SICP学习笔记(1.2.1 ~ 1.2.2) 周银辉 1, 递归过程 和 递归计算过程 在学习SICP前我还没注意过有这样的一个区分,因为我们始终停留在语法表面上的“递归过程(recursive procedure)”,而
周银辉
1, 递归过程 和 递归计算过程
在学习SICP前我还没注意过有这样的一个区分,因为我们始终停留在语法表面上的“递归过程(recursive procedure)”,而没有去理解其实质是否是“递归计算过程(recursive process)”。
- 递归过程:从语法书写层面上而言的,在过程的定义中,其直接或间接地引用该过程本身。 比如 F{F}或者 F{G{F}}
- 递归计算过程:从实际运算层面上而言的,一个在语法上按照递归过程书写的函数其在运算时可能是按照递归的方式也可能是按照迭代的方式进行的。这取决于解释器或编译器本身是否有对“递归”进行优化,比如Scheme解释器是“严格尾递归”的, 而C#之类的,即便在语法形式上是"尾递归"的,但其仍然不能被编译成迭代计算过程,当然,你可以使用for,while等.
2,迭代计算过程 和 递归计算过程
根据SICP中所言,迭代计算过程就是那种其状态数目可以用固定数目的状态变量来描述的过程。要理解这个非常简单,我们可以想象一下一个 for 循环 for (int i=0; i<10; i++) {} 伴随做计算的进行(不停的迭代),这个循环的状态在不停地发生变化,但这个变化仅仅需要常量数目个状态变量就可以描述和记录了,这里是一个状态变量 i ;另外,如果这个迭代计算被中断了,要从中断中恢复运算,仅需提供 i 值就可以了。这同时也说明,该迭代过程所需要的空间是一定的,其并不会随着迭代的进行而增加。
相反的,递归计算过程,其在空间的需求上会随着递归的深入而不断增加,因为我们需要在进入地N+1次递归前保存第N次迭代的相关数据,以便最后一次递归结束后能回退到先前的递归上来,如果这样的数据保存在栈上,当栈快被“使用完毕”时还没有结束递归的话,便会导致“栈溢出”。
3,树形递归
如果我们将一次“函数调用”看做是树的一个节点的话(注意,如果要对应到语言上的话,我这里说的是函数式编程语言,在这类语言里面不关心所谓的操作数,操作符,标识符等等,它们都是函数),那么我们就可以将整个表达式描述成一棵树的形式。对于递归函数而言,如果每个节点顶多有一颗子树,很明显,该递归是线性的;同理,如果树是按照“二叉树”的形式展开的,那么我们说这是“双递归”,如果有多颗子树则是普通的树形递归。(我猜想,这同样可以在语法层面和实际计算层面来划分,所以可以分别看待“树形递归过程” 和“树形计算过程”
4, 尾递归
比较这两个递归函数:
F()
{
// do something here
A;
F();
}
G()
{
// do something here
G();
A;
}
我们说函数 F 是尾递归的,而函数 G 不是。(为表示方便,我将跳出递归的条件省略了,不要关心是否会无穷地递归)
所谓尾递归,就是将“递归”调用这件事放到函数体的最后来执行。函数 F 相比于 G 一个很大的优势在于,当 F 即将进入下一次递归时,其不需要分配空间其保存本次计算的相关数据(轨迹),因为它不需要回退了(没事可做,还回来干嘛);而函数 G 则不同,其在进入下一次递归时,必须保存本次计算的相关数据,因为当它执行完下一次递归计算后,还得回来计算表达式 A 。(这类似于后序遍历,当遍历完子节点后还得回来完成对根节点的遍历)
尾递归的好处很明显,其可以节省空间(并防止栈溢出),因为我们可以将其计算过程转化成线性的。正如上面在讲“迭代计算过程 和 递归计算过程 “ 时所言,”迭代计算过程就是那种其状态数目可以用固定数目的状态变量来描述的过程“。由于尾递归的函数不需要保存本次递归的相关轨迹,所以我们可以在进入新的一次迭代时将上一次迭代的堆栈空间重新利用起来,而不必占用新的堆栈空间,这也就是为什么尾递归不会堆栈溢出了。说出来比较抽象,看看下面的代码或许能有所提示:
myLabel : F()
{
// do something here
A;
goto myLabel;
}
很不幸的是,C# 编译器并没支持尾递归,虽然 MSIL 中有一个所谓的 tail. 前缀(用于修饰call, callvirt, calli),但我们平时使用的C#编译器并不会在编译而成的代码中使用这个前缀,原因好像是说其”效率超低“, 感兴趣的看看这里: http://connect.microsoft.com/VisualStudio/feedback/ViewFeedback.aspx?FeedbackID=98236 以及 http://blogs.msdn.com/shrib/archive/2005/01/25/360370.aspx 。
将 “递归” 转换 为“尾递归” :
对于普通的递归转尾递归,需要引入一个概念:accumulator parameter (如何翻译?累加器参数/累积参数? 学过 F# 的同学可以指导下, F#中貌似有这个概念),该类参数负责累积每次递归产生的结果值并以参数的形式传入到下次递归中。
我们看阶乘的递归形式:
(define (F n)
(if (= n 1)
1
(* n (F (- n 1)))))
转换成尾递归形式:
(define (F n)
(G 1 1 n))
(define (G a i n)
(if (> i n)
a
(G (* i a) (+ i 1) n)))
其中的参数 a 就是我们这里所谓的accumulator parameter, 它累积了每次迭代的结果值并将其作为参数传入到下一次迭代中去。如何累积的呢:新的累计值 = i * 旧的累计值
5,练习 1.9
比较下面两个过程有啥不同:
(define (+ a b)
(if (= a 0)
b
(inc (+ (dec a) b))))
(define (+ a b)
(if (= a 0)
b
(+ (dec a) (inc b))))
很简单,对于定义的 过程 ”+“ 而言,第一个是普通的线性递归过程,其计算过程也是递归的; 第二个是尾递归,其计算过程会被Scheme解释器解释成迭代的。
6, 练习1.10
对Ackermann函数求值
在班车上用草稿纸加铅笔计算的,所以这里就没给出程序了
(A 1 10) = 2^10 (A 2 4) = 2^16 (A 3 3) = 2^16
(define (f n) (A 0 n)) 表示 2n
(define (g n) (A 1 n)) 表示 2^n
(define (h n) (A 2 n)) 表示 2^2^2^... (n 个2)
7,换零钱问题
这个题目非常有意思。注意到下面这句话:
those that do not use any of the first kind of coin, and those that do. Therefore, the total number of ways to make change for some amount is equal to the number of ways to make change for the amount without using any of the first kind of coin, plus the number of ways to make change assuming that we do use the first kind of coin. But the latter number is equal to the number of ways to make change for the amount that remains after using a coin of the first kind。
换零钱的全部方式数,等于完全不使用第一种钱币的方式数目,加上使用了第一种钱币的方式数 (这比较容易理解,就相当于在说,这个世界上的人口数目,等于我不认识的人的总数,加上我认识的人的总数), 而后一个数目等于去掉一个第一种硬币值后剩下的现金数的换钱方式数(这很明显,因为使用了第一种钱币(假设为a)的换钱方式中,每种方式都包含a,所以可以将a减去)
将其翻译成 C# 代码如下:
private static readonly int[] FirstDenomination = new[] { 50, 10, 1, 5, 25 };
public static int CountChange(int amount)
{
return CountChange(amount, 5);
}
public static int CountChange(int amount, int kindsOfCoins)
{
if (amount == 0)
{
return 1;
}
if (amount < 0 || kindsOfCoins == 0)
{
return 0;
}
return
CountChange(amount, kindsOfCoins - 1) +
CountChange(amount - FirstDenomination[kindsOfCoins - 1], kindsOfCoins);
} 注意,SICP上的:
(define (first-denomination kinds-of-coins)
(cond ((= kinds-of-coins 1) 1)
((= kinds-of-coins 2) 5)
((= kinds-of-coins 3) 10)
((= kinds-of-coins 4) 25)
((= kinds-of-coins 5) 50)))
实际上相当于定义一个枚举或者数组,所以我在 C# 代码中将其翻译成了 int[] FirstDenomination = new[] { 50, 10, 1, 5, 25 }; 其中的50,25 等代表的是每种钱币的面值(统一成了美分)。
如果我们计算1美元(100美分)的话,将得到如下结果:
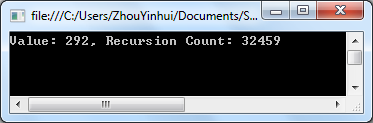
这是一个树形递归,计算步骤多么恐怖呀,递归调用了32459次, 这是一个非常痛苦的过程, 并且非常可惜的是没有简单并统一的方法将这样的树形递归转换成迭代形式。但对于不同的问题已有一些特定的解决方案来进行优化,比如对于大多数的树形递归问题,我们可以使用“动态规划”的方式来进行运算以减少运算量。关于动态规划可以参考这里:http://mat.gsia.cmu.edu/classes/dynamic/dynamic.html 或 这里 http://www.aw-bc.com/info/kleinberg/assets/downloads/ch6.pdf , 或者以后我会写点东西专门来说说动态规划与树形递归。
8,练习1.11
A function f is defined by the rule that f(n) = n if n<3 and f(n) = f(n - 1) + 2f(n - 2) + 3f(n - 3) if n> 3. Write a procedure that computes f by means of a recursive process. Write a procedure that computes f by means of an iterative process.
递归的方式:
(define (F n)
(if (< n 3)
n
(+ (F (- n 1)) (* 2 (F(- n 2))) (* 3 (F (- n 3))))))
尾递归的方式:
(define (G a b c count)
(cond ((= count 0) c)
((= count 1) b)
(else (G (+ a (* 2 b) (* 3 c)) a b (- count 1)))))
(define (F n)
(G 2 1 0 n))
根据上文讲过的 accumulator parameter 的概念 : 从这里+ (F (- n 1)) (* 2 (F(- n 2))) (* 3 (F (- n 3))))) 可以看出 , 新的累积值 = 旧的累计值a + 2 * 另外一个旧的累积值b + 3 * 另外一个更旧的累积值 , 所以 累积值 = a + 2b + 3c
9,练习 1.12
帕斯卡三角(杨辉三角),这个问题上中学时老师带着我们找个规律,蛮简单的:对于第 n 层的第 i 个数F(n, i),如果 n<=1 或者 i=0 或者 i=n 那么为 1,否则为 F(n-1, i-1)+F(n-1, i)
10, 练习1.13
利用数学归纳法比较容易证明的,另外原文没有说清楚的是: 其中, γ=1-ø ,更多的,看看 这里 : http://en.wikipedia.org/wiki/Fibonacci_number