领域驱动设计也就是3D(Domain-Driven Design)已经有了10年的历史,我相信很多人或多或少都听说过这个名词,但是有多少人真正懂得如何去运用它,或者把它运用好呢?于是有人说,DDD和TDD这些玩意是一些形而上的东西,只是一茶余饭后的谈资,又或是放到简历上提升逼格而已。前面这句话我写完之后犹豫了,犹豫要不要把它删掉,因为它让我看起来像个喷子,我确实感到不解,为什么别人10年前创造总结出来的东西,我们在10年之后对它的理解还处于这么低的一个层次。开篇就说远了,我也是最近才开始认真学习领域驱动设计,并且得到了园子里面netfocus,刘标才和田园里的蟋蟀的帮助,在此再次表示感谢。希望能和大家一起把DDD普及下去。
我们之前有一个关于领域驱动设计的讨论,另外dax.net也有一个关于领域驱动设计的系列写得不错,有兴趣的同学可以看看。本文会以一个初学者的角度来讲解DDD,让我们一切从零开始,我相信你跟我一样也会爱上它的。
本篇主要讨论一下为什么我们要用DDD,它能够为我们带来什么?
领域驱动系列 初探领域驱动设计(1)为复杂业务而生
初探领域驱动设计(2)EF 和 Repository
初探领域驱动设计(3)写好单元测试
......
- 一点废话,我们需要好的设计么?
- 从设计阶段出发 - 站在业务的角度思考问题
- 建模:区分实体、值对象和领域服务
- 厘清业务关系 - 聚合与聚合根
- 独立领域业务层 - 高内聚,低耦合,可测试
- 干净漂亮的代码
- 小结
当我们学习一些设计模式或者框架的时候,总有人会站出来和你说“这些都没有用,只要能实现功能就行了。” 在这里并非针对某个人,实际上我认为他们说的是对的,在资源有限的情况下,我们为了完成项目的交付,这是我们最好的选择。但是别忘了,欠下的债总是要还的,以实现功能为导向的项目务必会造成维护性的大大降低,如果只是一个临时随便用用的东西倒是可以一试,但如果是要长期进行更新的产品,那后期就会拖该产品的后腿。
我们团队现在维护着一个有着20多年历史的产品,该产品是一个酒店、餐饮行业的POS系统,在美国和亚太地区都占有着比较大的市场份额。该产品从C,C++,VB6一路更新,直到现在的C#,但是很可惜不是整体替换,而是局部的,所以现在项目里面这4种代码全都有。可能你会觉得这玩的是混搭,是潮流,但事实是,一旦产品上线之后,会有很多的新功能,老bug等在那里,再加上“重市场轻技术”的高层在那里制订战略,你压根就没有时间或者没有多少时间去重构。日积月累,等着你的就是每一次改代码都如履薄冰,一不小心就因为改一个bug而整出好几个新bug出来,前不久我们为了新版本的发布就停下所有开发的任务,大家集体花了1个月的时间去做回归测试了。因为前期发布新版本之后bug太多,所以这次老大们都不敢轻易发布了。:)
这是我们血的教训,如果你前期只顾开发功能,最后就会让你很难再开发新功能。所以真诚的希望大家不要再片面的说“只要实现功能就可以了!”,软件开发的领域这么大,我们没有必要把自己局限在某一个框框里面。对于大型系统来说,我们要学习的地方还有很多:
- 组织良好、可阅读性高的代码可以让其它开发人员很容易的开始去修改代码。
- 低耦合,高内聚 - 适合运用设计模式以及原则来设计一些好的框架可以降低修改代码引发新bug的风险。
- 良好的单元测试以及集成测试可以及时的帮助我们检测新增或修改的代码是否会破坏原有的逻辑。
- 自动化测试绝对是省时省力的好帮手,也是项目质量的保证。
- 持续集成可以帮助我们更快速安全的进行迭代。
上面说了这么多也没有提到DDD,那么为什么它能够在构建复杂系统的时候有优势呢?我们可以从以下几个点去思考:
- 从设计阶段出发,站在业务的角度思考问题
- 厘清业务主次
- 独立领域业务层,打通开发和测试阶段
- 干净的代码
除了DDD,现在还流行另外一个词汇TDD。但是不知道大家有没有注意到DDD(Domain-Driven Design)中的D代表着设计,而TDD(Test-Driven Development)中的D代表着开发,你有没有曾几何时把领域驱动设计说成领域驱动开发呢?当然我们确实是可以根据领域驱动来开发,但是DDD被设计出来的完美初衷却是设计。TDD强调的已经是开发了,要求开发人员先写单元测试然后再通过不断的迭代重构让单元测试通过,以此来实现功能。这样做的好处是强迫让开发人员清楚正确的理解需求,要知道这年头没有正确理解需求就开始写代码的程序员大有人在,并且我不认为需求就是业务,需求已经是将本来的业务理解之后,转化为了通过计算机可以实现的一些功能定义,通常是业务分析师或者项目经理会去完成这个工作。而DDD中的D(领域)更像是本来的业务,所以在领域驱动设计的时候,开发人员或者架构师直接与领域专家(或者说客户)进行沟通来建模,这些业务模型也是以后开发人员进行设计和实现的依据。
领域模型被当作开发人员之间,开发人员与领域专家之间沟通的桥梁,这样可以闭免开发人员用错误的方式去实现功能。实际上很多优秀的开发人员,都会很自然的将现实世界中的问题进行抽象,然后用计算机的语言表示出来,我们称之为面向对象。但是由于缺少亲临其境的体验,往往会离真实的业务模型有一些距离。
我们举一个例子来说明一下这个问题,假如我们要开发一个电子商务的网站,这个需求已经非常清楚了,现在那么多的电子商务网站直接照抄一个就可以了。现在我们来做一个下单的功能,来看看怎么去实现 。
作为一个高级程序员,我们得用面向对象的方式去开发,先建类。于是我们有了用户,订单,订单项的类,用户创建订单然后往订单里面添加商品,添加订单项的时候为了方便,我们只需要传入产品ID和数量就可以了,于是Order类有一个AddItem的方法。
作为一个高级程序员,一看这图感觉很完美,有木有? 好,下面开始实现AddItem方法。
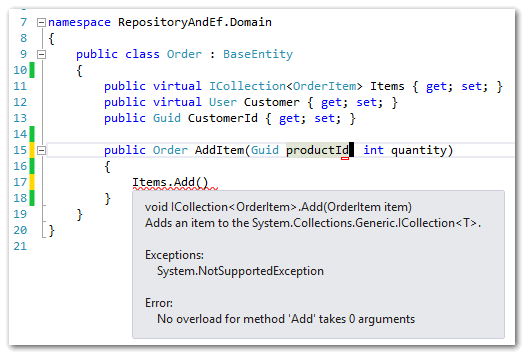
Order里面是一个OrderItem的集合,而这个AddItem的方法接收的是productId,我去哪里搞个Product对象给你?我不可能在这个实体里面直接去查数据库吧?本来是冲着这个技术点想咨询一下大家,后来在小组里面讨论了一下,我恍然大悟,上面的实体就是我从代码的层面去思考想出来的,下单嘛,当然是用户,订单和订单项喽。可是只要去网上买过东西都知道,用户是不会直接往订单里面加东西的,而是先把商品加入购物车,然后再通过“结算”一次性就根据购物车生成了一张订单,压根没有往订单里面添加订单项的行为。这才是真正的用户行为(领域逻辑)所以后来,我们的实体变成这样了:
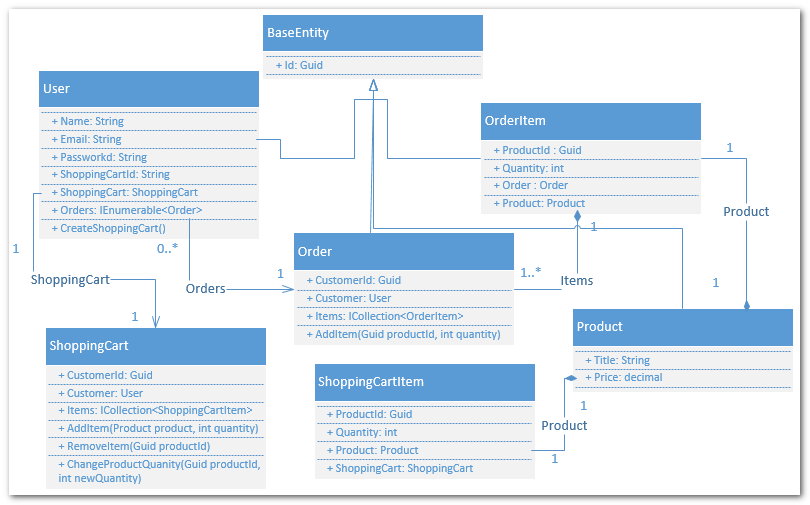
所以业务是这样的:
未注册用户也可以将商品添加到购物车中,但是不能下订单。
并且购物车中的商品不能保存起来,用户离开这个网站(一般是关掉浏览器),购物车中的商品就会消失。
注册用户购物车中的商品可以长期永久保存,通过购物车的“结算功能”,将购物车中选中的商品转化为订单。
所以购物车,应该在用户注册的时候就应该创建好,对应我们上面的User实体中的CreatShoppingCart()方法。下面我们先来简单实现一下注册的代码。
//User领域实体代码


1 namespace RepositoryAndEf.Domain 2 { 3 public class User : BaseEntity 4 { 5 public string Name { get; set; } 6 public string Email { get; set; } 7 public string Password { get; set; } 8 public Guid ShoppingCartId { get; set; } 9 public virtual ShoppingCart ShoppingCart { get; set; } 10 public virtual ICollection<Order> Orders { get; set; } 11 12 public void CreateShoppingCart() 13 { 14 ShoppingCart = new ShoppingCart 15 { 16 Id = Guid.NewGuid(), 17 Customer = this, 18 CustomerId = Id, 19 }; 20 21 ShoppingCartId = ShoppingCart.Id; 22 } 23 } 24 }View Code
//领域层 UserService.cs代码
1 namespace RepositoryAndEf.Domain 2 { 3 public class UserService 4 { 5 private IRepository<User> _userRepository; 6 7 public UserService(IRepository<User> userRepsoitory) 8 { 9 _userRepository = userRepsoitory; 10 } 11 12 public virtual User Register(string email, string name, string password) 13 { 14 var user = new User 15 { 16 Id = Guid.NewGuid(), 17 Email = email, 18 Name = name, 19 Password = password 20 }; 21 22 user.CreateShoppingCart(); 23 _userRepository.Insert(user); 24 return user; 25 } 26 } 27 }View Code
//应用层 UserService.cs代码
1 namespace RepositoryAndEf.Service 2 { 3 public class UserService : IUserService 4 { 5 protected Domain.UserService DomainuUserService 6 { 7 get 8 { 9 return EngineContext.Current.Resolve<Domain.UserService>(); 10 } 11 } 12 13 public User Register(string email, string name, string password) 14 { 15 var user = DomainuUserService.Register(email, name, password); 16 return user; 17 } 18 } 19 }View Code
上面是我们一次建模的过程,是一个将业务转变成代码,将现实世界抽象成软件世界的过程。我们需要画出模型不断的与业务人员(领域专家)去沟通,然后不断的重构去完善我们的模型,以至于这个模型能最准确的反映真实的业务。这是在最开始的设计阶段,是需求沟通阶段就需要做的工作,并且会一直贯穿我们后面的开发甚至维护阶段,没有人可以一开始就把领域模型建的100%准确,需求是复杂的,并且需求还是随时变化的,所以模型也会一直发生改变。它将作为开发人员与业务人员、测试人员以及开发人员自己之间沟通的桥梁。而DDD与其它方法论的区别之处就在于,它还提供了一整套的体系来保证后续对领域模型的重构不会让系统变得四分五裂,比如架构分层,仓储,依懒注入等等,我们后面再慢慢探讨。
在DDD中,领域模型分为三种:
- 实体
- 值对象
- 领域服务
我们不打算去解释以上的概念,我相信只要你搜索一下就可以得到很全面准确的答案。但是重要的是我们一定要理解3者之间的区别,什么时候是实体,什么时候是值对象,又是什么时候我们该用领域服务呢?我想这是刚接触DDD的人都难免会有些纠结的地方吧,在这里就强调一下。
实体相对于值对象而言拥有“标识”的概念,标识可以让我们持续性的跟踪实体。标识和数据库里面的“主键”是不一样的概念,主键是技术上的概念,但是标识是业务上的概念。
在我们上面的例子中用户ID是标识,我们用它来持续性的跟踪我们的用户。订单ID是标识,我们用它来持续性的跟踪订单,同时我们的用户和订单都是有着不同的状态。但是对于用户的地址来说,我们用什么来做标识呢?在电子商务网站这样的业务里面,我们不需要去持续的跟踪这个地址信息,它在我们的系统里面也不会有着像订单从“创建”、“已付款”、“已发货”、“已收货”等这样的状态,所以地址信息的我们系统中就是一个值对象。
但是我们如果换了一个系统,比如说死慢的长城宽带,他们把地址作为跟踪对象。同一个地址,谁都可以去注册,但是同一个时间只允许一个人去注册,那么这个地址对于长城宽带来说就去要去持续性的跟踪,有“开户”,“销户”的状态。那么地址信息对于长城宽带来说就是一个实体。
解决完实体和值对象,领域服务就好说了,一些重要的领域操作,既不属于实体也不属于值对象,那就可以把它放到服务中了。比如说我们上面的领域服务UserService里面的注册操作,注册这个操作可以说就是将这个用户保存到我们的系统中。在注册之间,这个用户是不存在的,我们又怎么能把注册这个操作放到User实体中去呢?所以把它放到领域服务中成了我们最好的选择。
即使是这样,哪些操作应该放到领域服务中对于很多初学者来说还是一件比较难选择的问题。也许只有慢慢的对业务越来越了解,对DDD应用的越来越熟,我们就会少一点纠结。
厘清业务主次-聚合与聚合根在上面的模型中,我们有很多关系的存在:用户-购物车(1对1),用户-订单-订单项-产品(1对多,1对1),购物车-购物车项-产品等。在DDD中,我们把这样多个模型用关联串起来组成一个聚合(aggregation)。
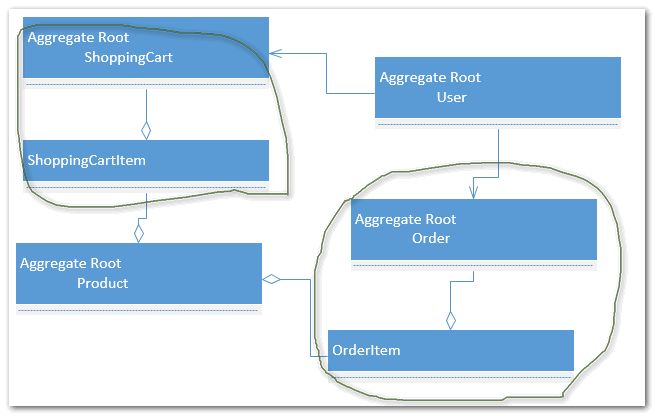
在我们的模型中,购物车-购物车项是一个聚合,订单-订单项是一个聚合。我们通常需要保护这些聚合的一致性,比如说我们把一个订单删掉了,那么这个订单的订单项也需要一起删除,否则他们存在也没有任何的意义。以前我们还会用到触发器,但是大家都知道这个东西维护起来比较麻烦,写起来也不方便等,所以后来大家都是在代码中来控制。但是一直没有一个好的约束说我们如何去更好的控制这些一致性,代码一直都很散乱,直到DDD,我们有了聚合和聚合根的概念,“我们通过为每一个聚合选择一个根,并通过根来控制所有对边界内的对象的访问。外部对象只能持有根的引用;由于根控制了访问,因此我们无法绕过它去修改内部元素。我们后面还会说到只能为根来建立Repository,这也是为了确保我们这里面讲的数据的一致性。
在我们上面的聚合中,只能通过购物车实体来操作购物车项,而不能你自己写一个保存的方法直接就把购物车项给保存到数据库中去了。这就是聚合和聚合根起到的作用。我们来看一下我们购物车实体的代码:
1 namespace RepositoryAndEf.Domain 2 { 3 public class ShoppingCart : BaseEntity 4 { 5 public ShoppingCart() 6 { 7 Items = new List<ShoppingCartItem>(); 8 } 9 10 #region Properties 11 12 public Guid CustomerId { get; set; } 13 public virtual User Customer { get; set; } 14 public virtual ICollection<ShoppingCartItem> Items { get; set; } 15 16 #endregion 17 18 #region Methods 19 public void AddItem(Product product, int quantity) 20 { 21 // 如果该产品ID已经存在于购物车中,我们直接更改数量即可 22 var repetitiveCartItem = Items.FirstOrDefault( 23 i => i.ProductId == product.Id); 24 25 if (repetitiveCartItem != null) 26 { 27 repetitiveCartItem.Quantity += quantity; 28 return; 29 } 30 31 Items.Add(new ShoppingCartItem 32 { 33 Product = product, 34 ProductId = product.Id, 35 Quantity = quantity, 36 }); 37 } 38 39 // 更改购物车数量 40 public void ChangeProductQuantity(Guid productId, int newQuantity) 41 { 42 var items = Items as ICollection<ShoppingCartItem>; 43 var existingCartItem = items.FirstOrDefault( 44 i => i.ProductId == productId); 45 46 if (existingCartItem == null) 47 { 48 throw new InvalidOperationException( 49 "Cannot find the product in shopping cart"); 50 } 51 existingCartItem.Quantity = newQuantity; 52 } 53 54 // 从购物车中移除该产品 55 public void RemoveItem(Guid productId) 56 { 57 var items = Items as ICollection<ShoppingCartItem>; 58 var existingCartItem = items.FirstOrDefault( 59 i => i.ProductId == productId); 60 61 if (existingCartItem == null) 62 { 63 throw new InvalidOperationException( 64 "Cannot find the product in shopping cart"); 65 } 66 67 items.Remove(existingCartItem); 68 } 69 #endregion 70 } 71 }View Code
大家可以看到我们购物车实体的逻辑很清晰,因为我们很明确购物车拥有哪些操作。当然还有另一种做法即把这些操作都放到用户实体中去,因为最终其实是用户做的这些操作。那我们的聚合就变成了用户-购物车-购物车项,这样也没有什么不可以,反而更符合真实的场景。但是会导致我们的聚合过庞大,也就是说我必须要先有用户实体才能进行操作,用户用户可能会绑上很多的东西:购物车、订单、地址等等。在现在都是ajax来操作的大型网站中,我们需要在服务端把这个用户请求加载出来再执行添加购物车的操作呢?还是可以直接加载购物车实体来操作呢?这就是一个粒度的问题,不同的问题和场景,大家可以区别来对待。总之聚合是可以根据业务或者一些特定需求来做出调整的。比如说购物车-购物车项-产品,这也是一个聚合,但是由于产品的特殊性,我们可以把产品也作为一个聚合根来单独进行访问。
我们来看一下应用层ShoppingCartService的代码:
1 public class ShoppingCartService : IShoppingCartService 2 { 3 private IRepository<ShoppingCart> _shoppingCartRepository; 4 private IRepository<Product> _productRepository; 5 6 public ShoppingCartService(IRepository<ShoppingCart> shoppingCartRepository, 7 IRepository<Product> productRepository) 8 { 9 _shoppingCartRepository = shoppingCartRepository; 10 _productRepository = productRepository; 11 } 12 13 public ShoppingCart AddToCart(Guid cartId, Guid productId, int quantity) 14 { 15 var cart = _shoppingCartRepository.GetById(cartId); 16 var product = _productRepository.GetById(productId); 17 cart.AddItem(product, quantity); 18 19 _shoppingCartRepository.Update(cart); 20 return cart; 21 } 22 23 }View Code
此应用层代码一出,大家就会发现,这代码太简洁了,有木有?因为所有的逻辑、业务都被放到领域实体那里面去处理了。即使我们业务逻辑改变了,或者我们需要重构了,它们都在领域实体那里面,改那里就好了。接下来的问题是,如何确保安全,正确的一次又一次的对领域实体进行重构呢?毕竟它也是各种关联,各种依懒呀?您请接着往下看我们的单元测试环节。
独立领域业务层 - 高内聚,低耦合,可测试讲到这里,请允许我从网上盗一张图,当然这张图早就已经是被引用过无数次了,它就是DDD中使用的分层结构。
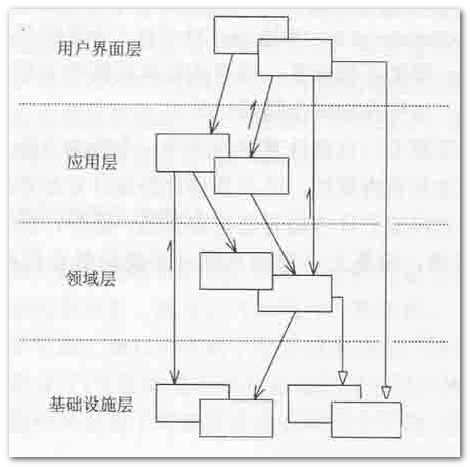
关于这个分层,每一层是干什么的,具体怎么玩,大家可以看一下dax的这一篇文章讲解的很清楚。总之,我们的领域模型以及相关的类比如工厂等会被独立成为一层来与应用层和基础设计层交互。
领域层是独立的,首先它是应用层的下层,所以肯定不会有对应用层的依懒,但是领域有一些模型或者服务少不了是要与数据库打交道的,比如说我们在注册用户的时候需要去验证当前的邮箱是不是已经被占用了。而这一类操作都是属于基础设施层做的事情,包含像一些数据库操作,日志,缓存等等。那么我们如何避免领域层对基础设施层的依懒呢?感谢面向对象设计 - 面向接口编程,只不过这里面的场景特别有代表性,它是一个非常常见的问题,于是它成为了一个模式:仓储(Repository)。
1 namespace RepositoryAndEf.Core.Data 2 { 3 public partial interface IRepository<T> where T : BaseEntity 4 { 5 T GetById(object id); 6 7 IEnumerable<T> Get( 8 Expression<Func<T, Boolean>> predicate); 9 10 bool Insert(T entity); 11 bool Update(T entity); 12 bool Delete(T entity); 13 } 14 }View Code
一般情况下,我们会把仓储的接口放到领域层,或者也可以再建一个Core层来作个项目最下面的那一层提供一些最公共的组件部分。关于仓储的代码,大家在上面领域服务UserService中的注册代码中就已经见到过了。可能需要注意的是,Repository用来将数据库与其它的业务和技术分离,所以我们在领域层中使用它,还在应用层中使用它。
Repository让我们专注于模型,不用去考虑持久化的问题。更为重要的一点是,因为它是接口,所以我们可以很方便的替代它,或者模拟一个实现来对我们的领域模型进行单元测试。下面是我们实现的MockRepository的代码:
1 public class MockRepository<T>: IRepository<T> where T : BaseEntity 2 { 3 private List<T> _list = new List<T>(); 4 5 public T GetById(Guid id) 6 { 7 return _list.FirstOrDefault(e => e.Id == id); 8 } 9 10 public IEnumerable<T> Get(Expression<Func<T, bool>> predicate) 11 { 12 return _list.Where(predicate.Compile()); 13 } 14 15 public bool Insert(T entity) 16 { 17 if (GetById(entity.Id) != null) 18 { 19 throw new InvalidCastException("The id has already existed"); 20 } 21 22 _list.Add(entity); 23 return true; 24 } 25 26 public bool Update(T entity) 27 { 28 var existingEntity = GetById(entity.Id); 29 if (existingEntity == null) 30 { 31 throw new InvalidCastException("Cannot find the entity."); 32 } 33 34 existingEntity = entity; 35 return true; 36 } 37 38 public bool Delete(T entity) 39 { 40 var existingEntity = GetById(entity.Id); 41 if (existingEntity == null) 42 { 43 throw new InvalidCastException("Cannot find the entity."); 44 } 45 46 _list.Remove(entity); 47 return true; 48 }View Code
下面我们给我们User领域实体的注册方法加一个检查Email是否存在的逻辑。
1 public virtual User Register(string email, string name, string password) 2 { 3 if (_userRepository.Get().Any(u => u.Email == email)) 4 { 5 throw new ArgumentException("email has already existed"); 6 } 7 8 var user = new User 9 { 10 Id = Guid.NewGuid(), 11 Email = email, 12 Name = name, 13 Password = password 14 }; 15 16 user.CreateShoppingCart(); 17 _userRepository.Insert(user); 18 return user; 19 }View Code
在我们真实的Repository出来之前,不管我们是打算是EF,还是NHibernate,我们现在只要对这个Mock的Repository来编程或者进行单元测试就可以了。
//UserService领域服务在单元测试
1 public class UserServiceTests 2 { 3 private IRepository<User> _userRepository = new MockRepository<User>(); 4 5 [Fact] 6 public void RegisterUser_ExpectedParameters_Success() 7 { 8 var userService = new UserService(_userRepository); 9 var registeredUser = userService.Register( 10 "hellojesseliu@outlook.com", 11 "Jesse", 12 "Jesse"); 13 14 var userFromRepository = _userRepository.GetById(registeredUser.Id); 15 16 userFromRepository.Should().NotBe(null); 17 userFromRepository.Email.Should().Be("hellojesseliu@outlook.com"); 18 userFromRepository.Name.Should().Be("Jesse"); 19 userFromRepository.Password.Should().Be("Jesse"); 20 } 21 22 [Fact] 23 public void RegisterUser_ExistedEmail_ThrowException() 24 { 25 var userService = new UserService(_userRepository); 26 var registeredUser = userService.Register( 27 "hellojesseliu@outlook.com", 28 "Jesse", 29 "Jesse"); 30 31 var userFromRepository = _userRepository.GetById(registeredUser.Id); 32 userFromRepository.Should().NotBe(null); 33 34 Action action = () => userService.Register( 35 "hellojesseliu@outlook.com", 36 "Jesse_01", 37 "Jesse"); 38 action.ShouldThrow<ArgumentException>(); 39 } 40 }View Code
我们用的XUnit.net作单元测试框架,同时用了Fluent Assertions。

结果很漂亮,有木有?有了单元测试来为我们的领域模型保驾护航,我们就可以安全的进行重构了。
干净漂亮的代码经常有人说代码是一件艺术,码农都是艺术家。我很喜欢这句话,如果你也认同,那就请像对待艺术品一样对待我们的代码,精心的打磨它。并且你不一定要非常的有经验才可以干这件事情;
如果你刚入行,那至少保证一代码可读性好(好的命名,代码逻辑清晰等);
再往上一点,你要能够更好的组织代码(类,函数);
等到你也成为专家了,那就开始考虑一些重用性,可扩展性,可维护性,可测试性的这些比较范的东西了;
而最后就上升到架构层面,考虑系统各个组件之间通讯,分层,等等。最后你就成为码神了。
DDD里面引入的一些思路包括分层、依懒注入、仓储等,可以给我们一些指导,大家从上面的代码也可以看出这些代码组织的很好,逻辑也不会散乱的到处都是。当然这个项目代码量有限,说服力是有限的,后面我们还会尝试去加入应用层的代码。代码已经放到CodePlex上去了:http://repositoryandef.codeplex.com
欢迎大家Follow。注意代码还没有写完,只是一个初级版本,我们后面会慢慢完善。这个项目会使用EF来作业ORM框架,Autofac作依懒注入容器,用Xunit作单元测试框架的同时引入了Fluent Assertions。
本文主要介绍了DDD的一些基础概念:
- 领域模型:领域实体、领域服务以及值对象;建模一定要从真实的领域业务出发,多与领域专家进行沟通来完善模型。
- 聚合与聚合根:它的主要作用是用来确保各种关系下的实体的数据一致性;但是确认聚合根这个过程,实际上也是对业务的梳理过程。
- 架构分层: 每一层都职责清楚;依懒于接口来降低耦合。
- 封装和测试: 所有的业务都放到领域层,同时对领域层进行单元测试来确保最核心的逻辑不会遭到破坏。
个人感觉没有必要太强调Repository的概念,从领域实体的生命周期(创建-持久化到数据库-销毁-从数据库重建)你会发现其实这个过程很普遍,并不是只有DDD才有的。所以我认为Repository主要是将数据访问功能给隔离开,避免领域实体对基础设施层的依懒。那它和三层有什么区别? BLL 引用DAL不也是依懒于接口么?给我的感觉是,DDD的领域实体持久化这一块就是三层里面的思路。这可能是在学习DDD初期的想法,因为真实的大型项目中是不会直接把领域实体给持久化的,那个叫DTO,于是Repository<>里面放的就不是我们的领域实体了,而是将领域实体转换成对应的DTO。
是否一定要使用DTO呢?领域实体和DTO互相转换,最后到了表现层DTO还要和ViewModel转换,会不会带来复杂性和性能上的损失?Repository和EF还有Unit Of Work怎么来协调?抱怨写单元测试么?怎么样让写单元测试不变成只是走过场而已? 这些问题留给我们后面再解决吧。