CPU使用率描述了非空闲时间占总CPU时间的百分比,根据CPU上运行任务的不同可以分为:用户CPU、系统CPU、等待I/O CPU、软中断和硬中断等
- 用户CPU使用率,包括用户态CPU使用率(user)和低优先级用户态CPU使用率(nice),表示CPU在用户态运行的时间百分比。用户CPU使用率高,通常说明有应用程序比较繁忙
- 系统CPU使用率,表示CPU在内核态运行的时间百分比(不包括中断)。系统CPU使用率高,说明内核比较繁忙
- 等待I/O的CPU使用率,通常也称之为iowait,表示等待I/O的时间百分比。iowait高,通常说明系统与硬件设备的I/O交互时间比较长。
- 软中断和硬中断的CPU使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断
- 窃取CPU使用率(steal)和客户CPU使用率(guest),分别表示被其他虚拟机占用的CPU时间百分比和运行客户虚拟机的CPU时间百分比
系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去1分钟、过去5分钟和过去15分钟的平均负载。
理想情况下,平均负载等于逻辑CPU个数,这表示每个CPU都恰好被充分利用。如果平均负载大于逻辑CPU个数,就表示负载比较重。
c>上下文切换- 无法获取资源而导致的自愿上下文切换
- 被系统强制调度导致的非自愿上下文切换
上下文切换,本身是保证Linux正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的CPU时间,消耗寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
d>CPU的缓存命中率https://cloud.tencent.com/developer/article/1597149
CPU的处理速度要比内存的访问速度快很多,CPU在访问内存的时候,就需要等待内存的响应。为了协调二者的巨大性能差距,CPU缓存(多级缓存)就出现了
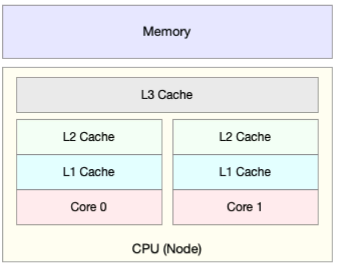
CPU缓存的速度介于CPU和内存之间,缓存的是热点的内存数据。根据不断增长的热点数据,这些缓存按照大小不同分为L1、L2、L3等三级缓存,其中L1和L2常用在单核中,L3则用在多核中。
从L1到L3,三级缓存的大小依次增大,相应的性能依次降低(当然比内存好很多)。而它们的命中率,衡量的是CPU缓存的复用情况,命中率越高,则表示性能越好。
2,性能工具 a>平均负载uptime查看系统的平均负载。在平均负载升高时,使用mpstat和pidstat,分别观察每个CPU和每个进程CPU的使用情况,进而定位负载升高的进程
b>上下文切换vmstat查看系统的上下文切换次数和中断次数。使用pidstat (-w),观察进程的自愿上下文切换(cswch/s)和非自愿上下文切换(nvcswch/s);使用pidstat(-wt)输出具体线程的上下文切换。
c>CPU使用率升高使用top观察具体的CPU情况,然后使用perf工具定位具体的线程和函数
d>不可中断进程和僵尸进程top观察iowait升高,并发现出现大量的zombie僵尸进程,使用dstat定位为磁盘读取导致,再使用pidstat找出相关进程,最后用perf工具定位原因
e>软中断top观察cpu使用率升高,再使用watch -d /proc/softirqs,找到变化速率较快的软中断,然后通过sar(-n DEV)显示网络收发的报告,发现为网络小包问题,最后用tcpdump,找到网络帧的类型和来源,确定为SYNFLOOD攻击导致。
3,性能指标和性能工具关联 a>根据指标找工具 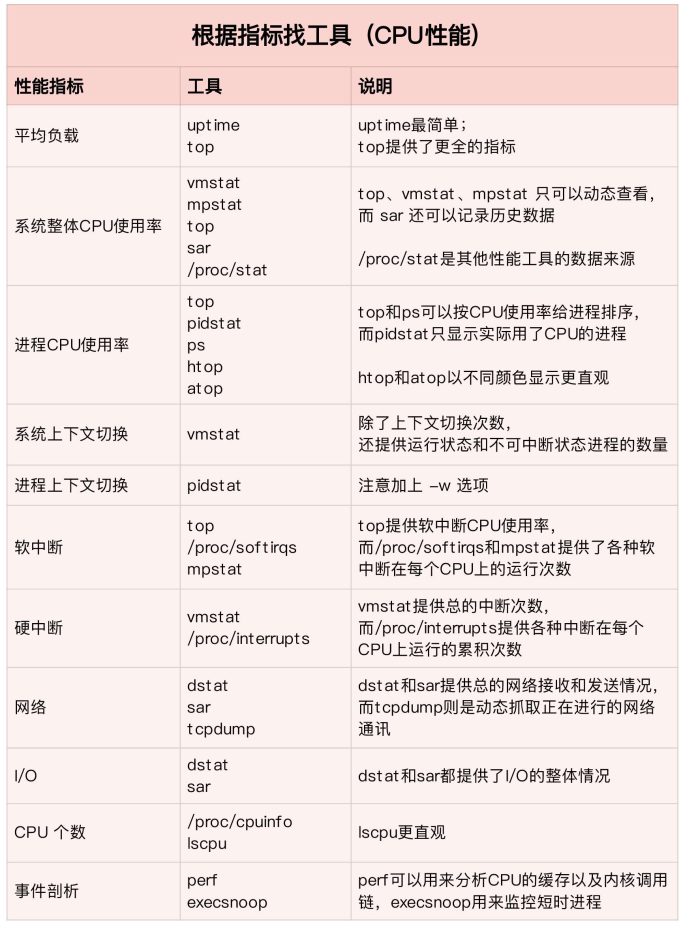
 c>分析CPU性能瓶颈
c>分析CPU性能瓶颈
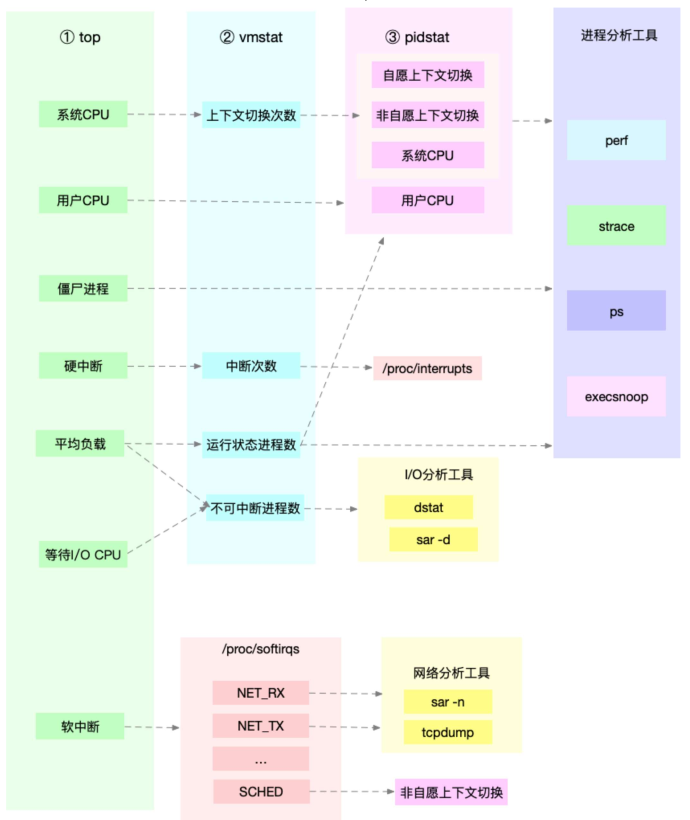
不要局限在单一维度的指标上。以web项目为例:
- 应用程序的维度,可以用吞吐量和请求延迟来评估应用程序的性能
- 系统资源的维度,可以用CPU使用率来评估系统的CPU使用情况
降低CPU使用率的最好方法是排除所有不必要的工作,只保留最核心的逻辑。比如减少循环的层次、减少递归、减少动态内存分配等。
除此之外,应用程序的优化也包括很多方法,最常用的:
- 编译器优化:很多编译器都会提供优化选项,适当开启。比如,gcc就提供了优化选项 -O2,开启后会自动对应用程序的代码进行优化。
- 算法优化:使用复杂度更低的算法,可以显著加快处理速度。比如,在数据比较大的情况下,可以用O(nlogn)的排序算法(如快排、归并排序等),代替O(n^2)的排序算法(如冒泡、插入排序等)。
- 异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费CPU的问题。
- 多线程代替多进程:相对于进程上下文切换, 线程上下文切换并不切换进程选址空间,因此可以降低上下文切换的成本
- 善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在下次用时就能直接从内存中获取,加快程序的处理速度。
从系统的角度来说,优化CPU的运行,一方面要充分利用CPU缓存的本地性,加速缓存访问;另一方面,就是要控制进程的CPU使用情况,减少进程间的相互影响。常见方法:
- CPU绑定:把进程绑定到一个或者多个CPU上,可以提高CPU缓存的命中率,减少跨CPU调度带来的上下文切换问题
- CPU独占:跟CPU绑定类似,进一步将CPU分组,并通过CPU亲和性机制为其分配进程。这样,这些CPU就由指定的进程独占,换句话说,不允许其他进程再来使用这些CPU。
- 优先级调整:使用nice调整进程的优先级,正值调低优先级,负值调高优先级。适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
- 为进程设置资源限制:使用Linux cgroups 来设置进程的CPU使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源
- NUMA(Non-Uniform Memory Accesss)优化:支持NUMA的处理器会被划分为多个node,每个node都有自己的本地内存空间。NUMA优化,其实就是让CPU尽可能只访问本地内存。
- 中断负载均衡:无论软中断还是硬中断,它们的中断处理程序都可能会耗费大量的CPU。开启irqbalance服务或者配置smp_affinity,就可以吧中断处理过程自动负载均衡到多个CPU上。