标题中牛皮吹的有点大,总结成一句话是:用一种极简的方案,处理了一个相对复杂的问题。
前言:
什么是设计模式?同事调侃道:设计模式就是把一个类,拆成一百个类。
调侃归调侃,能够将一个类拆成一百个类,而且类的功能划分合理,类之间彼此独立,又能相互配合,需要有足够的技术沉淀。
经典的设计模式,为我们指明了解决问题的思路和方向,结合新的框架及语言特性,可以得到更好的解决方案。
现状:
一个类有近万行代码(9160行),一个方法有800多行,一个实体类包含492个属性,一个赋值方法中包含234个if...else...判断,而且这种近万行的类文件不止一个,相信大多数人面对这种代码时,要么选择视而不见,要么会十分头疼,而我很幸运的接手了这样一个工作。
背景:
据说这是一个核心的业务模块,起初有2000多行代码,每次需求迭代,就加进去一部分代码,3年时间,增至目前近一万行的代码。
可以想象,这样的代码是没有任何架构可言的,完全是意识流式的写法,想到哪里就写到哪里,有新需求就加新代码,复制粘贴,修修改改,常年累月,形成了这样一个庞然大物。
基本原则:
代码不仅仅要满足运行的要求,好的代码更要便于阅读,逻辑清晰,易扩展,易维护,符合高内聚,低耦合的需求。以此为指导思想,开展重写工作。
如何制定一个统一的处理规范,将一个万行大类拆分为多个小类,并要这些小类相互配合,而又彼此隔离,是这次重写工作的重点。
(为节省阅读时间,直接说方案)
方案说明:
整体上,解决方案分为两部分:抽象层和实现层。
抽象层:定义接口,并负责接口实现类的初始化,调用执行等功能,
实现层:实现接口,创建具体的数据查询类,计算类。
数据传递:贯穿整个计算过程的数据,通过参数在计算类中进行传递;计算的中间数据,以注入的方式([Autowired]),在计算类之间传递。
整个方案可以说做到了尽可能的简洁,抽象层不关心具体实现,实现类之间完全解耦,每个类只需要关心自己的实现逻辑,类的调用顺序及依赖关系放到抽象层。
业务场景:
养殖行业的成本费用分摊计算
业务需求:
将当期发生的成本费用,按照一定比例,分摊到具体的成本对象以及其对应的成本项目上。
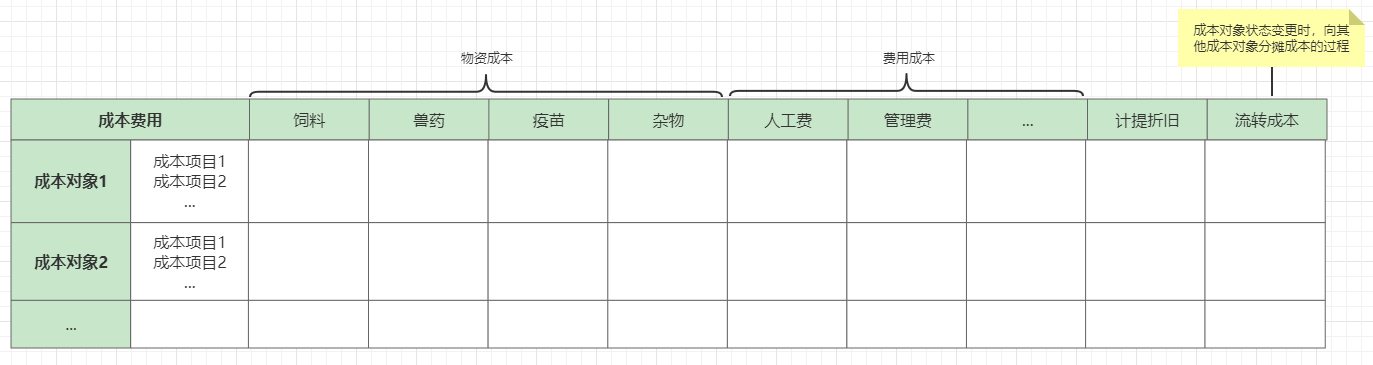
核心逻辑:
整个计算逻辑包括30多个计算步骤,需要从20多个数据源(分布在多个数据库的的20多个关联查询)中查询原始数据,经过层层计算,得到最终结果。
这30多个计算步骤,有的以原始数据作为输入数据,有的以前置计算结果作为输入数据。

思考过程:
首先想到的是用设计模式:职责链模式。
每个计算步骤作为职责链中的一个节点,节点依次执行,完成整个计算过程。
进一步研究发现,使用职责链模式有两个问题:
问题一:职责链模式的每个节点,依赖下一个节点,每个节点需要明确知道其下一节点,增加了节点间代码耦合。
问题二:职责链模式的节点实现自同一个接口,对于需要以其他节点的计算结果作为输入数据的节点并不友好。(有同学可能会想到用一个大类,将所有节点需要的数据都放到这个类中,节点从中筛选自己需要的数据,虽然能解决问题,但并不优雅)
如何解决:
第一个问题,使用职责链模式,是为了隔离每个步骤的关注点,降低代码耦合,至于执行顺序是由职责链自己控制还是由外部控制,并不重要,为此,将控制职责链执行顺序的职责放到职责链外部,是更合理的方式,最简单的方法是:使用List承载节点实现类,顺序执行即可。
第二个问题,数据传递的问题,节点要想访问某个数据,传参是最简单的方式,另一种方式是使用“注入”。也就是下面代码中的特性[Autowired],用过spring的同学应该不会陌生,这里借鉴spring的思想,自定义了一个数据注入的特性。大致思路是:前置计算器的计算结果存入一个全局数据容器中,需要使用该数据的计算器类,定义属性,标记[Autowired]特性,在计算器初始化时,会根据属性的类型,在全局数据容器中查找数据,自动对属性赋值,计算器不需要关心数据来源,只需要使用数据,完成计算逻辑即可。
/// <summary> /// 饲料费用计算 /// </summary> internal class MaterialCostCaculator : ICostCaculator { [Autowired] public MaterialRequisitionDataContext DataContext { get; set; } public List<KeyValuePair<string, decimal>> Caculate(FeedPigsContext feedDaysContext, CaculateItem item) { var result = new List<KeyValuePair<string, decimal>>(); } }
详细说明:
CostCaculateScheduler
CostCaculateScheduler是整个计算功能的唯一入口,该类只有一个方法 Caculate(),作用是:接收参数,初始化并调用 “数据查询类”和“计算器实现类”(具体功能下放到了CaculatorCollection和CostDataContextScheduler),完成整个计算工作。
后期计划加入注册“数据查询类”和“计算器实现类”的方法,以便调用方自定义使用哪些计算器。
CaculatorCollection
CaculatorCollection是计算器的集合类,可以理解为问题一的解决方案中提到的List,提取这个类是为了使结构更清晰。
CostDataContextScheduler
CostDataContextScheduler是一个数据查询类的调度器,可以在计算器执行前,完成对数据的查询,同时也充当问题二的解决方案中“全局数据容器”的角色。
ICostCaculator:是计算器接口。
ICostDataHandler:是通用数据的查询接口,其查询结果会存入“全局数据容器”。
ICostDataContext:是一个标志接口,是为了保持数据查询接口的外观的一致性。
对于每个计算环节来说,只需要定义具体的计算实现类,并完成注册即可。
最左侧的FeedDaysXXX相关的类,是用于查询成本对象,及计算分摊比例的,基本逻辑一致。
类图如下:

心得体会:
将一件简单的事情做复杂,很容易,而将一个复杂的业务做简单,却很考验能力。
经典的设计模式,为我们指明了解决问题的思路和方向,结合新的框架及语言特性,可以得到更好的解决方案。
费了好大力气,说了很多,但感觉好像还没说明白...