分布式锁的特性通过互斥性质,来保证线程对分布式系统中共享资源的有序访问
说人话:一把锁,挨个进
-
互斥(线程独享):即同一时刻只有一个线程能够获取锁
-
避免死锁:获得锁的线程崩溃后,不会影响后续线程获取锁,操作共享资源
-
隔离性:A获取的锁,不能让B去解锁(解铃还须系铃人)
-
原子性:加锁和解锁必须保证为原子操作
-
基于Redis
演变过程:
V-1.0:
SETNX:Redis提供了SETNE(SET if Not eXists)命令,表示当Key不存在时,才能设置Value,否则设置失败(获取锁失败)
DEL KEY:第一步获取锁成功,对共享资源操作完后,释放锁
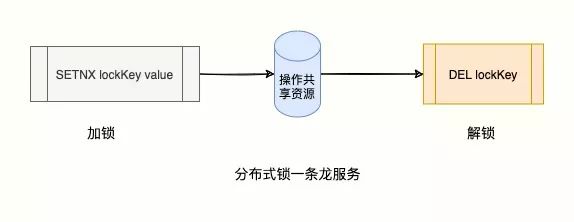
问题:
如果业务代码出现异常,阻塞或者报错了,那么该线程就一直持有锁,不释放,其他线程也永远获取不到————我王霸天得不到的谁也别想得到!V-2.0:
- SETNX+EXPIRE:给锁上过期时间,假如持有锁线程崩溃了,达到设置的过期时间后,会自动释放锁,避免后续线程获取不到锁!
问题:仍旧会死锁!SETNX和EXPIRE是两条命令,Redis单命令是原子操作,但多条命令为非原子操作!
SETNX执行成功,EXPIRE失败时就会发生死锁v-3.0:
- SET(NX+EX)(2.6.12版本之后):获取锁,并设置锁过期时间(
原子操作)如此,可以说是
彻底解决了死锁问题!
那么还问存在其他问题吗?
分析分布式锁的特征:互斥、死锁、原子等特性,我们都算是解决了!
但还未考虑隔离性的问题!
场景
- 线程A加锁成功后,去操作共享资源
- 但是因为发生了意外,线程A操作的时间超过了锁过期时间,锁被释放了
- 线程B进来了,枷锁成功,去操作共享资源了
- 此时,线程A操作完成了,回来释放锁,线程B的锁被A释放(
动了别人的老婆!)
隔离性带来的问题:
-
锁的过期时间设置不合理,导致线程A锁过期,被释放
-
线程A释放了线程B的锁
-
线程A的过期时间设置不合理,那就换一个合理的时间————对应到现实工作中,就是根据程序员的工作经验,对改值进行较为合理的设置,实在不行,杀了祭天!(不是很可靠)
-
其实很简单,锁过期就像去麦当劳喝咖啡喝完了呗,还想喝怎么办?续杯!————获取锁时,先设置一个过期时间,同时,开启一个守护线程,定时去查看锁的剩余存活时间,假如锁的存活时间快过期了,但业务代码还没执行完,赶紧去给大爷续杯,即重新设置过期时间(看门狗)
-
至于第二个问题,还是那句老话————解铃还须系铃人,加一个业务唯一标识,每个线程只能根据业务唯一去释放自己的锁,同时,需要注意:判断是否为自己的锁和删除锁
应为原子操作!不然仍旧会删错锁!
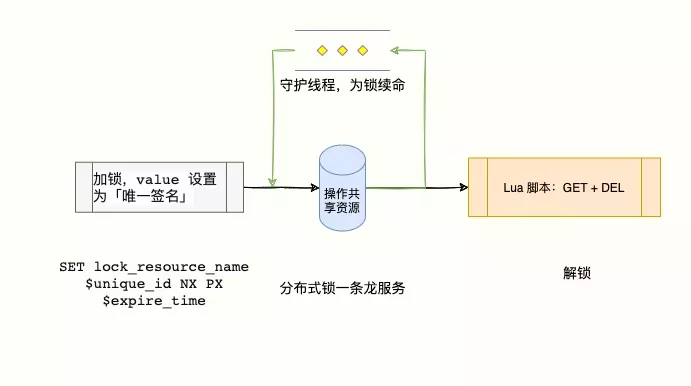
实现
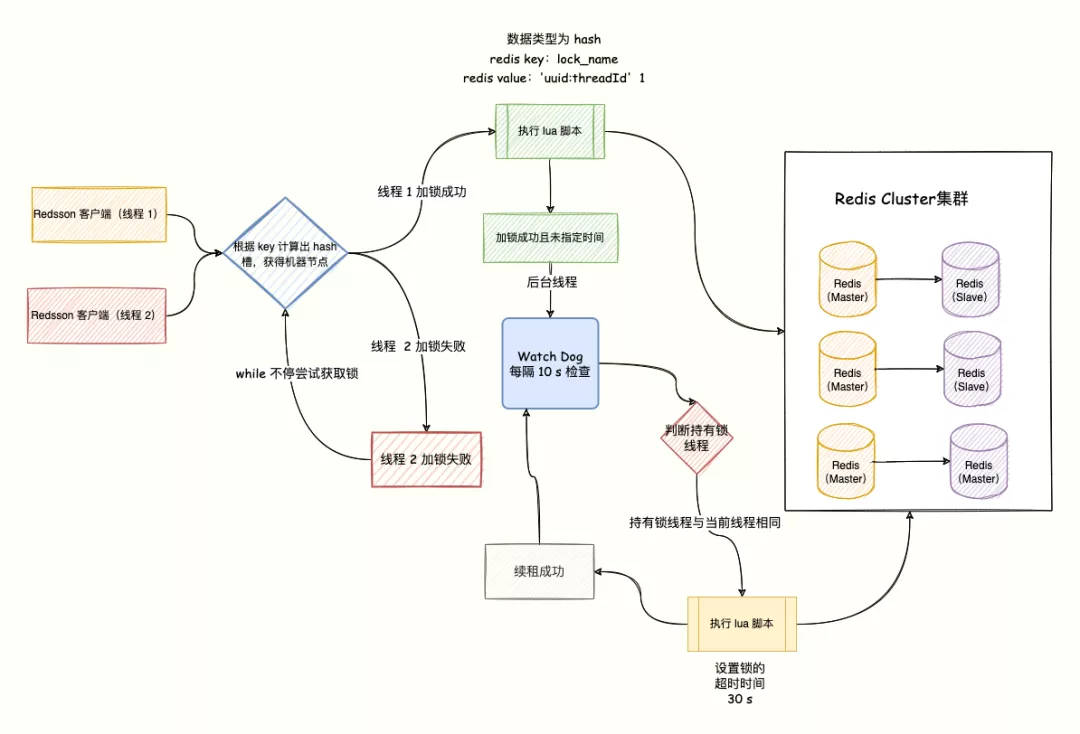
- Redission的看门狗(基于Netty时间轮算法实现):
private long lockWatchdogTimeout = 30 * 1000;
public RedissonLock(CommandAsyncExecutor commandExecutor, String name) {
super(commandExecutor, name);
this.commandExecutor = commandExecutor;
//会获取看门狗设置的时间,默认为10s检查一次,锁过快过期,且业务代码还没执行完,就会给锁续上这个时间,默认30s
this.internalLockLeaseTime = commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout();
this.pubSub = commandExecutor.getConnectionManager().getSubscribeService().getLockPubSub();
}
private RFuture<Boolean> tryAcquireOnceAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
//如果锁是永不过期,那么就按常规方式索取锁
if (leaseTime != -1) {
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_NULL_BOOLEAN);
}
//否则,会在获取锁之后,加一个定时任务,在锁执行完业务代码自行释放之前,不断的给所续上过期时间(默认10s检查一次,每次给锁续期30s)
RFuture<Boolean> ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_NULL_BOOLEAN);
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// lock acquired
if (ttlRemaining) {
scheduleExpirationRenewal(threadId);
}
});
return ttlRemainingFuture;
}
实现具体细节,参见Redission源码
- 线程隔离的问题:
考虑到获取锁判断后,再删除锁,这两个操作必须是原子性的,那么就需要查看一下Redis的API有没有提供这两个操作的原子性操作了
结果发现,没有!那么叫考虑第二种方案,在Redis中除了单条命令是原子性的,还有执行Lua脚本也是原子性操作!
//如果是自己的锁,则进行删除,否则返回
if redis.call("GET",KEY[1]) == ARGV[1] then
return redis.call("DEL",KEY[1])
else
return 0
end
小总结
经过了这几波优化之后,基于Redis的分布式锁(
Redis单实例),可算是安全放心大胆的使用了!悄悄的告诉你,其实我们这些优化过程Redis作者早就想到了,同时,他也提供了较为完善的解决方案,在工作中Redission可以实现以上所有!
作为技术宅男,要有极客精神(其实就是闲了无聊),有心的人,可能会发现,以上粉色标粗的Redis单实例字样,确实!以上分析的分布式锁适合单节点的Redis实例,如果遇到主从+哨兵的模式基本凉凉!
- 线程A在遇到主从架构时,先在Master上加锁成功
- 此时,还未等加锁命令SET同步到Slave上,Master就出现问题,宕机了!
- 通过哨兵过半原则,重新选出新的主节点,那么此时这把锁在新的主库上是找不到的!出现新问题了!
遇到这种情况是不是就完了!芭比Q了!准备提桶跑路了!


如果一遇到这种问题,就要程序员提桶跑路,那么Redis的作者恐怕在大佬圈是混不下去了!于是,他苦心钻研,誓死捍卫Redis尊严!于是乎它就出世了!————RedLock
要求:
原理:1. 主节点至少5个实例多主部署
2. 不再需要从节点和哨兵
疑问:1. 加锁线程带着Expire时间进入,在加锁前记录一个开始加锁时间T1
2. 轮流用相同的key和value在不同的节点上进行加锁操作,并且必须保证大多数(N/2+1)节点加锁成功,才算成功
3. 最少(N/2+1)个节点加锁成功后,记录当前时间T2
4. 如果T2-T1 < Expire,则加锁成功,反之失败
5. 释放锁时,要向所有节点(不管是否在该节点加锁成功)发送解锁请求!
6. 此时,锁的Key真正有效时间为:Expire - (T2-T1)
7. 部署的节点数最好是奇数,以更好的满足过半原则
分析:
- 为什么是N/2+1个节点加锁?
- 加锁成功后,计算加锁耗时的意义?
- 为什么释放锁时,要给所有节点(包括没有加锁成功的节点)发送解锁请求?
- N/2+1公式为过半原则,这里的本质时为了容错,CAP中的P说到,当分布式系统中,如果存在部分故障节点,但大多数节点仍旧正常时,可以认为整个系统仍旧可用
- 假如T2-T1 > Expire 就意味着一定会存在,最早加锁的节点过期自动解锁的情况,那么此时的加锁节点计数就不再正确!那么此次加锁就毫无意义了!(T2-T1为加锁时间,Expire为过期时间)
- 假设某节点加锁成功了,但是后续因为其他原因(网络)导致无法从该节点上获取响应结果,而被判断为未成功加锁,如果只给加锁成功的节点发起解锁请求,那么此时该节点是收不到解锁请求的,就会一直持有,影响后续无法使用
理性看待
其实,Redis作者研究出来的RedLock,在一些极端的情况下是存在风险的,比如:
- N节点的时钟存在较大偏差时,T2-T1 < Expire的讨论就是毫无意义的,依然存在琐失效的问题,想要解决这个问题,就得需要人工的去维护N节点之间的时钟趋于一致
- RedLock仍旧解决不了获得锁的线程客户端发生长时间GC,导致锁过期,如果再出现第二个线程仍旧可以获取锁,此时,就会出现同一时刻两个线程对共享资源同时获得锁的矛盾情况,严重违反分布式锁特性中的互斥性
- 因为RedLock无法提供类似fencing token的设计方案,从而推导出RedLock无法保证分布式的正确性
神仙打架局:
以上观点来自于业界大佬 Martin 对RedLock的质疑:https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
同时,Redis作者 Antirez 也作出了回复:http://antirez.com/news/101
- 基于Zookeeper
-
利用节点名称唯一性
原理
- 加锁时,所有线程均在相同的目录下创建一个文件,谁先创建成功,就代表获得锁,否则就代表失败,只能等待下次
- 当获取得锁的线程操作完业务代码后,会将该文件删除,同时通知其余客户端再次进入竞争
- 在一个路径下只能创建一个唯一的文件(文件名唯一),但容易引起“
惊群”效应
-
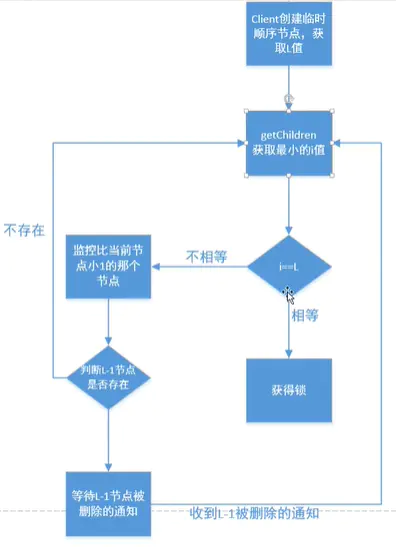
利用临时顺序节点
原理
- 所有线程刚开始都会在ZK中创建自己的临时节点,由ZK去保证这些节点的顺序
- 加锁时,线程会
判断ZK下的第一个节点是不是自己创建的,如果是,则加锁成功,如果不是,加锁失败,同时,给自己的上一个节点加一个节点监听器- 当节点监听器被通知上一个节点被删除时,当前节点会重新判断ZK下第一个节点是否是自己创建的,循环2的判断操作
- 用完锁后,每个线程只能删除自己创建的临时节点
- 二者对比
-
效率:ZK锁远不如Redis锁
-
失败处理:
ZK锁只需要维护
Watch监听器,等待锁被释放
Redis锁则是自旋重试,高并发时耗性能 -
宕机处理:
ZK是根据客户端上报心跳(长连接),判断客户端是否存在(持有锁),无心跳上报时,会删除节点(释放锁)————
(客户端长GC时,锁会被ZK释放)
Redis则是需要等到过期时间,才会释放锁
市面上常见的分布式锁,基本上都研究了一下,感觉收获颇丰!当然这些都是理论,光说不练假把式,下一篇就是分布式锁的实现大合集!期待!