Ruby 101:方法对象
Written by Allen Lee
从方法调用说起
在上一篇文章里,我们看到调用对象的方法实质上是向对象发送消息,下面,我们再来看一个有趣的应用。在Ruby里,字典可以通过 {key => value} 来创建,如果你使用的版本是1.9或以上,当key的类型是Symbol时,创建字典的语法可以进一步简化为 {key: value} (注意,冒号要紧贴在key后面),这使得我们可以创建这样的对象:
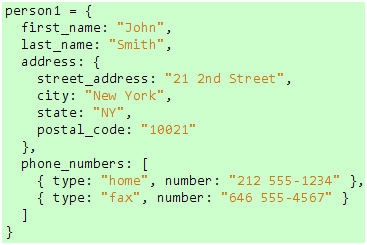
代码 1
有没有觉得这个写法很面熟?有些同学可能已经看出来了,这个写法很像JSON,事实上,这个代码正是仿照Wikipedia上的JSON示例代码写出来的,然而,由于它本身是一个字典对象,在访问里面的内容时需要使用字典的语法:

代码 2
现在,请思考一下,有没有办法使它接受这样的做法呢:

代码 3
有些同学可能已经反应过来了——打开Hash类,重写method_missing方法:

代码 4
当我们调用first_name和phone_numbers等不存在的方法时,就会触发method_missing方法,它首先检查字典是否包含这个方法名,若是,返回对应的值,否则,转交super处理。下面,我们执行一下代码:
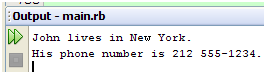
图 1
很好,基本上达到我们的预期了,但是,这种做法至少存在两个弊病,第一,它强制所有字典使用这种重定向逻辑,第二,如果字典的现有方法和它的键出现重名,重定向逻辑将被忽略,因为现有方法将被优先调用,不会触发method_missing方法,那么,怎么解决这两个问题?嗯……很抱歉,这些问题不是今天的主角,还是待到它们的主戏上演之时再行分解吧……
现在,请思考一个问题,当我们调用一个方法时,我们只需"直呼其名",像代码3的first_name和city等方法那样(当然,加上"()"也是可以的,即person1.first_name()),这意味着,当我们引用一个方法的名字时,我们实际上在引用它的返回值,那么,如果我想把一个方法本身而不是它的返回值作为参数传给另一个方法呢?考虑这样一个情景,我有一个购物车,内有图书若干:

代码 5
图书通过calc_preferential_price方法计算优惠价格:
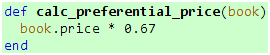
代码 6
现在,我想创建一个check_out方法,用来计算货款:
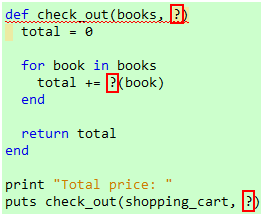
代码 7
那么,我该如何把calc_preferential_price方法传给check_out方法?
直接把方法的名字传给它肯定不行,因为"直呼其名"意味着调用它,得到的是它的返回值而不是它本身,再说,calc_preferential_price方法是有参数的,仅仅"直呼其名"会引发ArgumentError异常,那么,怎样才能得到calc_preferential_price方法本身呢?在回答这个问题之前,我们得先搞清楚,"方法本身"是什么,它是以什么形式存在的?有些同学可能猜出来了,是对象。在Ruby里,所有对象都有一个method方法(这个说法其实不够准确,但就目前而言,你大可放心这样理解),你可以通过它获取对象的实例方法的对象:
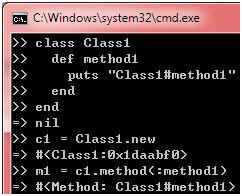
图 2
从上图可以看到,m1实质上是Method类的实例,你可以通过它的call方法调用method1方法:
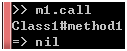
图 3
然而,calc_preferential_price方法并不在任何类里啊,我们应该通过哪个对象的method方法来获取它的对象?在上一篇文章里,我曾经说过,在Ruby里,任意一个时刻都有一个默认对象,那么,此时的默认对象又是什么呢?我们可以通过self来获知:

图 4
从上图可以看到,此时的默认对象是main对象,它是Object类的实例,事实上,我们通常把这些"游离"方法称作顶层方法(top-level method),它们是以Object类的私有实例方法的形式存在的,换句话说,你可以在任何对象内部调用它们(这个说法其实不够准确,但就目前而言,你大可放心这样理解):
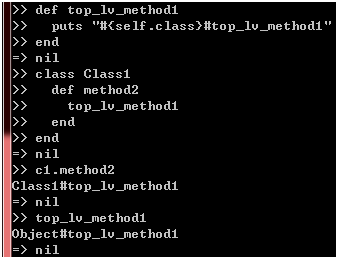
图 5
有了这些准备知识,我们可以把代码7补充完整了:
代码 8
值得提醒的是,由于默认对象正是calc_preferential_price方法的所属对象,于是我们可以省掉method方法前面的"消息接收者",当然,你也可以自行加上。下面,我们看看运行结果:
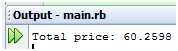
图 6
对于实例方法,我们可以通过method方法来获取它的对象,那么,类方法的对象又该如何获取呢?比如说,下面的Class1类的method3方法:
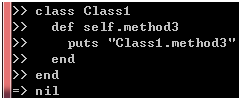
图 7
我们知道,Class1类是一个对象,所以它也有method方法,而method3是它的单例方法,所以我们可以通过它的method方法获取method3方法的对象:
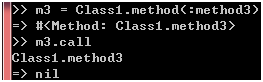
图 8
现在,请思考一下,如果method3是一个顶层方法呢?比如下面的top_lv_method2:
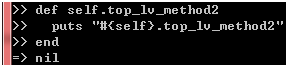
图 9
它和没有self.前缀的顶层方法有没有什么区别?它是Object类的私有实例方法还是私有类方法?在回答这些问题之前,我们得先搞清楚self是什么,从图4可以看到,self是main对象,所以它是main对象的单例方法,它和没有self.前缀的顶层方法之间的区别是,它是main对象的公有方法,并且只能通过main对象调用。说到这里,获取top_lv_method2方法的对象对你来说应该不难了:
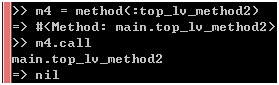
图 10
值得提醒的是,method方法无法获取代码1的first_name和city等方法的对象,因为它们并非真实方法。
说了这么多,也只不过想传递一段逻辑而已,而上面的做法似乎比较繁冗,有没有更好的选择?当然有,这也正是下一节要讲的内容。
传递逻辑
说到传递逻辑,有些同学马上想到.NET的委托,在Ruby里,类似的机制是通过Proc对象展开的,比如说,我们想把calc_preferential_price方法里面的逻辑传给check_out方法,那么我们可以这样做:

代码 9
我们通过Proc类的new方法创建一个Proc对象,同时,传递一块代码,这块代码用{}包围,里面包含两个部分,|book|是参数部分,多个参数可以通过逗号分隔,而book.price * 0.67则是主体逻辑,也是这块代码的执行结果,我们通常把这块代码称作代码块(code block)。那么,Proc对象包含的代码块如何才能执行呢,参数是如何传递的呢,执行结果又是如何获取的呢?答案非常简单,运行一下代码9就知道了。有些同学可能感到疑惑,难道check_out方法不用修改?是的,而且运行结果和图6的一样,这意味着Proc对象的使用方式和Method对象的一样,都是通过call方法来执行与之关联的代码逻辑,我们传给call方法的参数将会传给Proc对象包含的代码块,而代码块的执行结果将会通过call方法返回给我们。如果你使用的版本是1.9或以上,那么你可以proc方法来创建Proc对象,效果和通过Proc类的new方法来创建是一样的:
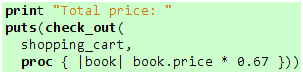
代码 10
当然,我相信没有人会认为把calc_preferential_price方法的主体代码复制到Proc对象的代码块里是个好主意,这样会增加维护成本,即使代码量很少,于是,对于现有的方法,像calc_preferential_price方法,我们可以在代码块里直接调用它:

代码 11
乍看之下,这种写法比代码8的更加繁冗,然而,它却能带来一些特别的好处:
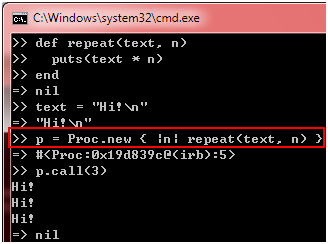
图 11
我们首先定义一个repeat方法,它的工作非常简单,把text文本输出n次。接着,我们创建一个text变量,并把一个字符串对象赋给它。然后,我们创建一个Proc对象,调用repeat方法输出text文本n次。最后,我们通过call方法执行Proc对象包含的代码块,向控制台输出3次"Hi!"。仔细观察创建Proc对象的那行代码,我们在代码块里引用外面的text变量,并用它"固定"repeat方法的第一个参数,有些同学可能已经看出来了,这正是闭包(closure)的应用。
不过,这种显式创建Proc对象并传给方法的做法比较少见,更常见的做法是把代码块附加到方法调用后面:

代码 12
上面代码创建/打开books.txt文件,并把shopping_cart里的书名写进去,完成之后文件流会自动关闭。如果你依样画葫芦,把代码11改成这样:

代码 13
当你运行代码时,你将被告知少了一个参数,显然,Ruby不把代码块看作参数列表的一部分,如果你希望Ruby把check_out方法的calc参数和你提供的代码块关联起来,那么你需要在calc参数前面加上&:
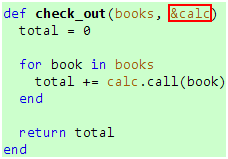
代码 14
再次运行代码,你就会得到图6的输出了。那么,在参数前面加上&之后究竟发生什么事呢?事情是这样的,当你运行代码13时,Ruby发现check_out方法的calc参数前面有个&,而你只提供了一个参数和一个代码块,于是,Ruby假定这个代码块是和calc参数对应的,然后用你提供的代码块创建一个Proc对象,并把它绑定到calc参数上,你可以把这个过程看作从代码块到Proc对象的隐式转换。那么,这种带有&前缀的参数可不可以有多个呢?我们可以试一下:
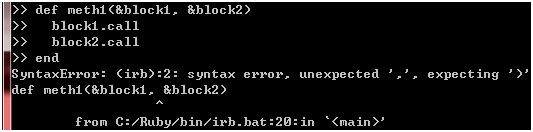
图 12
噢,出错了!Ruby不允许定义这样的方法,这意味着一个方法只能有一个带有&前缀的参数,此外,Ruby期望跟在block1参数后面的是)而不是,,这意味着带有&前缀的参数应该放在参数列表的末尾,换句话说,你不能把其它类型的参数放在带有&前缀的参数后面:

图 13
既然Ruby不把代码块看作参数列表的一部分,那么Ruby是否支持某种不通过参数来使用代码块的语法呢?当然有啦!Ruby提供了yield关键字:

代码 15
正如你所看到的,yield关键字的使用很像方法调用,你可以把参数传给它,你也可以使用它的返回值,实际上,参数最终是传给代码块的,而返回值也是来自代码块的。此外,我们看到check_out方法的签名也变了,calc参数已经不再需要了。如果我们只需在方法里面即时执行代码块,那么使用yield关键字就足够了,同时我们也可以得到更简洁的代码;如果我们需要延迟代码块的执行,比如说在将来某个条件满足的时刻才执行,那么我们还是需要通过代码14的写法来捕获代码块,把它保存到某个实例变量,以备后用。如果你现在运行代码11,你将被告知多了一个参数,如果你把第二个参数去掉:

代码 16
你将被告知缺少代码块,显然,你需要告诉Ruby把你提供的Proc对象当做代码块来处理,怎么才能做到这样呢?答案是在Proc对象前面加上&:

代码 17
再次运行代码,你就会得到图6的输出了。现在,请思考一下,如果我们希望check_out方法在有代码块的时候计算优惠价,没有的时候按原价计算,那么我们应该如何做呢?实现这个功能的关键在于如何检测代码块是否存在,这可以通过block_given?方法做到,于是,我们可以把check_out方法修改如下:

代码 18
下面我们来看看运行结果吧:
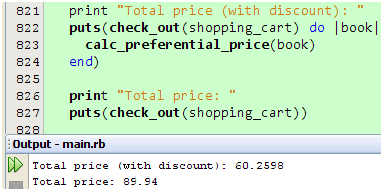
图 14
有些同学可能已经注意到了,有些代码块用{}来包围,有些则用do/end来包围,那么它们是否一样的呢,如果不是,又有哪些区别呢?我们试一下就知道了:
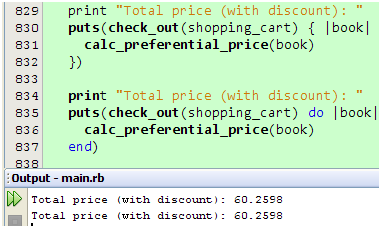
图 15
看来没什么区别嘛,难道只是代码风格不同而已?我们知道,Ruby允许我们在调用方法的时候不用括号来包围参数列表,如果我们把包围puts方法参数的括号去掉又会怎样呢?试一下就知道了:
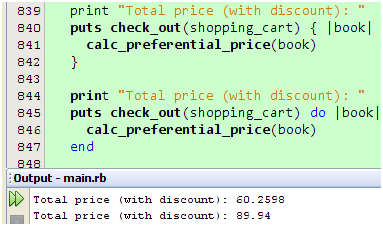
图 16
哈哈,这次看出区别了!把这个运行结果和图14的对比一下,不难发现,第二次计算结果和没有提供代码块的一样,这意味着代码块根本没有传给check_out方法! 这个结果正是{}和do/end两种写法的不同所致,用{}包围的代码块会优先和check_out方法的调用结合,整个东西的执行结果会成为puts方法的参数,而用do/end包围的代码块则和puts check_out(shopping_cart)的执行结果结合,换句话说,Ruby把图16的代码解释成:
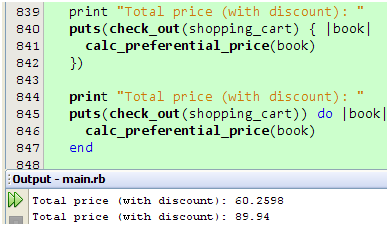
图 17
显然,用do/end包围的代码块传给puts方法了,由于puts方法不需要它,于是它被忽略了,就像不曾存在一样。当然,如果你在调用方法是总是用括号包围参数列表,那么你就不会受到这个问题的困扰了。
前面我们提到,如果你使用的版本是1.9或以上,那么你可以proc方法来创建Proc对象,然而,proc方法在1.9版本之前就有了,只是创建出来的是一种特殊的Proc对象,通常称为lambda。除了proc方法,Ruby也提供了lambda方法,在1.9版本之前,proc方法和lambda方法创建出来的都是lambda,到了1.9版,proc方法创建出来的是普通的Proc对象,而lambda方法创建出来的则是lambda。那么,lambda和普通的Proc对象有什么区别呢?主要有3个,第一个区别是我们必定会遇到的,普通Proc对象和代码块之间可以隐式转换,但lambda一定要显式创建,否则你得到的就是普通Proc对象:
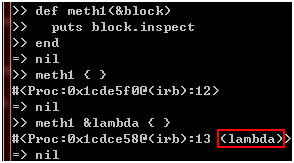
图 18
第二个区别是我认为最重要的,假设我们有这样两个方法:
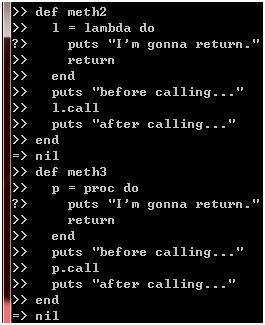
图 19
除了第一个方法里面使用lambda,第二个里面使用普通Proc对象之外,它们没有任何区别,那么,这两个方法的执行结果会否一样呢?试一下就知道了:
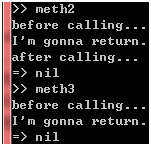
图 20
看到区别了吗?meth3方法的"after calling…"没有输出!这意味着meth3方法在执行puts "after calling…"这句之前就返回了,而导致meth3方法非预期返回的正是普通Proc对象里面包含的return关键字,换句话说,普通Proc对象里面包含的return关键字会改变方法的执行路径。说到这里,你可能会担心,如果别人传过来的代码块包含了return关键字,是否也会导致我们的方法出现非预期返回?我们不妨试试看:
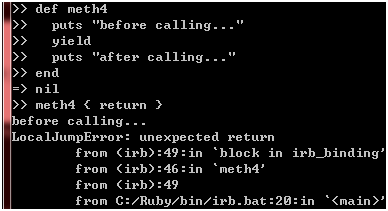
图 21
噢,抛异常了!这下你多少可以放心了吧。最后一个区别是关于参数的,比如times方法的使用:

图 22
我们既可以传给它一个不带参数的代码块,也可以传给它一个带参数的,即使参数的数目多过它提供的也不会出问题,如果换用lambda,情况就不一样了:
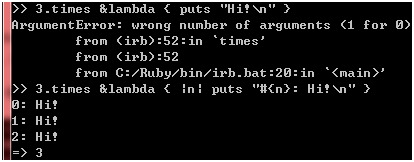
图 23
从这里可以看到,lambda对待参数是很严格的,数目必须刚好,多一个或者少一个都不行,从这个角度来看,lambda更接近方法。
Ruby 1.9引入了一种新的lambda写法:
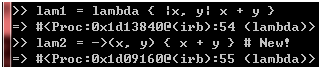
图 24
上面这两种写法是等效的,此外,新写法的()是可以省略的:
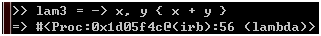
图 25
为什么要引入新的写法?据说是为了使lambda支持参数默认值:

图 26
好,那么我很想知道,新的语法是否也支持可变参数以及代码块?我们来试试看:
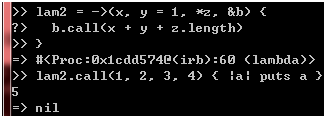
图 27
沃,真的支持耶!那么,yield关键字也支持吗?
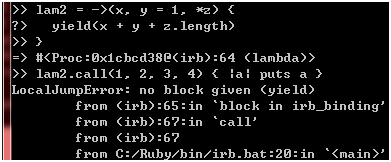
图 28
这次不行了。现在,我的脑子里蹦出一个念头,用旧的语法改写图27的lambda会怎样呢?我们来试试看:

图 29
额,有点无语哦,不是说这种写法对于现有解析器来说是不可能的吗,难道换了解析器?不管了,我们再来试试yield关键字:
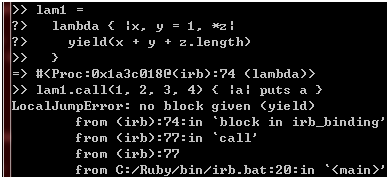
图 30
呵,情况一样。现在,我还想知道,普通的Proc对象对参数的支持是否像lambda一样?我们来试试看:
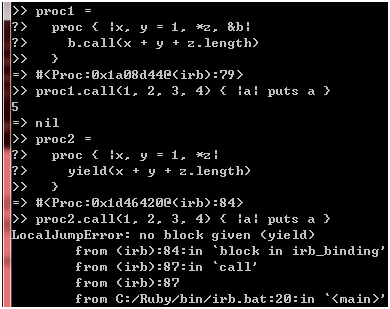
图 31
一样的!说到这里,你可能会问,既然新旧lambda写法毫无二致,为何还要引入新的写法?嗯,我也不知道,不过这让我想起一句话:
In Ruby, there's always more than one way to solve a given problem.
就像lambda的调用方式也有3种一样(这3种方式也同样适用于普通Proc对象和Method对象):
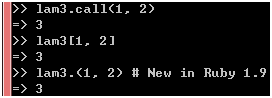
图 32
现在,这把"大刀"也砍向lambda了。至于这些风格迥异的写法孰优孰劣就见仁见智了,而这种允许多样性存在的想法是好是坏则更是见仁见智了。
既然谈到lambda了,接下来我想谈谈两个和它密切相关的主题:高阶方法和分部应用(partial application)。Ruby不是函数式编程语言,方法本身不是值,所以我们无法直接传递/返回方法,但借助lambda,创建高阶方法将不再是难事:

代码 19
那么,分部应用呢?比如下面这个代码:
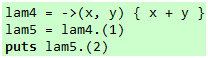
代码 20
这样真的可以吗?仔细想想就知道了,lambda对待参数非常严格,不提供足够参数是不行的,那么,普通Proc对象对待参数比较宽松,是否能成呢?我们不妨试一下:

图 33
我们确实避开参数问题了,却被主体代码挡住了,当我们调用Proc对象并提供一个参数时,另一个参数的值会默认为nil,接着,执行1 + nil就引发异常了。如果我们确实想使用分部应用,一个办法是使用"原装"lambda写法,根据Wikipedia,"在 lambda 演算中,每个表达式都代表一个只有单独参数的函数,这个函数的参数本身也是一个只有单一参数的函数,同时,函数的值是又一个只有单一参数的函数",于是,我们可以把代码20改成这样:
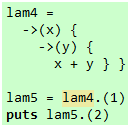
代码 21
这下就没问题了。值得提醒的是,把lam4从代码20变成代码21的过程叫做柯里化(currying),函数式编程语言的函数默认支持柯里化,然而,Ruby从1.9版开始也对此提供了一定程度的支持:

代码 22
柯里化是在Proc对象层面提供支持的,这意味着普通Proc对象和lambda都适用。
操作集合
现在,让我们把注意力集中在代码19,请思考一下,要让for循环正常运转,shopping_cart对象是否需要满足一些条件呢?我们不妨随便找个对象来试一下:
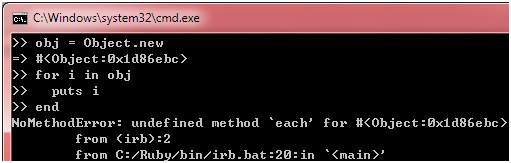
图 34
显然不行,然而,错误信息已经向我们透露了for循环需要一个each方法,那么,如何定义这个each方法呢?想想看,each方法应该是如何使用的呢?按照字面意思理解,它会把集合里面的东西一个一个地传给你,由你来决定如何处理这些东西,换句话说,你应该传给它一段处理逻辑,说到这里,有些同学可能已经反应过来了,我们可以传给它一个代码块,比如下面这段代码会把购物车里的所有书名输出到控制台:
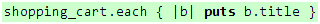
代码 23
使用上一节学到的知识,我们很容易就把这样的方法实现出来了:

图 35
我们把each方法定义为单例方法,仅对obj对象有效,它会依次把1、2、3传给你。现在,我们可以再试一下for循环了:
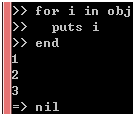
图 36
由于for循环最终也是调用each方法的,我们何不直接使用each方法?
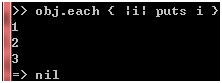
图 37
使用each方法和使用for循环在效果上是一样的,然而,each方法可以有返回值,那么,for循环呢?这个问题听起来有点怪异,但是,在Ruby里,for循环本身也是一个表达式,既然是一个表达式,它也应该有一个运算结果,事实上,图36和图37已经分别告诉你for循环的运算结果和each方法的返回值了,都是nil,那么,如果我改变each方法的返回值会怎样呢?我们不妨试试看:
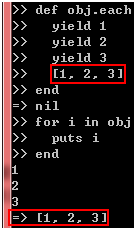
图 38
嗯,上图已经充分说明for循环的运算结果是来自each方法的返回值了,事实上,像数组和字典等集合的each方法都是返回集合本身的,这意味着for循环的运算结果也是集合本身:
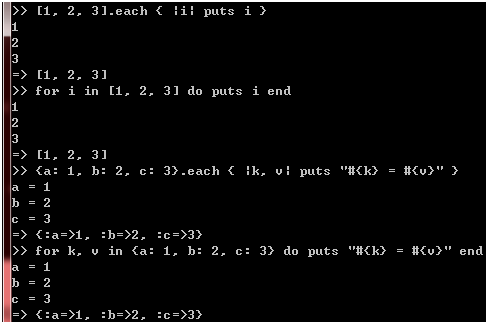
图 39
值得提醒的是,当我们把for循环写到一行时,中间要用do(或者;)分隔。另外,字典的each方法传给我们的不是两个参数,而是一个长度为2的数组,第一个元素是键,第二个是值,我们只需把each方法的调用稍稍修改一下就看出来了:

图 40
在Ruby里,数组可以进行类似模式匹配的解构:
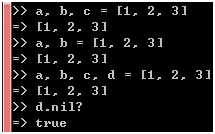
图 41
当变量的个数少于或者等于数组的长度时,每个变量都会得到对应位置的数组元素,当变量的个数大于数组的长度时,超出的那些变量将会是nil。事实上,右值不必是数组,把包围数组元素的[]去掉也是可以的:
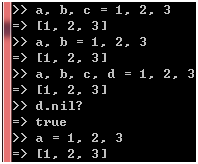
图 42
在Ruby里,这种赋值方式有个正式的名字,叫做并行赋值(parallel assignment),当左值只有一个,而右值却有多个时,右值将被转换成数组并赋给左值。
当你在你的集合类里实现each方法并包含Enumerable模块时,你将会得到一大堆很有用的方法,比如说,select、sort_by、map、reduce、take_while等等,这些方法都是建立在each方法之上的,你不必自己实现它们,只要你实现了each方法,它们就可以使用了,这极大地简化了集合类的创建过程,如果现有算法无法令你感到满意,你也可以重写它们。一般而言,除非你打算创建自己的集合类,否则你更感兴趣的应该是如何使用现有的集合类以及Enumerable模块提供的方法。接下来,我们将会通过一个简单的示例学习如何使用Enumerable模块提供的几个常用的方法。
我们的任务非常简单,从购物车里选出6本(或以内)共计金额不超过150元(以优惠价为准)且标题包含"Ruby"字眼的图书,输出它们的书名,计算总价(打折以后)、节省金额以及节省百分比。我相信这个任务对于你来说一点都不难,你甚至可以轻易想出多种不同的解决方案,下面,我们来看看其中一个可能的做法吧。
首先,我们通过select方法从购物车里选出标题包含"Ruby"字眼的图书:
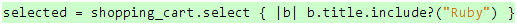
代码 24
它会把购物车里的图书一本一本地传给我们提供的代码块,并根据代码块的返回值来决定是否选择某本书,此外,你也可以添加其它条件,比如说,你还希望选出的图书都是4星以上,前提是你拥有可以操作的评级数据。
接着,我们通过map方法从上面的结果里提取出每本书的标题和原价,并计算优惠价:

代码 25
上面的代码看起来非常直观,就像数据从一组匿名对象按照特定的规则映射到另一组匿名对象似的,此外,我们还要感谢代码4,由于它的存在,字典能以类似匿名对象的方式使用,极大地提高了代码的可读性。
然后,我们通过sort_by按照优惠价对上面的结果进行排序(默认是从小到大):
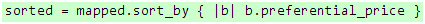
代码 26
它会把集合里的对象一个一个地传给我们提供的代码块,并根据代码块的返回值来对集合进行排序。此外,我们也可以通过sort方法进行排序,但代码块的写法会有所不同:

代码 27
接下来,我们要从上面的结果里选出6本(或以内)共计金额不超过150元的图书,对于前一项任务,我们可以通过take方法来处理:

代码 28
至于后一项任务,我们可以通过take_while方法来处理:

代码 29
它和take方法的区别在于,take方法取多少是由一个整数来决定的,而它取多少则由我们提供的代码块是否返回true来决定的,当代码块返回false时,它就会停下来并返回已经取出的对象。
最后,我们要把所有数据整合起来,能够胜任这项任务的非reduce方法莫属了:

代码 30
我们期望最后的结果包含一组书名、折后总价以及节省金额,这个结果可以看作一个包含3个元素的数组,第一个元素是一个数组,后两个元素都是整数,于是,我们把[[], 0, 0]作为初始值传给reduce方法。代码块的第一个参数是累计变量,第二个参数则是集合里的对象,而代码块的任务非常简单,把书名加到累计变量的第一个元素,把图书的折后单价加到累计变量的第二个元素,把图书的原价和折后单价之间的差价加到累计变量的第三个元素,然后返回累计变量。
现在,我们可以提取并输出结果了:
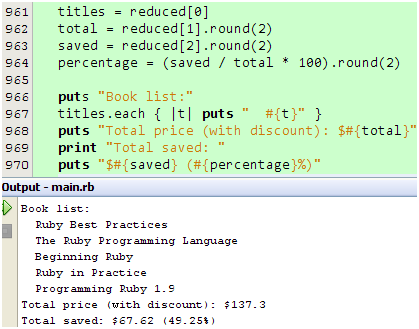
图 43
我们甚至可以把所有代码整合起来,放在一个方法里:

代码 31
值得注意的是process方法的第二个参数,我们使用了字典,并为它设置了默认值,这使得我们在调用process方法时既可以使用默认行为也可以使用定制行为,此外,当字典是最后一个参数时,Ruby允许我们把{}去掉,这样,字典参数用起来就像一组命名参数一样,而且这些命名参数还可以打乱顺序,非常直观和方便。
到目前为止,我们操作的集合都是包含了实际元素的,那么,对于那些无法包含实际元素的集合又该如何处理呢?举个例子,自然数集合,这是一个概念集合,你无法在一个具体集合里包含全体自然数,因为自然数有无穷多个,就算你愿意尝试,你的计算机也不会首肯的,不过,我们却对自然数的产生机制了如指掌,随便给你一个自然数,你都能够轻而易举地说出下一个自然数,换句话说,我们无法穷举所有自然数,但我们可以给出产生自然数的逻辑,那么,我们是否能够创建这样一个集合呢,如果可以,又该如何创建呢?
这个时侯就轮到Enumerator类出场了,它允许我们通过一段产生逻辑来描述一个集合,下面,我们来看看如何使用Enumerator类创建自然数集合:

代码 32
如你所见,整个过程非常简单,我们通过Enumerator类的new方法创建一个Enumerator对象,并通过代码块把产生自然数的逻辑传给它,这个代码块有一个参数,它是用来收集这段逻辑产生的自然数的,这段逻辑也没有难度,我们设置了一个初始值,然后在一个无限循环里把后续自然数输出到收集器。
那么,我们又该如何使用这个自然数集合呢?最直接的做法是,你想要多少个自然数,你就调用多少次next方法,如果你想重新来过,你可以通过rewind方法重设一下:
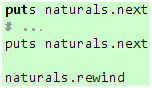
代码 33
由于Enumerator类实现了each方法并包含了Enumerable模块,我们也可以通过for循环来使用这个自然书集合:

代码 34
当然,更简单的做法是通过take方法:

代码 35
上面的代码分别获取头6个自然数、头6个自然数里的偶数以及头6个自然数里的偶数的平方,到目前为止,一切正常,但如果你把select方法的调用和take方法的调用换一下位置,你将会发现你的Ruby程序卡在那里了,为什么?因为这些方法返回的不是Enumerator对象而是数组,这意味着要对整个自然数集合进行求值,噢,买瓜!毫无疑问,这个问题将会极大地限制Enumerator类的应用,怎么办?
最直接的解决方案是打开Enumerator类并重写这些方法,使它们返回Enumerator对象而不是数组:

代码 36
现在,我们可以求头6个正偶数的平方的和了:

代码 37
那么,这几个方法原本的实现呢?被我们覆盖了,如果你希望保留原本的实现,可以在重写它们之前分别给它们取个"外号":

代码 38
这样,当你想使用原来的实现时,这些"外号"就派上用场了。
如果你不想修改Enumerator类,你也可以选用第三方的库,这里给大家介绍一个开源的惰性集合——LazyList。首先,在命令行输入gem install lazylist安装LazyList,接着,在代码里输入require 'lazylist'引用它,现在,我们来看看如何使用它实现前面的需求:

代码 39
毫无疑问,这对于LazyList来说只不过是小菜一碟,那么,如果我想创建下面这个集合呢?
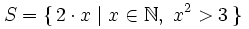
图 44
没有问题:
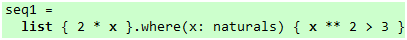
代码 40
如果我想创建一个集合,里面每个元素都是自然数集合和seq1集合对应位置的元素之和呢?也没问题:
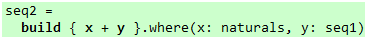
代码 41
这里的介绍只能算作一个引子,LazyList的更多潜能还有待你去发现,此外,LazyList的实现还使用了一些高级技术,比如特制的Proc对象和延迟机制等,如果你有意深潜Ruby,那么LazyList的代码绝对是一个不错的学习资源。
新的旅程
Ruby是什么?它能做什么?它又有哪些优势?这些问题让我不禁想起why the lucky stiff为《Beginning Ruby: From Novice to Professional, Second Edition》绘制的前言(节选):

事实上,这些问题几乎出现在每次我们遇到陌生语言的时候,随着我们对一门语言有了更多的了解,我们对这些问题的回答也会有所变化,我们最终可能会发现,这些最基本的问题往往是最难回答的问题,正如斯蒂芬·吉利根在《艾瑞克森催眠治疗理论》里探讨催眠本质时引用的艾瑞克森之言所说的:
"不论我说它是什么……都将会扰乱我对其诸多可能性的认识和利用。我们必须认识到,不论一种描述是多么精确或完整,都不能取代实际体验,也不适用于所有受试者。"
不论我在这里讲得多么详细,我所讲的都是Ruby的一些片段,没有你的实际体验,这些片段就无法连成一体,而我对上面这些问题的回答也就什么都不是了。
下一次,我想把注意力集中在Ruby的动态性上,希望到时能为你带来更多的惊喜!
P.S. why the lucky stiff已经"失踪"超过3个月了,希望他快点回来吧~