个人ASP.NET程序性能优化心得系列:
个人ASP.NET程序性能优化心得(1):数据库篇
个人ASP.NET程序性能优化心得(1):数据库篇(外一篇)
个人ASP.NET程序性能优化心得(2):ASP.NET代码优化
个人ASP.NET程序性能优化心得(3):前端性能优化
------------------------------------------------------------------------------
在上一篇文章《个人ASP.NET程序性能优化心得(1):数据库篇》里,不少园友对我其中的一些观点提出了一些质疑,这里我认真查阅了一些资料,更正了一些存在错误的地方,另外对一些存在争议的地方加上更详细的说明,并会对一些将于性能方面的问题以实例数据表现出来。
表结构:
News(NewsId,NewsTitle,Content,CateId,CateTitle,PostUserId,PostUserName,AddTime,DateNum,Hits,CommentNum)//Hits:点击数;CommentNum:评论次数 Cate(CateId,CateTitle)只有主键,未建外键,暂时未建其他索引;其中News表插入了100万条测试数据,Cate共有三条数据。
1、对于外键及相关键是否比严格的范式型效率高:
这两张表是显著的胖瘦表查询,这种情况也比较常见,假设使用严格的范式型表结构,也就是News表不存在CateTitle,这里进行连接查询:
select n.*,c.* from news n inner join Cate c on c.CateId=n.CateId and c.CateId=1
执行计划如下:
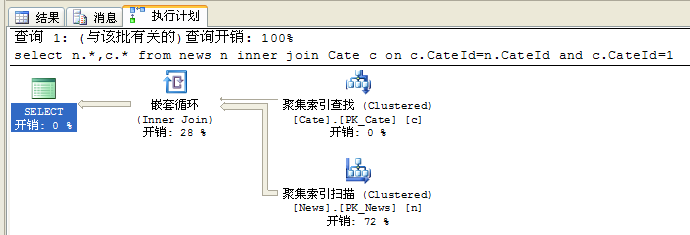
个人ASP.NET程序性能优化心得(1):数据库篇(外一篇)
另一种情况查询语句如下:
select * from News where CateId=1
执行计划如下:
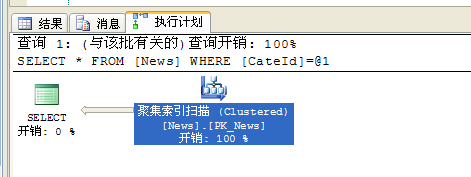
从执行计划里可以看到第一种情况在两次聚焦索引查找后再进行一次嵌套循环将结果合并,而第二种情况只有一次聚焦索引扫描,因此会在一定程序上减少性能的消耗,下图是SQL Server Profiler的对比:
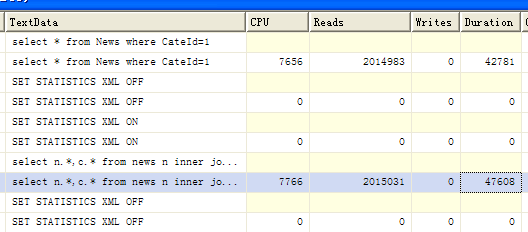
个人ASP.NET程序性能优化心得(1):数据库篇(外一篇)
这里Reads大致相同,由于语句又进行了一次合并去处,会对CPU有一定的性能消耗。
结论:将外键及相关键合并到主表上会在这种简单查询中提升一定的性能,但是它却是靠数据冗余来达到提升性能的目的,而实际上由于查询条件是在聚集索引上进行的,因此如果是数据量不大的情况可以不必考虑这种情况。
2、DateTime类型问题
上一篇文章我提到了一个观点,DateTime比Int性能要高,这是很武断的结论,而且那个例子里我仅是以排序来去说明。事实上两者类型都是BigInt类型来存储在数据库中的,只不过DateTime占用8个字节,Int占用4个字节,在这种简单的排序中性能基本没有任何差别,DateTime具有强大的时间运算函数,Int类型当然达不到这些功能,这时候使用DateTime是必须的,但如果是类似ORDER BY AddTime DESC这种情况,假设添加时间默认值是GETDATE(),那么这个排序与主键排序应该是一致的,这时建议使用ORDER BY NewsID DESC来进行排序。
SQL语句如下:
select top 5000 * from News order by addtime desc select top 5000 * from News order by NewsId desc
在SQL Server Profiler中执行结果如下:
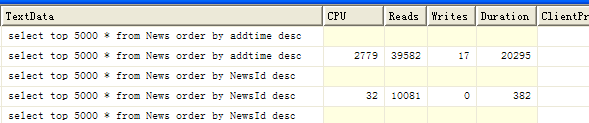
因此结论是:DateTime类型还是继续保留使用吧,如果存储的实际上是SmallDateTime建议还是使用smalldatetime来存储数据。
3、SELECT TOP 1问题
搞清楚聚集索引就一定会明白这个问题,主键一定是聚集索引,在聚集索引上进行查询性能其实影响不大,下图分别是带TOP 1和不带TOP 1对查询条件在主键上的分析:
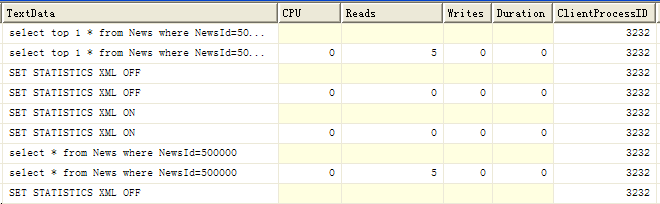
个人ASP.NET程序性能优化心得(1):数据库篇(外一篇)
而在复杂查询条件下我们就需要更多的参数进行查询,这个时候条件列往往假设在没有索引的情况下,就会进行全表扫描。这个时候性能就会受到影响,不使用TOP 1情况下:
select * from News where NewsId=500000 and PostUserName='walkingp'
执行计划如下:
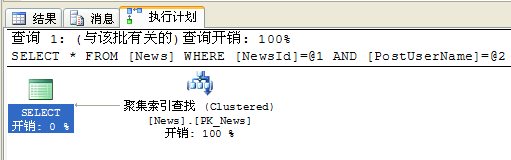
个人ASP.NET程序性能优化心得(1):数据库篇(外一篇)
个人ASP.NET程序性能优化心得(1):数据库篇(外一篇)
使用TOP 1进行条件约束情况下:
select top 1 * from News where NewsId=500000 and PostUserName='walkingp'
可以看到在查询到结果后符合TOP数目即返回了结果,这样就节省了全表扫描的时间:
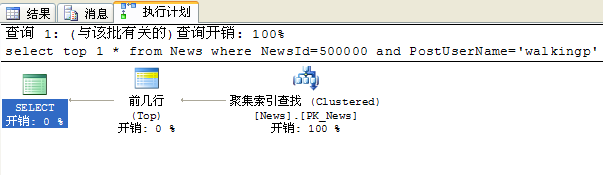
详情对比如下图:
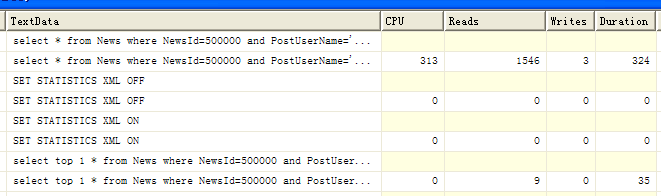
因此结论是对于查询不全部在(聚集)索引上的查询,如果仅是需要返回某几条,建议采用TOP进行约束,这种性能上的差异在嵌套查询IN等会体现得更加明显。
4、Hits、UpdateTime字段是否应该从表中分开
这类字段属于主表中更新最为频繁的字段,频繁对一张大数据量进行更新数据,显示会造成性能下降,因此在数据量较大时建议将这类数据分离到另一张表中,并对该表中逻辑外键列建立索引以提升性能。
新表结构如下:
News(NewsId,NewsTitle,Content,CateId,CateTitle,PostUserId,PostUserName,AddTime,DateNum,CommentNum)//Hits:点击数;CommentNum:评论次数 Hits(NewsId,Hits) Cate(CateId,CateTitle)
5、外键问题
外键问题影响性能是不言的事实,我们这里也是主要以性能为最主要考察点,当然具体情况其实更要以具体情况来考虑,外键是维护数据完整性重要的一个手段,在某些应用场合下数据的完整性可能要比性能更加的重要,这种情况下建议还是要建立外键。这种性能上的消耗相对于业务上的重要性要小得多,另外也可以通过其他优化方式来进行性能的优化。
对于互联网应用,数据增长极其快速,另外设计不合理、编码不严谨等方面都会造成运行中不可预料的问题(除了CSDN上那位老湿,谁敢保证0 bug?),相对来讲,使用外键的成本要高很多。当然对于企业网站这种小型系统,建议还是使用外键,最起码可以规范自己的编码规范。
6、Scan都是会进行全表扫描吗?
在物理上,SQL Server使用三种方法来组织其分区中的数据:1、用B树存储有聚集索引的表数据页;2、使用堆来存储没有存储组织的表;3、非聚集索引使用与聚集索引相类似的B树来存储索引结构。针对这三种不同结构,SQL Server使用的数据检索方法也会不一样:
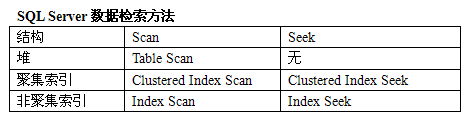
这其实已经是一个相当深奥的知识点了,我本人现在也是一知半角,上图来自《Microsoft SQL Server企业级平台管理实践》一书,结论如下:SCAN并非都会进行全表扫描;在某些情况下,Scan并非比Seek性能差。想要完全搞明白它,需要更清楚SQL Server核心的一些查询机制。
但是值得注意的是,一般情况下我们的查询以简单查询为主,这种情况下要尽量避免Scan,尤其是类似多重嵌套查询这种复杂的场景。
7、见识索引的强大
索引的概念相信不用我来讲了,下面以实例来说明索引的强大作用。
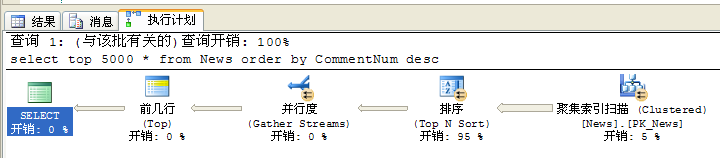
首先是在不建立索引的情况下对CommentNum(评论次数)进行倒序排序:
select top 5000 * from News order by CommentNum desc
然后对CommentNum建立索引:

重新执行SQL语句:
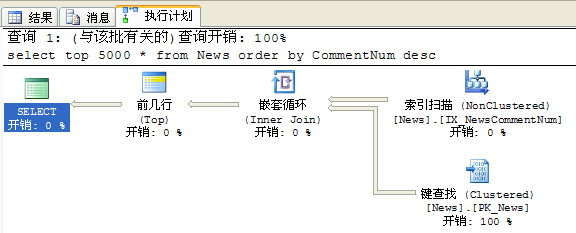
可以看出,在没有建立索引前,时间主要花费在排序上,而建立索引后时间就基本上全部都在查找了。两者对比如下图:


针对查询中可能出现的复杂条件可对其进行分析适当建立索引,一定会让性能大大提升。
最后,最重要的一点是,在实际的数据库应用中,应当灵活运用,不能拿理论去死套,在存在疑惑的地方可以自己去测试一下,多去查阅一些相对权威的资料,这样技术就在不断的慢慢进步了。
针对本文中有任何问题的,欢迎回复讨论。
参考资料:
《Microsoft SQL Server企业级平台管理实践》
本文同时发在我的个人主页:http://www.walkingp.com/?p=1136