随着互联网信息技术日新月异的发展,一个海量数据爆炸的时代已经到来。如何有效地处理、分析这些海量的数据资源,成为各大技术厂商争在激烈的竞争中脱颖而出的一个利器。可以说,如果不能很好的快速处理分析这些海量的数据资源,将很快被市场无情地所淘汰。当然,处理分析这些海量数据目前可以借鉴的方案有很多:首先,在分布式计算方面有Hadoop里面的MapReduce并行计算框架,它主要针对的是离线的数据挖掘分析。此外还有针对实时在线流式数据处理方面的,同样也是分布式的计算框架Storm,也能很好的满足数据实时性分析、处理的要求。最后还有Spring Batch,这个完全面向批处理的框架,可以大规模的应用于企业级的海量数据处理。
在这里,我就不具体展开说明这些框架如何部署、以及如何开发使用的详细教程说明。我想在此基础上更进一步:我们能否借鉴这些开源框架背后的技术背景,为服务的企业或者公司,量身定制一套符合自身数据处理要求的批处理框架。
首先我先描述一下,目前我所服务的公司所面临的一个用户数据存储处理的一个现状背景。目前移动公司一个省内在网用户数据规模达到几千万的规模数量级,而且每个省已经根据地市区域对用户数据进行划分,我们把这批数据存储在传统的关系型数据库上面(基于Oracle,地市是分区)。移动公司的计费结算系统会根据用户手机话费的余额情况,实时的通知业务处理系统,给手机用户进行停机、复机的操作。业务处理系统收到计费结算系统的请求,会把要处理的用户数据往具体的交换机网元上派发不同的交换机指令,这里简单的可以称为Hlr停复机指令(下面开始本文都简称Hlr指令)。目前面临的现状是,在日常情况下,传统的C++多进程的后台处理程序还能勉强的“准实时”地处理这些数据请求,但是,如果一旦到了每个月的月初几天,要处理的数据量往往会暴增,而C++后台程序处理的效率并不高。这时问题来了,往往会有用户投诉,自己缴费了,为什么没有复机?或者某些用户明明已经欠费了,但是还没有及时停机。这样的结果会直接降低客户对移动运营商支撑的满意度,于此同时,移动运营商本身也可能流失这些客户资源。
自己认真评估了一下,造成上述问题的几个瓶颈所在。
- 一个省所有的用户数据都放在数据库的一个实体表中,数据库服务器,满打满算达到顶级小型机配置,也可能无法满足月初处理量激增的性能要求,可以说频繁的在一台服务器上读写IO开销非常巨大,整个服务器处理的性能低下。
- 处理这些数据的时候,会同步地往交换机物理设备上发送Hlr指令,在交换机没有处理成功这个请求指令的时候,只能阻塞等待,进一步造成后续待处理数据的积压。
针对上述的问题,本人想到了几个优化方案。
- 数据库中的实体表,能不能根据用户的归属地市进行表实体的拆分。即把一台或者几台服务器的压力,进行水平拆分。一台数据库服务器就重点处理某一个或者几个地市的数据请求?降低IO开销。
- 由于交换机处理Hlr指令的时候,存在阻塞操作,我们能不能改成:通过异步返回处理的方式,把处理任务队列中的任务先下达通知给交换机,然后交换机通过异步回调机制,反向通知处理模块,汇报任务的执行情况。这样处理模块就从主动的任务轮询等待,变成等待交换机执行结果的异步通知,这样它就可以专注地进行处理数据的派发,不会受到某几个任务处理时长的限制,从而影响到后面整批次的数据处理。
- 数据库的实体表由于进行水平拆解,能不能做到并行加载?这样就会大大节约串行数据加载的处理时长。
- 并行加载出来的待处理数据最好能放到一个批处理框架里面,批处理框架能很好地根据要处理数据的情况,进行配置参数调整,从而很好地满足实时性的要求。比如月初期间,可以加大处理参数的值,提高处理效率。平常的时候,可以适当降低处理参数的取值,降低系统的CPU/IO开销。
基于以上几点考虑,得出如下图所示的设计方案的组件图:
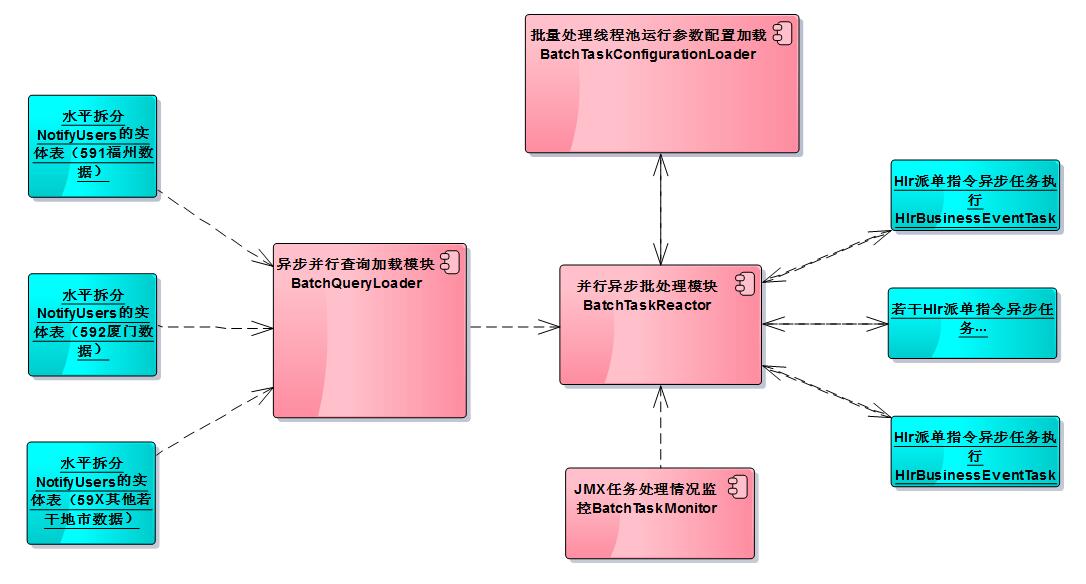
下面就具体说明一下,其中关键模块如何协同工作的。
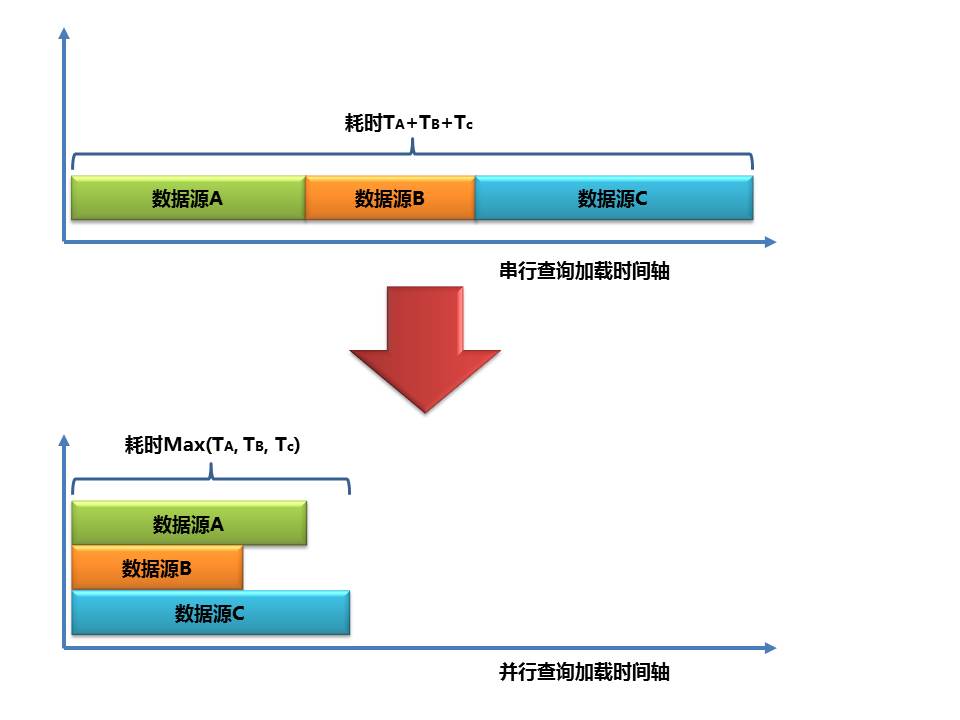
- 异步并行查询加载模块BatchQueryLoader:支持传入多个数据源对象,同时利用google-guava库中对于Future接口的扩展ListenableFuture,来实现批量查询数据的并行加载。Future接口主要是用来表示异步计算的结果,并且计算完成的时候,只能用get()方法获取结果,get方法里面其中有一个方法是可以设置超时时间的。在并行加载模块里面,批量并行地加载多个数据源里面的实体表中的数据,并最终反馈加载的结果集合。并行数据加载和串行数据加载所用的耗时可以简单用下面的图例来说明:串行加载的总耗时是每个数据源加载耗时的总和。而并行加载的总耗时,取决于最大加载的那个数据源耗时时长。(注:我们把每天要进行停复机处理的用户数据通过采集程序,分地市分布采集到水平分库的notify_users提醒用户表)
- 并行异步批处理模块BatchTaskReactor:内部是通过线程池机制来实现的,接受异步并行查询加载模块BatchQueryLoader得到的加载结果数据,放入线程池中进行任务的异步派发,它最终就是通过Hlr派单指令异步任务执行HlrBusinessEventTask模块下发指令任务,然后自己不断的从阻塞队列中获取,待执行的任务列表进行任务的分派。与此同时,他通过Future接口,异步得到HlrBusinessEventTask派发指令的执行反馈结果。
- 批量处理线程池运行参数配置加载BatchTaskConfigurationLoader:加载线程池运行参数的配置,把结果通知并行异步批处理模块BatchTaskReactor,配置文件batchtask-configuration.xml的内容如下所示。
<?xml version="1.0" encoding="GBK"?> <batchtask> <!-- 批处理异步线程池参数配置 --> <jobpool name="newlandframework_batchtask"> <attribute name="corePoolSize" value="15" /> <attribute name="maxPoolSize" value="30" /> <attribute name="keepAliveTime" value="1000" /> <attribute name="workQueueSize" value="200" /> </jobpool> </batchtask>
其中corePoolSize表示保留的线程池大小,workQueueSize表示的是阻塞队列的大小,maxPoolSize表示的是线程池的最大大小,keepAliveTime指的是空闲线程结束的超时时间。其中创建线程池方法ThreadPoolExecutor里面有个参数是unit,它表示一个枚举,即keepAliveTime的单位。说了半天,这几个参数到底什么关系呢?我举一个例子说明一下,当出现需要处理的任务的时候,ThreadPoolExecutor会分配corePoolSize数量的线程池去处理,如果不够的话,会把任务放入阻塞队列,阻塞队列的大小是workQueueSize,当然这个时候还可能不够,怎么办。只能叫来“临时工线程”帮忙处理一下,这个时候“临时工线程”的数量是maxPoolSize-corePoolSize,当然还会继续不够,这个时候ThreadPoolExecutor线程池会采取4种处理策略。
-
现在具体说一下是那些处理策略。首先是ThreadPoolExecutor.AbortPolicy 中,处理程序遭到拒绝将抛出运行时 RejectedExecutionException。然后是ThreadPoolExecutor.CallerRunsPolicy 中,线程调用运行该任务的 execute 本身。此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。其次是,ThreadPoolExecutor.DiscardPolicy 中,不能执行的任务将被删除。最后是ThreadPoolExecutor.DiscardOldestPolicy 中,如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)。如果要处理的任务没有那么多了,ThreadPoolExecutor线程池会根据keepAliveTime设置的时间单位来回收多余的“临时工线程”。你可以把keepAliveTime理解成专门是为maxPoolSize-corePoolSize的“临时工线程”专用的。
-
线程池参数的设定。正常情况下我们要如何设置线程池的参数呢?我们应该这样设置:I、workQueueSize阻塞队列的大小至少大于等于corePoolSize的大小。II、maxPoolSize线程池的大小至少大于等于corePoolSize的大小。III、corePoolSize是你期望处理的默认线程数,个人觉得线程池机制的话,至少大于1吧?不然的话,你这个线程池等于单线程处理任务了,这样就失去了线程池设计存在的意义了。
- JMX(Java Management Extensions)批处理任务监控模块BatchTaskMonitor:实时地监控线程池BatchTaskReactor中任务的执行处理情况(具体就是任务成功/失败情况)。
介绍完毕了几个核心模块主要的功能,那下面就依次介绍一下主要模块的详细设计思路。
- 我们把每天要进行停复机处理的用户数据通过采集程序,采集到notify_users表。首先定义的是,我们要处理采集的通知用户数据对象的结构描述,它对应水平分库的表notify_users的JavaBean对象。notify_users的表结构为了演示起见,简单设计如下(基于Oracle数据库):
create table notify_users
对应JavaBean实体类NotifyUsers,具体代码定义如下:
(
home_city number(3) /*手机用户的归属地市编码*/,
msisdn number(15) /*手机号码*/,
user_id number(15) /*手机用户的用户标识*/
);/** * @filename:NotifyUsers.java * * Newland Co. Ltd. All rights reserved. * * @Description:要进行批处理通知的用户对象 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.model; import org.apache.commons.lang.builder.ToStringBuilder; import org.apache.commons.lang.builder.ToStringStyle; public class NotifyUsers { public NotifyUsers() { } // 用户归属地市编码(这里具体是:591表示福州/592表示厦门) private Integer homeCity; // 用户的手机号码 private Integer msisdn; // 用户标识 private Integer userId; public Integer getHomeCity() { return homeCity; } public void setHomeCity(Integer homeCity) { this.homeCity = homeCity; } public Integer getMsisdn() { return msisdn; } public void setMsisdn(Integer msisdn) { this.msisdn = msisdn; } public Integer getUserId() { return userId; } public void setUserId(Integer userId) { this.userId = userId; } public String toString() { return new ToStringBuilder(this, ToStringStyle.SHORT_PREFIX_STYLE) .append("homeCity", homeCity).append("userId", userId) .append("msisdn", msisdn).toString(); } }
- 异步并行查询加载模块BatchQueryLoader的类图结构:
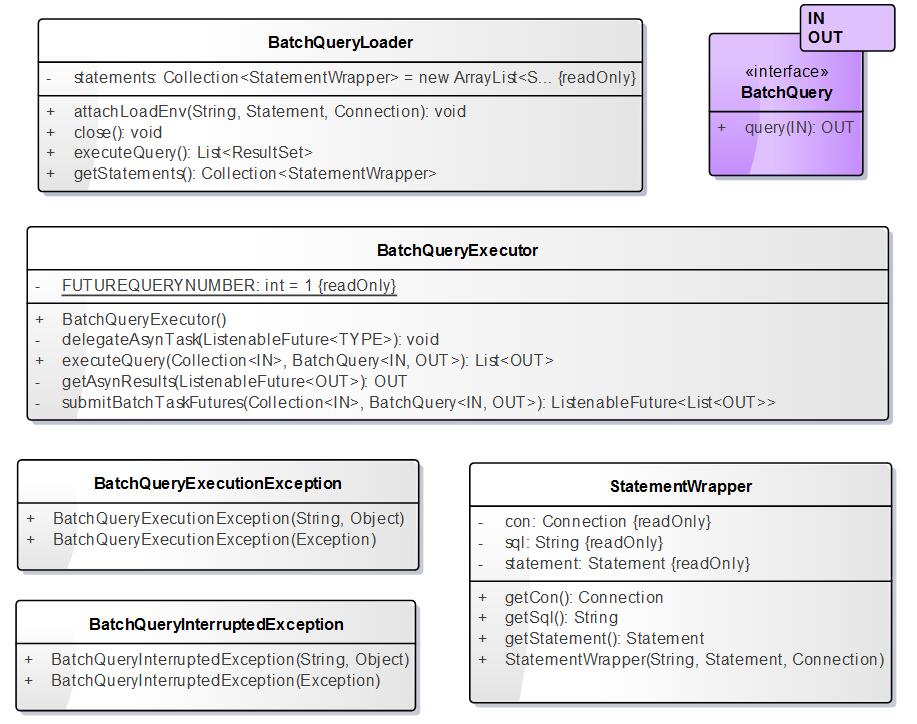 我们通过并行查询加载模块BatchQueryLoader调用异步并行查询执行器BatchQueryExecutor,来并行地加载不同数据源的查询结果集合。StatementWrapper则是对JDBC里面Statement的封装。具体代码如下所示:
我们通过并行查询加载模块BatchQueryLoader调用异步并行查询执行器BatchQueryExecutor,来并行地加载不同数据源的查询结果集合。StatementWrapper则是对JDBC里面Statement的封装。具体代码如下所示: -
/** * @filename:StatementWrapper.java * * Newland Co. Ltd. All rights reserved. * * @Description:Statement封装类 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.sql.Connection; import java.sql.Statement; public class StatementWrapper { private final String sql; private final Statement statement; private final Connection con; public StatementWrapper(String sql, Statement statement, Connection con) { this.sql = sql; this.statement = statement; this.con = con; } public String getSql() { return sql; } public Statement getStatement() { return statement; } public Connection getCon() { return con; } }
定义两个并行加载的异常类BatchQueryInterruptedException、BatchQueryExecutionException
/** * @filename:BatchQueryInterruptedException.java * * Newland Co. Ltd. All rights reserved. * * @Description:并行查询加载InterruptedException异常类 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; public class BatchQueryInterruptedException extends RuntimeException { public BatchQueryInterruptedException(final String errorMessage, final Object... args) { super(String.format(errorMessage, args)); } public BatchQueryInterruptedException(final Exception cause) { super(cause); } }
/** * @filename:BatchQueryExecutionException.java * * Newland Co. Ltd. All rights reserved. * * @Description:并行查询加载ExecutionException异常类 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; public class BatchQueryExecutionException extends RuntimeException { public BatchQueryExecutionException(final String errorMessage, final Object... args) { super(String.format(errorMessage, args)); } public BatchQueryExecutionException(final Exception cause) { super(cause); } }
再抽象出一个批量查询接口,主要是为了后续能扩展在不同的数据库之间进行批量加载。接口类BatchQuery定义如下
/** * @filename:BatchQuery.java * * Newland Co. Ltd. All rights reserved. * * @Description:异步查询接口定义 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; public interface BatchQuery<IN, OUT> { OUT query(IN input) throws Exception; }
好了,现在封装一个异步并行查询执行器BatchQueryExecutor
/** * @filename:BatchQueryExecutor.java * * Newland Co. Ltd. All rights reserved. * * @Description:异步并行查询执行器 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import com.google.common.util.concurrent.ListenableFuture; import com.google.common.util.concurrent.ListeningExecutorService; import com.google.common.util.concurrent.FutureCallback; import com.google.common.util.concurrent.Futures; import com.google.common.util.concurrent.MoreExecutors; import org.apache.commons.collections.Closure; import org.apache.commons.collections.CollectionUtils; import org.apache.commons.collections.functors.ForClosure; import java.util.concurrent.Callable; import java.util.concurrent.ExecutionException; import java.util.concurrent.Executors; import java.util.Collection; import java.util.HashSet; import java.util.List; import java.util.Set; public class BatchQueryExecutor { private final static int FUTUREQUERYNUMBER = 1; public BatchQueryExecutor() { } public <IN, OUT> List<OUT> executeQuery(final Collection<IN> inputs,final BatchQuery<IN, OUT> executeUnit) { ListenableFuture<List<OUT>> futures = submitBatchTaskFutures(inputs,executeUnit); delegateAsynTask(futures); return getAsynResults(futures); } private <IN, OUT> ListenableFuture<List<OUT>> submitBatchTaskFutures( final Collection<IN> inputs, final BatchQuery<IN, OUT> executeUnit) { final Set<ListenableFuture<OUT>> result = new HashSet<ListenableFuture<OUT>>( inputs.size()); final ListeningExecutorService service = MoreExecutors .listeningDecorator(Executors.newFixedThreadPool(inputs.size())); Closure futureQuery = new Closure() { public void execute(Object input) { final IN p = (IN) input; result.add(service.submit(new Callable<OUT>() { @Override public OUT call() throws Exception { return executeUnit.query(p); } })); } }; Closure parallelTask = new ForClosure(FUTUREQUERYNUMBER, futureQuery); CollectionUtils.forAllDo(inputs, parallelTask); service.shutdown(); return Futures.allAsList(result); } private <OUT> OUT getAsynResults(final ListenableFuture<OUT> futures) { try { return futures.get(); } catch (InterruptedException ex) { throw new BatchQueryInterruptedException(ex); } catch (ExecutionException ex) { throw new BatchQueryExecutionException(ex); } } private <TYPE> void delegateAsynTask( final ListenableFuture<TYPE> allFutures) { Futures.addCallback(allFutures, new FutureCallback<TYPE>() { @Override public void onSuccess(final TYPE result) { System.out.println("并行加载查询执行成功"); } @Override public void onFailure(final Throwable thrown) { System.out.println("并行加载查询执行失败"); } }); } }
最后的并行查询加载模块BatchQueryLoader直接就是调用上面的异步并行查询执行器BatchQueryExecutor,完成不同数据源的数据并行异步加载,代码如下
/** * @filename:BatchQueryLoader.java * * Newland Co. Ltd. All rights reserved. * * @Description:并行查询加载模块 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import java.util.ArrayList; import java.util.Arrays; import java.util.Collection; import java.util.Iterator; import java.util.List; public class BatchQueryLoader { private final Collection<StatementWrapper> statements = new ArrayList<StatementWrapper>(); public void attachLoadEnv(final String sql, final Statement statement, final Connection con) { statements.add(new StatementWrapper(sql, statement, con)); } public Collection<StatementWrapper> getStatements() { return statements; } public void close() throws SQLException { Iterator<StatementWrapper> iter = statements.iterator(); while (iter.hasNext()) { iter.next().getCon().close(); } } public List<ResultSet> executeQuery() throws SQLException { List<ResultSet> result; if (1 == statements.size()) { StatementWrapper entity = statements.iterator().next(); result = Arrays.asList(entity.getStatement().executeQuery( entity.getSql())); return result; } else { BatchQueryExecutor query = new BatchQueryExecutor(); result = query.executeQuery(statements, new BatchQuery<StatementWrapper, ResultSet>() { @Override public ResultSet query(final StatementWrapper input) throws Exception { return input.getStatement().executeQuery( input.getSql()); } }); return result; } } }
- 批量处理线程池运行参数配置加载BatchTaskConfigurationLoader模块,主要从负责从batchtask-configuration.xml中加载线程池的运行参数。BatchTaskConfiguration批处理线程池运行参数对应的JavaBean结构
/** * @filename:BatchTaskConfiguration.java * * Newland Co. Ltd. All rights reserved. * * @Description:批处理线程池参数配置 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import org.apache.commons.lang.builder.EqualsBuilder; import org.apache.commons.lang.builder.HashCodeBuilder; import org.apache.commons.lang.builder.ToStringBuilder; import org.apache.commons.lang.builder.ToStringStyle; public class BatchTaskConfiguration { private String name; private int corePoolSize; private int maxPoolSize; private int keepAliveTime; private int workQueueSize; public void setName(String name) { this.name = name; } public String getName() { return this.name; } public int getCorePoolSize() { return corePoolSize; } public void setCorePoolSize(int corePoolSize) { this.corePoolSize = corePoolSize; } public int getMaxPoolSize() { return maxPoolSize; } public void setMaxPoolSize(int maxPoolSize) { this.maxPoolSize = maxPoolSize; } public int getKeepAliveTime() { return keepAliveTime; } public void setKeepAliveTime(int keepAliveTime) { this.keepAliveTime = keepAliveTime; } public int getWorkQueueSize() { return workQueueSize; } public void setWorkQueueSize(int workQueueSize) { this.workQueueSize = workQueueSize; } public int hashCode() { return new HashCodeBuilder(1, 31).append(name).toHashCode(); } public String toString() { return new ToStringBuilder(this, ToStringStyle.SHORT_PREFIX_STYLE) .append("name", name).append("corePoolSize", corePoolSize) .append("maxPoolSize", maxPoolSize) .append("keepAliveTime", keepAliveTime) .append("workQueueSize", workQueueSize).toString(); } public boolean equals(Object o) { boolean res = false; if (o != null && BatchTaskConfiguration.class.isAssignableFrom(o.getClass())) { BatchTaskConfiguration s = (BatchTaskConfiguration) o; res = new EqualsBuilder().append(name, s.getName()).isEquals(); } return res; } }
当然了,你进行参数配置的时候,还可以指定多个线程池,于是要设计一个:批处理线程池工厂类BatchTaskThreadFactoryConfiguration,来依次循环保存若干个线程池的参数配置
/** * @filename:BatchTaskThreadFactoryConfiguration.java * * Newland Co. Ltd. All rights reserved. * * @Description:线程池参数配置工厂 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.util.Map; import java.util.HashMap; public class BatchTaskThreadFactoryConfiguration { // 批处理线程池参数配置 private Map<String, BatchTaskConfiguration> batchTaskMap = new HashMap<String, BatchTaskConfiguration>(); public BatchTaskThreadFactoryConfiguration() { } public void joinBatchTaskConfiguration(BatchTaskConfiguration batchTaskConfiguration) { if (batchTaskMap.containsKey(batchTaskConfiguration.getName())) { return; }else{ batchTaskMap.put(batchTaskConfiguration.getName(), batchTaskConfiguration); } } public Map<String, BatchTaskConfiguration> getBatchTaskMap() { return batchTaskMap; } }
剩下的是,加载运行时参数配置模块BatchTaskConfigurationLoader
/** * @filename:BatchTaskConfigurationLoader.java * * Newland Co. Ltd. All rights reserved. * * @Description:线程池参数配置加载 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.io.InputStream; import org.apache.commons.digester.Digester; public final class BatchTaskConfigurationLoader { private static final String BATCHTASK_THREADPOOL_CONFIG = "./newlandframework/batchtask/parallel/batchtask-configuration.xml"; private static BatchTaskThreadFactoryConfiguration config = null; private BatchTaskConfigurationLoader() { } // 单例模式为了控制并发要进行同步控制 public static BatchTaskThreadFactoryConfiguration getConfig() { if (config == null) { synchronized (BATCHTASK_THREADPOOL_CONFIG) { if (config == null) { try { InputStream is = getInputStream(); config = (BatchTaskThreadFactoryConfiguration) getDigester().parse(getInputStream()); } catch (Exception e) { e.printStackTrace(); } } } } return config; } private static InputStream getInputStream() { return BatchTaskConfigurationLoader.class.getClassLoader() .getResourceAsStream(BATCHTASK_THREADPOOL_CONFIG); } private static Digester getDigester() { Digester digester = new Digester(); digester.setValidating(false); digester.addObjectCreate("batchtask", BatchTaskThreadFactoryConfiguration.class); // 加载批处理异步批处理线程池参数配置 digester.addObjectCreate("*/jobpool", BatchTaskConfiguration.class); digester.addSetProperties("*/jobpool"); digester.addSetProperty("*/jobpool/attribute", "name", "value"); digester.addSetNext("*/jobpool", "joinBatchTaskConfiguration"); return digester; } }
上面的这些模块主要是针对线程池的运行参数可以调整而设计准备的。
- 并行异步批处理模块BatchTaskReactor主要类图结构如下
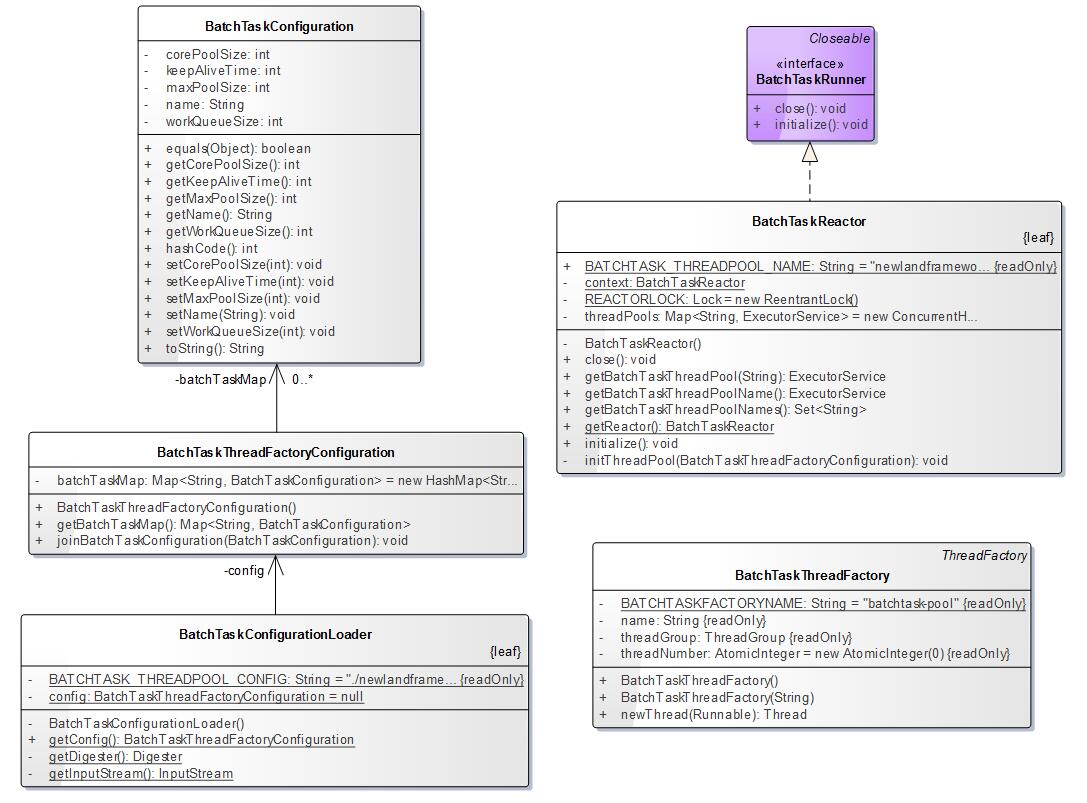 BatchTaskRunner这个接口,主要定义了批处理框架要初始化和回收资源的动作。
BatchTaskRunner这个接口,主要定义了批处理框架要初始化和回收资源的动作。
/** * @filename:BatchTaskRunner.java * * Newland Co. Ltd. All rights reserved. * * @Description:批处理资源管理定义接口 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.io.Closeable; public interface BatchTaskRunner extends Closeable { public void initialize(); public void close(); }
我们还要重新实现一个线程工厂类BatchTaskThreadFactory,用来管理我们线程池当中的线程。我们可以把线程池当中的线程放到线程组里面,进行统一管理。比如线程池中的线程,它的运行状态监控等等处理,你可以通过重新生成一个监控线程,
来运行、跟踪线程组里面线程的运行情况。当然你还可以重新封装一个JMX(Java Management Extensions)的MBean对象,通过JMX方式对线程池进行监控处理,本文的后面,有给出运用JMX技术,进行批处理线程池任务完成情况监控的实现,实现线程池中线程运行状态的监控可以参考一下。这里就不具体给出,线程池线程状态监控的JMX模块代码了。言归正传,线程工厂类BatchTaskThreadFactory的实现如下/** * @filename:BatchTaskThreadFactory.java * * Newland Co. Ltd. All rights reserved. * * @Description:线程池工厂 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.util.concurrent.atomic.AtomicInteger; import java.util.concurrent.ThreadFactory; public class BatchTaskThreadFactory implements ThreadFactory { final private static String BATCHTASKFACTORYNAME = "batchtask-pool"; final private String name; final private ThreadGroup threadGroup; final private AtomicInteger threadNumber = new AtomicInteger(0); public BatchTaskThreadFactory() { this(BATCHTASKFACTORYNAME); } public BatchTaskThreadFactory(String name) { this.name = name; SecurityManager security = System.getSecurityManager(); threadGroup = (security != null) ? security.getThreadGroup() : Thread.currentThread().getThreadGroup(); } @Override public Thread newThread(Runnable runnable) { Thread thread = new Thread(threadGroup, runnable); thread.setName(String.format("BatchTask[%s-%d]", threadGroup.getName(), threadNumber.incrementAndGet())); System.out.println(String.format("BatchTask[%s-%d]", threadGroup.getName(), threadNumber.incrementAndGet())); if (thread.isDaemon()) { thread.setDaemon(false); } if (thread.getPriority() != Thread.NORM_PRIORITY) { thread.setPriority(Thread.NORM_PRIORITY); } return thread; } }
下面是关键模块:并行异步批处理模块BatchTaskReactor的实现代码,主要还是对ThreadPoolExecutor进行地封装,考虑使用有界的数组阻塞队列ArrayBlockingQueue,还是为了防止:生产者无休止的请求服务,导致内存崩溃,最终做到内存使用可控
采取的措施。/** * @filename:BatchTaskReactor.java * * Newland Co. Ltd. All rights reserved. * * @Description:批处理并行异步线程池处理模块 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.util.Set; import java.util.Map; import java.util.Map.Entry; import java.util.concurrent.ExecutorService; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.BlockingQueue; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.TimeUnit; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; public final class BatchTaskReactor implements BatchTaskRunner { private Map<String, ExecutorService> threadPools = new ConcurrentHashMap<String, ExecutorService>(); private static BatchTaskReactor context; private static Lock REACTORLOCK = new ReentrantLock(); public static final String BATCHTASK_THREADPOOL_NAME = "newlandframework_batchtask"; private BatchTaskReactor() { initialize(); } // 防止并发重复创建批处理反应器对象 public static BatchTaskReactor getReactor() { if (context == null) { try { REACTORLOCK.lock(); if (context == null) { context = new BatchTaskReactor(); } } finally { REACTORLOCK.unlock(); } } return context; } public ExecutorService getBatchTaskThreadPoolName() { return getBatchTaskThreadPool(BATCHTASK_THREADPOOL_NAME); } public ExecutorService getBatchTaskThreadPool(String poolName) { if (!threadPools.containsKey(poolName)) { throw new IllegalArgumentException(String.format( "批处理线程池名称:[%s]参数配置不存在", poolName)); } return threadPools.get(poolName); } public Set<String> getBatchTaskThreadPoolNames() { return threadPools.keySet(); } // 关闭线程池,同时等待异步执行的任务返回执行结果 public void close() { for (Entry<String, ExecutorService> entry : threadPools.entrySet()) { entry.getValue().shutdown(); System.out.println(String.format("关闭批处理线程池:[%s]成功", entry.getKey())); } threadPools.clear(); } // 初始化批处理线程池 public void initialize() { BatchTaskThreadFactoryConfiguration poolFactoryConfig = BatchTaskConfigurationLoader.getConfig(); if (poolFactoryConfig != null) { initThreadPool(poolFactoryConfig); } } private void initThreadPool(BatchTaskThreadFactoryConfiguration poolFactoryConfig) { for (Entry<String, BatchTaskConfiguration> entry : poolFactoryConfig.getBatchTaskMap().entrySet()) { BatchTaskConfiguration config = entry.getValue(); // 使用有界的阻塞队列,考虑为了防止生产者无休止的请求服务,导致内存崩溃,最终做到内存使用可控 BlockingQueue<Runnable> queue = new ArrayBlockingQueue<Runnable>(config.getWorkQueueSize()); ThreadPoolExecutor threadPool = new ThreadPoolExecutor( config.getCorePoolSize(), config.getMaxPoolSize(), config.getKeepAliveTime(), TimeUnit.SECONDS, queue, new BatchTaskThreadFactory(entry.getKey()),new ThreadPoolExecutor.CallerRunsPolicy()); threadPools.put(entry.getKey(), threadPool); System.out.println(String.format("批处理线程池:[%s]创建成功",config.toString())); } } }
- 下面设计实现的是:交换机Hlr指令处理任务模块。当然,在后续的业务发展过程中,还可能出现,其他类型指令的任务处理,所以根据“开闭”原则的定义,要抽象出一个接口类:BusinessEvent
/** * @filename:BusinessEvent.java * * Newland Co. Ltd. All rights reserved. * * @Description:业务事件任务接口定义 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.model; public interface BusinessEvent { // 执行具体批处理的任务 public int execute(Integer userId); }
然后具体的Hlr指令发送任务模块HlrBusinessEvent要实现这个接口类的方法,完成用户停复机Hlr指令的派发。代码如下:
/** * @filename:HlrBusinessEvent.java * * Newland Co. Ltd. All rights reserved. * * @Description:Hlr指令派发任务接口定义 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.model; import org.apache.commons.lang.math.RandomUtils; public class HlrBusinessEvent implements BusinessEvent { // 交换机上的指令执行成功失败标识0表示成功 1表示失败 public final static int TASKSUCC = 0; public final static int TASKFAIL = 1; private final static int ELAPSETIME = 1000; @Override public int execute(Integer userId) { // 这里为了举例,随机产生1000以内的随机数 int millis = RandomUtils.nextInt(ELAPSETIME); // 简单模拟往交换机发送停机/复机的指令 try { Thread.sleep(millis); String strContent = String.format( "线程标识[%s]用户标识:[%d]执行交换机指令工单耗时:[%d]毫秒", Thread .currentThread().getName(), userId, millis); System.out.println(strContent); // 这里为了演示直接简单根据随机数是不是偶数简单模拟交换机指令执行的结果 return (millis % 2 == 0) ? TASKSUCC : TASKFAIL; } catch (InterruptedException e) { e.printStackTrace(); return TASKFAIL; } } }
实际运行情况中,我们可能要监控一下指令发送的时长,于是再设计一个:针对Hlr指令发送任务模块HlrBusinessEvent,切面嵌入代理的Hlr指令时长计算代理类:HlrBusinessEventAdvisor,具体的代码如下:
/** * @filename:HlrBusinessEventAdvisor.java * * Newland Co. Ltd. All rights reserved. * * @Description:Hlr指令派发时长计算代理类 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.model; import org.aopalliance.intercept.MethodInterceptor; import org.aopalliance.intercept.MethodInvocation; import org.apache.commons.lang.time.StopWatch; public class HlrBusinessEventAdvisor implements MethodInterceptor { public HlrBusinessEventAdvisor() { } @Override public Object invoke(MethodInvocation invocation) throws Throwable { // 计算一下指令派发时长 StopWatch sw = new StopWatch(); sw.start(); Object obj = invocation.proceed(); sw.stop(); System.out.println("执行交换机指令工单耗时: [" + sw.getTime() + "] 毫秒"); return obj; } }
剩下的,我们由于是要,异步并行计算得到执行结果,于是我们设计一个:批处理Hlr任务执行模块HlrBusinessEventTask,它要实现java.util.concurrent.Callable接口的方法call,它会返回一个异步任务的执行结果。
/** * @filename:HlrBusinessEventTask.java * * Newland Co. Ltd. All rights reserved. * * @Description:Hlr指令派任务执行类 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.model; import java.util.concurrent.Callable; import org.springframework.aop.framework.ProxyFactory; import org.springframework.aop.support.NameMatchMethodPointcutAdvisor; public class HlrBusinessEventTask implements Callable<Integer> { private NotifyUsers user = null; private final static String MAPPERMETHODNAME = "execute"; public HlrBusinessEventTask(NotifyUsers user) { this.user = user; } @Override public Integer call() throws Exception { synchronized (this) { ProxyFactory weaver = new ProxyFactory(new HlrBusinessEvent()); NameMatchMethodPointcutAdvisor advisor = new NameMatchMethodPointcutAdvisor(); advisor.setMappedName(MAPPERMETHODNAME); advisor.setAdvice(new HlrBusinessEventAdvisor()); weaver.addAdvisor(advisor); BusinessEvent proxyObject = (BusinessEvent) weaver.getProxy(); Integer result = new Integer(proxyObject.execute(user.getUserId())); // 返回执行结果 return result; } } }
- 接下来,我们要把并行异步加载的查询结果,和并行异步处理任务执行的模块,给它组合起来使用,故重新封装一个,通知用户批处理任务管理类模块:NotifyUsersBatchTask。它的主要功能是:批量并行异步加载查询待停复机的手机用户,然后把它放入并行异步处理的线程池中,进行异步处理。然后我们打印出,本次批处理的任务一共有多少,成功数和失败数分别是多少(当然,本文还给出了另外一种JMX方式的监控)。NotifyTaskSuccCounter类,主要是统计派发的任务中执行成功的任务的数量,而与之相对应的类NotifyTaskFailCounter,是用来统计执行失败的任务的数量。具体的代码如下
/** * @filename:NotifyUsersBatchTask.java * * Newland Co. Ltd. All rights reserved. * * @Description:通知用户批处理任务管理类 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import javax.sql.DataSource; import java.util.ArrayList; import java.util.List; import java.util.concurrent.ExecutorService; import org.apache.commons.collections.Closure; import org.apache.commons.collections.CollectionUtils; import org.apache.commons.collections.functors.IfClosure; import org.apache.commons.lang.StringUtils; import newlandframework.batchtask.jmx.BatchTaskMonitor; import newlandframework.batchtask.model.NotifyUsers; import newlandframework.batchtask.parallel.BatchQueryLoader; import newlandframework.batchtask.parallel.BatchTaskReactor; public class NotifyUsersBatchTask { public NotifyUsersBatchTask() { } private ArrayList<DataSource> dataSource; // 基于JMX的任务完成情况监控计数器 private BatchTaskMonitor monitor = new BatchTaskMonitor(BatchTaskReactor.BATCHTASK_THREADPOOL_NAME); // 支持同时加载多个数据源 public NotifyUsersBatchTask(ArrayList<DataSource> dataSource) { this.dataSource = dataSource; } // 批处理任务执行成功计数器 class NotifyTaskSuccCounter implements Closure { public static final String NOTIFYTASKSUCCCOUNTER = "TASKSUCCCOUNTER"; private int numberSucc = 0; public void execute(Object input) { monitor.increaseBatchTaskCounter(NOTIFYTASKSUCCCOUNTER); numberSucc++; } public int getSuccNumber() { return numberSucc; } } // 批处理任务执行失败计数器 class NotifyTaskFailCounter implements Closure { public static final String NOTIFYTASKFAILCOUNTER = "TASKFAILCOUNTER"; private int numberFail = 0; public void execute(Object input) { monitor.increaseBatchTaskCounter(NOTIFYTASKFAILCOUNTER); numberFail++; } public int getFailNumber() { return numberFail; } } // 并行加载查询多个水平分库的数据集合 public List<NotifyUsers> query() throws SQLException { BatchQueryLoader loader = new BatchQueryLoader(); String strSQL = "select home_city, msisdn, user_id from notify_users"; for (int i = 0; i < dataSource.size(); i++) { Connection con = dataSource.get(i).getConnection(); Statement st = con.createStatement(); loader.attachLoadEnv(strSQL, st, con); } List<ResultSet> list = loader.executeQuery(); System.out.println("查询出记录总数为:" + list.size()); final List<NotifyUsers> listNotifyUsers = new ArrayList<NotifyUsers>(); for (int i = 0; i < list.size(); i++) { ResultSet rs = list.get(i); while (rs.next()) { NotifyUsers users = new NotifyUsers(); users.setHomeCity(rs.getInt(1)); users.setMsisdn(rs.getInt(2)); users.setUserId(rs.getInt(3)); listNotifyUsers.add(users); } } // 释放连接资源 loader.close(); return listNotifyUsers; } // 批处理数据集合,任务分派 public void batchNotify(List<NotifyUsers> list, final ExecutorService excutor) { System.out.println("处理记录总数为:" + list.size()); System.out.println(StringUtils.center("记录明细如下", 40, "-")); NotifyTaskSuccCounter cntSucc = new NotifyTaskSuccCounter(); NotifyTaskFailCounter cntFail = new NotifyTaskFailCounter(); BatchTaskPredicate predicate = new BatchTaskPredicate(excutor); Closure batchAction = new IfClosure(predicate, cntSucc, cntFail); CollectionUtils.forAllDo(list, batchAction); System.out.println("批处理一共处理:" + list.size() + "记录,处理成功:" + cntSucc.getSuccNumber() + "条记录,处理失败:" + cntFail.getFailNumber() + "条记录"); } }
异步处理任务执行提交模块BatchTaskPredicate,主要是从线程池中采集异步提交要处理的任务,然后根据异步的执行结果,反馈给线程池:这个任务执行成功还是执行失败了。具体代码如下:
/** * @filename:BatchTaskPredicate.java * * Newland Co. Ltd. All rights reserved. * * @Description:批处理异步任务提交执行任务模块 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask; import java.util.concurrent.ExecutorService; import java.util.concurrent.Future; import java.util.concurrent.TimeUnit; import org.apache.commons.collections.Predicate; import newlandframework.batchtask.model.HlrBusinessEvent; import newlandframework.batchtask.model.HlrBusinessEventTask; import newlandframework.batchtask.model.NotifyUsers; public class BatchTaskPredicate implements Predicate { private ExecutorService excutor = null; public BatchTaskPredicate(ExecutorService excutor) { this.excutor = excutor; } public boolean evaluate(Object object) { if (object instanceof NotifyUsers) { NotifyUsers users = (NotifyUsers) object; Future<Integer> future = excutor.submit(new HlrBusinessEventTask(users)); try { // 设定5s超时 Integer result = future.get(5, TimeUnit.SECONDS); return result.intValue() == HlrBusinessEvent.TASKSUCC; } catch (Exception e) { // 如果失败试图取消对此任务的执行 future.cancel(true); e.printStackTrace(); return false; } } else { return false; } } }
最后,我们通过,通知用户批处理任务管理类NotifyUsersBatchTask,它构造的时候,可以通过指定数据库连接池,批量加载多个数据源的数据对象。这里我们假设并行加载cms/ccs两个数据源对应的notify_users表的数据,它的spring配置batchtask-multidb.xml配置内容如下:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"> <property name="locations"> <list> <value>newlandframework/batchtask/jdbc-cms.properties</value> <value>newlandframework/batchtask/jdbc-ccs.properties</value> </list> </property> </bean> <bean id="dtSource-cms" destroy-method="close" class="org.apache.commons.dbcp.BasicDataSource"> <property name="driverClassName" value="${jdbc.cms.driverClassName}"/> <property name="url" value="${jdbc.cms.url}"/> <property name="username" value="${jdbc.cms.username}"/> <property name="password" value="${jdbc.cms.password}"/> </bean> <bean id="dtSource-ccs" destroy-method="close" class="org.apache.commons.dbcp.BasicDataSource"> <property name="driverClassName" value="${jdbc.ccs.driverClassName}"/> <property name="url" value="${jdbc.ccs.url}"/> <property name="username" value="${jdbc.ccs.username}"/> <property name="password" value="${jdbc.ccs.password}"/> </bean> <bean id="notifyUsers" class="newlandframework.batchtask.NotifyUsersBatchTask"> <constructor-arg name="dataSource"> <list> <ref bean="dtSource-ccs"/> <ref bean="dtSource-cms"/> </list> </constructor-arg> </bean> </beans>
- 我们再来实现一种,通过JMX方式进行线程池批处理任务完成情况的监控模块。首先定义一个MBean接口,它根据计数器的名称,返回计数结果。
/** * @filename:BatchTaskMonitorMBean.java * * Newland Co. Ltd. All rights reserved. * * @Description:JMX批处理任务监控接口 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.jmx; public interface BatchTaskMonitorMBean { public int getBatchTaskCounter(String taskName); }
我们再来实现这个接口,于是设计得到BatchTaskMonitor模块
/** * @filename:BatchTaskMonitor.java * * Newland Co. Ltd. All rights reserved. * * @Description:JMX批处理任务监控模块 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.jmx; import javax.management.AttributeChangeNotification; import javax.management.NotificationBroadcasterSupport; import javax.management.ObjectName; import javax.management.InstanceAlreadyExistsException; import javax.management.MBeanRegistrationException; import javax.management.MalformedObjectNameException; import javax.management.NotCompliantMBeanException; import java.util.concurrent.atomic.AtomicInteger; import java.lang.management.ManagementFactory; import java.text.MessageFormat; import java.util.HashMap; import java.util.Map; public class BatchTaskMonitor extends NotificationBroadcasterSupport implements BatchTaskMonitorMBean { private static final String TASKMONITOR_NAME = "newlandframework.batchtask.jmx.{0}:type=BatchTaskMonitor"; Map<String, AtomicInteger> batchTaskCounter; private int sequenceTaskNumber = 0; // 注册MBean,内置计数器,实时监控批处理任务的成功/失败情况 public BatchTaskMonitor(String taskName) { batchTaskCounter = new HashMap<String, AtomicInteger>(); try { registerMBean(taskName); } catch (InstanceAlreadyExistsException e) { System.out.println("InstanceAlreadyExistsException BatchTaskMonitor Register Fail"); } catch (MBeanRegistrationException e) { System.out.println("MBeanRegistrationException BatchTaskMonitor Register Fail"); } catch (NotCompliantMBeanException e) { System.out.println("NotCompliantMBeanException BatchTaskMonitor Register Fail"); } catch (MalformedObjectNameException e) { System.out.println("MalformedObjectNameException BatchTaskMonitor Register Fail"); } } private void registerMBean(String taskName) throws InstanceAlreadyExistsException, MBeanRegistrationException, NotCompliantMBeanException, MalformedObjectNameException { String strObjectName = MessageFormat.format(TASKMONITOR_NAME, taskName); ManagementFactory.getPlatformMBeanServer().registerMBean(this, new ObjectName(strObjectName)); } // 批处理任务计数器递增 public void increaseBatchTaskCounter(String taskName) { if (batchTaskCounter.containsKey(taskName)) { notifyMessage(taskName, batchTaskCounter.get(taskName).incrementAndGet()); } else { batchTaskCounter.put(taskName, new AtomicInteger(1)); } } private void notifyMessage(String taskName, int batchNewTaskCounter) { sendNotification(new AttributeChangeNotification(this, sequenceTaskNumber++, System.currentTimeMillis(), "batchTaskCounter \"" + taskName + "\" incremented", "batchTaskCounter", "int", batchNewTaskCounter - 1, batchNewTaskCounter)); } // 获取计数器的计数结果 public int getBatchTaskCounter(String taskName) { if (batchTaskCounter.containsKey(taskName)) { return batchTaskCounter.get(taskName).intValue(); } else { return 0; } } }
其中,计数器的名称,我已经在NotifyUsersBatchTask模块中已经指定了。批处理任务执行成功计数器叫做:String NOTIFYTASKSUCCCOUNTER = "TASKSUCCCOUNTER"。批处理任务执行失败计数器叫做String NOTIFYTASKFAILCOUNTER = "TASKFAILCOUNTER"。这样我们就可以通过JConsole实现,监控线程池任务的运行处理情况了。
- 最终,我们要把上面所有的模块全部“组装”起来。客户端调用方式的参考代码,样例如下所示
try { // 初始化并行异步任务执行反应器 BatchTaskReactor reactor = BatchTaskReactor.getReactor(); final ExecutorService excutor = reactor.getBatchTaskThreadPool(BatchTaskReactor.BATCHTASK_THREADPOOL_NAME); List<NotifyUsers> listNotifyUsers = null; NotifyUsersBatchTask notifyTask = (NotifyUsersBatchTask) context.getBean("notifyUsers"); // 并行查询水平分库的结果 listNotifyUsers = notifyTask.query(); StopWatch sw = new StopWatch(); sw.start(); // 并行异步批处理查询结果集合 notifyTask.batchNotify(listNotifyUsers, excutor); sw.stop(); reactor.close(); String strContent = String.format("=========批处理并行任务执行结束,耗时[%d]毫秒=========", sw.getTime()); System.out.println(strContent); } catch (SQLException e) { e.printStackTrace(); }
我们再来运行一下,看下结果如何?先在数据库中分别插入福州591、厦门592一共80条的待处理数据(实际上,你可以插得更多,越多越能体现出这种异步并行批处理框架的价值)。运行截图如下:

正如我们所预想地那样。很好。
现在,我们再通过JMX技术,查看监控一下,并行批处理异步线程池任务的完成情况吧。我们先连接上我们的MBean对象BatchTaskMonitor。
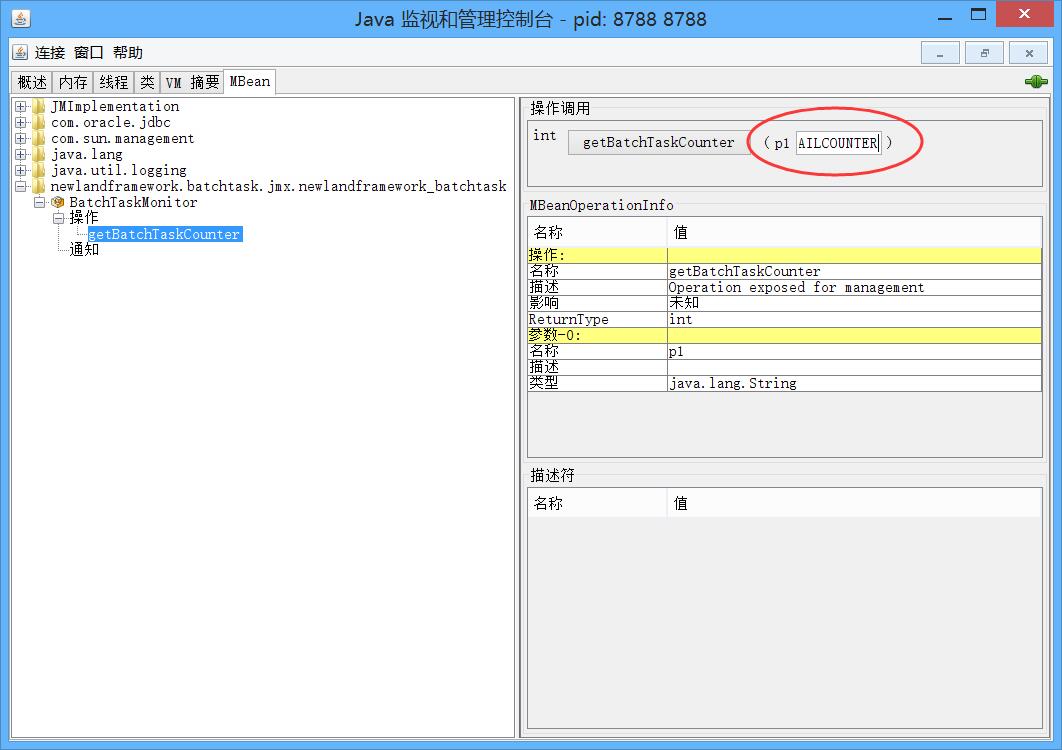
发现里面有个暴露的操作方法getBatchTaskCounter(根据计数器名称返回计数结果)。我们在上面红圈的输入框内,输入统计失败任务个数的计数器TASKFAILCOUNTER,然后点击确定。最后运行结果如下所示:
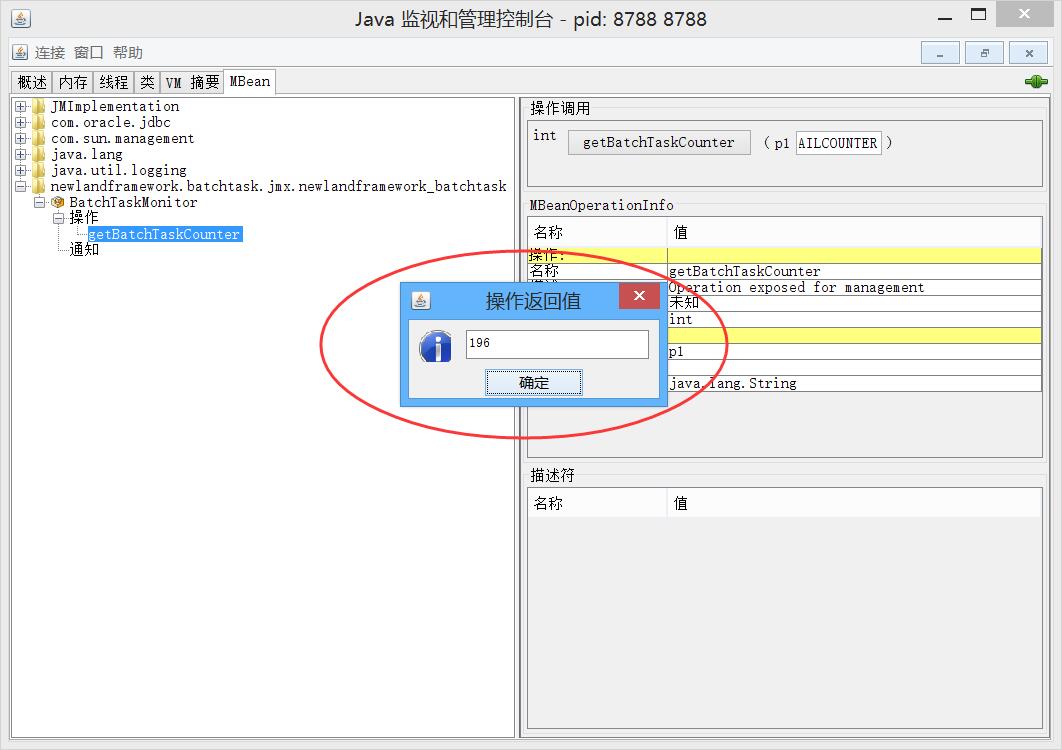
发现我们批处理任务,目前已经处理失败了196个啦!正如我们希望的那样,可视化实时监控的感觉非常好。
写在最后
最终,我们通过并行异步加载技术和线程池机制设计出了一个精简的批处理框架。上面的代码虽然不算多,但是,有它很独特的应用场景,麻雀虽小五脏俱全。相信它对于其他的同行朋友,还是很有借鉴意义的。况且现在的服务器都是多核、多CPU的配置,我们要很好地利用这一硬件资源。对于IO密集型的应用,可以根据上面的思路,加以改良,相信一定能收到不错的效果!
好了,不知不觉地写了这么多的内容和代码。本文的前期准备、编码、调试、文章编写工作,也消耗了本人大量的脑力和精力。不过还是挺开心的,想着能把自己的一些想法通过博客的方式沉淀下来,对别人有借鉴意义,而对自己则是一种“学习和总结”。路漫漫其修远兮,吾将上下而求索。故在此,抛砖引玉。如果本人有说地不对的地方,希望各位园友批评指正!不吝赐教!