本章是系列文章的第四章,介绍了worklist算法。Worklist算法是图分析的核心算法,可以说学会了worklist算法,编译器的优化方法才算入门。这章学习起来比较吃力,想要融汇贯通的同学,建议多参考几个学校的教程交叉着看。
卡耐基梅隆大学 15745: https://www.cs.cmu.edu/afs/cs/academic/class/15745-s16/www/lectures/L5-Intro-to-Dataflow.pdf
密西根大学 583f18: http://web.eecs.umich.edu/~mahlke/courses/583f18/lectures/583L5.pdf 和 http://web.eecs.umich.edu/~mahlke/courses/583f18/lectures/583L6.pdf
哈工大 编译原理:编译原理 - 哈尔滨工业大学_哔哩哔哩_bilibili
但密西根大学的583f18根本就没说worklist算法,只是简单的数据流分析,卡耐基梅隆大学15745提到了worklist,但也讲的非常简单,还是DCC888里面讲的稍微详细一点。
本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
4.1 解析约束别人说知识爆炸,我们先做知识轰炸,说不定哪天就把脑子炸开了。
- 数据流分析的本质是创建约束系统
- 约束系统是对问题的高级抽象
- 解析约束系统有很多有效的算法
- 对待解决问题的描述同样也提供了一种解决方案
- 怎么实际的解析一种约束系统?性能上可行并且有很大概率是正确的算法
手头没有prolog的同学可以从下面链接里面下载一个win64的版本:
https://www.swi-prolog.org/download/stable/bin/swipl-8.4.2-1.x64.exe
如果喜欢linux的也可以在安装一个linux的版本,例如ubuntu的下载命令:
apt install gprolog
安装完之后执行swipl可以进入swipl的prolog界面(linux下面安装的是gprolog,所以执行gprolog)。prolog的每条命令都用“.”结束,例如启动之后可以敲“pwd.”看到当前目录,退出可以敲“halt.”。

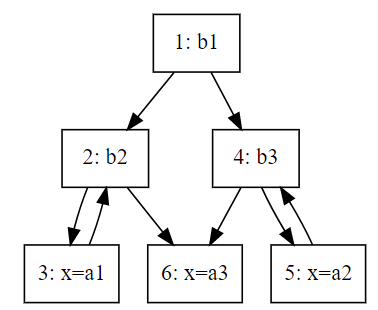
给定程序,这里面有几个BB基本块?
1 if b1 2 then 3 while b2 do x = a1 4 else 5 while b3 do x = a2 6 x = a3
BB列表:
1: b1 2: b2 3: x=a1 4: b3 5: x=a2 6: x=a3
通过BB分析画出CFG:
1 digraph { 2 "1: b1" -> {"2: b2" "4: b3"} 3 "2: b2" -> "3: x=a1" -> "2: b2" 4 "4: b3" -> "5: x=a2" -> "4: b3" 5 {"2: b2" "4: b3"} -> "6: x=a3" 6 }
我们复习一下上一章的reaching definition,上面这个例程的reaching definition推导过程如下:
1 IN[x1] = {} 2 IN[x2] = OUT[x1] ∪ OUT[x3] 3 IN[x3] = OUT[x2] 4 IN[x4] = OUT[x1] ∪ OUT[x5] 5 IN[x5] = OUT[x4] 6 IN[x6] = OUT[x2] ∪ OUT[x4] 7 OUT[x1] = IN[x1] 8 OUT[x2] = IN[x2] 9 OUT[x3] = (IN[x3]\{3,5,6}) ∪ {3} 10 OUT[x4] = IN[x4] 11 OUT[x5] = (IN[x5]\{3,5,6}) ∪ {5} 12 OUT[x6] = (IN[x6]\{3,5,6}) ∪ {6}
我们将这里的过程整理成prolog代码:
1 diff([], _, []). 2 diff([H|T], L, LL) :- member(H, L), diff(T, L, LL). 3 diff([H|T], L, [H|LL]) 4 :- \+ member(H, L), diff(T, L, LL). 5 union([], L, L). 6 union([H|T], L, [H|LL]) 7 :- union(T, L, LL). 8 9 10 solution([X1_IN, X2_IN, X3_IN, X4_IN, X5_IN, X6_IN, 11 X1_OUT, X2_OUT, X3_OUT, X4_OUT, X5_OUT, X6_OUT]) :- 12 X1_IN = [], 13 union(X1_OUT, X3_OUT, X2_IN), 14 X3_IN = X2_OUT, 15 union(X1_OUT, X5_OUT, X4_IN), 16 X5_IN = X4_OUT, 17 union(X2_OUT, X4_OUT, X6_IN), 18 X1_OUT = X1_IN, 19 X2_OUT = X2_IN, 20 diff(X3_IN, [3, 5, 6], XA), union(XA, [3], X3_OUT), 21 X4_OUT = X4_IN, 22 diff(X5_IN, [3, 5, 6], XB), union(XB, [5], X5_OUT), 23 diff(X6_IN, [3, 5, 6], XC), union(XC, [6], X6_OUT), !.
prolog的语法可以参考swi-prolog的手册manual (swi-prolog.org),注意swi的prolog自己扩展了一些prolog函数,有些函数在其他版本的prolog里面不一定能用。
将上面的prolog代码保存成一个pl文件,例如rd.pl,运行swipl(linux 下是gprolog),加载并运行,可以得到
solution([[], [3], [3], [5], [5], [3, 5], [], [3], [3], [5], [5], [6]]) 返回值是true(gprolog返回yes)。如果想知道推导过程,可以用“trace.”打开单步执行:
1 PS D:\doc\DC888\hw> swipl 2 3 1 ?- [rd]. 4 true. 5 6 2 ?- solution([[], [3], [3], [5], [5], [3, 5], [], [3], [3], [5], [5], [6]]). 7 true. 8 9 3 ?- trace. 10 true. 11 12 [trace] 3 ?- solution([[], [3], [3], [5], [5], [3, 5], [], [3], [3], [5], [5], [6]]). 13 Call: (10) solution([[], [3], [3], [5], [5], [3, 5], [], [...]|...]) ? creep 14 Call: (11) []=[] ? creep 15 Exit: (11) []=[] ? creep 16 Call: (11) union([], [3], [3]) ? creep 17 Exit: (11) union([], [3], [3]) ? creep 18 Call: (11) [3]=[3] ? creep 19 Exit: (11) [3]=[3] ? creep 20 Call: (11) union([], [5], [5]) ? creep 21 Exit: (11) union([], [5], [5]) ? creep 22 Call: (11) [5]=[5] ? creep 23 Exit: (11) [5]=[5] ? creep 24 Call: (11) union([3], [5], [3, 5]) ? creep 25 Call: (12) lists:member(3, [5]) ? creep 26 Fail: (12) lists:member(3, [5]) ? creep 27 Redo: (11) union([3], [5], [3, 5]) ? creep 28 Call: (12) lists:member(3, [5]) ? creep 29 Fail: (12) lists:member(3, [5]) ? creep 30 Redo: (11) union([3], [5], [3, 5]) ? creep 31 Call: (12) union([], [5], [5]) ? creep 32 Exit: (12) union([], [5], [5]) ? creep 33 Exit: (11) union([3], [5], [3, 5]) ? creep 34 Call: (11) []=[] ? creep 35 Exit: (11) []=[] ? creep 36 Call: (11) [3]=[3] ? creep 37 Exit: (11) [3]=[3] ? creep 38 Call: (11) diff([3], [3, 5, 6], _20084) ? creep 39 Call: (12) lists:member(3, [3, 5, 6]) ? creep 40 Exit: (12) lists:member(3, [3, 5, 6]) ? creep 41 Call: (12) diff([], [3, 5, 6], _20084) ? creep 42 Exit: (12) diff([], [3, 5, 6], []) ? creep 43 Exit: (11) diff([3], [3, 5, 6], []) ? creep 44 Call: (11) union([], [3], [3]) ? creep 45 Exit: (11) union([], [3], [3]) ? creep 46 Call: (11) [5]=[5] ? creep 47 Exit: (11) [5]=[5] ? creep 48 Call: (11) diff([5], [3, 5, 6], _27698) ? creep 49 Call: (12) lists:member(5, [3, 5, 6]) ? creep 50 Exit: (12) lists:member(5, [3, 5, 6]) ? creep 51 Call: (12) diff([], [3, 5, 6], _27698) ? creep 52 Exit: (12) diff([], [3, 5, 6], []) ? creep 53 Exit: (11) diff([5], [3, 5, 6], []) ? creep 54 Call: (11) union([], [5], [5]) ? creep 55 Exit: (11) union([], [5], [5]) ? creep 56 Call: (11) diff([3, 5], [3, 5, 6], _2514) ? creep 57 Call: (12) lists:member(3, [3, 5, 6]) ? creep 58 Exit: (12) lists:member(3, [3, 5, 6]) ? creep 59 Call: (12) diff([5], [3, 5, 6], _2514) ? creep 60 Call: (13) lists:member(5, [3, 5, 6]) ? creep 61 Exit: (13) lists:member(5, [3, 5, 6]) ? creep 62 Call: (13) diff([], [3, 5, 6], _2514) ? creep 63 Exit: (13) diff([], [3, 5, 6], []) ? creep 64 Exit: (12) diff([5], [3, 5, 6], []) ? creep 65 Exit: (11) diff([3, 5], [3, 5, 6], []) ? creep 66 Call: (11) union([], [6], [6]) ? creep 67 Exit: (11) union([], [6], [6]) ? creep 68 Exit: (10) solution([[], [3], [3], [5], [5], [3, 5], [], [...]|...]) ? creep 69 true.
solution([[], [3], [3], [5], [5], [3, 5], [], [3], [3], [5], [5], [6]])执行返回true表示,1~6处的reaching definition的输入集合分别为:
[], [3], [3], [5], [5], [3, 5],
输出集合分别为:
[], [3], [3], [5], [5], [6]
的情况下,是能被验证成功的。
但验证通过的集合不一定是最优解,例如,如果在一些集合中加入4,一样也能推导成功:
solution([[], [3], [3], [4, 5], [4, 5], [3, 4, 5], [], [3], [3], [4, 5], [4, 5], [4, 6]]).
一般的,把这些4换成任意变量也是能成功的:
1 PS D:\doc\DC888\hw> swipl 2 3 1 ?- [rd]. 4 true. 5 6 2 ?- solution([[], [3], [3], [a, 5], [a, 5], [3, a, 5], [], [3], [3], [a, 5], [a, 5], [a, 6]]). 7 true. 8 9 3 ?-
这主要是因为集合的diff和union函数中有一个特殊处理,下面2个函数的意思是,不论H是否是L的成员diff([H|T], L, [H|LL])和diff(T, L, LL)等价,union([H|T], L, [H|LL])和union(T, L, LL)等价,这对一些未知元素的推导会非常有用:
1 diff([H|T], L, [H|LL]) 2 :- \+ member(H, L), diff(T, L, LL). 3 union([H|T], L, [H|LL]) 4 :- \+ member(H, L), union(T, L, LL). 5 ji
就实际意义而言,程序点4或者程序点2处,如果新定义了变量,则可以传递到后面程序点的reaching definition集合里面,如果没有定义任何变量(例如当前的例程只是做了true和false的判断),那后面就没有程序点4或者程序点2处新增的变量集合。
虽然这个推导能容忍不同的答案,但还是能保证一致性,如果将X6_OUT换成空,则程序会报false:
1 PS D:\doc\DC888\hw> swipl 2 3 1 ?- [rd]. 4 true. 5 6 2 ?- solution([[], [3], [3], [a, 5], [a, 5], [3, a, 5], [], [3], [3], [a, 5], [a, 5], []]). 7 false. 8 9 3 ?-
因为不论前面的输入或者输出集合怎么变化,在程序点6新定义了变量x,这个新增的变量x肯定是能进入程序点6的reaching definition的输出集合的。
4.1.2 静态分析和动态分析结果静态分析有时候会提供一些在实际运行中不可能发生的结果。
例如对下面的CFG,由于y是x的平方,肯定不会小于0,所以程序点4肯定执行不到。
如果实际运行中某个定义D在基本块B处可达,但静态分析推导出来的结果是不可达,则称为这个静态分析是假的不可达(false negative,是不是有点像核酸检测中的假阴?)。假的不可达是错误结论。如果核酸检测中某个人本来是阳性,核酸检测结果是阴性,那后面可能没人会对他进行复核,导致这个阳性流出到社会面。所以假阴的后果是很严重的。
相对的,如果静态分析的结果认为某个定义D在基本块B处可达,但实际运行过程中不可达,则认为这个静态分析是假的可达(false positive,类似核酸检测的假阳)。假的可达是不严密的(imprecise),但不能算错误。例如核酸检测中出现假阳,后面会专门进行复核,如果多次复核之后发现是假阳,之前的检测结果可以取消掉。
4.1.3 使用prolog找到解决方案前面prolog执行过程主要都是检查某个解决方案是否正确,但实际上也可以用prolog找到解决方案。
但要注意,prolog是对系统空间的穷举计算(类似tla+,Temporal Logic of Actions,参见The TLA+ Home Page (lamport.azurewebsites.net)),所以有些推导可能是非常耗时,甚至由于中间存在循环,可能永远无法结束。
还是上面的例子,如果执行下面的命令,在windows下面会一直循环下去,在linux下执行会提示堆栈溢出,加了“length(X5_OUT, 1), ”限制就能正常跑出结果:
solution([X1_IN, X2_IN, X3_IN, X4_IN, X5_IN, X6_IN, X1_OUT, X2_OUT,
X3_OUT, X4_OUT, [5], X6_OUT]).
1 root@794bb5fbd58a:~/DCC888# gprolog 2 GNU Prolog 1.3.0 3 By Daniel Diaz 4 Copyright (C) 1999-2007 Daniel Diaz 5 | ?- [rd1]. 6 compiling /home/ronghua.zhou/DCC888/rd1.pl for byte code... 7 /home/ronghua.zhou/DCC888/rd1.pl compiled, 21 lines read - 4036 bytes written, 6 ms 8 9 yes 10 | ?- X5_OUT = [5], 11 X1_IN = [], 12 X2_IN = [3], 13 X3_IN = [3], 14 X4_IN = [5], 15 X5_IN = [5], 16 X6_IN = [3, 5], 17 OUT = [], 18 X2X1_OUT = [], 19 _OUTX2_OUT = [3], 20 X3_OUT = [3], 21 X4_OUT = [5], 22 X6_OUT = [6] . 23 24 X1_IN = [] 25 X1_OUT = [] 26 X2_IN = [3] 27 X2_OUT = [3] 28 X3_IN = [3] 29 X3_OUT = [3] 30 X4_IN = [5] 31 X4_OUT = [5] 32 X5_IN = [5] 33 X5_OUT = [5] 34 X6_IN = [3,5] 35 X6_OUT = [6] 36 37 yes 38 | ?- length(X5_OUT, 1), solution([X1_IN, X2_IN, X3_IN, X4_IN, X5_IN, X6_IN, 39 X1_OUT, X2_OUT, X3_OUT, X4_OUT, X5_OUT, X6_OUT]). 40 41 X1_IN = [] 42 X1_OUT = [] 43 X2_IN = [3] 44 X2_OUT = [3] 45 X3_IN = [3] 46 X3_OUT = [3] 47 X4_IN = [5] 48 X4_OUT = [5] 49 X5_IN = [5] 50 X5_OUT = [5] 51 X6_IN = [3,5] 52 X6_OUT = [6] 53 54 yes 55 | ?- solution([X1_IN, X2_IN, X3_IN, X4_IN, X5_IN, X6_IN, 56 X1_OUT, X2_OUT, X3_OUT, X4_OUT, X5_OUT, X6_OUT]). 57 58 Fatal Error: local stack overflow (size: 8192 Kb, environment variable used: LOCALSZ)
4.2 解决循环worklist的方法
混沌迭代:假定很多约束放在一个袋子里面,每次从袋子中提取一个约束,并解析它,直到所有约束都从袋子里面取出。
4.2.1 用混沌迭代解决reaching definition1 for each i ∈ {1, 2, 3, 4, 5, 6} 2 IN[xi] = {} 3 OUT[xi] = {} 4 repeat 5 for each i ∈ {1, 2, 3, 4, 5, 6} 6 IN'[xi] = IN[xi]; 7 OUT'[xi] = OUT[xi]; 8 OUT[xi] = def(xi) ∪ (IN[xi] \ kill(xi)); 9 IN[xi] = ∪ OUT[s], s ∈ pred[xi]; 10 until ∀ i ∈ {1, 2, 3, 4, 5, 6} 11 IN'[xi] = IN[xi] and OUT'[xi] = OUT[xi]
4.2.2 抽象之后的混沌迭代算法
1 x1 = ⊥ , x2 = ⊥ , … , xn = ⊥ 2 do 3 t1 = x1 ; … ; tn = xn 4 x1 = F1 (x1, …, xn) 5 … 6 xn = Fn (x1, …, xn) 7 while (x1 ≠ t1 or … or xn ≠ tn)
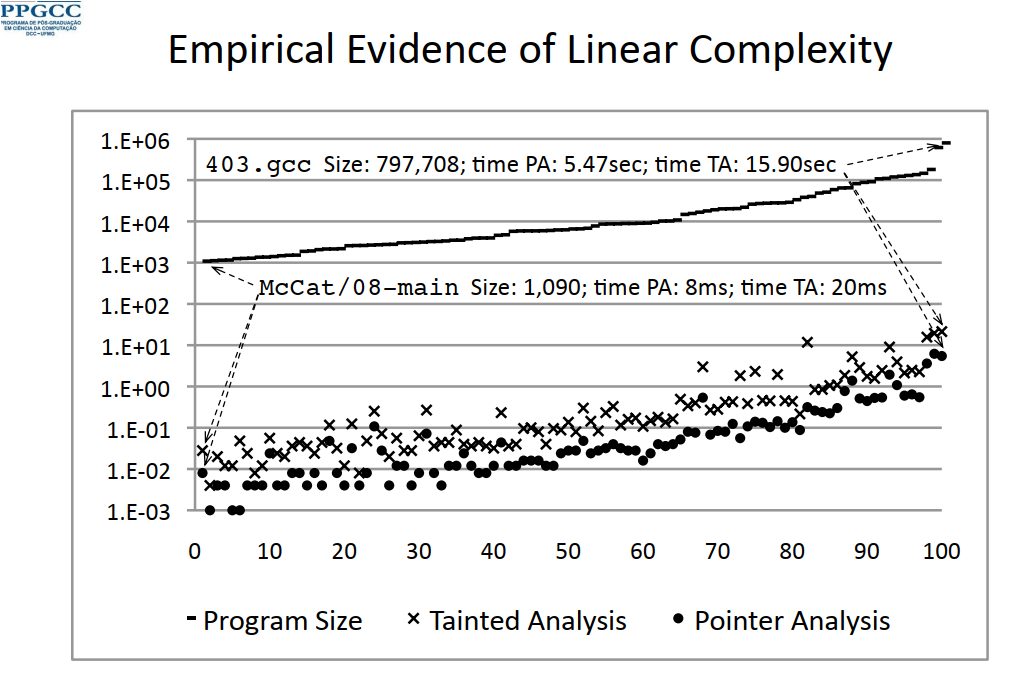
根据不动点原理(Fixed Point Theory,参见Fixed Point Theory - an overview | ScienceDirect Topics),可以证明该计算过程存在一个不动点,也就是即使在不规定具体执行顺序的情况下,也能正常终结。但这个原始算法的复杂度是O(n5),几乎比所有真实存在的算法的复杂度都要高。但如果给定条件是所有节点之间是有序的,这个复杂度可以最终降维到O(n),也就是线性复杂度,很多实验也证实了这种假定。
下面是课程中给出混沌迭代算法是线性复杂度的证据,列举了污染分析和指针分析的复杂度相对程序规模的增长情况(但我有点疑惑,左边坐标系是指数坐标系,如果复杂度相对指数坐标系是线性,是不是表示这个复杂度是指数复杂度?):
4.2.3 混沌迭代计算的加速
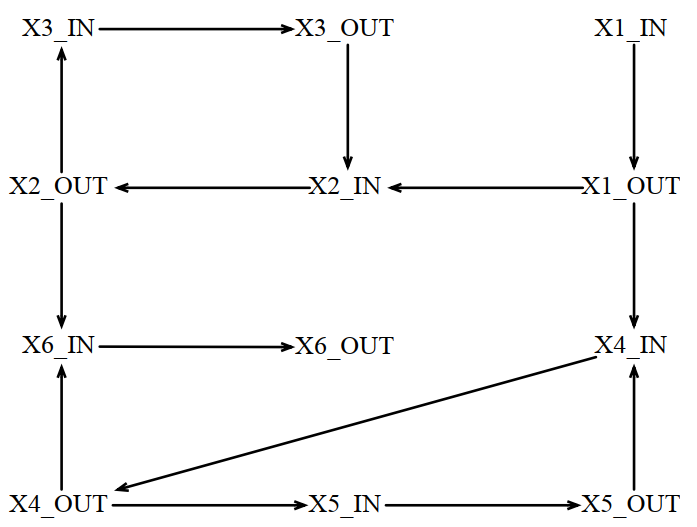
对等式的计算如果不加排序,复杂度是惊人的,但通过一定的计算排序,可以有效降低计算复杂度。
找到约束变量之间的依赖图:
4.2.4 混沌迭代的worklist表达
1 x1 = ⊥ , x2 = ⊥ , … , xn = ⊥ 2 w = [v1, …, vn] 3 while (w ≠ []) 4 vi = extract(w) 5 y = Fi (x1, …, xn) 6 if y ≠ xi 7 for v ∈ dep(vi) 8 w = insert(w, v) 9 xi = y
为了方便讲解,原来的计算方法对6个程序点,存在12个参数(6个IN,6个OUT),但实际上IN和OUT能相互推导,所以只保留6个输入的集合不会影响计算效果,简化版的reaching definition的推导程序如下:
1 solution([X1_IN, X2_IN, X3_IN, X4_IN, X5_IN, X6_IN]) :- 2 X1_IN = [], /* F1 */ 3 diff(X3_IN, [3, 5, 6], XA), union(XA, X1_IN, XB), union(XB, [3], X2_IN), /* F2 */ 4 X3_IN = X2_IN, /* F3 */ 5 diff(X5_IN, [3, 5, 6], XC), union(XC, X1_IN, XD), union(XD, [5], X4_IN), /* F4 */ 6 X5_IN = X4_IN, /* F5 */ 7 union(X2_IN, X5_IN, X6_IN), !. /* F6 */
注意,上面solution函数中的没一行都是生成worklist算法中y的Fi,worklist中的dep(vi)是之前依赖图中的依赖关系集合,例如对程序点1,实际上所有程序点的输入和输出集合都依赖它,即使简化之后只剩下输入集合,也是2到6的输入集合都依赖程序点1,但dep(vi)只计算直接依赖,也就是说dep(v1)={x2, x4},为了便于推导,我们先生成一个简化版依赖图。
1 digraph { 2 "X1_IN" -> {"X2_IN" "X4_IN"} 3 "X2_IN" -> "X3_IN" -> "X2_IN" 4 "X4_IN" -> "X5_IN" -> "X4_IN" 5 {"X2_IN" "X4_IN"} -> "X6_IN" 6 }
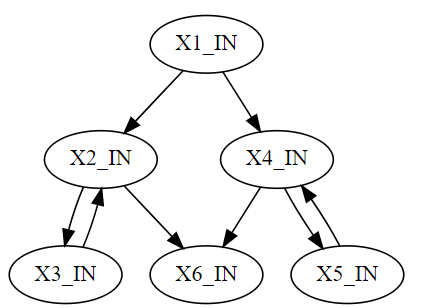
大家有没有从这幅简化版的依赖图里面看到和CFG之间的关联关系?是的,简化版的依赖图基本上就是CFG(如果对某个BB不只是一条指令的情况下,简化依赖图里面的每个变量会变成一个变量的集合,但依赖关系还是和CFG保持一致)。所以后面我们做worklist的计算表的时候,只需要看着CFG就可以做出来了。
现在让我们手工推导一下worklist表,注意推导过程中的insert和extract使用的LIFO栈(Last-In, First-Out, 后进先出 ),而且我们不关心栈里面是否已经有对应的元素:

4.2.5 寻找更好的遍历顺序
因为前面画出来的依赖图是对部分节点并不存在循环,所以它不存在一个拓扑意义上的遍历顺序,但我们可以有一个准遍历顺序(quasi-ordering)。
以下概念参考Directed graph traversal, orderings and applications to data-flow analysis - Eli Bendersky's website (thegreenplace.net)。
深度优先搜索(Depth-First Search),也称为深度优先遍历(Depth-First Span),从根节点开始遍历。将当前遍历节点加入遍历过的列表,并对与当前节点有联通边的所有节点进行深度优先遍历。下面是python的伪代码:
1 def dfs(graph, root, visitor): 2 """DFS over a graph. 3 Start with node 'root', calling 'visitor' for every visited node. 4 """ 5 visited = set() 6 def dfs_walk(node): 7 visited.add(node) 8 visitor(node) 9 for succ in graph.successors(node): 10 if not succ in visited: 11 dfs_walk(succ) 12 dfs_walk(root)
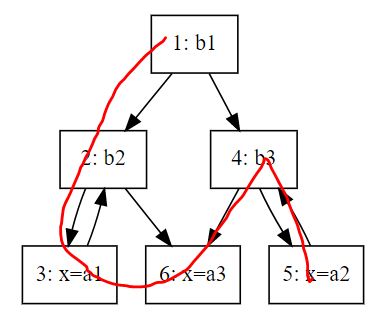
图中的DFS和普通的树不一样,因为可能一个节点有多个父节点,可能会存在部分节点先遍历子结点再遍历父节点的情况。例如对之前那个例程的CFG,DFS的顺序是[1, 2, 3, 6, 4, 5],画成图这样的:
后根序列(post-order):和DFS的遍历过程类似,但注意这里是先遍历,再加入到列表。生成的顺序是[3, 6, 2, 5, 4, 1](按算法本身来说也可能生成[6, 3, 2, 5, 4, 1])。下面是后根序列的python代码:
1 def postorder(graph, root): 2 """Return a post-order ordering of nodes in the graph.""" 3 visited = set() 4 order = [] 5 def dfs_walk(node): 6 visited.add(node) 7 for succ in graph.successors(node): 8 if not succ in visited: 9 dfs_walk(succ) 10 order.append(node) 11 dfs_walk(root) 12 return order
画出来的图是这样的:
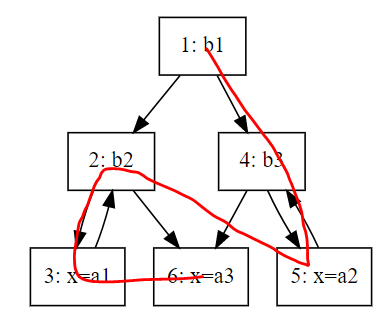
反向后根遍历(Reverse postorder):顾名思义,就是把后根遍历的序列转置以下,是后根遍历的逆序,简称rPostorder。生成的顺序是[1,4, 5, 2, 6, 3]。图和后根遍历的一样,只不过方向相反。
当然,一个图转换成DFS或者rPostorder的时候,由于对多个节点共父节点的情况下,这多个节点之间的顺序是不确定的,所以可能会存在多个DFS或者Postorder,也就会有多个rPostorder。
基于rPostorder的worklist算法伪代码:
1 insert(v, P): 2 return P ∪ {v} 3 4 extract(C, P): 5 if C = [] 6 C = sort_rPostorder(P) 7 P = {} 8 return (head(C), (tail(C), P)) 9 10 main: 11 x1 = ⊥ , x2 = ⊥ , … , xn = ⊥ 12 C=[], P={v1, ... , vn} 13 while (C ≠ [] || P ≠ {}) 14 vi, C, P = extract(C, P) 15 y = Fi (x1, …, xn) 16 if y ≠ xi 17 for v ∈ dep(vi) 18 P = insert(v, P) 19 xi = y
下面的rPostorder版本的worklist算法是按[1, 2, 3, 4, 6, 5]的排序来进行的,换成其他rPostorfer的序列推导出来的步数是一样的。
这样排序造成的一个直接后果就是所有子结点的遍历必须在父节点之后,这样确保它的所有前驱节点都先遍历,这样导致第一轮C计算到[]之后,第二轮遍历过程中P不会再有新的元素出现,确保两轮遍历之后算法结束。
从上图看,第一轮遍历完之后,所有输入集合基本上就不变了,那第二轮遍历是否可以省略?
4.3 强子图强子图(Strong Components,简称SC或者SCG):如果某个图中存在一个最大的子图,子图中任意节点之间都联通,则称为强子图,也可以叫强连通子图(简称SCC或者SCCG)。
由于SC的拓扑一致性,也就是说把SC当做一个普通节点计算出来的约束系统和把SC中的所有节点拆分开之后计算出来的约束系统是一致的,所以通常可以用SC来对图进行降维。
降维之后的CFG的dot描述如下:
1 digraph { 2 "1: b1" -> {"2: b2, 3: x=a1" "4: b3, 5: x=a2"} -> "6: x=a3" 3 }
画出来的图是这样的:
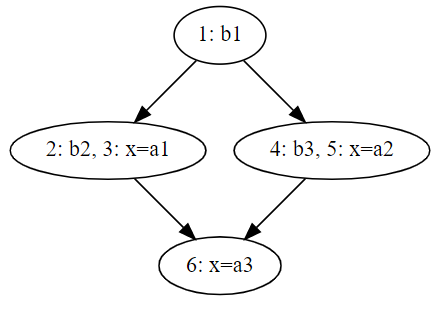
基于SCC的拓扑一致性,可以先将某个SCC或者其前驱程序点的约束计算完(计算完的意思是计算到某个不动点),再计算该SCC后继的程序点,计算后继节点的程序点时不需要往前遍历。基于SCC的worklist遍历过程:

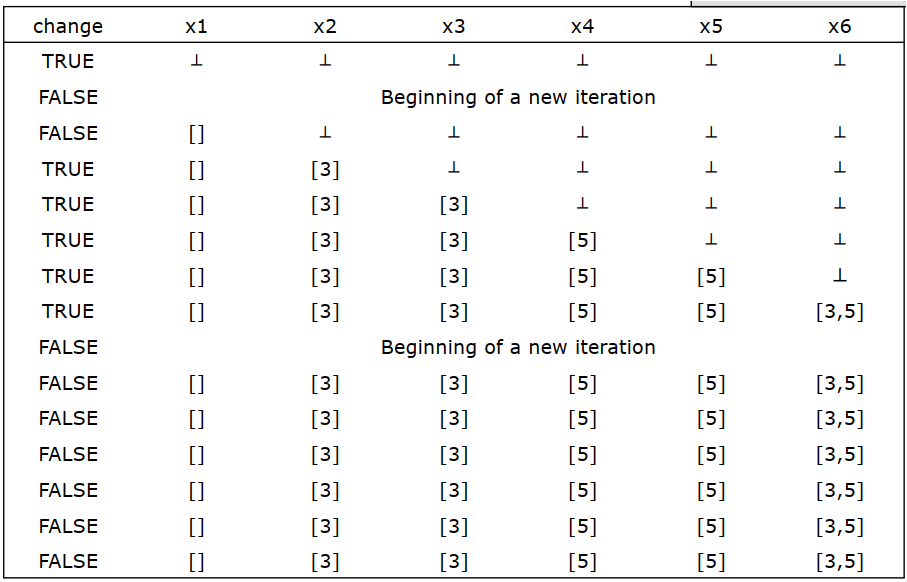
4.4 算法简化:轮转迭代
轮转迭代不用保存一个待解析的列表,也不用怎么实现extract和insert,但会迭代更多次数。
1 x1 = ⊥ , x2 = ⊥ , … , xn = ⊥ 2 change = true 3 while (change) 4 change = false 5 for i = 1 to n do 6 y = Fi (x1, …, xn) 7 if y ≠ xi 8 change = true 9 xi = y
15步可以把约束系统计算完毕:
4.5 集合的表达 4.5.1 bit-vectors位图矩阵
位图矩阵一般在紧密分析中适用,每个元素占用一个bit,空间上只需要N/K个字,其中N是元素个数,K是每个字的bit位个数,插入的复杂度是O(1),运行复杂度是线性的。
4.5.2 其他表达方式哈希表和链表通常对稀疏分析时适用,因为大多数元素并不会在某个程序点有值,适用哈希表可以只保存有值的元素。
4.6 worklist算法简史第一次引入worklist:Kildall, G. "A Unified Approach to Global Program Optimization", POPL, 194-206 (1973)
第一次使用SCC进行数据流分析:Horwitz, S. Demers, A. and Teitelbaum, T. "An efficient general iterative algorithm for dataflow analysis", Acta Informatica, 24, 679-694 (1987)
其他分析:Hecht, M. S. "Flow Analysis of Computer Programs", North Holland, (1977)
【本文转自:韩国服务器 http://www.yidunidc.com处的文章,转载请说明出处】