我是fancy,一个年纪轻轻bug量就累计到3200个的程序员,同事们都夸我一个人养活了整个测试组。
最近迷上了并发编程。并发这玩意怎么说呢,就是你平时工作用不到,一用就用在面试上。这不,又卷起了并发容器。
那说起并发容器,你一定也知道那几个,CopyOnWriteArrayList、并发队列BlockingQueue,等等。但是作为面试的典中典,聊到并发容器就无法绕开ConcurrentHashMap。
由于篇幅原因,这篇文章不会具体解释那些较为基础的问题,比如为什么散列表数组的长度一定要是2的n次方等。将更多围绕并发这个话题。如有需要,之后会另外讲解。
所以本文我们就来深入聊聊这个大厂面试青睐的对象,八股文里的兰博基尼:ConcurrentHashMap。

以下的技术点都基于JDK1.8~
基础回顾我们都知道,从JDK1.8起,ConcurrentHashMap底层的数据结构就已经从原来的Segment分段锁变为了数组 + 链表 + 红黑树的形态。
它是一款并发容器,一款装数据的容器在并发环境下铁定就会有各种各样的问题。你在单线程环境下玩单机,并发环境下就会有别的线程和你抢数据,抢桶位。因此编写JUC包的大神Doug Lea也都为这些场景一一做了适配,可以说是绝对的并发安全,至少运行了这么多年了也没遇到什么bug。
红黑树红黑树数据结构
JDK1.8这里的红黑树,准确的来说是一个TreeBin代理类,它作为红黑树的具体实现起存储作用,而TreeNode是封装红黑树的数据结构,所以你可以理解TreeBin就是封装TreeNode的一个容器。
红黑树在ConcurrentHashMap里面的体现是一个双向链表:

红黑树插入数据
在这里,红黑树维护一个字段dir。
在插入数据的时候会获取节点的hash值,从而与当前节点p的hash值比较,若插入节点的hash小于当前节点,则dir的值为-1,否则为1:
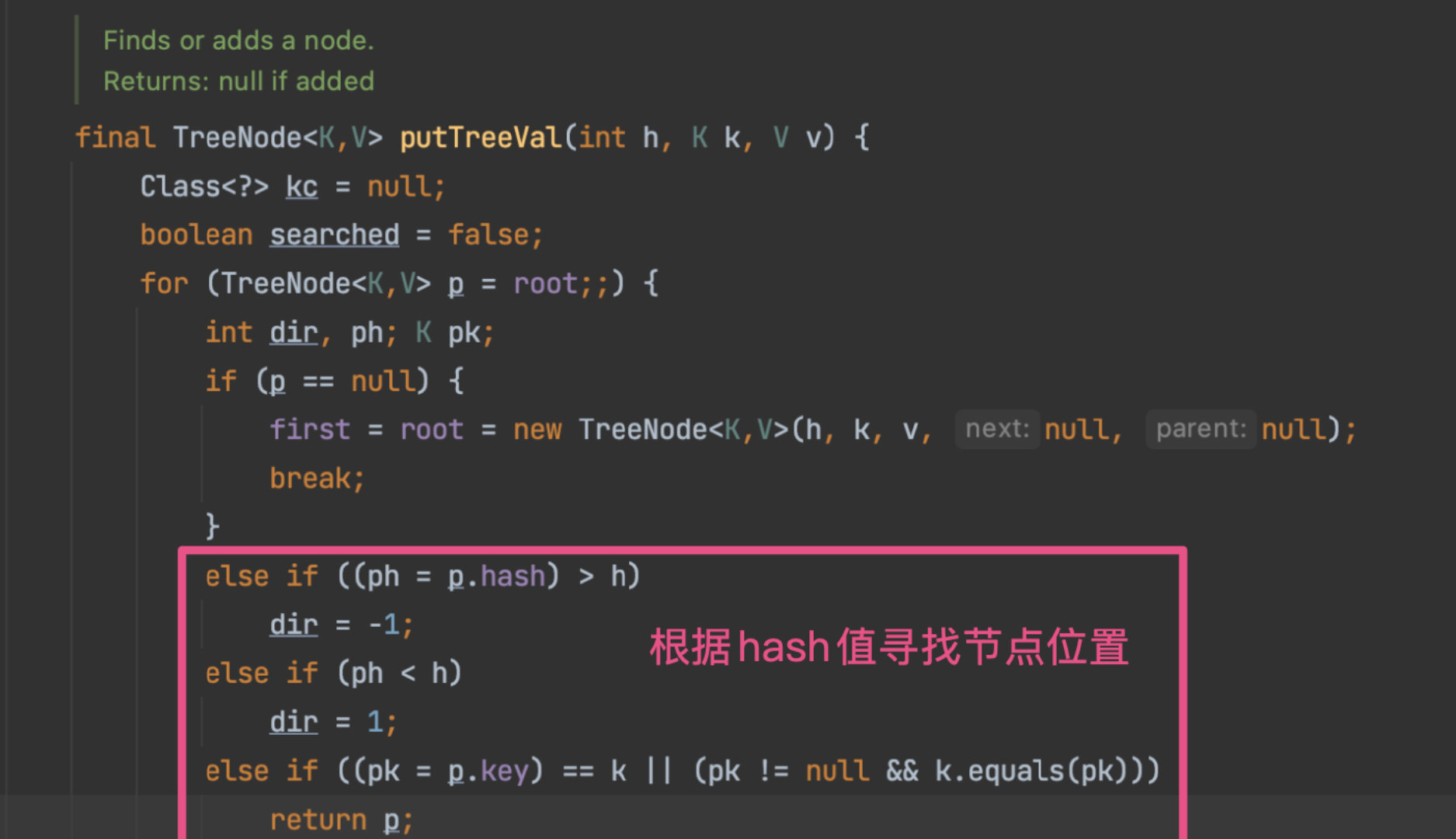
所以,当dir的值为-1时,就代表插入节点需要插入到当前节点的左子节点或者继续往左子树上查找,相反如果dir值为1则向右查找,这里的规则和二叉查找树的规则是一样的。
多线程竞争下的读写操作由于读操作本身就是天然线程安全的。所以多个线程对同一个桶位同时读并不会有什么问题。
但若是相互竞争的写操作,就是通过Synchronized锁的方式来保证某个桶位同一时刻只有一个线程能获取到资源。
通过源码可以看到,put()方法的核心是putVal():

putVal()很长,它主要是通过Synchronized去锁住每一个节点保证并发的安全性。在这里最为重要的两点,一是判断你put进去的这个元素,是处于链表还是处于红黑树上;二就是判断当前插入的key是否与链表或者红黑树上的某个元素一致。如果当前插入key与链表当中所有元素的key都不一致时,那么当前的插入操作就追加到链表的末尾。否则就替换掉key对应的value。
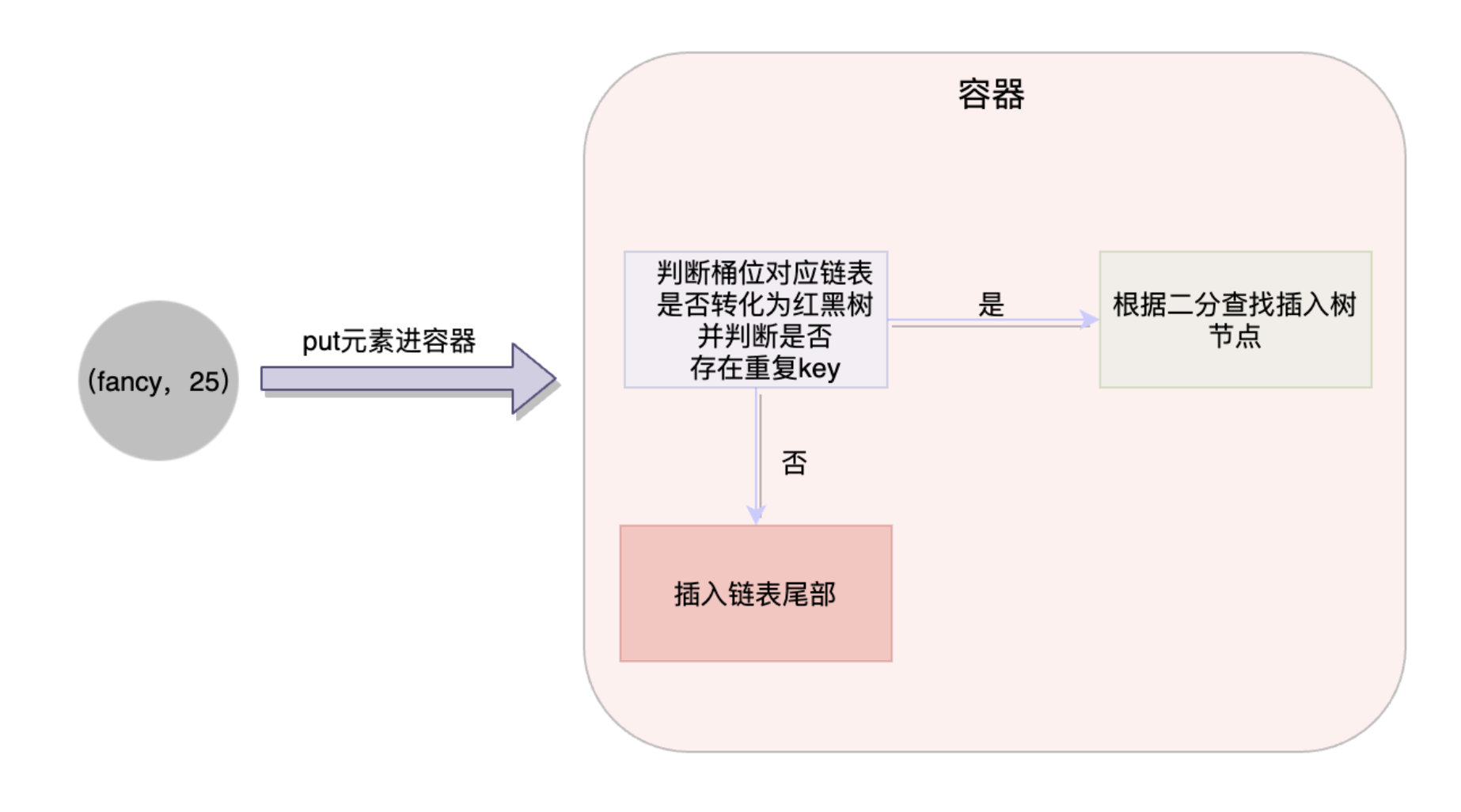
在知道扩容原理之前,得知道什么情况会导致扩容。
因此需要知道的两个重要字段:
- MIN_TREEIFY_CAPACITY : 数组初始长度,默认为64
- TREEIFY_THRESHOLD : 树化阈值,指定桶位链表长度达到8的话,就可能发生树化操作
线程往桶里面新增每一个元素,都会对链表的长度进行判断,只有元素个数大于阈值MIN_TREEIFY_CAPACITY并且链表长度大于8,才会调用treeifyBin()把链表转化为红黑树,否则就会进行扩容操作。
这里的扩容,指的就是扩大数组的桶个数,从而装下更多的元素。
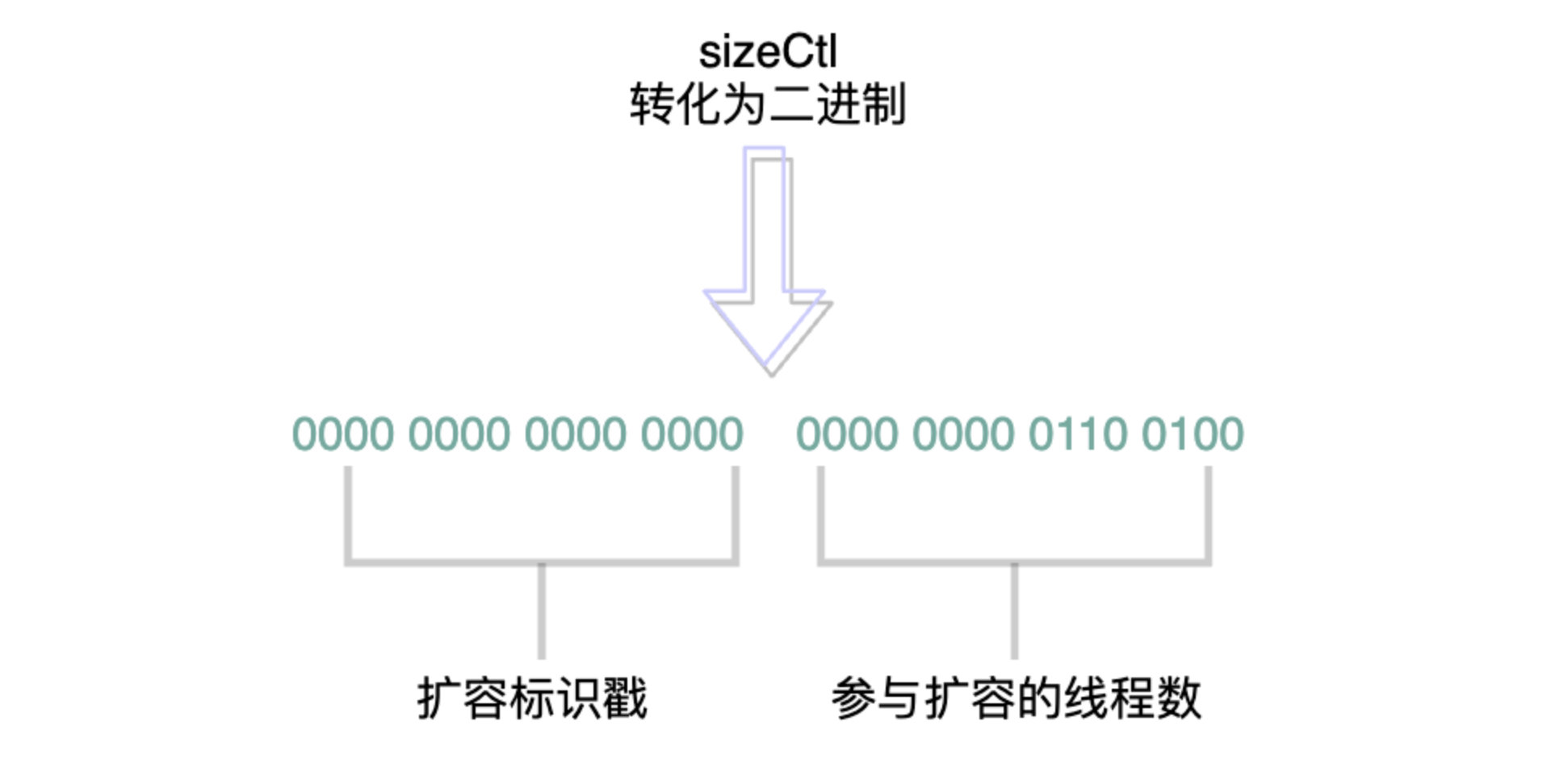
除此之外,扩容还维护了另一重要的字段,sizeCtl:

通过翻译,我们可以知道这个字段有三种状态:
- sizeCtl < 0:若为-1则起标记作用,告知其它线程此时正在初始化;若为其它的值表示当前table正在扩容
- sizeCtl = 0:表示创建table数组时还未进行扩容,没有指定的初始容量
- sizeCtl > 0:表示当table初始化后下次扩容的触发条件
字段的值可以转化为32位的二进制数值,它的高16位表示扩容标识戳,用来标识扩容的范围,如从长度16扩容到32;低16位表示当前参与扩容的线程数量。
扩容操作会新建一个长度更大的数组,然后将老数组上的元素全部迁移到新的数组去。
扩容的本质目的是为了减少桶位链表的长度,提高查询效率。因为链表的查询复杂度是O(n),如果链表过长就会影响查询效率。
假设桶位的长度从16扩容到32,说明桶位变多了,那迁移到新数组后就需要有元素去到新的桶位。这就需要通过一些算法将老数组和新数组的元素位置做一个映射。因为扩容后元素有的需要迁移到新的位置,有的还是处于和老数组一样的位置,只不过是换了一个数组。
如何计算出这个元素迁移后要呆在哪个桶位呢?这里使用了一个按位与的算法。就是将这个桶位key的hash值 & (扩容前数组长度 - 1),若生成的值等于0则不需要迁移,否则就要进行迁移。并且维护两个变量ln和hn代表是否需要进行位置迁移。然后采用尾插法将元素插入。这就是LastRun机制。
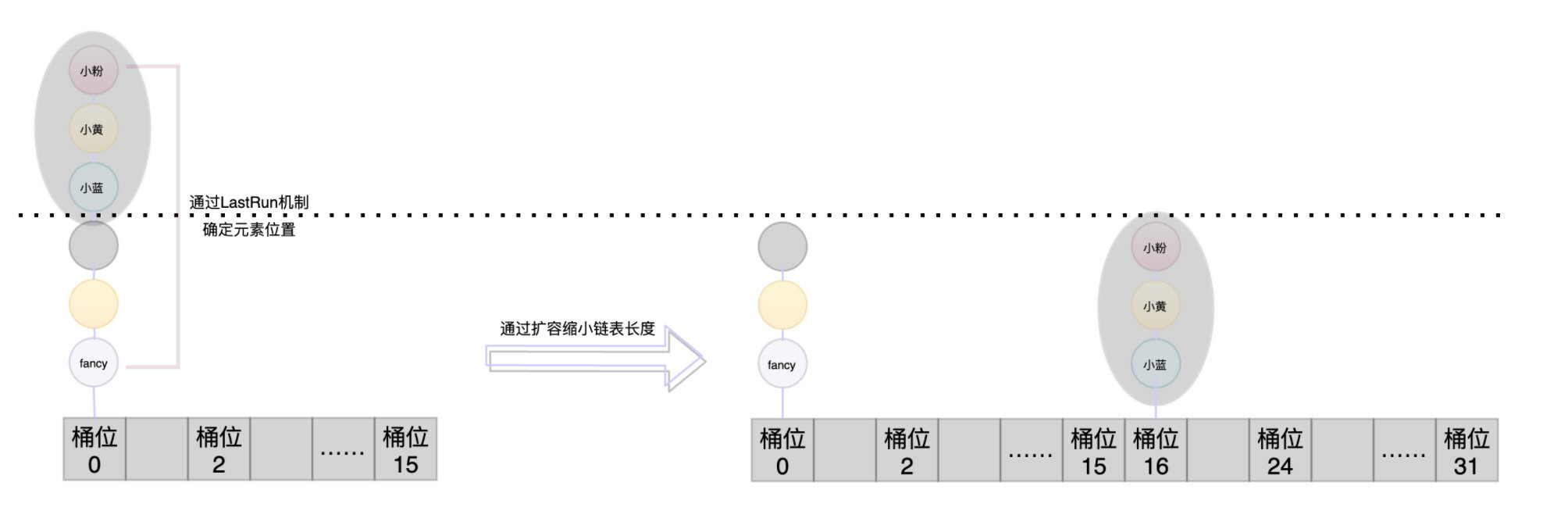
注:尾插法指的就是后面插入的元素都处于前一个元素的后面

这里简单普通的扩容是没什么问题的,大多数场景都和HashMap的扩容是一样的。
问题就在于当前是处于并发环境的,而扩容也需要时间。
正在扩容 && 有多个线程正在竞争所以,比较复杂的场景来了。若是桶位正在扩容,且有多个线程正在竞争读写咋办?厚礼谢
没关系,我们依然分情况来讨论。
扩容期间的读操作
如果扩容期间,有线程进行元素的读取,比如你去get()某个key的value,那读不读的到呢?
答案是可以。但是前提是你这个节点已经迁移结束,如果你是一个正在扩容迁移的节点,那就访问不到。
具体的操作,就是去调用find()。
当一个桶位要进行数据迁移,就会往这个桶位上放置一个ForwardingNode节点。除此之外还需要去标识这个节点是正在迁移还是已经迁移结束了的;
在这里我们统称迁移前的桶位节点叫老节点,迁移后的桶位节点叫新节点。当其中某一个节点迁移完成后,就会在老节点上添加一个fwd引用,它指向新节点的地址。
所以当某个线程访问了这个节点,看到它上面存在fwd引用,就说明当前table正在扩容,那么就会根据这个引用上的newtable字段去新数组的对应桶位上找到数据然后返回。

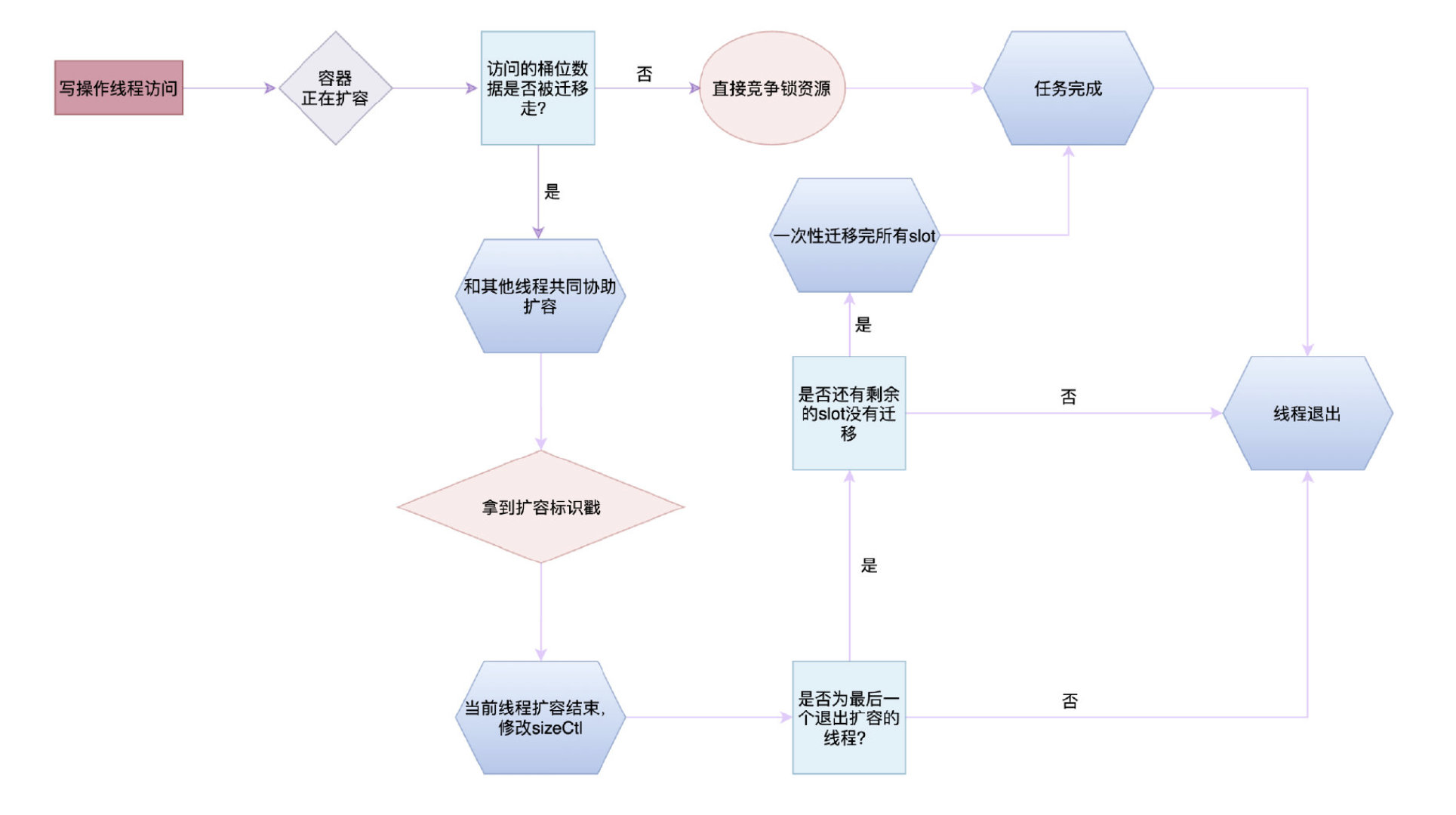
扩容期间的写操作
写操作相较于读操作会更加复杂一点,原因就是读操作只需要获取对应数据返回就行了,而写操作还要修改数据,所以当一个写线程来修改数据刚好碰到容器处于扩容期间,那么它还要协助容器进行扩容。
具体的扩容操作依然还要分情况,假如访问的桶位数据还没有被迁移走的话,那就直接竞争锁,然后在老节点上进行操作就行。
但是假如线程修改的节点正好是一个fwd节点,说明当前节点正处于扩容操作,那么为了节约线程数并且快速完成任务,当前线程就会进行协助扩容。如果有多个线程进行同时写,那么它们都会调用helpTransfer()进行协助扩容。
这里协助扩容的方式就是拿到一个扩容标识戳,这个标识戳的作用就是用来标识扩大的容量大小。因为每个线程都是独立的嘛,互不通信,但是它们要做的事情是相同的,就是将桶位扩大相同的值,所以它们就必须拿到这个相同的标识戳,只有标识戳一致才会进行扩容。
假设一个容器从16个桶位扩容到32个桶位,有线程A、B两个线程。
若A触发了扩容的机制,那么线程A就会进行扩容,此时线程B也来进行写操作,发现正在扩容就会进入到协助扩容的步骤中去。
所以线程A和线程B共同负责桶位的扩容。
一个线程负责扩容的桶位个数,是根据CPU核心数来算的。最少是16个,也就是一个线程最少要负责16个元素的扩容:
我们在上面有提过,sizeCtl转化为32位后,它的低16位是表示当前参与扩容的线程数量。所以当A线程触发了扩容之后,它就会将sizeCtl低16位的最后一位值+1,表示扩容线程多了一位,当它退出扩容时又会将最后一位的值-1,表示扩容线程少了一位,就这样各个线程共同维护这个字段。

所以你一定会好奇了:那我要是最后一个退出扩容的线程要怎么维护啊?是的,最后一个线程还有一些别的事情要做。当某一个线程完成任务后去判断sizeCtl的值得时候,发现它的低16位只剩下最后一位是1,再减下去就是0了,那就代表它是最后一个退出扩容的线程。此时它还需要去检查一遍老的table数组,判断是否还有遗漏的slot没有迁移。具体的操作就是去轮询检查是否还留有fwd节点,如果没有的话代表迁移完成,如果有的话还需要继续将它迁移到新的桶位:
由于源码非常长,所以我们就不贴全部源码了,通过流程图的方式来帮助大家理解这个扩容期间的操作:
有的童鞋在看Juc这一块的时候会去背诵源码,将方法的调用链都讲的头头是道,我认为没有必要,相反面试官可能会觉得你过于抽象,背的这么清楚。并发的核心在于如何用手段去解决可能遇到的安全问题,并且让它更高效点,面试的目的也是为了体现你思维能力。
如果觉得本文有所收获,可以点赞支持一下呀~
【本文由:阿里云代理 http://www.56aliyun.com 复制请保留原URL】