最近,又遇到了慢 SQL,简单的看了下,又是因为 MySQL 本身优化器还有查询计划估计不准的问题。SQL 如下:
select * from t_pay_record
WHERE
((
user_id = 'user_id1'
AND is_del = 0
))
ORDER BY
id DESC
LIMIT 20
这个 SQL 执行了 20 分钟才有结果。但是我们换一个 user_id,执行就很快。从线上业务表现来看,大部分用户的表现都正常。我们又用一个数据分布与这个用户相似的用户去查,还是比较快。
我们先来 EXPLAIN 下这个原始 SQL,结果是:
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | t_pay_record | NULL | index | idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del | PRIMARY | 8 | NULL | 22593 | 0.01 | Using where |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------+---------+------+-------+----------+-------------+
然后我们换一些分布差不多的用户但是响应时间正常的用户,EXPLAIN 结果有的是:
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------------------------------------------------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------------------------------------------------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | t_pay_record | NULL | index | idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del | idx_user_id_trade_code_status_amount_create_time_is_del | 195 | NULL | 107561| 10.00| Using where |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------------------------------------------------------+---------+------+-------+----------+-------------+
有的是:
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | t_pay_record | NULL | index | idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del | idx_user_id | 195 | NULL | 87514| 10.00| Using where |
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
其实根据这个表现就可以推断出,是走错索引了。为啥会用错索引呢?这个是因为多方面的原因导致的,本篇文章将针对这个 SQL 来分析下这个多方面的原因,并给出最后的解决办法。
对于 MySQL 慢 SQL 的分析在之前的文章,我提到过 SQL 调优一般通过下面三个工具:
- EXPLAIN:这个是比较浅显的分析,并不会真正执行 SQL,分析出来的可能不够准确详细。但是能发现一些关键问题。
- PROFILING: 通过
set profiling = 1开启的 SQL 执行采样。可以分析 SQL 执行分为哪些阶段,并且每阶段的耗时如何。需要执行并且执行成功 SQL,并且分析出来的阶段不够详细,一般只能通过某些阶段是否存在如何避免这些阶段的出现进行优化(例如避免内存排序的出现等等)。 - OPTIMIZER TRACE:详细展示优化器的每一步,需要执行并且执行成功 SQL。MySQL 的优化器由于考虑的因素太多,迭代太多,配置相当复杂,默认的配置在大部分情况没问题,但是在某些特殊情况会有问题,需要我们进行人为干预。
这里再说一下在不同的 MySQL 版本, EXPLAIN 和 OPTIMIZER TRACE 结果可能不同,这是 MySQL 本身设计上的不足导致的,EXPLAIN 更贴近最后的执行结果,OPTIMIZER TRACE 相当于在每一步埋点采集,在 MySQL 不断迭代开发的时候,难免会有疏漏
对于上面这个 SQL,我们其实 EXPLAIN 就能知道它的原因是走错索引了。但是不能直观的看出来为啥会走错索引,需要通过 OPTIMIZER TRACE 进行进一步定位。但是在进一步定位之前,我想先说一下 MySQL 的 InnoDB 查询优化器数据配置。
MySQL InnoDB 查询优化器数据配置(MySQL InnoDB Optimizer Statistics)官网文档地址:https://dev.mysql.com/doc/refman/8.0/en/innodb-persistent-stats.html
为了优化用户的 SQL 查询,MySQL 会对所有 SQL 查询进行 SQL 解析、改写和查询计划优化。针对 InnoDB 引擎,制定查询计划的时候要分析:
- 全表扫描消耗是多大
- 走索引可以走哪些索引?会考虑 where 条件,以及 order 条件,通过里面的条件找有这些条件的索引
- 每个索引的查询消耗是多大
- 选出消耗最小的那个查询计划并执行
每个索引查询消耗,需要通过 InnoDB 查询优化器数据。这个数据是通过采集表以及索引数据得出的,并且并不是全量采集,而是抽样采集。与以下配置相关:
innodb_stats_persistent全局变量控制全局默认的数据是否持久化,默认为 ON 即持久化,我们一般不会能接受在内存中保存,这样万一数据库重启,表就要重新分析,这样减慢启动时间。控制单个表的配置是STATS_PERSISTENT(在CREATE TABLE以及ALTER TABLE中使用)。innodb_stats_auto_recalc全局变量全局默认是否自动更新,默认为 ON 即在表中有 10% 以上的行更新后触发后台异步更新采集数据,。控制单个表的配置是STATS_AUTO_RECALC(在CREATE TABLE以及ALTER TABLE中使用)。innodb_stats_persistent_sample_pages全局变量控制全局默认的采集页的数量,默认为 20. 即每次更新,随机采集表以及表中的每个索引的 20 页数据,用于估算每个索引的查询消耗是多大以及全表扫描消耗是多大,控制单个表的配置是STATS_SAMPLE_PAGES(在CREATE TABLE以及ALTER TABLE中使用)。
通过之前的 EXPLAIN 的结果,我们知道最后的查询用的索引是 PRIMARY 主键索引,这样的话整个 SQL 的执行过程就是:通过主键倒序遍历表中的每一条数据,直到筛选出 20 条。通过执行耗时我们知道,这个遍历了很多数据才凑满 20 条,效率极其低下。为啥会这样呢?
通过 SQL 语句我们知道,在前面提到的第二步中,考虑的索引包括 where 条件中的 user_id,is_del 相关的索引(通过 EXPLAIN 我们知道有这些索引:idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del),以及 order by 条件中的 id 索引,也就是主键索引。假设本次随机采集中采集的页数据是这个样子的:
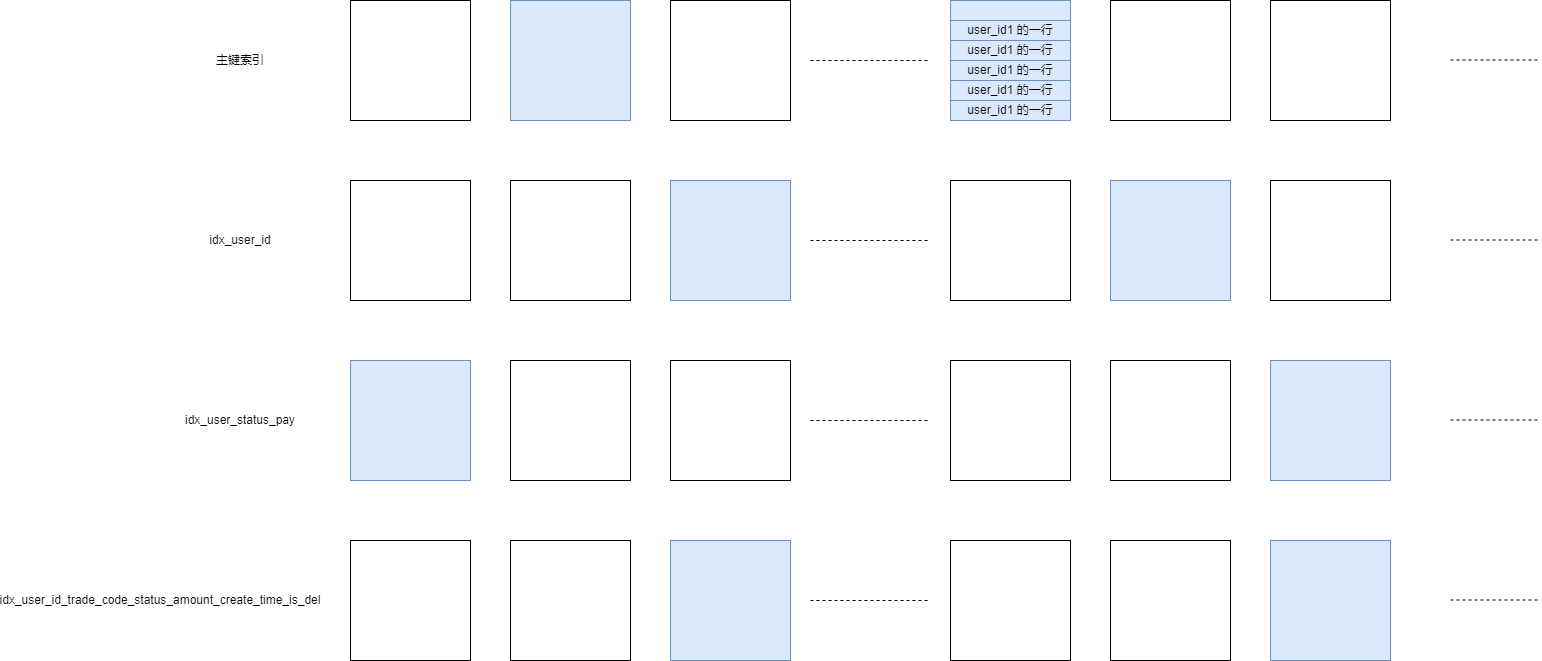
图中蓝色的代表抽样到的页,同一个表内每个索引都会抽样默认 20 页。假设本次采集的结果就是图中所示,其他索引采集的比较均衡,通过其他索引判断用户都要扫描几万行的结果。但是主键采集的最后一页,正好末尾全是这个用户的记录。由于语句最后有 limit 20,如果末尾正好有 20 条记录(并且都符合 where 条件),那么就会认为按照主键倒着找 20 条记录就可以了。这样就会造成优化器认为走主键扫描消耗最少。但是实际上并不是这样,因为这是采样的,没准后面有很多很多不是这个用户的记录,对大表尤其如此。
如果我们把 limit 去掉,EXPLAIN 就会发现索引走对了,因为不限制 limit,主键索引就要全部扫描一遍,消耗怎么也不可能比 user_id 相关的索引低了。
执行时间正常的 SQL 为啥 user_id 不同也会走分析出走不同索引的原因同样的,由于所有索引的优化器数据是随机采样的,随着表的不断变大以及索引的不断膨胀,还有就是可能加更复杂的索引,这样会加剧使用不同参数分析索引消耗的差异性(这里就是使用不同的 user_id)。
这也引出了一个新的可能大家也会遇到的问题,我在原有索引的基础上,加了一个复合索引(举个例子就是原来只有 idx_user_id,后来加了 idx_user_status_pay),那么原来的只按照 user_id 去查数据的 SQL,有的可能会使用
idx_user_id,有的可能会使用 idx_user_status_pay,使用 idx_user_status_pay 大概率比使用 idx_user_id, 慢。所以,添加新的复合索引,可能会导致原来的不是这个复合索引要优化的 SQL 的其他业务 SQL 变慢,所以需要慎重添加
- 由于统计数据不是实时更新,而是更新的行数超过一定比例才会开始更新。并且统计数据不是全量统计,是抽样统计。所以在表的数据量很大的时候,这个统计数据很难非常准确。
- 由于统计数据本来就不够准确,表设计如果也比较复杂,存储的数据类型比较多,字段也很多,并且最关键的是有各种复合索引,索引也越来越复杂,这样更加加剧了这个统计数据的不准确性。
- 顺便说一下:MySQL 表数据量不能很大,需要做好水平拆分,同时字段不能太多,所以需要做好垂直拆分。并且索引不能随便加,想加多少加多少,也有以上说的这两个原因,这样会加剧统计数据的不准确性,导致用错索引。
- 手动 Analyze Table,会在表上加读锁,会阻塞表上的更新以及事务。所以不能在这种在线业务关键表上面使用。可以考虑在业务低峰的时候,定时 Analyze 业务关键 Table
- 依靠表本身自动刷新数据机制,参数比较难以调整(主要是
STATS_SAMPLE_PAGES这个参数,STATS_PERSISTENT我们一般不会改,我们不会能接受在内存中保存,这样万一数据库重启,表就要重新分析,这样减慢启动时间,STATS_AUTO_RECALC我们也不会关闭,这样会导致优化器分析的越来越不准确),很难预测出到底调整到什么数值最合适。并且业务的增长,用户的行为导致的数据的倾斜,也是很难预测的。通过 Alter Table 修改某个表的STATS_SAMPLE_PAGES的时候,会导致和 Analyze 这个 Table 一样的效果,会在表上加读锁,会阻塞表上的更新以及事务。所以不能在这种在线业务关键表上面使用。所以最好一开始就能估计出大表的量级,但是这个很难。
综上所述,我建议线上对于数据量比较大的表,最好能提前通过分库分表控制每个表的数据量,但是业务增长与产品需求都是不断在迭代并且变复杂的。很难保证不会出现大并且索引比较复杂的表。这种情况下需要我们,在适当调高 STATS_SAMPLE_PAGES 的前提下,对于一些用户触发的关键查询 SQL,使用 force index 引导它走正确的索引,这样就不会出现本文中说的因为 MySQL 优化器表采集数据的不准确导致的某些用户 id 查询走错索引的情况。
微信搜索“我的编程喵”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:
- 知乎:https://www.zhihu.com/people/zhxhash
- B 站:https://space.bilibili.com/31359187
