。
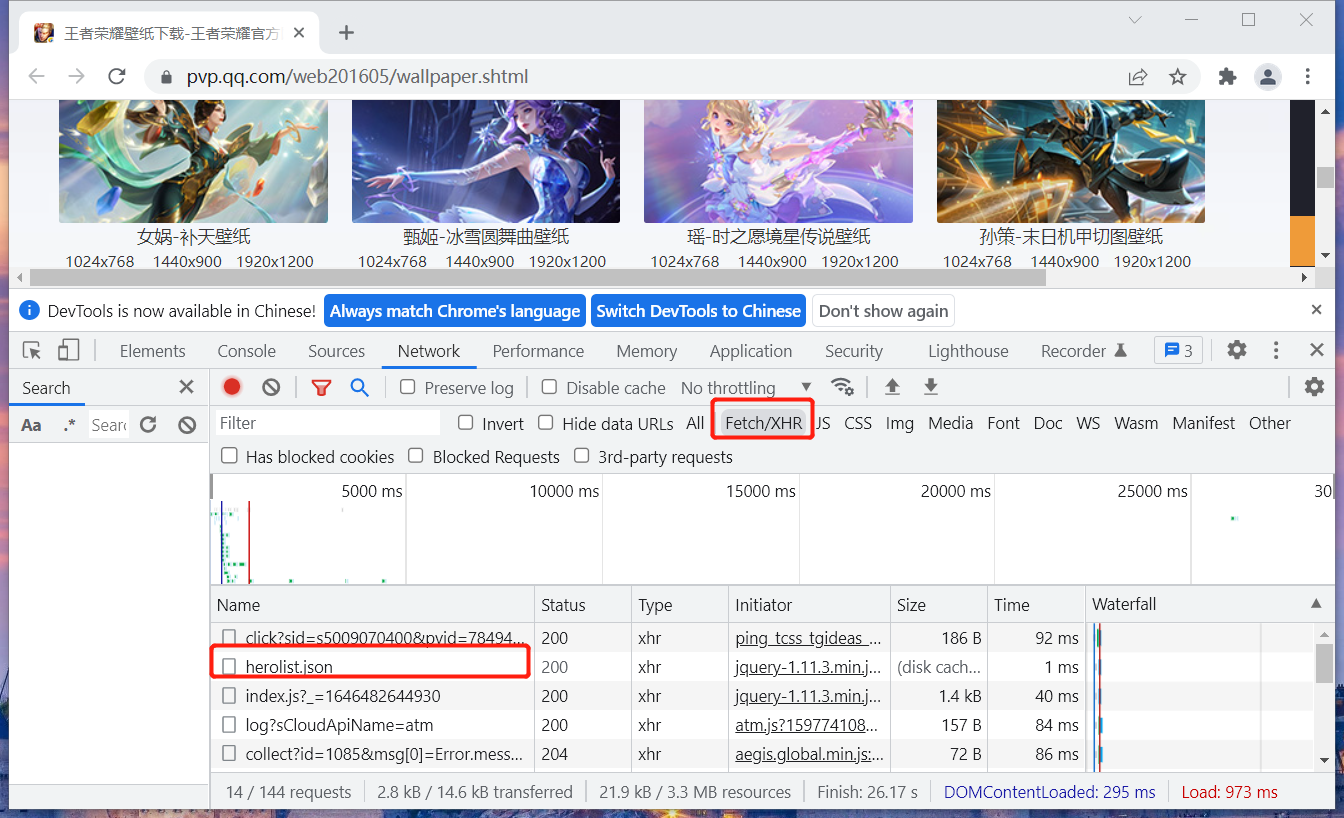
于是,以此路径作为入口链接开始编码。
import requests
wzry_url = "https://pvp.qq.com/web201605/js/herolist.json"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
response = requests.get(wzry_url)
# 获得网站数据
content = response.text
print(content)
执行程序后,看到如下输出结果。
[{
"ename": 105,
"cname": "廉颇",
"title": "正义爆轰",
"new_type": 0,
"hero_type": 3,
"skin_name": "正义爆轰|地狱岩魂"
}, {……},……
]
数据以 JSON 格式返回,但是没有看到图片路径信息。
看来此路径不是资源的真正入口链接。
现在扩大路径查找范围,找到一个workList_inc.cgi 路径。
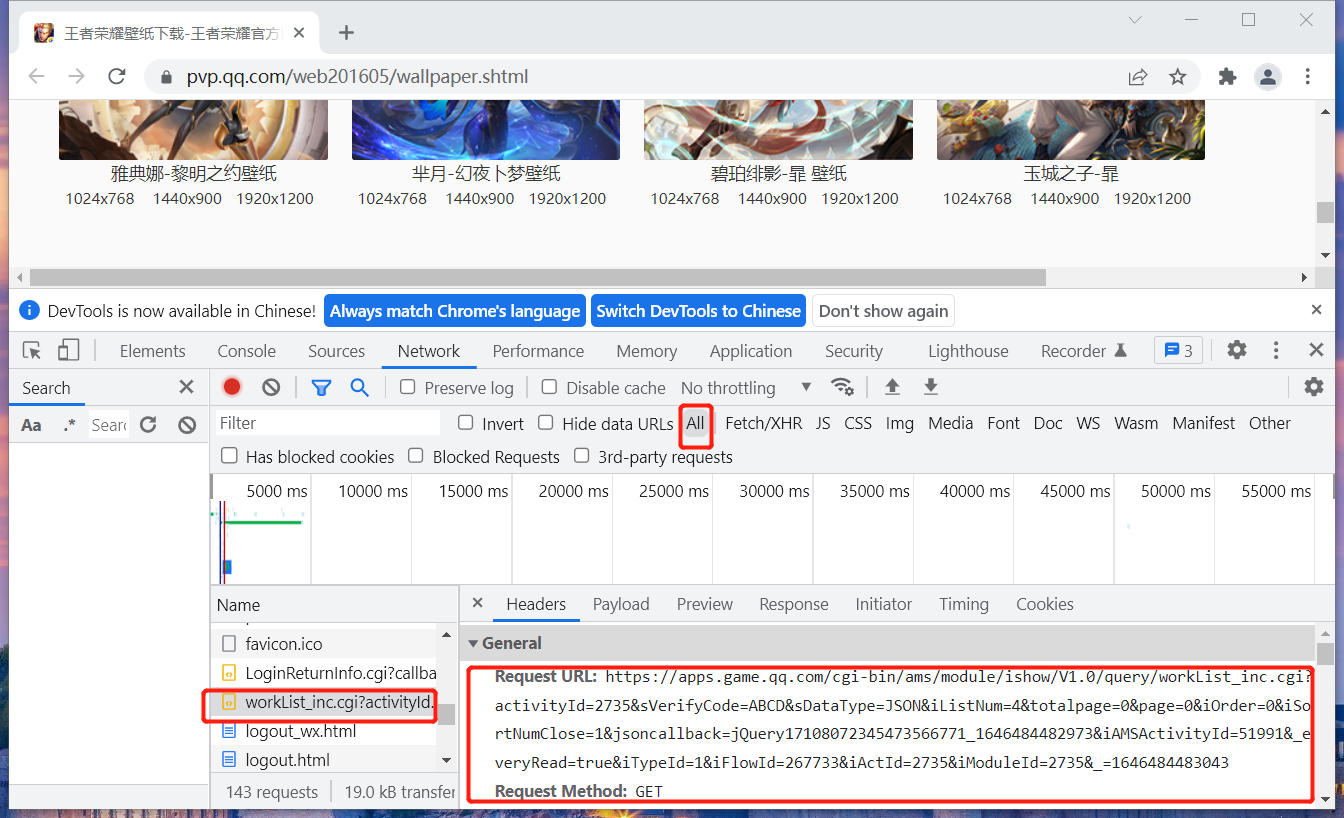
复制此路径后分析发现,此路径的嫌疑非常大。
https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=4&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17108072345473566771_1646484482973&iAMSActivityId=51991&_everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&_=1646484483043
在 "Response"中可以看到请求返回值是一个 JSON 格式。
jQuery17108072345473566771_1646484482973({"iBltFlag":"0","iCache":"1","iRet":"0","iTotalLines":"299","iTotalPages":"75","sMsg":"Successful","List":[{"dtInputDT":"2022%2D02%2D23%2017%3A57%3A56","iBallotNum":"0","iClickNum":"0","iCommentNum":"0","iDownloadNum":"0","iNonsupportNum":"0","iProdId":"1931","iStatus":"1","sProdImgNo_1":"https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610274%5F1265602313%5F44569%5FsProdImgNo%5F1%2Ejpg%2F200","sProdImgNo_2":"https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610274%5F1265602313%5F44569%5FsProdImgNo%5F2%2Ejpg%2F200","sProdImgNo_3":"https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610274%5F1265602313%5F44569%5FsProdImgNo%5F3%2Ejpg%2F200","sProdImgNo_4":"https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610275%5F1265602313%5F44569%5FsProdImgNo%5F4%2Ejpg%2F200","sProdImgNo_5":"https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610275%5F1265602313%5F44569%5FsProdImgNo%5F5%2Ejpg%2F200","sProdImgNo_6":"https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610275%5F1265602313%5F44569%5FsProdImgNo%5F6%2Ejpg%2F200","sProdImgNo_7":"https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610275%5F1265602313%5F44569%5FsProdImgNo%5F7%2Ejpg%2F200","sProdImgNo_8":"https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610275%5F1265602313%5F44569%5FsProdImgNo%5F8%2Ejpg%2F200","sProdName":"%E5%A5%B3%E5%A8%B2%2D%E8%A1%A5%E5%A4%A9%E5%A3%81%E7%BA%B8","sThumbURL":"https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610274%5F1265602313%5F44569%5FsProdImgNo%5F1%2Ejpg%2F200"},{……}]})
数据里面有一个 List 属性,返回的是一个数组,每一个数组中包括一个 JSON 对象,关键是 JSON 对象中有语义很明确的地址信息。
https%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735022317%2F1645610274%5F1265602313%5F44569%5FsProdImgNo%5F1%2Ejpg%2F200
把此路径和前面分析出来的图片路径比较一下
https://shp.qpic.cn/ishow/2735021517/1644917442_1265602313_38411_sProdImgNo_1.jpg/0
会发现,JSON 中的路径是对真正图片路径中的特殊符号转码后生成的。
看来包括真正资源的入口链接就是它了。
https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=4&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&_=1646484483043
开始编码之前,先根据语义修改一下请求参数:
- iListNum 参数应该表示每一页有多少张 ,现修改成 10。
- 删除 jsoncallback=jQuery17108072345473566771_1646484482973 请求参数。
import requests
import urllib.parse
import json
# 真正资源的入口链接
url = "https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=10&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&_=1646484483043"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
# 请求第一页数据(page=0)
resp = requests.get(url, headers=headers)
res_text = resp.text
# 反序列化 JSON
data_dict = json.loads(res_text)
# 所有图片数据
all_imgs_data = data_dict.get("List")
# 迭代图片
for img_data in all_imgs_data:
# 获取图片的路径(网站提供不同分辨率的图片,数字编号从0 到 8)
img_url = img_data["sProdImgNo_4"]
# 解码
img_url = urllib.parse.unquote(img_url)
# 把 URL 后面的 200 替换成 0
img_url = img_url.replace("200", "0")
# 抓取图片数据
resp = requests.get(img_url, headers=headers)
# 保存图片到本地
with open("d:/heros/" + urllib.parse.unquote(img_data["sProdName"])+".jpg", "wb") as f:
f.write(resp.content)
以上代码仅获取了10 张图片,如果需要更多,可以修改:
把 iListNum 设置成一个更大的值。
或者通过迭代方式修改 page=0 后面的值 ,这个参数表示页码
打开本地目录,可看到下载下来的高清壁纸。
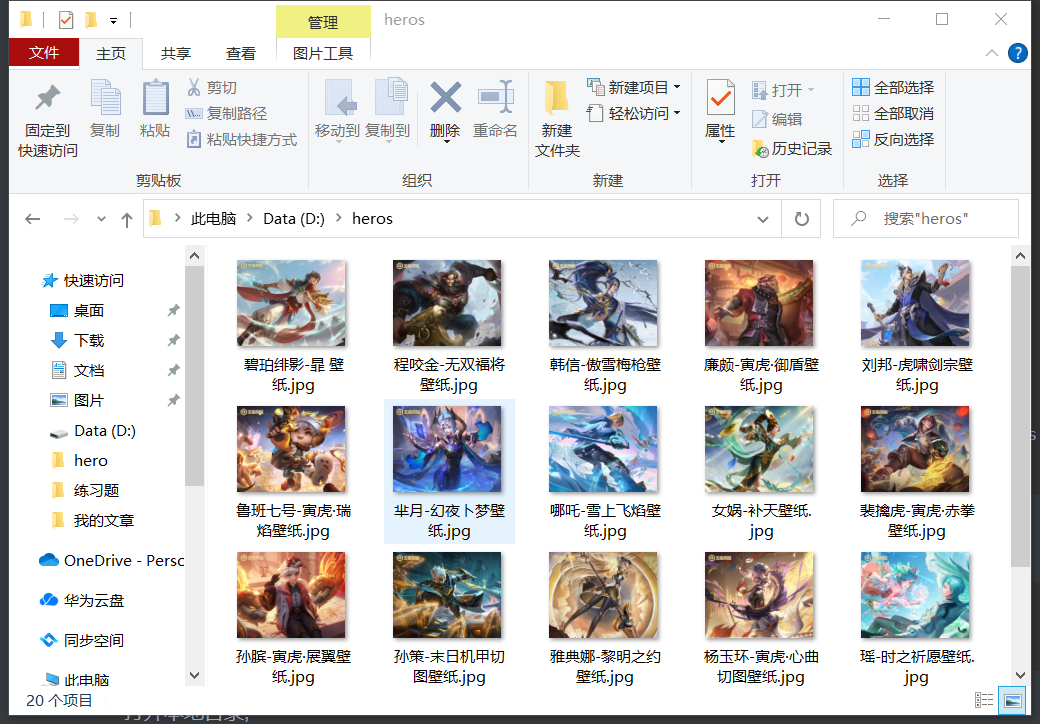
爬虫程序的编写关键,准确分析到资源路径。