上篇文章引起不少有价值的回复,我也学到不少东西,谢谢大家。
在此对上篇做下补充说明:
1,因本人毕业以来从事的项目全是业务逻辑复杂的企业应用软件,ERP,SCM,HRP,CRM……,这种系统,如Martin Fowler在PEAA一书中所说,是适合使用Domain Model的,上文和本篇讨论的都是基于这样的场景和前提。
2,正如一哥们回复中说的,天下没有绝对的东西,我们都在写随笔,不是写论文。这两篇文章只是提供一种看待问题的视角,看问题的视角多了,到了具体的项目,就会有更多的选择。
3,写上篇时没想到要分上下篇,导致整个上篇没有说明啥叫“裸奔”,不过从评论看,大部分人都读懂了:就是让“领域模型”不依赖于其它任何东西(如数据访问层)。
天气热了,实在不想下了班还鼓捣技术,不过想想还是一鼓作气写完拉倒。
逻辑依赖与物理依赖
上篇留下的问题是:为什么“业务逻辑”要依赖于“存储技术”?为什么“目的”要依赖于“手段”?
其实“目的”依赖于“手段”并没有什么问题,但更准确的说法应该是“目的”受约束于“手段”,具体说就是“业务逻辑层”受约束于“数据存储层”,举个例子,如果使用NHibernate作为ORM框架,设计的“领域模型”一定是把所有属性都设置为virtual,为了迁就于NHibernate的LazyLoad实现技术。这种迁就或者依赖是无法消除的,然而这里说的是概念上或逻辑上的依赖。
如果到了具体实现上,仍然存在这种依赖,就成了物理上的依赖,简单地说就是BLL这个assembly会对DAL这个assembly有个引用。物理依赖有什么问题?
反馈延迟带来的伤害
先离题一下说说反馈。举个例子,我们拿着杯子去饮水机接水,随着水位的上升,我们知道何时应该停止,这就是眼睛看到水位后,大脑给出的反馈。如果反馈延迟(哪怕只延迟2秒)甚至根本没有反馈,会有什么后果?水溢出来了,大脑才反应过来,后果一定是手被烫到。
简单的例子可以说明反馈被延迟带来的危害。然而在软件开发中,很多团队不断地被延迟的反馈所反复蹂躏伤害。此话怎讲呢?
举个例子吧,“代码即设计”,如果代码就是我们的设计,那么如何保证我们的设计正确?很多团队最常见的办法是人肉测试。把代码打包成软件,然后丢给测试人员甚至客户。在我经历过的一个瀑布式软件过程里,今天写好的代码,也许要一个月后才会到测试人员手中,半年后到客户手中,也就是说,外界对我们设计(代码)的验证和反馈周期,需要几个月之久。这是多么大的延迟,2秒延迟就会烫伤我们的手,几个月,我们伤的起吗?
如何加速反馈
这就是“迭代开发”被引入的一个理由:缩小反馈周期。一个迭代(常见的是2周)内必须把反馈圈给结束掉,也就是2周内完成一个Feature的需求分析、设计、代码、测试等所有环节。从这个角度出发,如果一个迭代里不能getting things done,那不叫迭代,那就叫“两周”。
对于一个Feature来说,两周的反馈周期是可以接受的,毕竟每两周有个功能点给客户看看,确保我们do the right thing,很不错了。
然而如何保证我们do things right(比如,设计和可维护性等等足够好)呢?还有,这两周做的正确的东西,如何保证随着功能的不断增加而不会在将来被破坏呢(答案:回归测试)?如果每两周都人肉回归以前做过的所有功能,那就需要太多QA了。
答案就是自动化测试。Unit Test保证do things right;验收测试/集成测试来保证do right things。
自动化测试金字塔
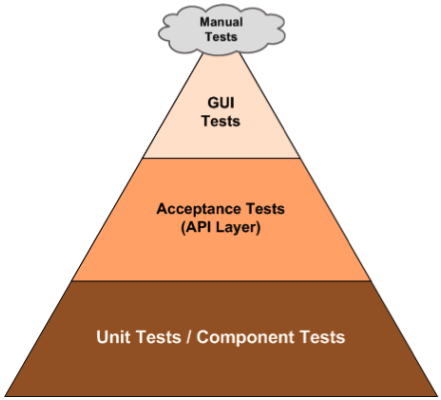
如图,意思是什么呢?如果一个项目的所有自动化测试用例是100,那么最下面的Unit Test应该占80个左右,中间的集成测试占15个左右,上面的UI驱动的验收测试占5个左右。(还有个最上面的人肉测试,那是浮云:))为啥呢?因为Unit Test的ROI(投资回报率)最高,它上手容易、运行快,UI驱动的验收测试的ROI最低,运行慢、维护成本高(因为UI是很易变的,UI一变,UI测试脚本就得改。)
所以一个团队如果要开始自动化测试,最好从Unit Test开始。而最应该写Unit Test的地方是哪个地方呢?毫无疑问,是我们的“目的层”——“领域模型层”。
Persistence Ignorance
回到我们的问题,“领域模型层”对“数据存储层”有物理上的依赖,导致的不好的结果就是,很难写Unit Test。想象一下,有个Customer类,它的AddOrder()方法里面调用了DAL层的东西,也就是连接了数据库,那我跑我的UT时也一定要连数据库。连数据库的UT那不叫UT。
怎么办呢?“依赖反转”,Inversion Of Control,IOC。具体做法是:本来BLL依赖于DAL,现在抽一个接口IDAL,让BLL依赖于IDAL,DAL从IDAL继承。从Assembly上来说,BLL和IDAL放到一个Assembly里,DAL放到另一个Assembly,那么DAL这个Assembly现在对BLL那个Assembly有个依赖了。——这样,就把依赖给反转了。然后通过Dependency Injection,在运行时把DAL作为IDAL的运行时实例,注入到BLL中。这就是IOC和DI的关系,他们其实不是一个东西,只不过很相关,有时就用IOC或DI泛指这项技术了。
BLL对DAL的依赖,从编译期延迟到了运行期,编译期对DAL没有依赖,只对IDAL有依赖,这就是Persistence Ignorance(不知的请google之)。
这有多重要?
BLL(领域模型)开始裸奔了,它对其它层没有依赖,我们可以为他写丰富的Unit Test,这有多重要?
每个unit test都用其方法名说明了我们的设计意图,甚至小片业务逻辑,比如有个测试用例,方法名叫“should_promote_to_VIP_when_customer_buying_platinum_card”,如果让你接手一个别人留下的代码,你不是很清楚里面的业务逻辑,你是愿意去看文档?还是愿意去看他留下的存储过程、或者100行又臭又长的方法?还是愿意看这样的一句话:“当客户买了白金卡后,应该把它提升为VIP”?
unit test的覆盖率足够高时,我们读完所有的unit test方法名(只是名字),我们已经了解了大部分的业务逻辑。
事实上,一个项目的维护成本往往是开发成本的四五倍甚至几十倍(越差的代码,这个比例越高)。另外大家也深有体会:读代码比写代码难。那么为了降低读代码或者维护别人/自己代码的痛苦(当老板的,降低维护成本意味着白花花的银子啊),有啥理由不让我们的“领域模型”裸奔呢?
丰满的领域模型裸奔着向我们呼啸而来
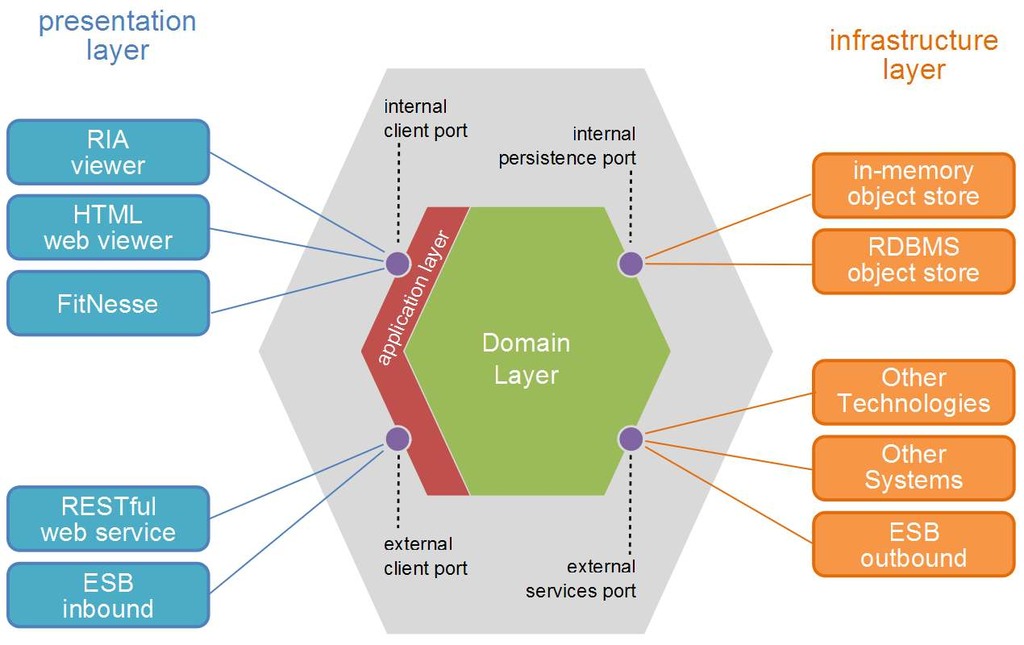
下图是敏捷宣言签署者之一的Alistair Cockburn的Hexagonal Architecture,很精彩的图,留作参考资料,大家意会,不解释了。