Sharding的基本思想就要把一个数据库切分成多个部分放到不同的数据库 (server)上,从而缓解单一数据库的性能问题。不太严格的讲,对于海量数据的数据库,如果是因为表多而数据多,这时候适合使用垂直切分,即把关系紧密(比如同一模块)的表切分出来放在一个server上。如果表并不多,但每张表的数据非常多,这时候适合水平切分,即把表的数据按某种规则(比如按ID 散列)切分到多个数据库(server)上。当然,现实中更多是这两种情况混杂在一起,这时候需要根据实际情况做出选择,也可能会综合使用垂直与水平切分,从而将原有数据库切分成类似矩阵一样可以无限扩充的数据库(server)阵列。
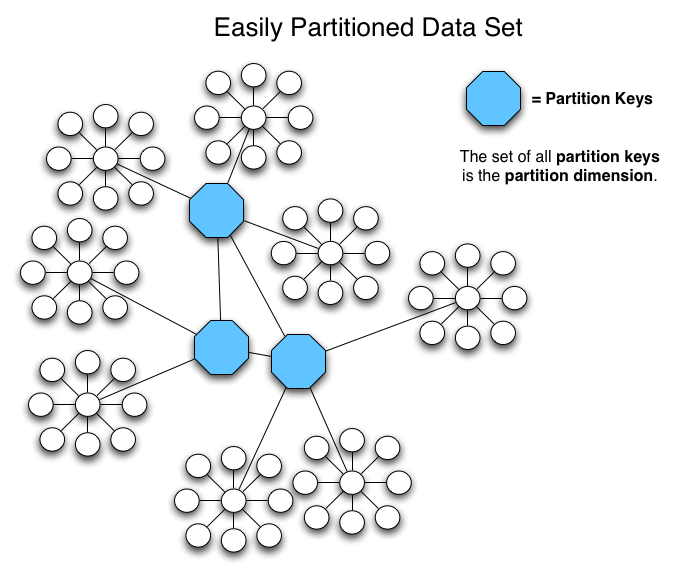
什么是切分数据库切分 是一个固有的关系流程,可以通过一些逻辑数据块将一个表的行分为不同的小组。例如,如果您正在根据时间戳对一个名为 foo 的超大型表进行分区,2010 年 8 月之前的所有数据都将进入分区 A,而之后的数据则全部进入分区 B。分区可以加快读写速度,因为它们的目标是单独分区中的较小型数据集。
分区功能并不总是可用的(MySQL 直到 5.1 版本后才支持),而且其需要的商业系统的成本也让人望而却步。更重要的是,大部分分区实现在同一个物理机上存储数据,所以受到硬件基础的影响。除此之外,分区也不能鉴别硬件的可靠性或者说缺乏可靠性。因此,很多智慧的人们开始寻找进行伸缩的新方法。
切分 实质上是数据库级别的分区:它不是通过数据块分割数据表的行,而是通过一些逻辑数据元素对数据库本身进行分割(通常跨不同的计算机)。也就是说,切分不是将数据表 分割成小块,而是将整个数据库 分割成小块。
切分的一个典型示例是基于根据区域对一个存储世界范围客户数据的大型数据库进行分割:切分 A 用于存储美国的客户信息,切分 B 用户存储亚洲的客户信息,切分 C 欧洲,等。这些切分分别处于不同的计算机上,且每个切分将存储所有相关数据,如客户喜好或订购历史。
切分的好处(如分区一样)在于它可以压缩大型数据:单独的数据表在每个切分中相对较小,这样就可以支持更快速的读写速度,从而提高性能。切分还可以改善可靠性,因为即便一个切分意外失效,其他切分仍然可以服务数据。而且因为切分是在应用程序层面进行的,您可以对不支持常规分区的数据库进行切分处理。资金成本较低同样也是一个潜在优势。
垂直拆分垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。

水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。

让我们从普遍的情况来考虑数据的切分:一方面,一个库的所有表通常不可能由某一张表全部串联起来,这句话暗含的意思是,水平切分几乎都是针对一小搓一小搓(实际上就是垂直切分出来的块)关系紧密的表进行的,而不可能是针对所有表进行的。另一方面,一些负载非常高的系统,即使仅仅只是单个表都无法通过单台数据库主机来承担其负载,这意味着单单是垂直切分也不能完全解决问明。因此多数系统会将垂直切分和水平切分联合使用,先对系统做垂直切分,再针对每一小搓表的情况选择性地做水平切分。从而将整个数据库切分成一个分布式矩阵。

hibernate的shards方案:
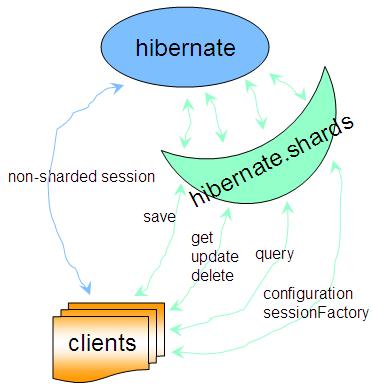
这里有几篇文章可以参考一下:
Hibernate Shards 数据的水平、垂直切割(一)- Hibernate测试环境 Hibernate Shards 数据的水平、垂直切割(二)- Hibernate Shards基本演示 Hibernate Shards 数据的水平、垂直切割(三)- Hibernate Shards结构注意:Hibernate Shards是不支持跨切分查询的。
使用hibernate shards进行拆分:
http://www.ibm.com/developerworks/cn/java/j-javadev2-11/index.html
也可以用hibernate shards构建基于SAAS的应用,因为我们知道在SAAS应用中,数据是需要隔离的,现在的隔离有很多种方案:
比如在IAAS建立虚拟化的完全隔离。
在PAAS基于策略的隔离等。
下面这篇是数据隔离的一个示例:
http://www.oschina.net/question/12_12465
apache sliceSlice扩展自OpenJPA用于分布式数据库的一个开源项目。Slice以插件的方式附加至OpenJPA runtime,通过配置一个持久单元就能够激活多个数据库支持。一旦配置好Slice,现有OpenJPA应用程序就能够在同一个事务中利用多个数据库进行处理。查询也将依赖所有数据库并行执行,任何更新也会提交至相应的数据库。
更确切的说slice更像是openjpa的一个插件,用来实现shards,下面看一下官方的图
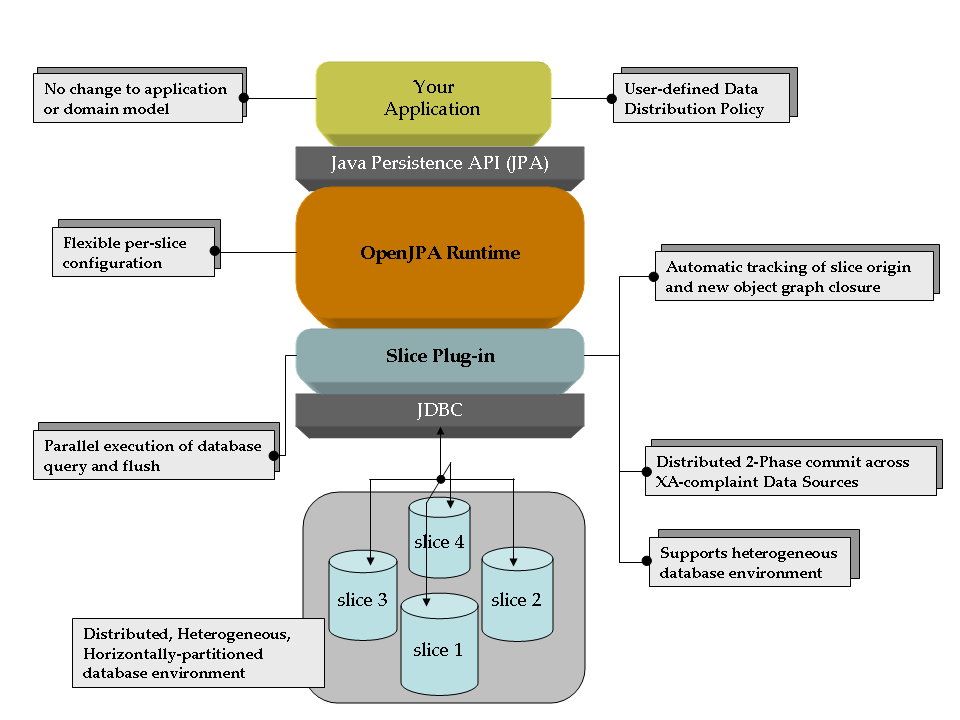
如果使用openjpa的方案可以考虑一下。
顺便附一下官方的网址:
http://people.apache.org/~ppoddar/slice/site/
dbShards首先,这个是一个商用的产品,绝对不是一个开源的方案。
- 单一数据库:
首先从配置一个网站应用开始,其由4太应用服务器及一个数据库组成。下图展示了一个应用的配置,数据库配置max_connections为1000。为避免数据库过载,我们将其并发请求数设置为800,因此设置每个应用服务器的连接池为允许最多200连接。设置每个应用服务器对于入站HTTP请求最少支持200线程的处理。 
- 拆分数据库:
现在假设我们采用拆分数据库,其中有4个物理子库(每个专用服务器上有1个单独的MySQL实例)。现在我们有4个数据库,每一个的 max_connections配置为1000。同样,我们要限制每个数据库800个并发事务。假设拆分架构的结果是在所有4个子库上平均分布查询,即每台应用服务器可以处理4倍的并发请求,并可以同每个子库建立200个连接。

详细的配置等可参考官方的文档:
http://www.dbshards.cn/articles/database-sharding-configuration/
最后再说一句,这个是商用的不是免费的。
CUBRIDCUBRID 是一个全面开源,且完全免费的关系数据库管理系统。CUBRID为高效执行Web应用进行了高度优化,特别是需要处理大数据量和高并发请求的复杂商务服务。通过提供独特的最优化特性,CUBRID可以支持更多的并发请求,更少的响应时间。
CUBRID这个名称,实际上是两个单词的组合:"Cube"(立方体)和"Bride"(桥梁)。对CUBRID而言,"Bride"代表"data bridge"(数据桥),而"Cube"代表密封盒子,可以为放在其中的数据提供安全。因此,CUBRID代表可以为机密信息提供安全保障。
从下表中可以对比一下cubrid的shards方案与其它的shards的不同之处:

大多数的解决方案都基于一个特定的数据库。他们通常的方式是使用一个中间的代理层。也就是说每一次的SQL请求都需要经过解析。
cubrid的架构:

操作流程如下:

这是非常不错的一个方案,可以考虑在团队中推广应用。
IBM WebSphere eXtreme ScaleIBM的分区方案,更确切的说应该是一套整体的方案:
1)WebSphere eXtreme Scale 初探,第 1 部分: 了解 WebSphere eXtreme Scale 及其工作原理
http://www.ibm.com/developerworks/cn/websphere/techjournal/0911_kirby/0911_kirby.html
2)Websphere eXtreme Scale 的先进先出(FIFO)特性研究
http://www.ibm.com/developerworks/cn/websphere/library/techarticles/1209_zhujf_fifo/1209_zhujf_fifo.html
3)深入剖析 WebSphere eXtreme Scale HTTP 会话管理
http://www.ibm.com/developerworks/cn/websphere/techjournal/1301_ying/1301_ying.html
IBM® WebSphere® eXtreme Scale 是一种通用、高速的缓存解决方案,可在各种不同的设计中予以配置和使用。不过,您不能盲目地使用 WebSphere eXtreme Scale 提供的 API,并想当然地认为它会减轻数据库的工作重负,使您的应用程序更快地运行。作为提高应用程序性能的一种策略,缓存应当被明智谨慎地应用。同样地,您不能想当然地认为您的应用程序可以弹性地应对硬件故障,除非您为此筹备了有意识的计划。

最后还是要说一句,东西是好东西,可惜即不开源,也不免费。
MongoDB shardingMongoDB 是一种流行的非关系型数据库。作为一种文档型数据库,除了有无 schema 的灵活的数据结构,支持复杂、丰富的查询功能外,MongoDB 还自带了相当强大的 sharding 功能。
下面是架构图:

关于更详细的介绍,可以参考:
http://xiezhenye.com/2012/12/mongodb-sharding-%E6%9C%BA%E5%88%B6%E5%88%86%E6%9E%90.html
也可以参考官方的文档:
http://docs.mongodb.org/manual/sharding/
这对于正在使用非关系型数据库并且正用到分表功能的团队可以说是一个福音。
MySQL ClusterMySQL Cluster 是一种技术,该技术允许在无共享的系统中部署“内存中”数据库的 Cluster 。通过无共享体系结构,系统能够使用廉价的硬件,而且对软硬件无特殊要求。此外,由于每个组件有自己的内存和磁盘,不存在单点故障。
MySQL Cluster 由一组计算机构成,每台计算机上均运行着多种进程,包括MySQL服务器,NDB Cluster 的数据节点,管理服务器,以及(可能)专门的数据访问程序。关于 Cluster 中这些组件的关系。

如果想做mysql集群可以考虑使用。
Plugin for Grails这个没什么可说的,基于grails的shards插件。
网站是:
http://grails.org/plugin/sharding
Redisredis-sharding 是一个由perl写的 Redis 的proxy,使用它,你可以将数据分布存储在多个Redis实例上,而在操作数据时却像只操作一个实例一样。利用它相当于透明地解决了 Redis 单线程无法有效利用多核心服务器的问题。当然,我们更期待官方的cluster方案。
项目地址:https://github.com/kni/redis-sharding
架构:
/- Redis (node 1) Client 1 --- /-- Redis (node 2) Redis Sharding --- Redis (node 3) Client 2 --- \-- Redis (node 4) \- Redis (node 5)
启动redis-sharding,分别为使用默认host,port与指定host,port的方式:
perl redis_sharding.pl --nodes=10.1.1.2:6380,10.1.1.3:6380,... perl redis_sharding.pl --port=6379 --nodes=10.1.1.2:6380,10.1.1.3:6380,... perl redis_sharding.pl --host=10.1.1.1 --port=6379 --nodes=10.1.1.2:6380,10.1.1.3:6380,...
redis-sharding还支持重新切分数据,但这需要暂时停掉proxy,下面是将原来的db 9的数据重新sharding到B1-B5五个实例上:
停掉redis-sharding后再执行:
perl resharding.pl --db=9 --from=A1 --nodes=B1,B2,B3,B4,B5
perl resharding.pl --db=9 --from=A2 --nodes=B1,B2,B3,B4,B5
然后再启动新的管理B1-B5的redis-sharding实例即可:
perl redis_sharding.pl --nodes=B1,B2,B3,B4,B5
如果需求简单可以考虑使用。
Ruby ActiveRecord功能和hibernate shards类似,都是基于orm的shard,如果使用ruby的朋友可以使用。
ScaleBase's Data Traffic ManagerScaleBase 的关键卖点是它的旗舰产品 Data Traffic Manager。其最大的特点是可以跟客户已有的应用协同工作,不需要客户重写应用。Data Traffic Manager 的作用相当于在数据库与客户端(可以是 app server、BI 工具或任何数据库客户端)之间充当代理,其部署方式可以是在本地或云端。

商用产品,不多说,前景十分看好。
Solr Search Server顾名思意:
solr提供的服务器分发。在处理搜索的可以深入一下。
SQLAlchemy ORMSQLAlchemy是Python编程语言下的一款开源软件。提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行。
SQLAlchemy“采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型”。SQLAlchemy的理念是,SQL数据库的量级和性能重要于对象集合;而对象集合的抽象又重要于表和行。因此,SQLAlchmey采用了类似于Java里Hibernate的数据映射模型,而不是其他ORM框架采用的Active Record模型。不过,Elixir和declarative等可选插件可以让用户使用声明语法。
如果你正在用python,而且想做分表的功能,可以重点关注下。
SQL Azuremicrosoft的分片方案:
对于大数据分析高度可扩展的NoSQL数据库是很热门的话题,但是组织可以对传统的关系型数据库通过水平行分区进行横向扩展和纵向扩展,使它们运行于多个服务器实例上,这也就是所谓的分片技术(Sharding)。 SQL Azure是定制版SQL Server 2008 R2集群基于云的实现,运行于微软公司全球数据中心网络上。SQL Azure提供了高达99.9%服务级别协议的高可用性,由三重数据复制实现,省下了为处理运营高峰负载压力需要在服务器硬件上的资本投资。
SQL Azure服务是在12月12日发布的,该版本把SQL Azure数据库的最大容量从50GB增加到了150GB,引入了称之为SQL Azure Federation的分片技术,隐性地降低了每月运营成本达到45%到95%之多,具体比例依赖于数据库大小。Federations使重新分配和划分数据更容易了,而且提供了无需应用停机处理这些操作的路由层。
DBA和开发人员如何利用SQL Azure发挥他们的T-SQL管理技能,并能够消除按需分配数据库服务器的常规配置和维护成本呢?需要做联邦的数据来源于接近800万行的 Windows Azure表特征数据,这些数据来自于六个默认的计数器:网络接口每秒发送的字节数和接收的字节数,每秒钟ASP.NET应用请求数,建立的TCPv4连接数,内存可用字节和处理时间百分比。SQL Server 2008 R2 SP1源表(WADPerfCounters)有一个组合的集群主键,由PartitionKey和RowKey值组成。SQL Azure目标表做联邦后增加了CounterID值,从1到6,代表了六个时间计数器。这些表给他们的主键增加了CounterID,因为必须包含联邦分发主键值。
如果你正在跟微软合作或者考虑使用微软的方案,可以选用。
IBM InformixIBM的数据库:
IBM Informix 关系数据库管理系统为所有规模的企业提供了联机事务处理和决策支持应用,适用于Microsoft Windows、Linux、UNIX 和 Apple Mac OS X 平台。
如果使用这个数据库可以使用它的shard功能。
GizzardTwitter已经从以往的数据存储开发经验中提出一个名为Gizzard的Scala框架,让用户可以更方便地创建自定义容错、分布式数据库。 Twitter给出了一个名为“Rowz”的示例,方便用户上手。Twitter还公布了Gizzard的完整代码。有了Gizzard,初创公司和小公司就可以更好更快地处理大量数据,从而利用更少的资源满足用户需求。
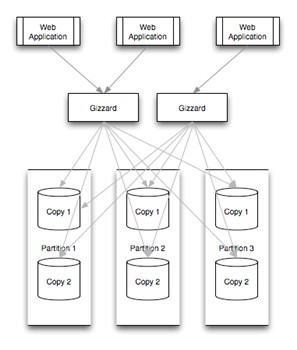
它更像是一个数据shards的方案之一,可以不使用关系型数据库。
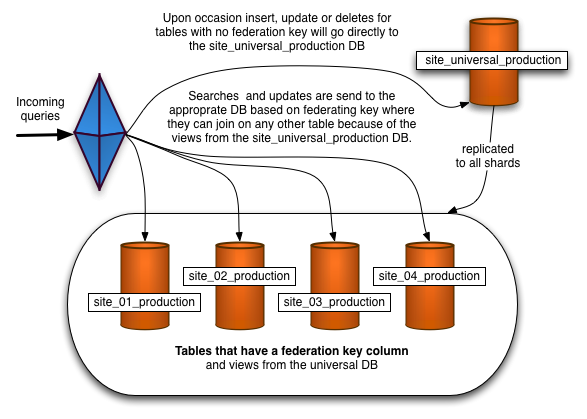
Spock Proxy这也是在实际需求中产生的一个开源项目。Spock(http://www.spock.com/)是一个人员查找的 Web 2.0 网站。通过对自己的单一 DB 进行有效 Sharding化 而产生了Spock Proxy(http://spockproxy.sourceforge.net/ ) 项目,Spock Proxy 算得上 MySQL Proxy 的一个分支,提供基于范围的 Sharding 机制。Spock 是基于 Rails 的,所以Spock Proxy 也是基于 Rails 构建,关注 RoR 的朋友不应错过这个项目。
架构示意图:
上面介绍了 RoR 的实现,HiveDB (http://www.hivedb.org/)则是基于Java 的实现,另外,稍有不同的是,这个项目背后有商业公司支持。
架构示意图:
前面几个都是针对 MySQL 的 Sharding 方案,PL/Proxy 则是针对 PostgreSQL 的,设计思想类似 Teradata 的 Hash 机制,数据存储对客户端是透明的,客户请求发送到 PL/Proxy 后,由这里分布式存储过程调用,统一分发。 PL/Proxy 的设计初衷就是在这一层充当”数据总线”的职责,所以,当数据吞吐量支撑不住的时候,只需要增加更多的 PL/Proxy 服务器即可。大名鼎鼎的 Skype 用的就是 PL/Proxy 的解决方案。
Pyshardshttp://code.google.com/p/pyshards/wiki/Pyshards
这是个基于 Python的解决方案。该工具的设计目标还有个 Re-balancing 在里面,这倒是个比较激进的想法。目前只支持 MySQL 数据库。
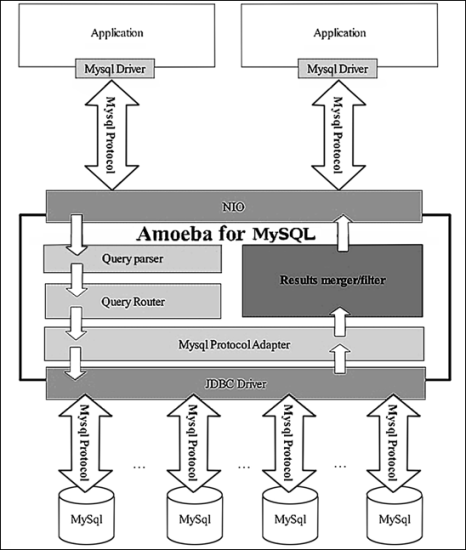
Amoeba是一个以MySQL为底层数据存储,并对应用提供MySQL协议接口的proxy。它集中地响应应用的请求,依据用户事先设置的规则,将SQL请求发送到特定的数据库上执行。基于此可以实现负载均衡、读写分离、高可用性等需求。与MySQL官方的MySQL Proxy相比,作者强调的是amoeba配置的方便(基于XML的配置文件,用SQLJEP语法书写规则,比基于lua脚本的MySQL Proxy简单)。
Amoeba相当于一个SQL请求的路由器,目的是为负载均衡、读写分离、高可用性提供机制,而不是完全实现它们。用户需要结合使用MySQL的 Replication等机制来实现副本同步等功能。amoeba对底层数据库连接管理和路由实现也采用了可插拨的机制,第三方可以开发更高级的策略类来替代作者的实现。这个程序总体上比较符合KISS原则的思想。
主要解决以下问题:
a). 数据切分后复杂数据源整合
b). 提供数据切分规则并降低数据切分规则给数据库带来的影响
c). 降低数据库与客户端连接
d). 读写分离路由
Amoeba For MySQL是专门针对MySQL数据库的方案,架构示意图:
Amoeba For Aiadin是个更通用的方案,他前端接收MySQL协议的请求,后端可以使用MySQL、Oracle、PostGreSql等其他数据源,这些对应用程序是透明的。架构示意图:

Atlas是由奇虎360公司Web平台部基础架构组开发维护的一个基于MySQL协议的数据中间层项目。它在MySQL官方推出的MySQL- Proxy 0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。目前该项目在360公司内部得到了广泛应用,3/4以上的MySQL业务已经接入了 Atlas平台,每天承载的读写请求数达20亿条以上。
主要功能特性:
1. 自动读写分离,对应用透明
2. 自动分表
3. IP过滤,包括指定具体IP和网段IP
4. SQL语句黑白名单
5. 字符集和默认数据库的自动修正
6. 可强制读主库,避免从库的同步延迟
7. 主库宕机的情况下读操作不受影响
8. 在挂接LVS的情况下可平滑重启,应用不感知
9. 自动检测DB状态,故障或连接不上的DB自动摘除,不再导入请求,在故障或网络恢复后自动重新导入请求
10. 可在线手动将某台DB设置为上线或下线状态
11. 可在线手动增加或减少一台DB
12. 从库间加权的负载均衡
官方网址:
https://github.com/Qihoo360/Atlas
刚开源出来不久,文档较少,不过可以尝试使用,毕竟中国自己的开源框架吗。
cobarCobar是关系型数据的分布式处理系统,它可以在分布式的环境下看上去像传统数据库一样为您提供海量数据服务。
- 产品在阿里巴巴B2B公司已经稳定运行了3年以上。
- 目前已经接管了3000+个MySQL数据库的schema,为应用提供数据服务。
- 据最近统计cobar集群目前平均每天处理近50亿次的SQL执行请求。
不解释,阿里团队开源出来的产品。
详细可到官方网址:
http://code.alibabatech.com/wiki/display/cobar/Home
最后具体使用哪款产品还要根据实际的情况,及数据量等实际的需求。“只有合适才是最好的!”