今天我来谈一谈容易被人混淆的二个集合:Request[]与Request.Params[]
这二个集合我在博客【我心目中的Asp.net核心对象】中就提到过它们, 而且还给出了一个示例,并以截图的形式揭示过它们的差别。但由于那篇博客中有更多有价值的对象要介绍, 因此也就没有花太多的篇幅着重介绍这二个集合。但我发现,不知道这二个集合差别的人确实太多,以至于我认为很有必要为它们写个专题来细说它们的差别了。
在ASP.NET编程中,有三个比较常见的来自于客户端的数据来源:QueryString, Form, Cookie 。 我们可以在HttpRequest中访问这三大对象, 比如,可以从QueryString中获取包含在URL中的一些参数, 可以从Form中获取用户输入的表单数据, 可以从Cookie中获取一些会话状态以及其它的用户个性化参数信息。 除了这三大对象,HttpRequest还提供ServerVariables来让我们获取一些来自于Web服务器变量。 通常,这4个数据来源都很明确,我想没人会混淆它们。
一般情况下,如果我们在事先就能明确知道某个参数是来源于哪个集合,那么直接访问那个集合,问题也就简单了。 然而,更常见的数据来源通常只会是QueryString, Form ,而且尤其是当在客户端使用Jquery的$.ajax()这类技术时, 可以很随意地将参数放到QueryString或者是Form中,那么,服务端通常为了也能灵活地应对这一现况, 可以使用Request[]与Request.Params[] 这二种方式来访问这些来自于用户提交的数据。 本文的故事也因此而产生了:Request[]与Request.Params[] 有什么差别??
回顾博客原文由于【我心目中的Asp.net核心对象】有对它们的一些介绍以及示例截图, 无奈,有些人可能由于各种原因,没看到那段文字,这里我也只好再贴一次了:
这二个属性都可以让我们方便地根据一个KEY去【同时搜索】QueryString、Form、Cookies 或 ServerVariables这4个集合。
通常如果请求是用GET方法发出的,那我们一般是访问QueryString去获取用户的数据,如果请求是用POST方法提交的,
我们一般使用Form去访问用户提交的表单数据。而使用Params,Item可以让我们在写代码时不必区分是GET还是POST。
这二个属性唯一不同的是:Item是依次访问这4个集合,找到就返回结果,而Params是在访问时,先将4个集合的数据合并到一个新集合(集合不存在时创建),
然后再查找指定的结果。
为了更清楚地演示这们的差别,请看以下示例代码:
<body> <p>Item结果:<%= this.ItemValue %></p> <p>Params结果:<%= this.ParamsValue %></p> <hr /> <form action="<%= Request.RawUrl %>" method="post"> <input type="text" name="name" value="123" /> <input type="submit" value="提交" /> </form> </body>
public partial class ShowItem : System.Web.UI.Page { protected string ItemValue; protected string ParamsValue; protected void Page_Load(object sender, EventArgs e) { string[] allkeys = Request.QueryString.AllKeys; if( allkeys.Length == 0 ) Response.Redirect("ShowItem.aspx?name=abc", true); ItemValue = Request["name"]; ParamsValue = Request.Params["name"]; } }
页面在未提交前浏览器的显示:
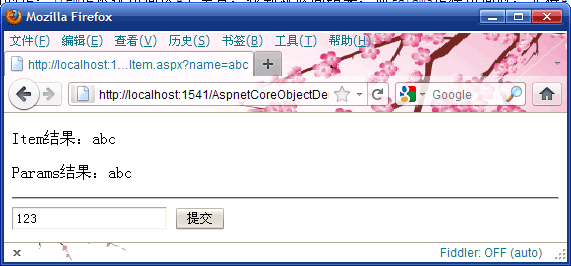
点击提交按钮后,浏览器的显示:
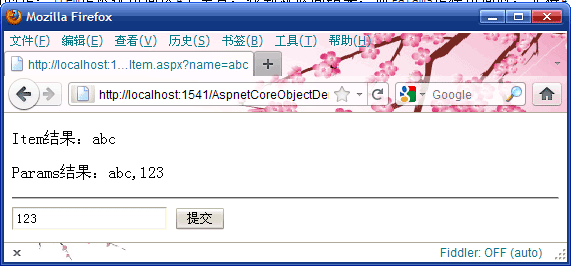
差别很明显,我也不多说了。说下我的建议吧:尽量不要使用Params,不光是上面的结果导致的判断问题, 没必要多创建一个集合出来吧,而且更糟糕的是写Cookie后,也会更新集合。
正如我前面所说的客观原因:由于那篇博客中有更多有价值的对象要介绍,因此也就没有花太多的篇幅着重介绍这二个集合。 下面,我来仔细地说说它们的差别。
实现方式分析前面的示例中,我演示了在访问Request[]与Request.Params[] 时得到了不同的结果。为什么会有不同的结果呢,我想我们还是先去看一下微软在.net framework中的实现吧。
首先,我们来看一下Request[]的实现,它是一个默认的索引器,实现代码如下:
public string this[string key] { get { string str = this.QueryString[key]; if( str != null ) { return str; } str = this.Form[key]; if( str != null ) { return str; } HttpCookie cookie = this.Cookies[key]; if( cookie != null ) { return cookie.Value; } str = this.ServerVariables[key]; if( str != null ) { return str; } return null; } }
这段代码的意思是:根据指定的key,依次访问QueryString,Form,Cookies,ServerVariables这4个集合,如果在任意一个集合中找到了,就立即返回。
Request.Params[]的实现如下:
public NameValueCollection Params { get { //if (HttpRuntime.HasAspNetHostingPermission(AspNetHostingPermissionLevel.Low)) //{ // return this.GetParams(); //} //return this.GetParamsWithDemand(); // 为了便于理解,我注释了上面的代码,其实关键还是下面的调用。 return this.GetParams(); } } private NameValueCollection GetParams() { if( this._params == null ) { this._params = new HttpValueCollection(0x40); this.FillInParamsCollection(); this._params.MakeReadOnly(); } return this._params; } private void FillInParamsCollection() { this._params.Add(this.QueryString); this._params.Add(this.Form); this._params.Add(this.Cookies); this._params.Add(this.ServerVariables); }
它的实现方式是:先判断_params这个Field成员是否为null,如果是,则创建一个集合,并把QueryString,Form,Cookies,ServerVariables这4个集合的数据全部填充进来, 以后的查询都直接在这个集合中进行。
我们可以看到,这是二个截然不同的实现方式。也就是因为这个原因,在某些特殊情况下访问它们得到的结果将会不一样。
不一样的原因是:Request.Params[]创建了一个新集合,并合并了这4个数据源,遇到同名的key,自然结果就会不同了。
在博客【我心目中的Asp.net核心对象】中, 说到Request.Params[]时,我简单地说了一句:而且更糟糕的是写Cookie后,也会更新集合。 如何理解这句话呢?
我想我们还是来看一下我们是如何写一个Cookie,并发送到客户端的吧。下面我就COPY一段 【细说Coookie】中的一段原文吧:
Cookie写入浏览器的过程:我们可以使用如下代码在Asp.net项目中写一个Cookie 并发送到客户端的浏览器(为了简单我没有设置其它属性)。
HttpCookie cookie = new HttpCookie("MyCookieName", "string value"); Response.Cookies.Add(cookie);
代码的关键点在于调用了Response.Cookies.Add(),我们来看看它们是如何实现的。首先来看Response.Cookies
public HttpCookieCollection Cookies { get { if (this._cookies == null) { this._cookies = new HttpCookieCollection(this, false); } return this._cookies; } }
再来看HttpCookieCollection这个集合的实现:
public sealed class HttpCookieCollection : NameObjectCollectionBase { public HttpCookieCollection() : base(StringComparer.OrdinalIgnoreCase) { } internal HttpCookieCollection(HttpResponse response, bool readOnly) : base(StringComparer.OrdinalIgnoreCase) { this._response = response; base.IsReadOnly = readOnly; } public void Add(HttpCookie cookie) { if (this._response != null) { this._response.BeforeCookieCollectionChange(); } this.AddCookie(cookie, true); if (this._response != null) { this._response.OnCookieAdd(cookie); } }
注意:由于在HttpResponse中创建HttpCookieCollection时,把HttpResponse对象传入了,因此,在调用HttpCookieCollection.Add()方法时, 会调用HttpResponse的OnCookieAdd(cookie); 我们接着看:
internal void OnCookieAdd(HttpCookie cookie) { this.Request.AddResponseCookie(cookie); }
又转到Request对象的调用了,接着看:
internal void AddResponseCookie(HttpCookie cookie) { if (this._cookies != null) { this._cookies.AddCookie(cookie, true); } if (this._params != null) { this._params.MakeReadWrite(); this._params.Add(cookie.Name, cookie.Value); this._params.MakeReadOnly(); } }
从以上的代码分析中,我们可以看到,我们调用Response.Cookies.Add()时,Cookie也会加到HttpRequest.Cookies中。
而且,如果我们访问过程Request.Params[],也会加到那个集合中。
本文一开始的示例中,为什么代码 ParamsValue = Request.Params["name"]; 得到的结果是:【abc,123】?
根据前面示例代码我们可以得知:abc这个值是由QueryString提供的,123这值是由Form提供的,最后由Request.Params[]合并在一起了就变成这个样子了。 有没有人想过:为什么合起来就变成了这个样子了呢?
要回答这个问题,我们需要回顾一下Params的定义:
public NameValueCollection Params
注意:它的类型是NameValueCollection 。MSDN对这个集合有个简单的说明:
此集合基于 NameObjectCollectionBase 类。但与 NameObjectCollectionBase 不同,该类在一个键下存储多个字符串值。
为了便于大家更容易理解这个类的工作方式,我画了一张草图:
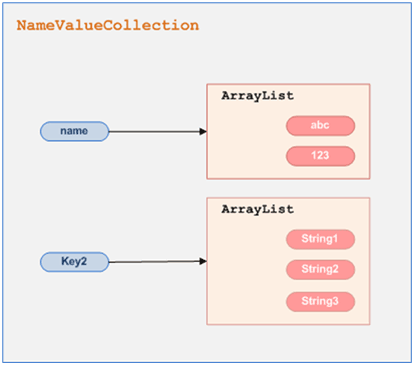
【name】这个key对应差一个ArrayList,而那个ArrayList中,包含了二个字符串:abc 和 123 ,这就是它的工作方式。
既然它能在一个键值下存储多个字符串,那我们就来看一下它到底是如何实现的,直接转到Add()方法:(注意我在代码中添加的注释)
public virtual void Add(string name, string value) { if( base.IsReadOnly ) { throw new NotSupportedException(SR.GetString("CollectionReadOnly")); } this.InvalidateCachedArrays(); // 这是一个关键的调用,它调用基类,得到每个name对应的元素, // 而每个name对应的元素是一个ArrayList ArrayList list = (ArrayList)base.BaseGet(name); if( list == null ) { // 如果不存在name对应的元素,则创建ArrayList list = new ArrayList(1); if( value != null ) { // 添加value到ArrayList,它将是第一个值 list.Add(value); } base.BaseAdd(name, list); } else if( value != null ) { // 在原有的ArrayList中继续添加新的值 list.Add(value); } }
我们再来看一下当我们访问Params[]这个索引器时,.net framework又是如何实现的:
public string this[string name] { get { return this.Get(name); } set { this.Set(name, value); } } public virtual string Get(string name) { // 根据name得到ArrayList ArrayList list = (ArrayList) base.BaseGet(name); // 将ArrayList变成一个字符串行 return GetAsOneString(list); } private static string GetAsOneString(ArrayList list) { int num = (list != null) ? list.Count : 0; if( num == 1 ) { return (string)list[0]; } if( num <= 1 ) { return null; } StringBuilder builder = new StringBuilder((string)list[0]); for( int i = 1; i < num; i++ ) { builder.Append(','); // 逗号就来源于此。 builder.Append((string)list[i]); } return builder.ToString(); }
现在,您该明白了为什么当一个key有多个值时,为什么会用逗号分开来了吧。
或许,看到这里,您又有了一个新的想法:对于有多值的情况,还要我来按逗号拆分它们,太麻烦了,有没有不要拆分的方法呢?
答案是:有的,您可以访问NameValueCollection的GetValues方法,这个方法的实现如下:
public virtual string[] GetValues(string name) { ArrayList list = (ArrayList)base.BaseGet(name); return GetAsStringArray(list); } private static string[] GetAsStringArray(ArrayList list) { int count = (list != null) ? list.Count : 0; if( count == 0 ) { return null; } string[] array = new string[count]; list.CopyTo(0, array, 0, count); return array; }
我想结果一定是您所期待的,它是一个string[] ,我们可以方便的遍历它:
string[] array = Request.Params.GetValues("name"); if( array != null ) foreach(string val in array)再谈QueryString, Form
前面我解释了NameValueCollection的工作原理,并揭示了Request.Params["name"]; 得到【abc,123】这个结果的原因。
事实上,这个怪异的结果有时并不只是Params会有,同样的故事还可能由QueryString, Form这二个对象上演(最终会在Request[]那里也有体现)。
我还是拿【我心目中的Asp.net核心对象】的示例来说明吧:
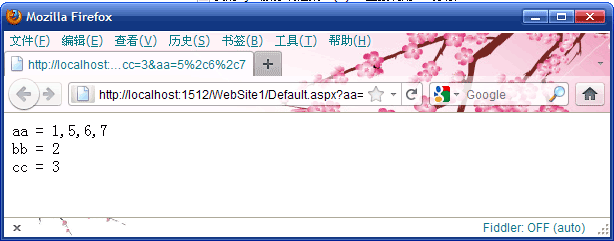
protected void Page_Load(object sender, EventArgs e) { string[] allkeys = Request.QueryString.AllKeys; if( allkeys.Length == 0 ) Response.Redirect( Request.RawUrl + "?aa=1&bb=2&cc=3&aa=" + HttpUtility.UrlEncode("5,6,7"), true); StringBuilder sb = new StringBuilder(); foreach( string key in allkeys ) sb.AppendFormat("{0} = {1}<br />", HttpUtility.HtmlEncode(key), HttpUtility.HtmlEncode(Request.QueryString[key])); this.labResult.Text = sb.ToString(); }
页面最终显示结果如下(注意键值为aa的结果):
示例代码中,开始部分用于检查URL是否包含参数,如果没有,则加入一些参数。写成这样的原因是: 第一次访问这个页面时,URL中肯定是不包含参数的,为了能演示,所以我就加了一些固定的参数,这样便于后面的讲解。
这个示例也演示了:遇到同名的多个值,用逗号分开的做法,并不是Params才会有的,QueryString也可能会有, 当然,Form也逃不掉这个特性的缠绕,不过,我现在倒想举个有使用价值的示例。
我有这样一个录入界面(左边),并希望最终的录入结果以右图的方式显示:
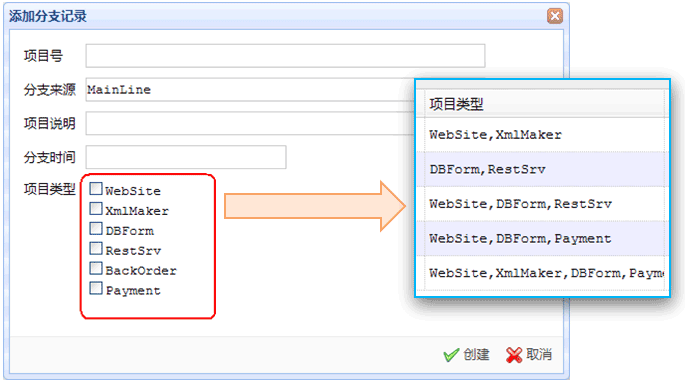
我想这个功能的实现并不难,但如何做才是最简单呢?
下面我贴出我的实现方法,大家看看算不算比较容易:
<tr><td style="vertical-align: top">项目类型</td><td>
<% foreach( string pt in AppHelper.ProjectTypes ) { %>
<label><input type="checkbox" name="ProjectType" value="<%= pt %>" /><%= pt%></label><br />
<% } %>
</td></tr>
注意:所有的checkbox的name都是一样的。
服务端嘛,我认为没有必要再贴代码了,我想您懂的。
在这个示例中,我正好利用了NameValueCollection的这个特点,让它帮我实现了这个逗号分隔的效果,要不然,我还得自己去做!
如何处理冲突通过前面的一些示例,我们可以看到并非只有Params[]会有冲突,只要类型是NameValueCollection的数据源,都有这个问题。
我要再重申一次:QueryString, Form,Param都有这样的冲突问题,只是Param需要合并4种数据源,它将冲突的机率变大了。
那么,我们如何正确的处理这类冲突呢? 还记得我前面提到的NameValueCollection的GetValues方法吧,也只好用它了。(除非你愿意自己手工拆分字符串) 然后再用一个循环就可以访问所有冲突值了,就像下面这样:
string[] array = Request.Params.GetValues("name"); if( array != null ) foreach(string val in array)
注意:Request[]的返回结果是一个字符串,就不能使用这种方法。但是,它的冲突机率要少很多。
现在,还有个现实的问题:QueryString, Form是最常用的数据源,我们要不要这样处理它呢?
这的确是个很现实的问题,我认为在回答这个问题前,我们需要分析一下这二个集合出现KEY冲突时是个什么样子的。
1. "abc.aspx?id=1 &id=2" 在这URL中,我想问问各位:看到这个URL,您会怎么想?我认为它是错的,错在拼接URL的操作中。 其次,我认为URL的修改或者拼接通常由一个工具类来控制,我们有理由保证它不会出现冲突,毕竟范围相应较小,我们容易给出这个保证。 因此,我认为,直接访问QueryString可以忽略这种冲突的可能。
2. 表单数据中name重复的情况。我认为这个集合倒是有可能出现冲突,但也极有可能是我们故意安排的,就像前面的示例一样。 其次,表单的内容在开发阶段相对固定,各个输入控件的name也是比较清楚的,不存在动态变换的可能,因此, 我认为,直接访问Form也可以忽略这种冲突的可能。
另一方面,我们平时写QueryString[], Form[]都太习惯了,这样的代码太多了,也不可能改成循环的判断, 因此,我们只能尽量保证在一个数据源的范围内,它们是不重复的。 事实上,前二个集合通常仅仅与某一个页面相关,范围也相对较小,更容易保证。 因此,如果有了这个保证,在访问这二类集合时,忽略冲突也是可接受的。
但是,Params需要合并4种数据源,尤其是包含Cookies,ServerVariables这二类对象并非与某个页面相关,它们是全局的, 因此冲突的可能性会更大,所以,我认为:如果您要访问Params[],那么,请改成Params.GetValues() ,因为这样才更合适。
Request[]还是Request.Params[] ??前面说了这么多,我想Request[]和Request.Params[]的差别,这次应该是说清楚了,到此也该给个结论了: 到底选择Request[]还是Request.Params[] ??
我想很多人应该会比较关注这个答案,这里我也想说说我的观点,不过,我要说明一点: 本文的所有文字,都只表示我的个人观点,仅供参考。
我认为:要想清楚地回答这个问题,有必要从二个角度再来观察这二者:常见用法和设计原因。
1. 常见用法: 我一直认为设计这二个集合是为了方便,让我们可以不必区分GET, POST而直接得到所需的用户数据。 如果没有这二个集合,而我们又需要不区分GET,POST时,显然就要自己去实现这类的集合, 而在自己实现时,也极有可能是先尝试访问QueryString, 如果没有,再去找Form ...。看到了吗,这不正是Request[]的实现方式吗? 也正是基于这个前提,遇到前面那种【abc,123】场景时,Request[]得到的结果或许更符合我们的预期。毕竟在获取到结果后, 我们会基于结果做一些判断,比如:name参数可能对应一个数据库的表字段,用它可以找到一个实际数据行, 如果结果是abc或者是123,这时程序都能处理(都有匹配的记录),但来个【abc,123】,这个还真没法处理了。
另一方面,在前面的例子中,我也解释了这并不是Params[]特有的,QueryString, Form都有这样的问题,自然地Request[]也有这个问题, 只是由于Params需要合并4类数据源,让这种冲突的机会更大了。
说到这里,有必要再来谈谈前面的几个例子,【abc,123】中,name在QueryString, Form中重复了,显然这属于不合理的设计, 现实情况中,应该是不会产生这类事情的,除非偶然。不过,当偶然的不幸发生时,也正好能体现这二者的差别了。 至于我前面所举的几个例子,虽然在现实中不太可能会出现,但我的意图是在向您展示这些技术的细节差异, 展示一些可能偶然会发生的情况,因此,请不要认为那是个技术误导。
2. 设计原因:让我们再从设计严谨性这个角度来看待这二者的差别,还是拿【abc,123】这个例子来说吧, Request[]这种依次判断的方式,显然会遗漏一些信息,因此,从严谨性这个角度来看,Request[]是不完美的。 毕竟,最终用户会如何以某种想法使用这二个API,没人知道。微软是设计平台的,他们不得不考虑这个问题,不设计这二个集合, 是.net framework的不完善,用错了,就是我们自己的错了。
基于以上观点,我给出我的4点意见:
1. 不建议使用Params[],因为:a. 不希望被偶然情况影响,b. 较高的使用成本。
2. Request[] 使用简单,适合要求不高的场合:示例代码。
3. 如果需要兼顾性能和易用性,可以模仿Request[]自行设计。(通常并不需要访问4个集合)
4. 了解差异,体会细节,有时会发现它还是有利用价值的。
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】按钮。
如果,您希望更容易地发现我的新博客,不妨点击一下右下角的【关注 Fish Li】。
因为,我的写作热情也离不开您的肯定支持。
感谢您的阅读,如果您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是Fish Li 。