目录几年前搞过一段时间hadoop,现在又要开始搞了,发现环境都不会搭建了。写个博客记录下搭建过程。
- 1、创建虚拟机及规划
- 2、关闭防火墙
- 3、设置各主机之间免密登录
- 1、在每台主机hosts文件中添加IP与主机名的映射关系
- 2、设置互信(每台主机都执行)
- 4、安装JDK和hadoop
- 1、上传软件包
- 2、安装Java,设置环境变量
- 3、配置文件修改
- 4、将上述内容分别拷贝至hadoop2、hadoop3
- 5、启动服务
- 1、执行初始化命令
- 2、启动hadoop集群
- 3、启动yarn。
- 4、启动历史服务器.
- 默认配置
- 各个服务组件逐一启动/停止
下面是我本地的环境信息
- 修改机器名:
hostnamectl set-hostname [机器名] # hostnamectl set-hostname hadoop1
修改IP信息:
在
/etc/sysconfig/network-scripts/ifcfg-ens33文件中配置IP信息。主要修改如下几项。IPADDR="192.168.68.120" # IP地址 PREFIX="24" # 子网掩码位数,也可以设置为 NETMASK=255.255.255.0 GATEWAY="192.168.68.1" # 网关
规划
我们首先创建个名的
hadoop用户,后续所有操作如无特别说明,均是在hadoop用户下执行.adduser hadoop # 创建hadoop用户 passwd hadoop # 设置hadoop用户密码,回车后输入hadoop用户密码
2、关闭防火墙
在每台主机上用
root用户执行
systemctl stop firewalld # 停止防火墙
systemctl disable firewalld # 禁用防火墙开机启动
-
在每台主机
/etc/hosts文件中添加如下内容。/etc/hosts文件hadoop用户没有权限,所以修改这个文件要用root用户操作。192.168.68.120 hadoop1 192.168.68.121 hadoop2 192.168.68.122 hadoop3
-
在每台主机生成ssh公钥私钥,将公钥拷贝到所有主机(包括自己)。
ssh-keygen -t rsa #这里需要连续4个回车 ssh-copy-id hadoop1 ssh-copy-id hadoop2 ssh-copy-id hadoop3
1、上传软件包需要的软件是jdk和hadoop,我本次使用的是
jdk-11.0.10_linux-x64_bin.tar.gz、hadoop-3.2.3.tar.gz。我本地软件安装位置在
/home/hadoop/software这里的操作都是在hadoop1上执行,最后会拷贝到hadoop2、hadoop3上
-
创建安装目录
software目录mkdir /home/hadoop/software -
上传软件包
将
jdk-11.0.10_linux-x64_bin.tar.gz、hadoop-3.2.3.tar.gz上传到/home/hadoop/software目录中
- 解压java、hadoop
#在/home/hadoop/software目录中执行
tar -zxvf jdk-11.0.10_linux-x64_bin.tar.gz # 解压jdk
tar -zxvf hadoop-3.2.3.tar.gz # 解压hadoop
-
设置java环境变量
在
~/.bashrc文件中添加如下内容JAVA_HOME=/home/hadoop/software/jdk-11.0.10 CLASSPATH=.:$JAVA_HOME/lib PATH=$PATH:$JAVA_HOME/bin export JAVA_HOME CLASSPATH PATH export HADOOP_HOME=/home/hadoop/software/hadoop-3.2.3 export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin执行如下命令使环境变量生效
source ~/.bashrc
3.1 修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/core-site.xml
<!-- 指定HDFS中NameNode的地址,这里也就是指定了NameNode在hadoop1这个节点上-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/software/hadoop-3.2.3/data/tmp</value>
</property>
3.修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/hdfs-site.xml
<!-- 指定HDFS中NameNode的web端访问地址,这里的节点要和core-site的节点对应起来-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- 指定secondary节点主机配置 ,这里也就是指定了secondary节点在hadoop3-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:50090</value>
</property>
3.修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址,也就是指定resourcemanager所在的节点 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop3</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED _HOME</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop1:19888/jobhistory/logs</value>
</property>
修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址,也就是指定了历史服务器节点 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
修改/home/hadoop/software/hadoop-3.2.3/etc/hadoop/workers
hadoop1
hadoop2
hadoop3
scp -r /home/hadoop/software/jdk-11.0.10 hadoop2:/home/hadoop/software/
scp -r /home/hadoop/software/jdk-11.0.10 hadoop3:/home/hadoop/software/
scp -r /home/hadoop/software/hadoop-3.2.3 hadoop2:/home/hadoop/software/
scp -r /home/hadoop/software/hadoop-3.2.3 hadoop3:/home/hadoop/software/
scp ~/.bashrc hadoop2:~/
scp ~/.bashrc hadoop3:~/
5、启动服务 1、执行初始化命令如果在执行这一步之前已经使用hdoop用户登录了hadoop2或者hadoop3,为了使上面拷贝的环境变量生效,需要在
hadoop2,hadoop3上分别执行
source ~/.bashrc命令
在hadoop1节点上执行
hdfs namenode -format #只在namenode节点执行
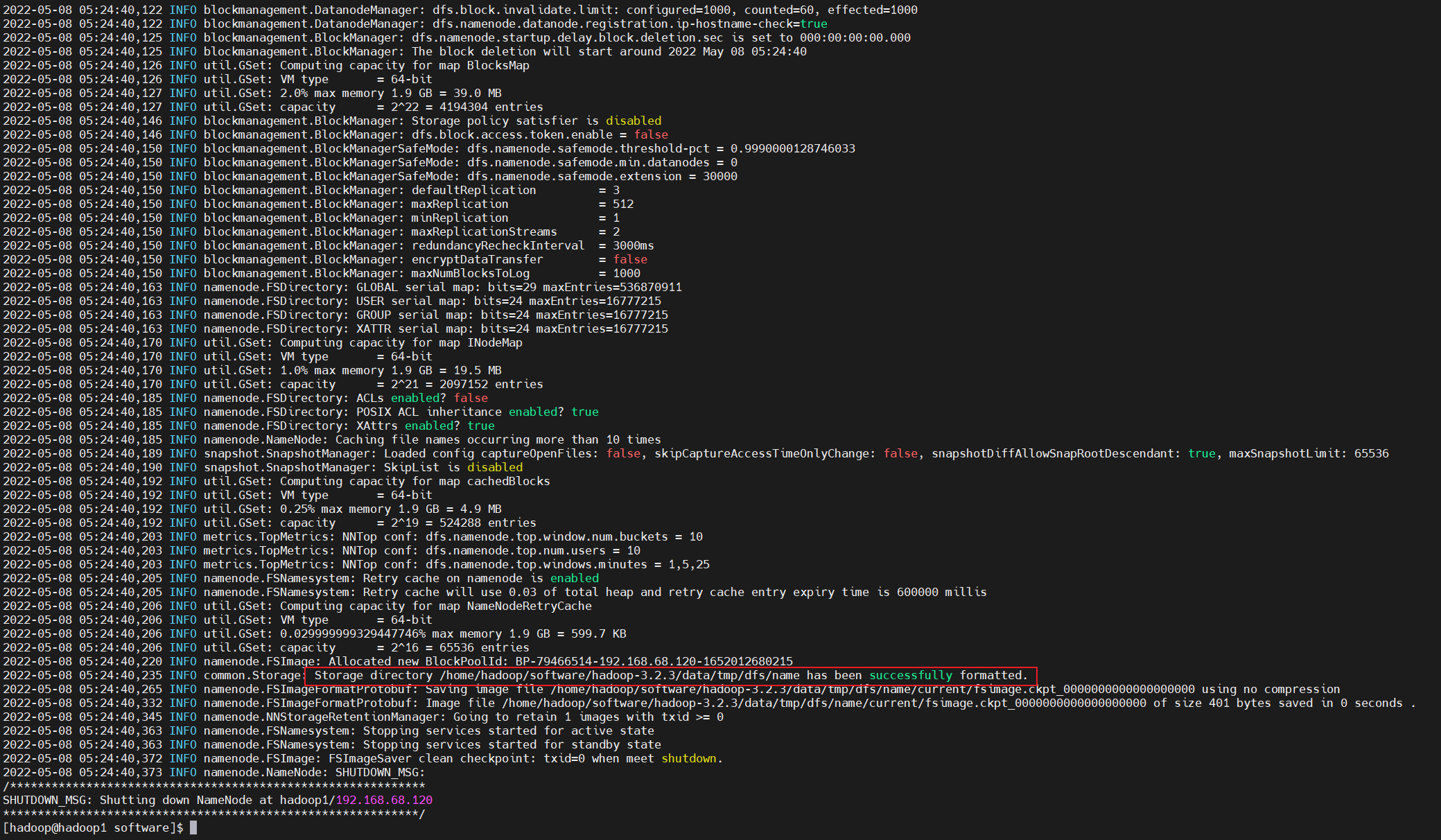
看到上面这句就表示执行成功。
2、启动hadoop集群在hadoop1节点上执行如下命令
start-dfs.sh # 需要在namenode节点上执行

分别在每台主机执行jps命令检查进程是否启动正常

同时也可以通过web界面进行访问http://192.168.68.120:9870/dfshealth.html#tab-overview
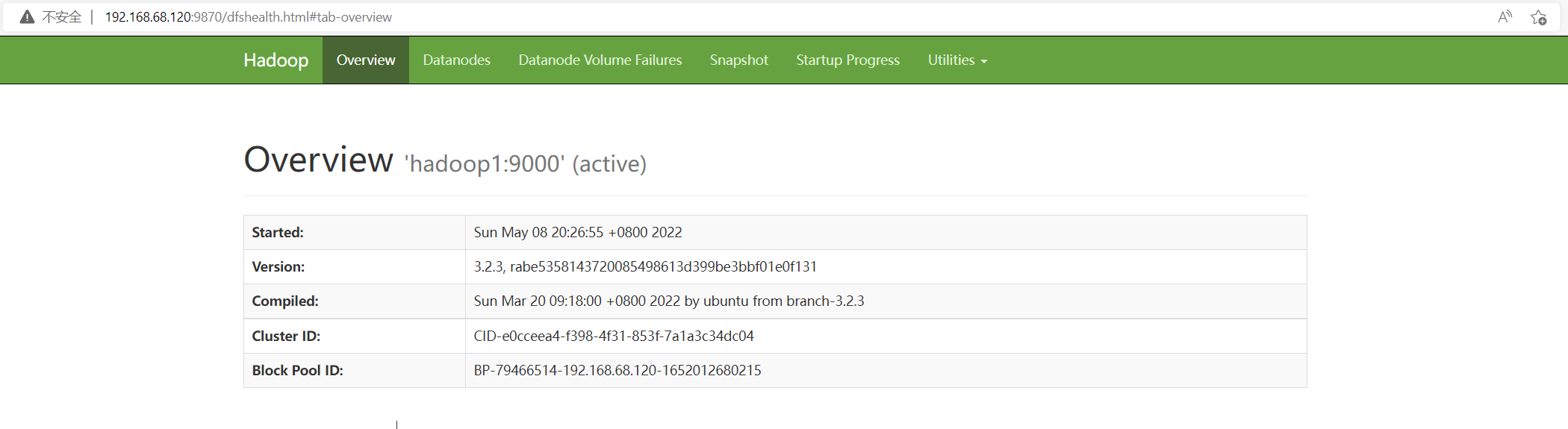
在hadoop3 节点上实行如下命令
start-yarn.sh #注意这个需要在yarn所在节点启动(`yarn-site.xml`中`yarn.resourcemanager.hostname`属性指定)。
再次通过检查每台主机进程是否启动正常

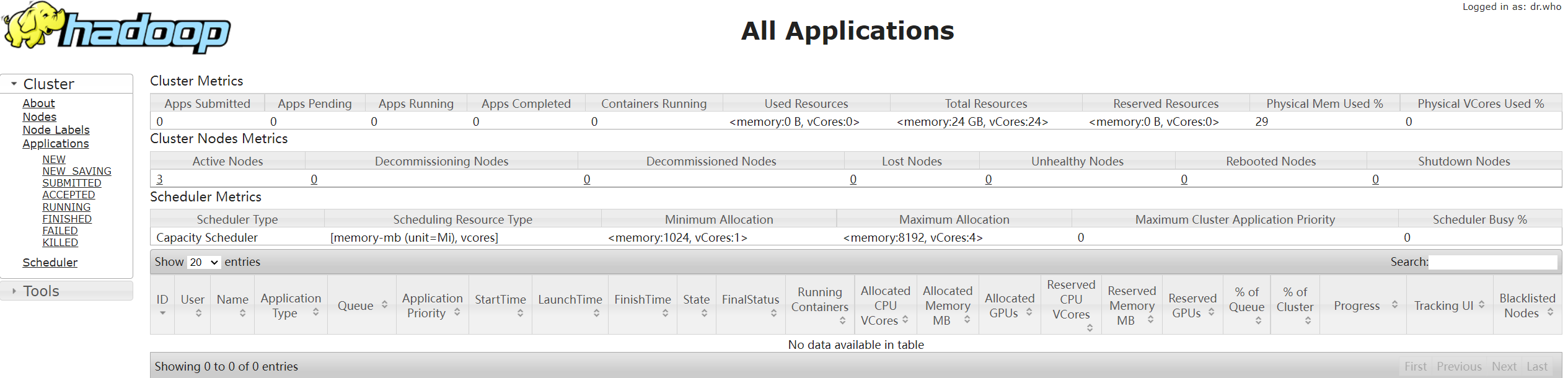
也可以通过web界面进行访问http://192.168.68.122:8088/cluster
在hadoop1节点上执行如下命令。(通过mapred-site.xml配置文件中指定)
mapred --daemon start historyserver

到这里,整个hadoop集群就已经搭建完成了。
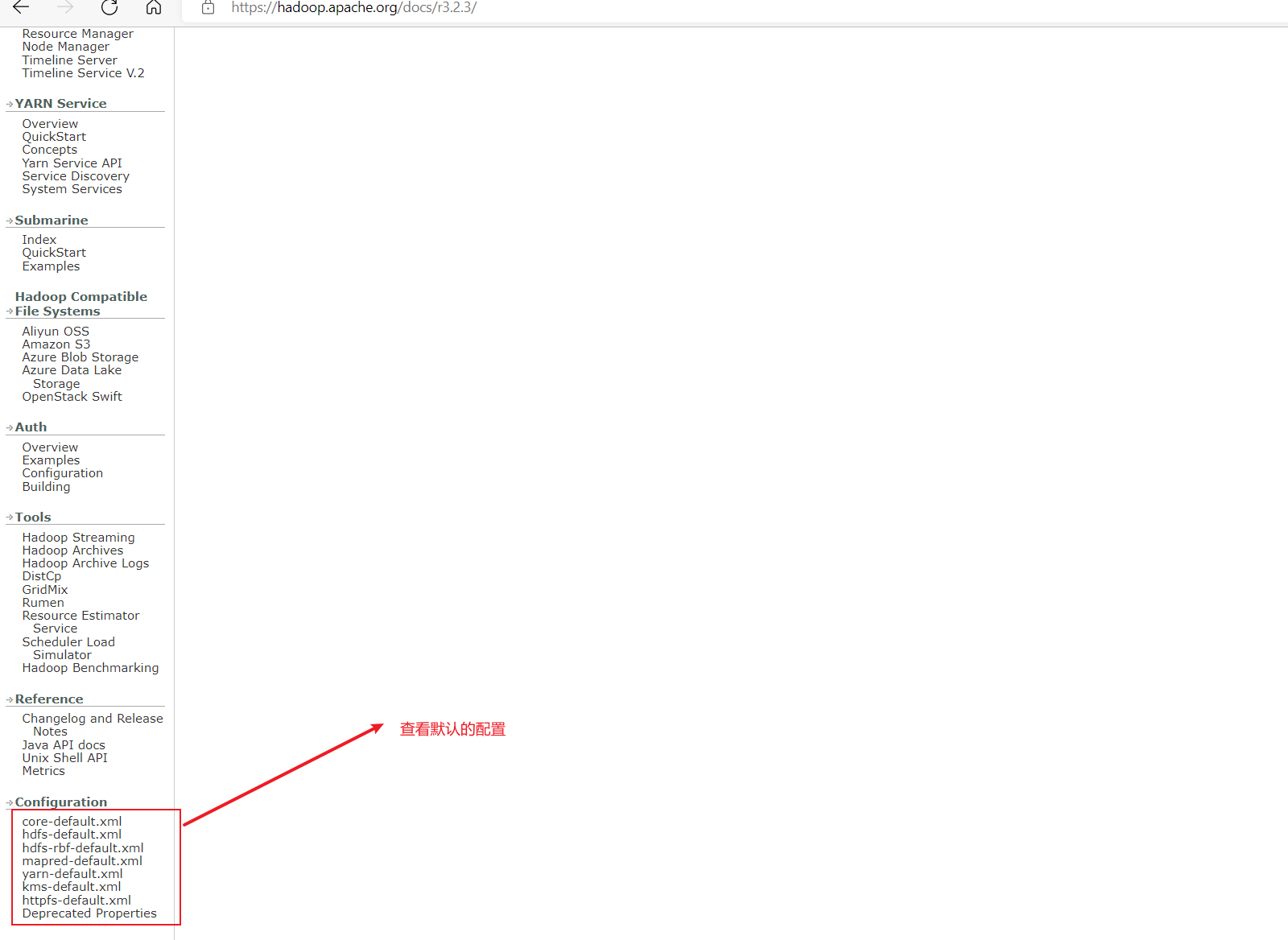
默认配置hadoop很多配置都有默认配置。具体可以通过官网文档查看。具体位置Index of /docs (apache.org),在这里找到对应版本。
各个服务组件逐一启动/停止(1)分别启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode(2)启动/停止 YARN
yarn --daemon start/stop resourcemanager/nodemanager