在什么是操作系统这篇文章中,介绍过操作系统像是一个代理一样,为我们去管理计算机的众多硬件,我们需要计算机的一些计算服务、数据管理的服务,都由操作系统提供接口来完成。这样做的好处是让一般的计算机使用者不用关心硬件的细节。
1. 什么是操作系统的接口既然使用者是通过操作系统接口来使用计算机的,那到底是什么是操作系统提供的接口呢?
接口(interface)这个词来源于电气工程学科,指的是插座与插头的连接口,起到将电与电器连接起为的功能。后来延伸到软件工程里指软件包向外提供的功能模块的函数接口。所以接口是用来连接两个东西、信号转换和屏蔽细节。
那对于操作系统来说:操作系统通过接口的方式,建立了用户与计算机硬件的沟通方式。用户通过调用操作系统的接口来使用计算机的各种计算服务。为了用户友好性,操作系统一般会提供两个重要的接口来满足用户的一些一般性的使用需求:
- 命令行:实际是一个叫
bash/sh的端终程序提供的功能,该程序底层的实质还是调用一些操作系统提供的函数。 - 窗口界面:窗口界面通过编写的窗口程序接收来自操作系统消息队列的一些鼠标、键盘动作,进而做出一些响应。
对于非一般性使用需求,操作系统提供了一系列的函数调用给软件开发者,由软件开发者来实现一些用户需要的功能。这些函数调用由于是操作系统内核提供的,为了有别于一般的函数调用,被称为系统调用。比如我们使用C语言进行软件开发时,经常用的printf函数,它的内部实际就是通过write这个系统调用,让操作系统内核为我们把字符打印在屏幕上的。
为了规范操作系统提供的系统调用,IEEE制定了一个标准接口族,被称为POSIX(Portable Operating System Interface of Unix)。一些我们熟悉的接口比如:fork、pthread_create、open等。
计算机硬件资源都是操作系统内核进行管理的,那我们可以直接用内核中的一些功能模块来操作硬件资源吗?可以直接访问内核中维护的一些数据结构吗? 当然不行!有人会说,为什么不行呢?我买的电脑,内核代码在内存中,那内存不都是我自己买的吗?,我自己不能访问吗?
现在我们运行的操作系统都是一个多任务、多用户的操作系统。如果每个用户进程都可以随便访问操作系统内核的模块,改变状态,那整个操作系统的稳定性、安全性都大大降低了。
为了将内核程序与用户程序隔离开,在硬件层面上提供了一次机制,将程序执行的状态分为了不同的级别,从0到3,数字越小,访问级别越高。0代表内核态,在该特权级别下,所有内存上的数据都是可见的,可访问的。3代表用户态,在这个特权级下,程序只能访问一部分的内存区域,只能执行一些限定的指令。
操作系统在建立GTD表的时候,将GTD的每个表项中的2位(4种特权级别)设置为特权位(DPL),然后操作系统将整个内存分为不同的段,不同的段,在GDT对应的表项中的DPL位是不同的。比如内核内存段的所有特权位都为00。而用户程序访存时,在保护模式下都是通过段寄存器+IP寄存器来访问的,而段寄存器里则用两位表示当前进程的级别(CPL),是位于内核态还是用户态。
既然如此,那我们还有什么办法可以调用操作系统的内核代码呢?操作系统为了实现系统调用,提供了一个主动进入内核的惟一方式:中断指令int。int指令会将GDT表中的DPL改为3,让我们可以访问内核中的函数。所以所有的系统调用都必须通过调用int指令来实现,大致的过程如下:
- 用户程序中包含一段包含int指令的代码
- 操作系统写中断处理,获取相调程序的编号
- 操作系统根据编号执行相应的代码
下面我们以printf函数的调用为例,说明该函数是如何一步一步最终落在内核函数上去的。
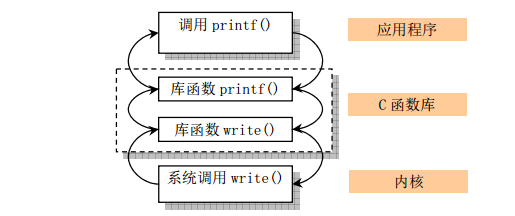 图1:应用程序、库函数和内核系统调用之间的关系
图1:应用程序、库函数和内核系统调用之间的关系
printf函数是C语言的一个库函数,它并不是真正的系统调用,在Unix下,它是通过调用write函数来完成功能的。
write函数内部就是调用了int中断。一般的系统调用都是调用0x80号中断。而操作系统中一般不会的显式的写出write的实现代码,而是通过_syscall3宏展开的实现。_syscall3是专门用来处理有3个参数的系统调用的函数的实现。同理还有_syscall0、_syscall1和_syscall2等,目前最大支持的参数个数为3个,这三个参数是通过ebx, ecx,edx传递的。如果有系统调用的参数超过了3个,那么可以通过一个参数结构体来进行传递。
// linux/lib/write.c
#define __LIBRARY__
#include <unistd.h>
//
_syscall3(int,write,int,fd,const char *,buf,off_t,count)
// linux/include/unistd.h
#define _syscall3(type,name,atype,a,btype,b,ctype,c) \
type name(atype a,btype b,ctype c) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a)),"c" ((long)(b)),"d" ((long)(c))); \
if (__res>=0) \
return (type) __res; \
errno=-__res; \
return -1; \
}
所以宏展开后,write函数的实现实现为:
int write(int fd, const char *buf, off_t count)
{
long __res;
__asm__ volatile ("int $0x80"
: "=a" (__res)
: "0" (__NR_write),"b" ((long)(a)),"c" ((long)(b)),"d" ((long)(c)));
if (__res>=0)
return (type) __res;
errno=-__res;
return -1;
}
我们看到实际函数内部并没有做太多的事情,主要就是调用int 0x80,将把相关的参数传递给一些通用寄存器,调用的结果通过eax返回。其中一个很重要的调用参数是__NR_write这个也是一个宏,就是wirte的系统调用号,在linux/include/unistd.h中被定义为4,同样还有很多其他系统调用号。因为所有的系统调用都是通过int 0x80,那怎么知道具体需要什么功能呢,只能通过系统调用号来识别。
下面我们来看看int 0x80是如何执行的。这是一个系统中断,操作系统对于中断处理流程一般为:
- 关中断:CPU关闭中段响应,即不再接受其它外部中断请求
- 保存断点:将发生中断处的指令地址压入堆栈,以使中断处理完后能正确地返回。
- 识别中断源:CPU识别中断的来源,确定中断类型号,从而找到相应的中断服务程序的入口地址。
- 保护现场所:将发生中断处理有关寄存器(中断服务程序中要使用的寄存器)以及标志寄存器的内存压入堆栈。
- 执行中断服务程序:转到中断服务程序入口开始执行,可在适当时刻重新开放中断,以便允许响应较高优先级的外部中断。
- 恢复现场并返回:把“保护现场”时压入堆栈的信息弹回原寄存器,然后执行中断返回指令(IRET),从而返回主程序继续运行。
前3项通常由处理中断的硬件电路完成,后3项通常由软件(中断服务程序)完成。
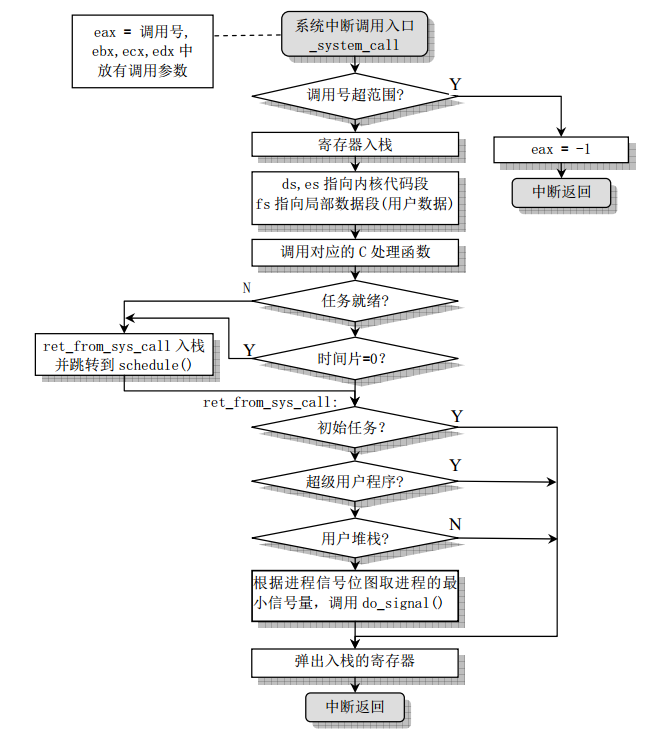 图2:系统调用中断处理流程
图2:系统调用中断处理流程
那0x80号中断的处理程序是什么呢,我们可以看一下操作系统是如何设置这个中断向量表的。在操作系统初始化时shecd_init函数里,调用了
set_system_gate(0x80, &system_call);
我们深入看一下set_system_gate函数做了什么
#define _set_gate(gate_addr,type,dpl,addr) \
__asm__ ("movw %%dx,%%ax\n\t" \
"movw %0,%%dx\n\t" \
"movl %%eax,%1\n\t" \
"movl %%edx,%2" \
: \
: "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \
"o" (*((char *) (gate_addr))), \
"o" (*(4+(char *) (gate_addr))), \
"d" ((char *) (addr)),"a" (0x00080000))
#define set_system_gate(n,addr) \
_set_gate(&idt[n],15,3,addr)
通过上面的代码,我们可以看出,set_system_gate把第0x80中断表的表项中中断处理程序入口地址设置为&system_call。并且把那一项IDT表中的DPL设置了为3, 方便用户程序可以去访问这个地址。
所以init 0x80最终会被system_call这个函数地址处的代码来实际处理。让我们看下system_call做了什么事情。
# linux/kernel/system_call.s
nr_system_calls=72 # 最大的系统调用个数
.globl _system_call
system_call:
cmpl $nr_system_calls-1,%eax # eax中放的系统调用号,在write的调用过程中为__NR_write = 4
ja bad_sys_call
push %ds # 下面是一些寄存器保护,后面还要弹出
push %es
push %fs
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call
movl $0x10,%edx # set up ds,es to kernel space
mov %dx,%ds # 把ds的段标号设置为0001 0000(最后2位是特权级),所以段号为4,内核态数据段
mov %dx,%es
movl $0x17,%edx # 把fs的段标号设置为0001 0111(最后2位是特权级),所以段号为5,用户态数据段
mov %dx,%fs
call sys_call_table(,%eax,4) # 实际的系统调用
pushl %eax
movl current,%eax
cmpl $0,state(%eax) # state 检测是否为就绪状态
jne reschedule # 进入调度程序
cmpl $0,counter(%eax) # counter 查看信号状态
je reschedule
ret_from_sys_call:
movl current,%eax # task[0] cannot have signals
cmpl task,%eax
je 3f
cmpw $0x0f,CS(%esp) # was old code segment supervisor ?
jne 3f
cmpw $0x17,OLDSS(%esp) # was stack segment = 0x17 ?
jne 3f
movl signal(%eax),%ebx
movl blocked(%eax),%ecx
notl %ecx
andl %ebx,%ecx
bsfl %ecx,%ecx
je 3f
btrl %ecx,%ebx
movl %ebx,signal(%eax)
incl %ecx
pushl %ecx
call do_signal
popl %eax
3: popl %eax
popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret
我们可以发现,上面代码中大部分代码是寄存器状态保存与恢复,堆栈段的切换。核心代码为call sys_call_table(,%eax,4),它是一个函数调用,函数的地址为sys_call_table(,%eax,4) = sys_call_table + 4*%eax 说明sys_call_table为一个数组入口,数组中的元素长度都为4个字节,我们要访问数组中的第%eax个元素。而%eax即为系统调用号。sys_call_table就是所有系统调用的函数指针数组。
// 定义在 linux/include/linux/sys.h
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid };
到这里,我们找到了最终真正的执行核心函数地址sys_write,这个是操作实现的内核代码,所有的屏幕打印就是由该函数最终实现。它里面涉及IO的一些硬件驱动函数,我们在这里就不再继续深入了。
到此,我们已经通过printf这样一个上层的函数接口,清楚操作系统是如何一步步为了我们提供了一个内核调用的方法。如此的精细控制,让人感叹。
4. 我们如何为操作系统添加一个系统调用下面简单说明一下,如何在操作系统源码中添加两个我们自己的系统调用whoami和iam
- iam系统调用把我们指定的一个字符串保存在内核中。
- whoami把内核中的通过iam设置的那个字符串读取出来。
下面是具体的操作步骤。
- 在linux/kernel文件夹加入一个自定义的文件who.c
- 在who.c中实现sys_iam和sys_whoami,需要注意的实现这两个函数时,需要用于用户栈数据与内核栈数据拷贝。
- 在linux/include/linux/sys.h中的sys_call_table中添加两个数组项。
- 修改linux/kernel/system_call.s中的系统调用个数nr_system_calls。
- 用int 0x80实现iam和whoami函数。
- 编写用户程序调用上面两个函数。
要注意的是:在系统调用的过程中,段寄存器ds和es指向内核数据空间,而fs被设置指向用户数据空间。因此在实际数据块信息传递过程中Linux内核就可以利用fs寄存器来执行内核数据空间与用户数据空间之间的数据复制工作,并且在复制过程中内核程序不需要对数据边界范围作任何检查操作。边界检查操作由CPU自动完成。内核程序的实际数据传送工作可以使用get_fs_byte()和puts_fs_bypte()等函数进行。
[1] 《Linux内核完全剖析基于0.12内核》 赵炯著。
[2] 网易云课堂,哈尔滨工业大学《操作系统之应用》 李治军。