文/赵杰
2015.11.04
服务端日志你有多重视?
- 我们没有日志
- 有日志,但基本不去控制需要输出的内容
- 经常微调日志,只输出我们想看和有用的
- 经常监控日志,一方面帮助日志微调,一方面及早发现程序的问题
只做到第1点的,你可以洗洗去睡了。很多公司都有做到第2点和第3点,这些公司的服务端程序基本已经跑了很长时间了,已比较稳定,确实无需花太多时间去关注。如果一个新产品,在上线初期,我觉得就有必要做到第4点。
日志怎么看?
- 都说了,我们没有日志
- 线上日志逐个tail+grep
- 编写脚本,下载某个时间范围内的全部日志到本地再搜索
tail+grep或者把日志下载下来再搜索,可以应付不多的主机和应用不多的部署场景。但对于多机多应用部署就不合适了。这里的多机多应用指的是同一种应用被部署到几台服务器上,每台服务器上又部署着不同的多个应用。可以想象,这种场景下,为了监控或者搜索某段日志,需要登陆多台服务器,执行多个tail -F和grep命令。一方面这很被动。另一方面,效率非常低,数次操作下来,程序员的心情也会变糟(我还要去维护宇宙和平的好嘛)。
这篇文章讲的就是如何解决分布式系统的日志管理问题。先给大家看看最终的效果:
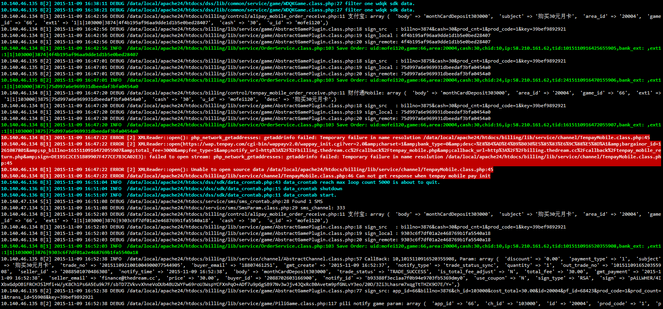
单个屏幕上所有服务器的日志实时滚动着显示。每条日志开头还标明日志的来源(下图)。
实现这种效果的原理是后台跑着一个程序,这个程序负责汇总所有日志到一个本地文件中。只要执行tail -f这个文件就可以做到监控日志了。因为所有日志都汇总在一个文件里了,所以做日志搜索的时候只要针对这一个文件搜索就可以了。
能够汇总日志文件的工具名字叫Logstash,即本文的介绍重点。它使用JRuby编写,开源,主流,免费,使用简单(宇宙和平使者必备单品)。
2. Logstash部署架构Logstash的理念很简单,它只做3件事情:
- Collect:数据输入
- Enrich:数据加工,如过滤,改写等
- Transport:数据输出
别看它只做3件事,但通过组合输入和输出,可以变幻出多种架构实现多种需求。这里只抛出用以解决日志汇总需求的部署架构图:
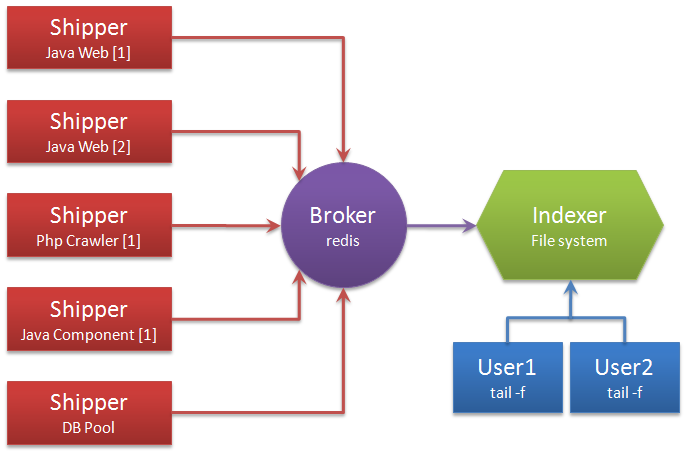
解释术语:
- Shipper:日志收集者。负责监控本地日志文件的变化,及时把日志文件的最新内容收集起来,输出到Redis暂存。
- Indexer:日志存储者。负责从Redis接收日志,写入到本地文件。
- Broker:日志Hub,用来连接多个Shipper和多个Indexer。
无论是Shipper还是Indexer,Logstash始终只做前面提到的3件事:
- Shipper从日志文件读取最新的行文本,经过处理(这里我们会改写部分元数据),输出到Redis,
- Indexer从Redis读取文本,经过处理(这里我们会format文本),输出到文件。
一个Logstash进程可以有多个输入源,所以一个Logstash进程可以同时读取一台服务器上的多个日志文件。Redis是Logstash官方推荐的Broker角色“人选”,支持订阅发布和队列两种数据传输模式,推荐使用。输入输出支持过滤,改写。Logstash支持多种输出源,可以配置多个输出实现数据的多份复制,也可以输出到Email,File,Tcp,或者作为其它程序的输入,又或者安装插件实现和其他系统的对接,比如搜索引擎Elasticsearch。
总结:Logstash概念简单,通过组合可以满足多种需求。
3. Logstash的安装,搭建和配置 3.1. 安装Java下载JDK压缩包。
一般解压到/user/local/下,形成/usr/local/jdk1.7.0_79/bin这种目录结构。
配置JAVA_HOME环境变量:echo 'export JAVA_HOME=/usr/local/jdk1.7.0_79' >> ~/.bashrc。
去官网下载Logstash的压缩包。
一般也解压到/usr/local/下,形成/usr/local/logstash-1.4.3/bin这种目录结构。
Logstash的运行方式为主程序+配置文件。Collect,Enrich和Transport的行为在配置文件中定义。配置文件的格式有点像json,又有点像php。
3.3. 编写Shipper角色的配置文件:shipper.confinput {
file {
path => [
# 这里填写需要监控的文件
"/data/log/php/php_fetal.log",
"/data/log/service1/access.log"
]
}
}
如上,input描述的就是数据如何输入。这里填写你需要收集的本机日志文件路径。
output {
# 输出到控制台
# stdout { }
# 输出到redis
redis {
host => "10.140.45.190" # redis主机地址
port => 6379 # redis端口号
db => 8 # redis数据库编号
data_type => "channel" # 使用发布/订阅模式
key => "logstash_list_0" # 发布通道名称
}
}
如上,output描述的就是数据如何输出。这里描述的是输出到Redis。
data_type的可选值有channel和list两种。用过Redis的人知道,channel是Redis的发布/订阅通信模式,而list是Redis的队列数据结构。两者都可以用来实现系统间有序的消息异步通信。channel相比list的好处是,解除了发布者和订阅者之间的耦合。举个例子,一个Indexer在持续读取Redis中的记录,现在想加入第二个Indexer,如果使用list,就会出现上一条记录被第一个Indexer取走,而下一条记录被第二个Indexer取走的情况,两个Indexer之间产生了竞争,导致任何一方都没有读到完整的日志。channel就可以避免这种情况。这里Shipper角色的配置文件和下面将要提到的Indexer角色的配置文件中都使用了channel。
filter {
mutate {
# 替换元数据host的值
replace => ["host", "10.140.46.134 B[1]"]
}
}
如上,filter描述的是如何过滤数据。mutate是一个自带的过滤插件,它支持replace操作,可以改写数据。这里改写了元数据中的host字段,替换成了我们自己定义的文本。
Logstash传递的每条数据都带有元数据,如@version,@timestamp,host等等。有些可以修改,有些不允许修改。host记录的是当前主机的信息。Logstash可能不会去获取主机的信息或者获取的不准确,这里建议替换成自己定义的主机标示,以保证最终的日志输出可以有完美的格式和良好的可读性。
3.4 编写Indexer角色的配置文件:indexer.confinput {
redis {
host => "10.140.45.190" # redis主机地址
port => 6379 # redis端口号
db => 8 # redis数据库编号
data_type => "channel" # 使用发布/订阅模式
key => "logstash_list_0" # 发布通道名称
}
}
如上,input部分设置为从redis接收数据。
output {
file {
path => "/data/log/logstash/all.log" # 指定写入文件路径
message_format => "%{host} %{message}" # 指定写入格式
flush_interval => 0 # 指定刷新间隔,0代表实时写入
}
}
如上,output部分设置为写入本地文件。
官方文档里flush_interval为缓冲时间(单位秒)。我实践下来不是秒而是数量,Logstash会等待缓冲区写满一定数量后才输出。这对线上调试是不能接受的,建议上线初期设为0。程序稳定后,随着日志量的增大,可以增大flush_interval的值以提高文件写入性能。
Indexer的配置文件中,我明确指定了message_format的格式,其中%{host}对应的就是之前手动设置的host元数据。
# 先在Indexer主机上启动
nohup /usr/local/logstash-1.4.3/bin/logstash agent -f indexer.conf &>/dev/null &
# 然后在Shipper主机上启动
nohup /usr/local/logstash-1.4.3/bin/logstash agent -f shipper.conf &>/dev/null &
# 最后在Indexer上观察日志
tail -f /data/log/logstash/all.log
我们来测试一下,切到Shipper主机上,模拟日志产生:
echo "Hello World" >> /data/log/php/php_fetal.log
再切换到Indexer主机上,如果出现:10.140.46.134 B[1] Hello World,说明Logstash部署成功。
在tail -f的时候,如果使用awk配合echo,可以匹配你想要高亮的文本,改变他们的前景色和背景色。就像效果图里的那样(这是宇宙和平使者必备单品的重要属性好嘛)。这里附上我写的脚本,把脚本中的关键信息替换成你想要匹配的文本即可:
tail -f /data/log/logstash/all.log | awk '{
if (match($0, /.*(PHP Deprecated|PHP Notice|PHP Fatal error|PHP Warning|ERROR|WARN).*/)) { print "\033[41;37;1m"$0"\033[0m" }
else if (match($0, /.*关键信息1.*/)) { print "\033[32;1m"$0"\033[0m" }
else if (match($0, /.*关键信息2.*/)) { print "\033[36;1m"$0"\033[0m" }
else { print $0 } }'
So easy,妈妈再也不用担心我的日志。。。
4. 还有什么有些公司需要挖掘日志的价值,那仅仅收集和实时显示是不够的,需要把逼格上升到日志分析技术层面。
一个完整的日志分析技术栈需要实时收集,实时索引和展示三部分组成,Logstash只是这其中的第一个环节。Logstash所属的Elastic公司,已经开发了完整的日志分析技术栈,它们是Elasticsearch,Logstash,和Kibana,简称ELK。Elasticsearch是搜索引擎,而Kibana是Web展示界面。
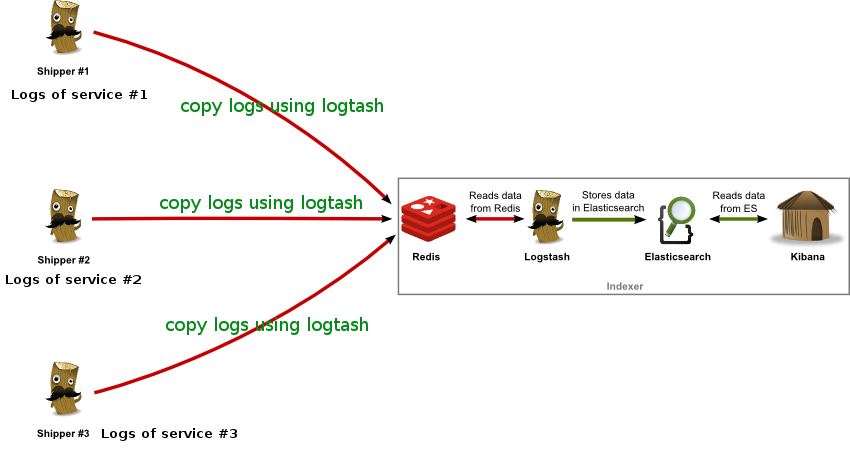
如果你搭建了完整的技术栈,你的老板就可以在图形化界面上按不同的维度去搜索日志了。
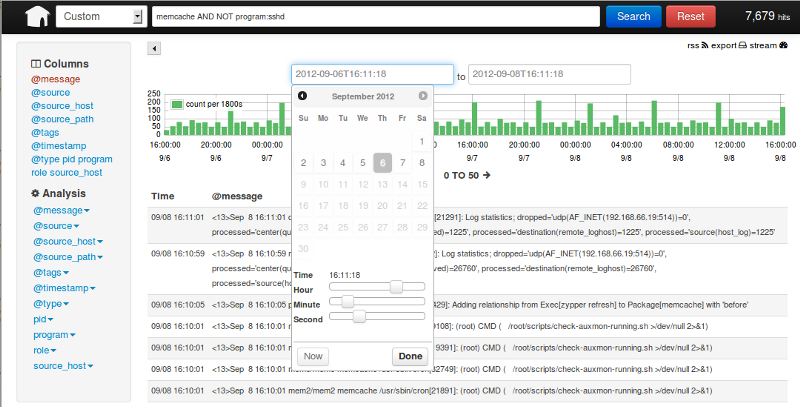
还可以做一些高大上的统计和计算。
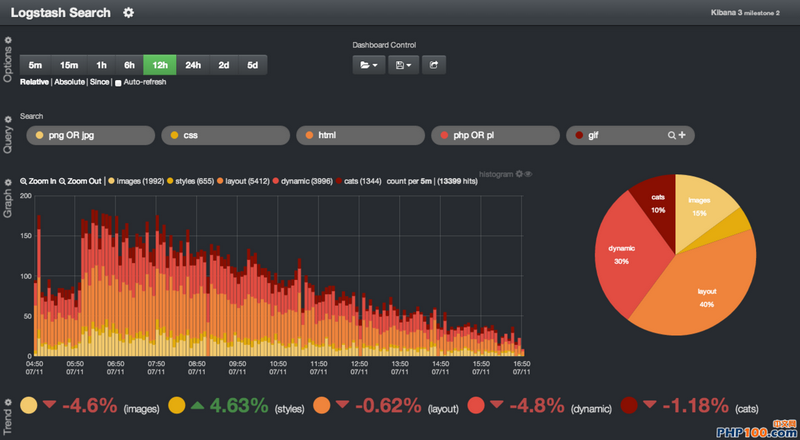
当然,我认为90%的公司是没有必要这么做的(毕竟他们的程序员还要去维护宇宙的和平),能做到在控制台里监控和搜索就能满足需要了。但我们也可以看看剩下的那10%的公司是怎么做的,比如这篇文章:新浪是如何分析处理32亿条实时日志的?
参考文献:
- Logstash 最佳实践 -- github上的中文译本
- Logstash 官方文档