
声明关注微信公众号:K哥爬虫,持续分享爬虫进阶、JS/安卓逆向等技术干货!
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请在公众号联系我立即删除!
逆向目标- 目标:站 Z 之家网站 ICP 备案号查询
- 主页:
aHR0cDovL2ljcC5jaGluYXouY29tLw== - 接口:
aHR0cDovL2ljcC5jaGluYXouY29tL2hvbWUvR2V0UGVyaW1pdEJ5SG9zdA== - 逆向参数:
hostToken、permitToken
本次主要是 AST 解混淆实战,本例中的 JS 混淆方式是 sojson 旗下的 jsjiami v6 版本,感兴趣的可以去官网体验一下:https://www.jsjiami.com/ ,如果你还不了解 AST,可以先看看 K 哥上期的文章(非常详细):《逆向进阶,利用 AST 技术还原 JavaScript 混淆代码》,本文部分 AST 还原代码直接使用了上期文章中的代码,所以细节方面不再赘述,有疑问的地方可以参考参考上期文章。
第三方工具逆向领域大佬云集,市面上已经有很多大佬写好的解混淆工具了,除了我们自己手动去写 AST 解析代码以外,有时候直接使用工具会更加方便,当然并没有十全十美的工具,不过大部分情况下都能成功解混淆的,以下工具值得去体验一下:
- 蔡老板一键还原 OB 混淆:https://github.com/Tsaiboss/decodeObfuscator
- 哲哥 AST 混淆还原框架:https://github.com/sml2h3/ast_tools
- V 神 Chrome 插件,内置 AST 混淆还原:https://github.com/cilame/v_jstools
- jsjiami v6 专用解密工具:https://github.com/NXY666/JsjiamiV6-Decryptor
进入主题,首先抓包看看,来到 ICP 备案查询页面,查询结果中,其他信息都可以直接在相应的 html 源码中找到,只有这个备案号是通过接口传过来的,对应的请求和相关加密参数如下图所示:
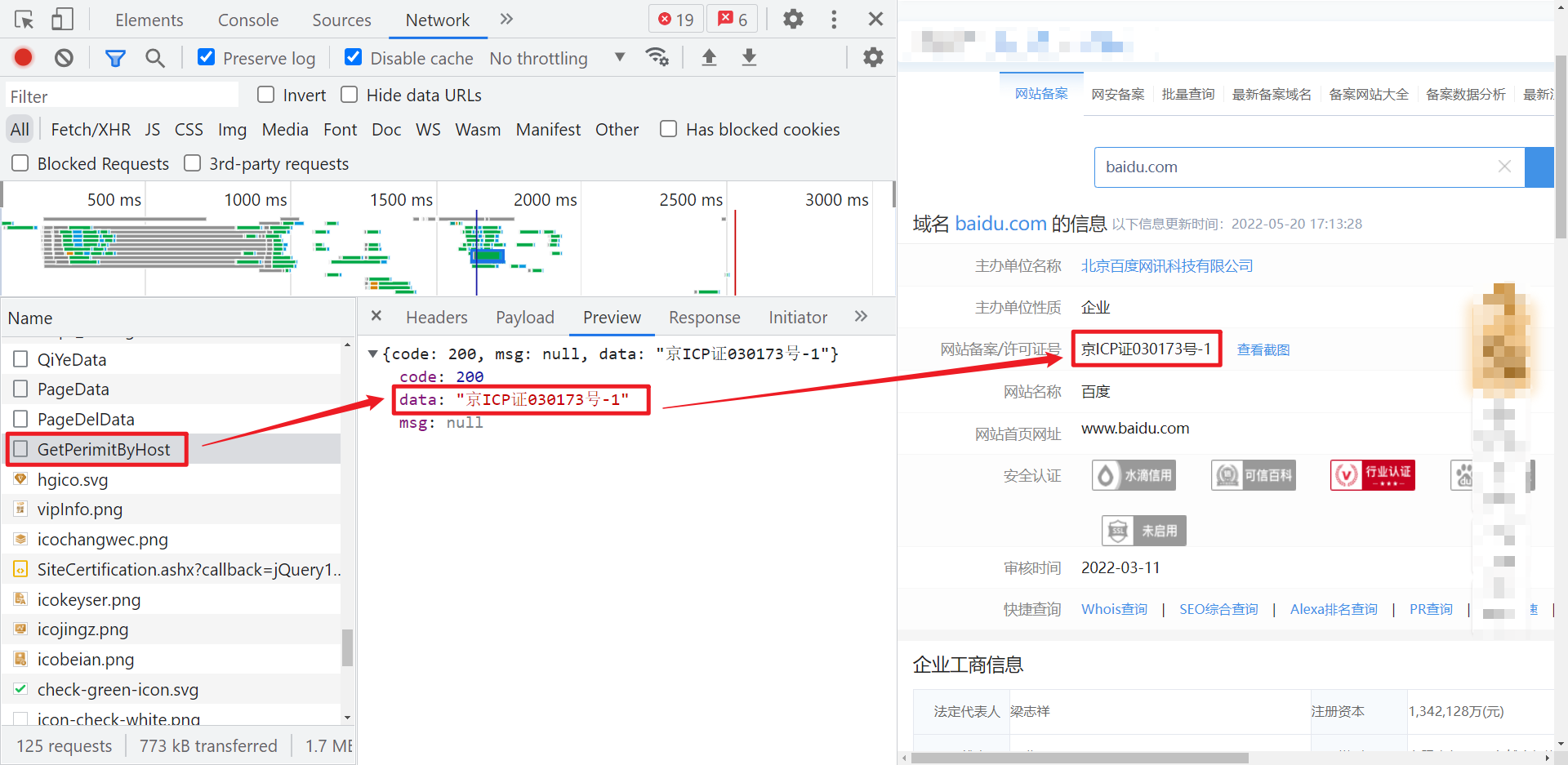
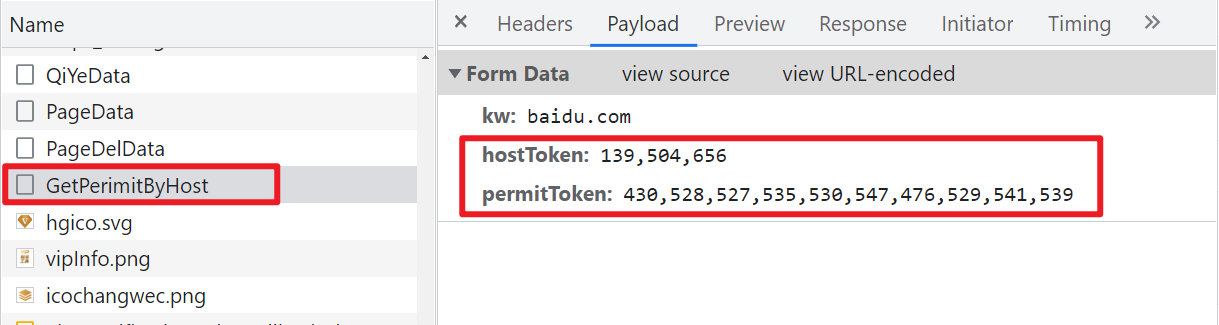
直接搜索关键字 hostToken 或者 permitToken 即可定位:
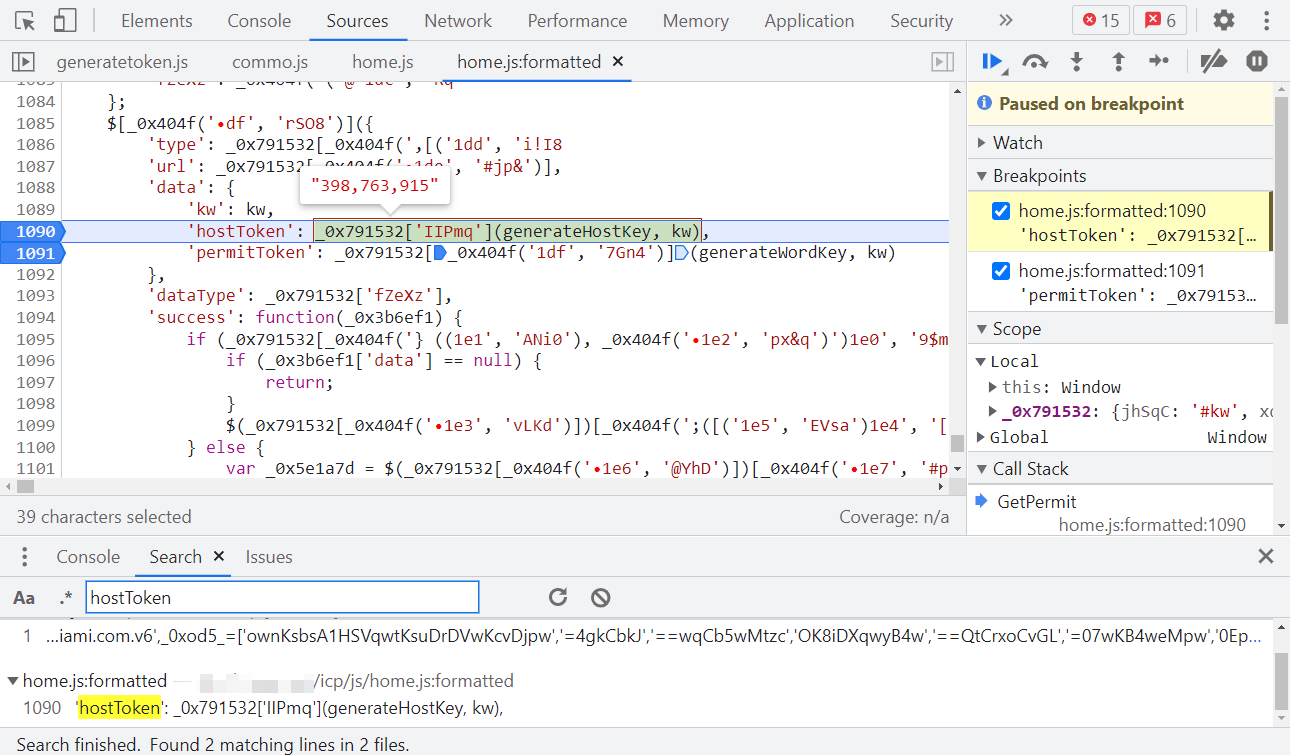
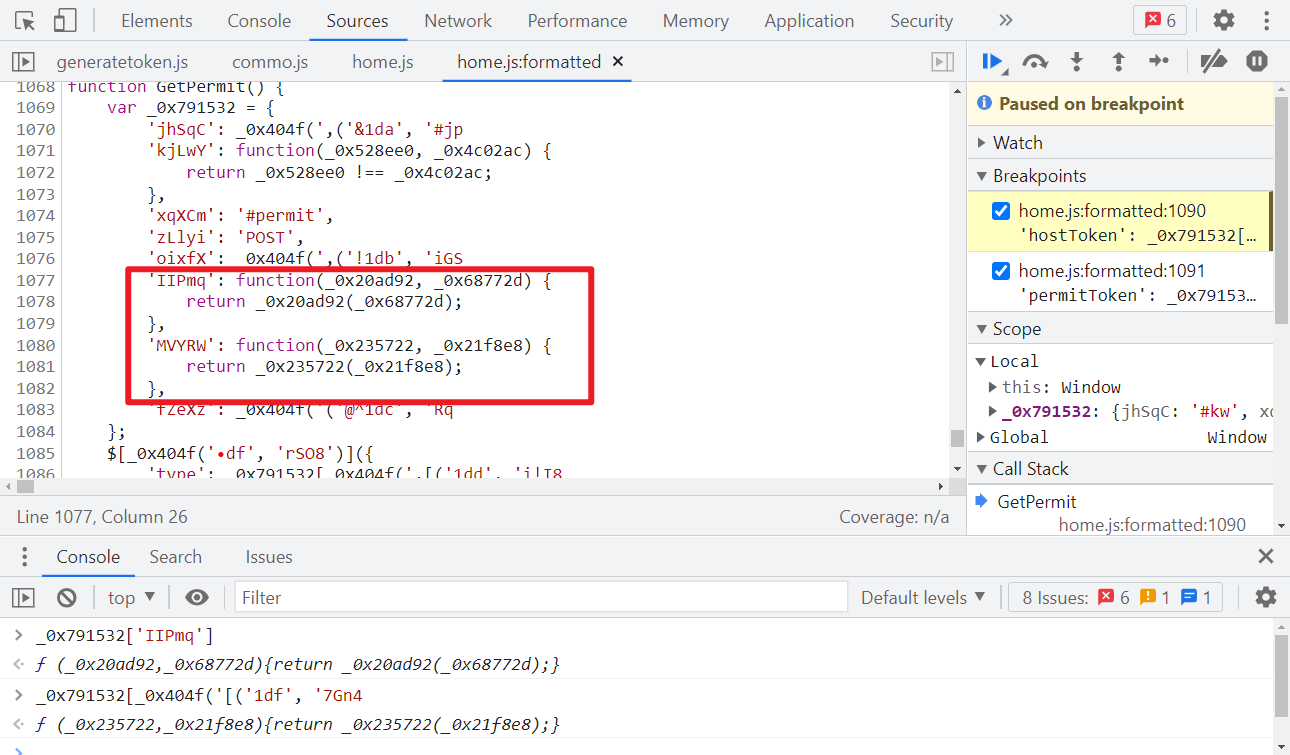
关键代码:
'data': {
'kw': kw,
'hostToken': _0x791532['IIPmq'](generateHostKey, kw),
'permitToken': _0x791532[_0x404f('1df', '7Gn4')](generateWordKey, kw)
}
这里的混淆可以手动跟一下,还原后如下:
'data': {
'kw': kw,
'hostToken': generateHostKey(kw),
'permitToken': generateWordKey(kw)
}
kw 是查询的域名,有用的就是 generateHostKey() 和 generateWordKey() 两个方法了,跟进去看,代码经过了 jsjiami v6 混淆:
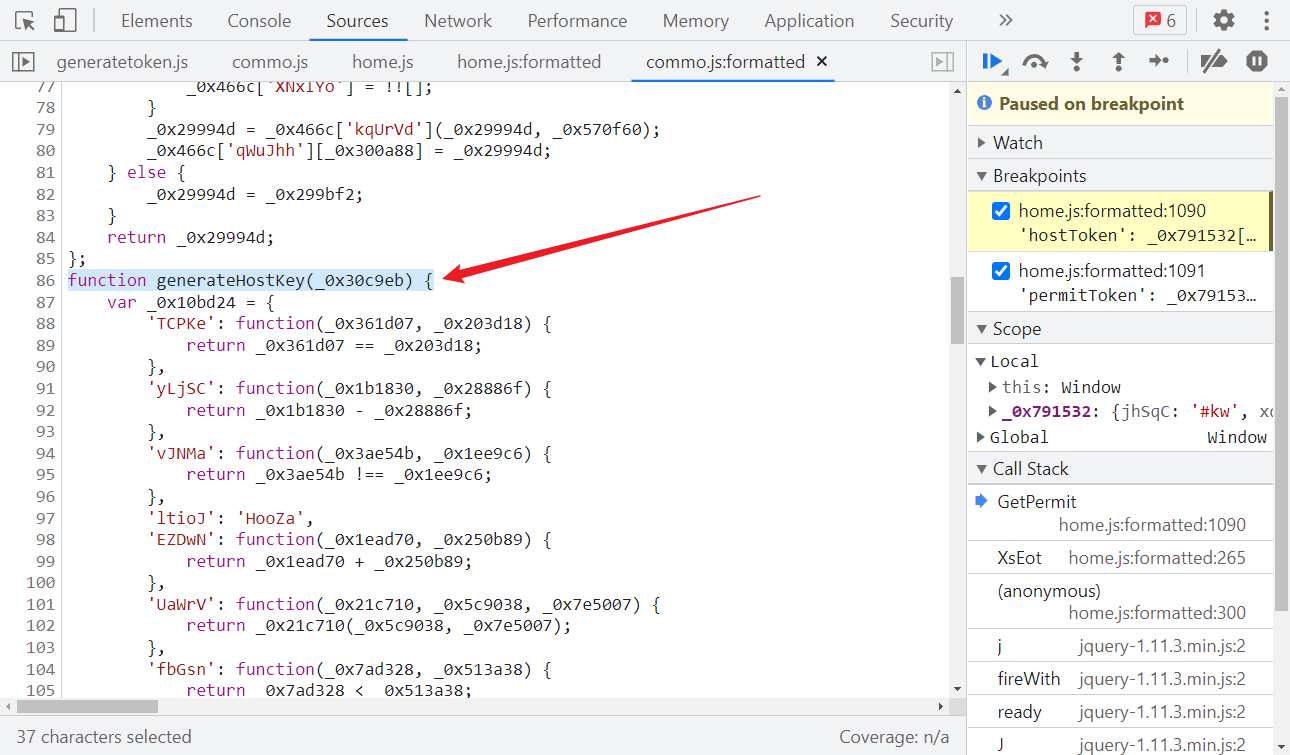
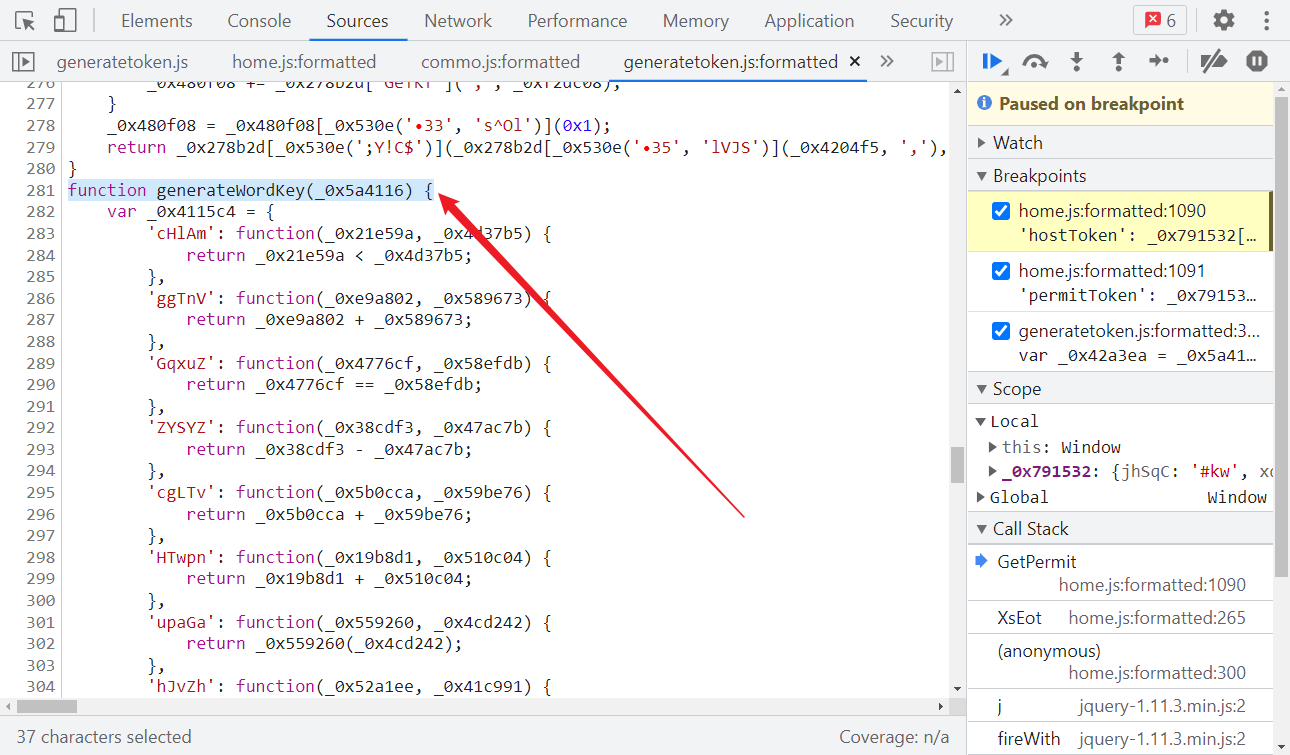
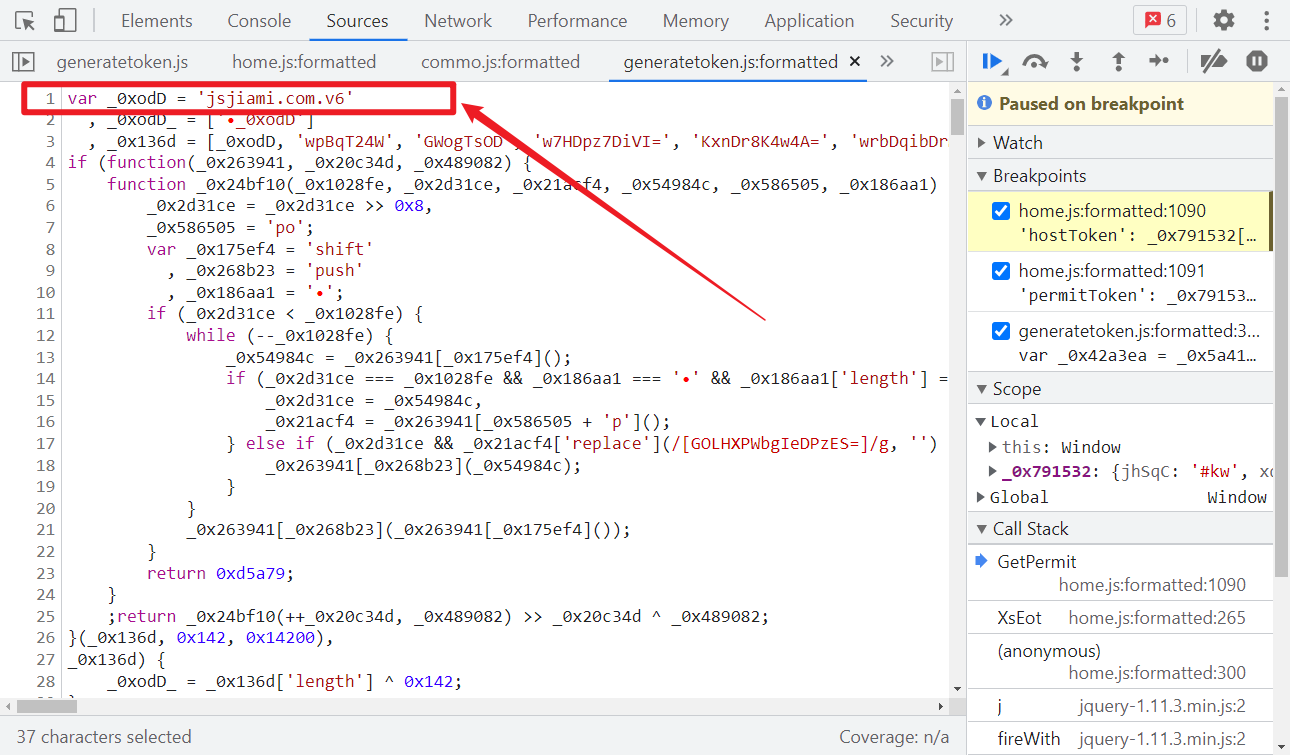
jsjiami 混淆的特征其实和 OB 混淆是类似的:
- 一般由一个大数组或者含有大数组的函数、一个数组位移操作的自执行函数、一个解密函数和加密后的函数四部分组成;
- 函数名和变量名通常以 _0x 或者 0x 开头,后接 1~6 位数字或字母组合;
- 数组位移操作的自执行函数里,有明显的 push、shift 关键字。
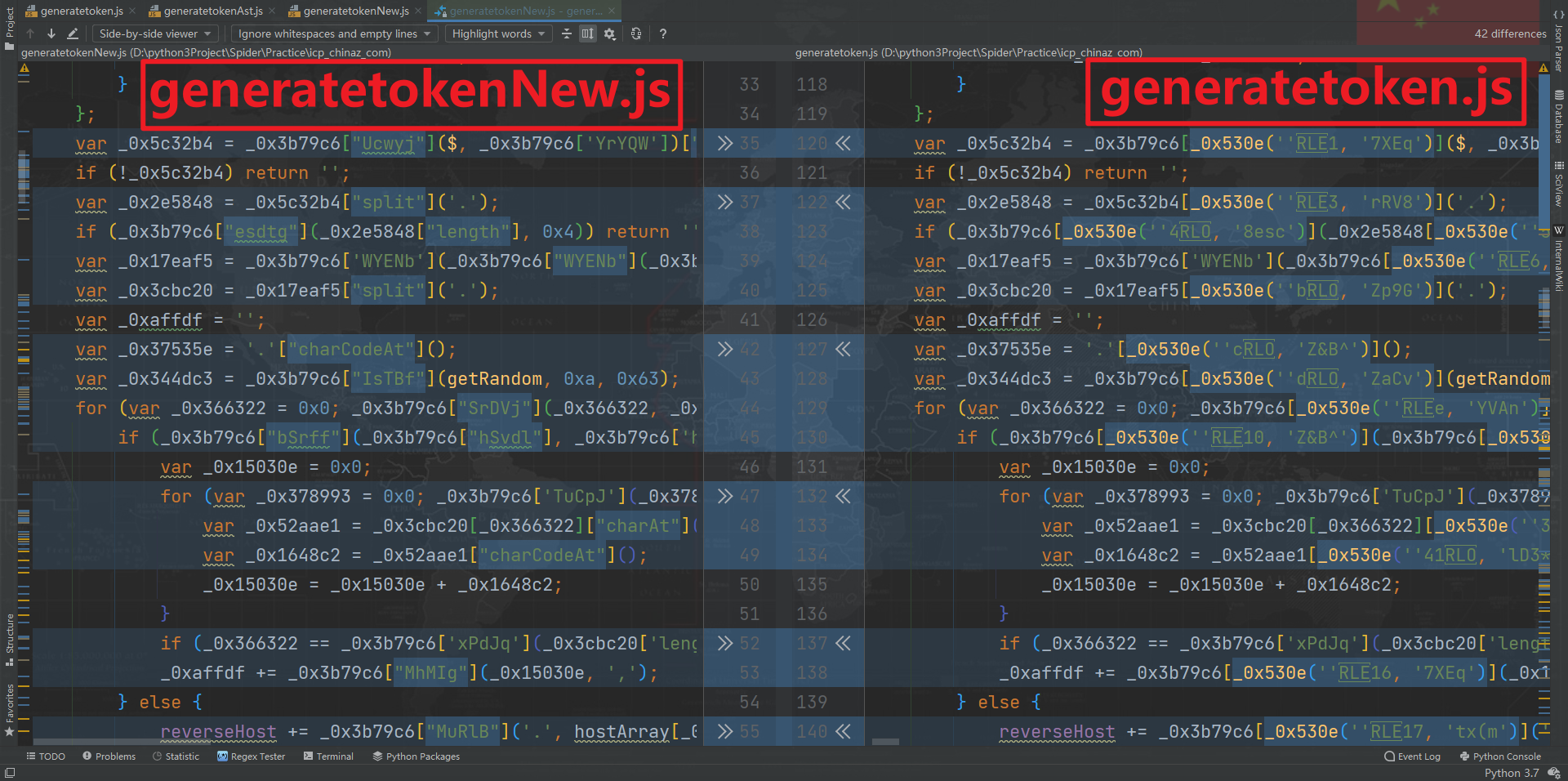
本例中,generateHostKey() 方法在 commo.js 里,generateWordKey() 方法在 generatetoken.js 里,结构如下图所示:
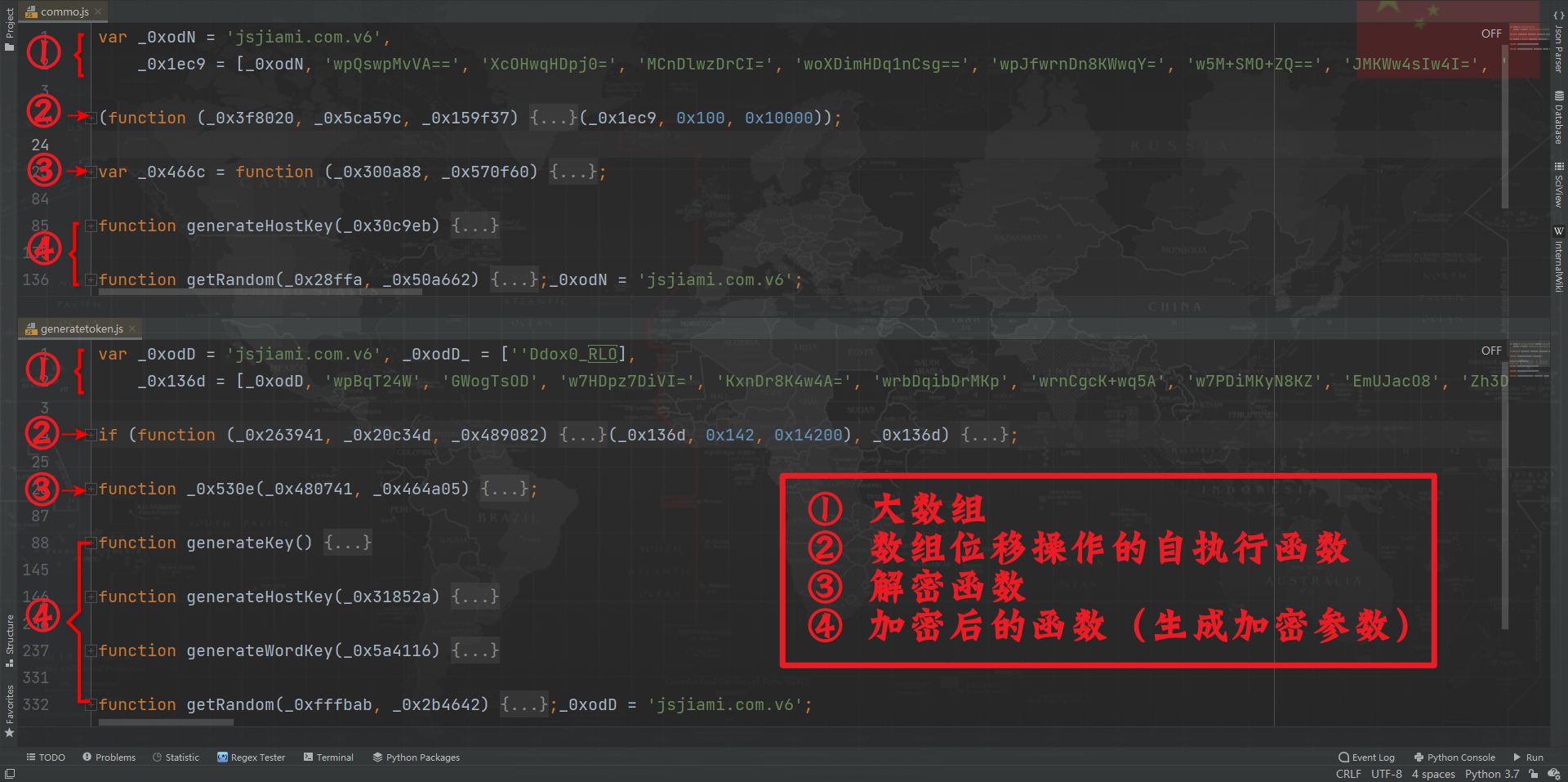
观察 generatetoken.js 文件,可以发现这里面也有 commo.js 里面的 generateHostKey() 和 getRandom() 方法,从方法名来看貌似是重复了,实际上混淆还原后方法是一样的,所以这里我们只需要还原 generatetoken.js 就可以了。
- 混淆 JS 文件:
generatetoken.js - AST 还原代码:
generatetokenAst.js - 还原后的代码:
generatetokenNew.js
在原来混淆后的 JS 里,解密函数是 _0x530e,首先观察整个 JS,调用了很多次解密函数,类似于:_0x530e('1', '7XEq')。
注意这里代码里面有一些特殊字符,类似于 RLE、RLO 之类的,如果在 VSCode 打开是一些 U+202B、U+202E 的字符,实际上这是 RTLO (Right-to-Left Override) 字符,U+202B 和 U+202E 的意思分别是根据内存顺序从左至右和从右至左显示字符,感兴趣的可以网上搜索了解一下。这里并不影响我们进行还原操作。但是如果直接复制过来的话就会导致前后文显示的顺序不对,所以本文中为了方便描述,粘贴的部分代码就手动去掉了这些字符。
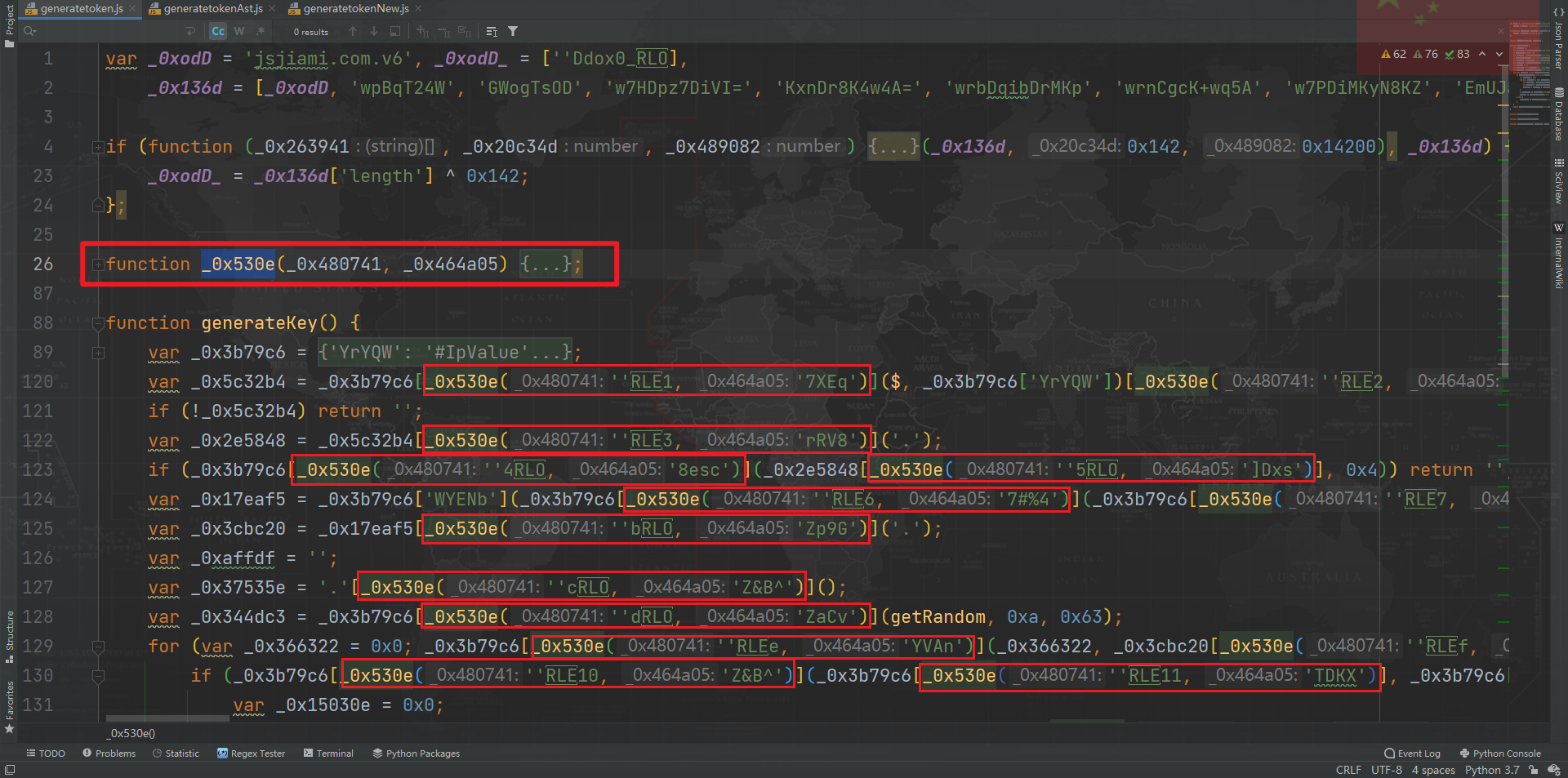
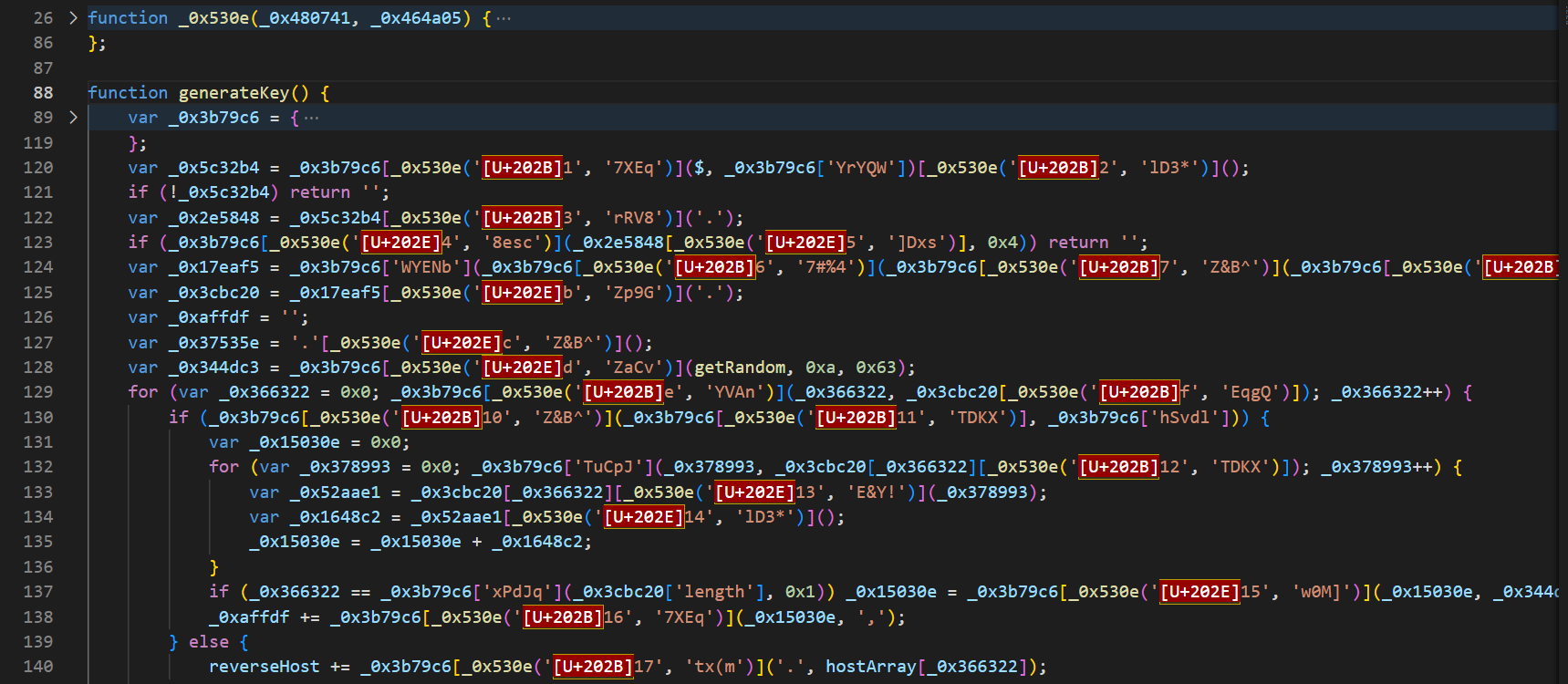
所以第一步我们要还原一下解密函数,把所有 _0x530e 调用的地方直接替换成实际值,首先需要将大数组、自执行函数、加密函数和解密函数分割开,将代码放到 astexplorer.net 看一下,也就是将 body 的前四部分和后面剩余部分分割开来,如下图所示:
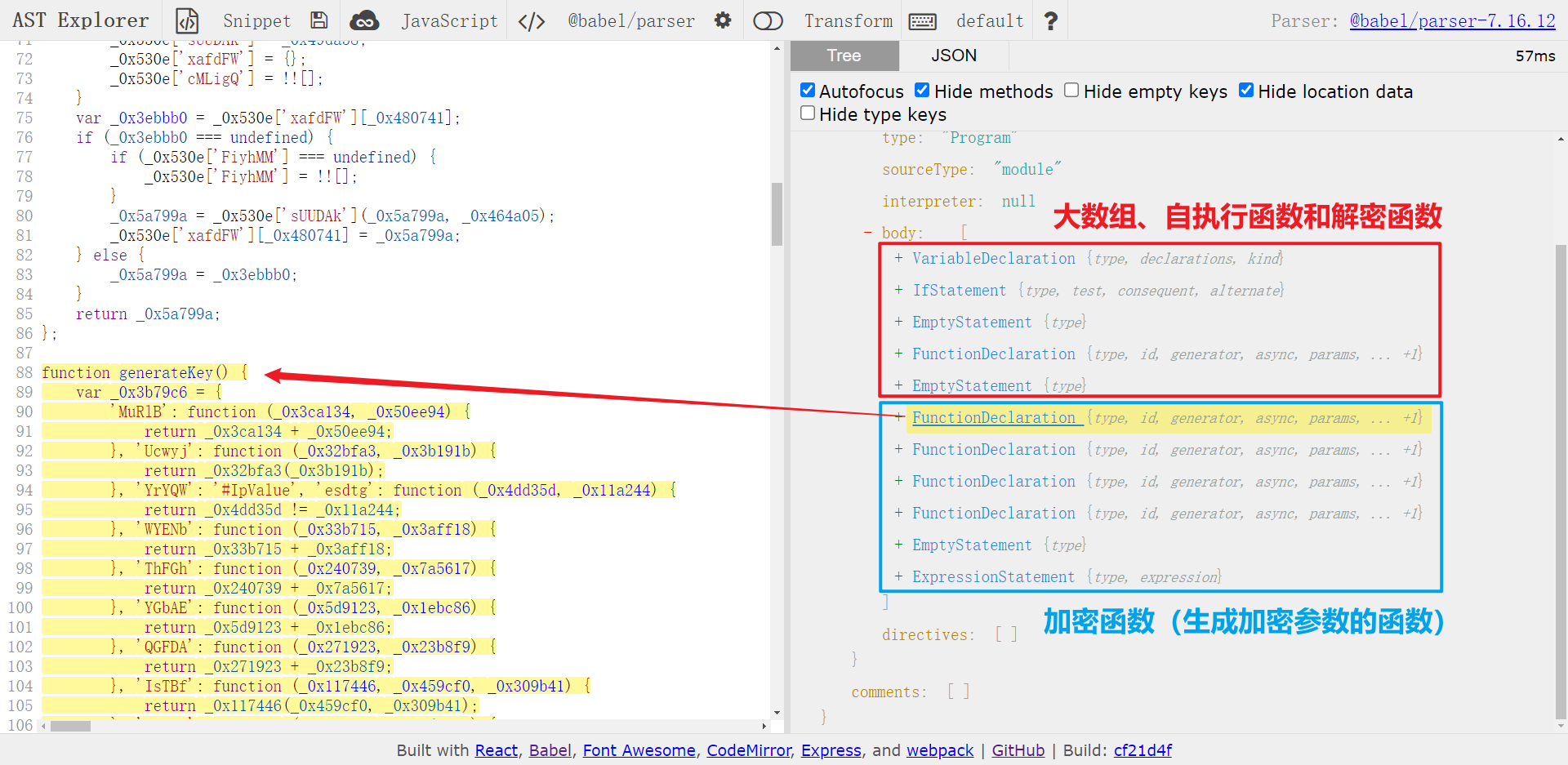
分割代码:
const fs = require("fs");
const parse = require("@babel/parser").parse;
const generate = require("@babel/generator").default
const traverse = require("@babel/traverse").default
const types = require("@babel/types")
// 导入混淆代码并解析为 AST
const oldCode = fs.readFileSync("generatetoken.js", {encoding: "utf-8"});
const astCode = parse(oldCode);
// 获取整个 AST 节点的长度
let astCodeLength = astCode.program.body.length
// 获取解密函数的名字 也就是 _0x530e
let decryptFunctionName = astCode.program.body[3].id.name
// 分割加密函数和解密函数,即 body 的前四部分和后面剩余部分
let decryptFunction = astCode.program.body.slice(0, 4)
let encryptFunction = astCode.program.body.slice(4, astCodeLength)
// 获取加密函数和解密函数的方法多种多样,比如可以挨个取值并转换成 JS 代码
// 这样做就不需要将解密函数赋值给整个 AST 节点了
// let decryptFunction = "";
// for(let i=0; i<4; i++){
// decryptFunction += generate(astCode.program.body[i], {compact: true}).code
// }
// eval(decryptFunction);
在上面的获取加密函数和解密函数的代码中,方法不是唯一的,多种多样,比如直接循环取 body 并转换成 JS 代码,比如直接人工把大数组、自执行函数和解密函数三部分,拿出来放到一个新文件里,然后导出解密方法,后续直接调用也可以。
在本例中,拿到解密函数后,需要将其赋值给整个 AST 节点,然后再将整个 AST 节点转换成 JavaScript 代码,这里注意有可能会检测代码是否格式化,所以建议转换要加一个 compact 参数,避免格式化,转换完成后 eval 执行一下,让数组位移操作完成,然后我们就可以直接调用解密函数,即 _0x530e()。
// 将解密函数赋值给整个 AST 节点
astCode.program.body = decryptFunction
// 将 AST 节点转换成 JS 代码,并 eval 执行一下
decryptFunction = generate(astCode, {compact: true}).code
eval(decryptFunction);
// 测试一下,直接调用 _0x530e 函数可以正确拿到结果
// 输出 split
// console.log(_0x530e('b', 'Zp9G'))
现在我们能直接调用解密函数 _0x530e() 了,接下来要做的就是怎么把混淆代码中所有调用 _0x530e() 的地方替换成真实值,在此之前,我们要把加密函数(generateKey()、generateHostKey()、generateWordKey() 和 getRandom())赋值给整个 AST 节点,此时整个节点就没有大数组、自执行函数和解密函数了,解密函数 _0x530e() 已经被写入内存,所以后面不影响我们调用。
老样子,还是先在 astexplorer.net 看一下调用 _0x530e() 的地方,以 _0x530e('b', 'Zp9G') 为例,其真实值应该是 split,对比一下替换前后的结构,如下图所示:
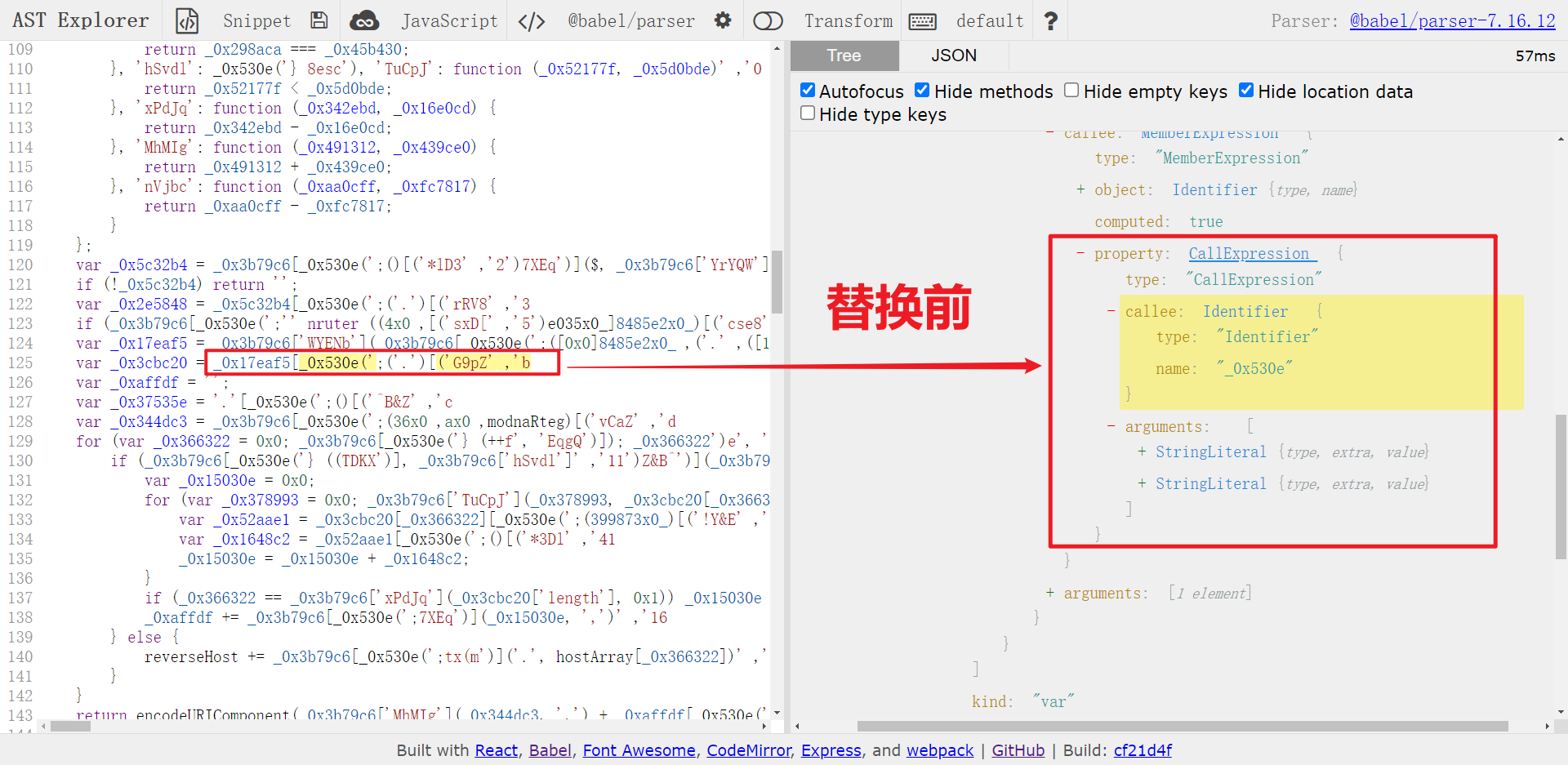
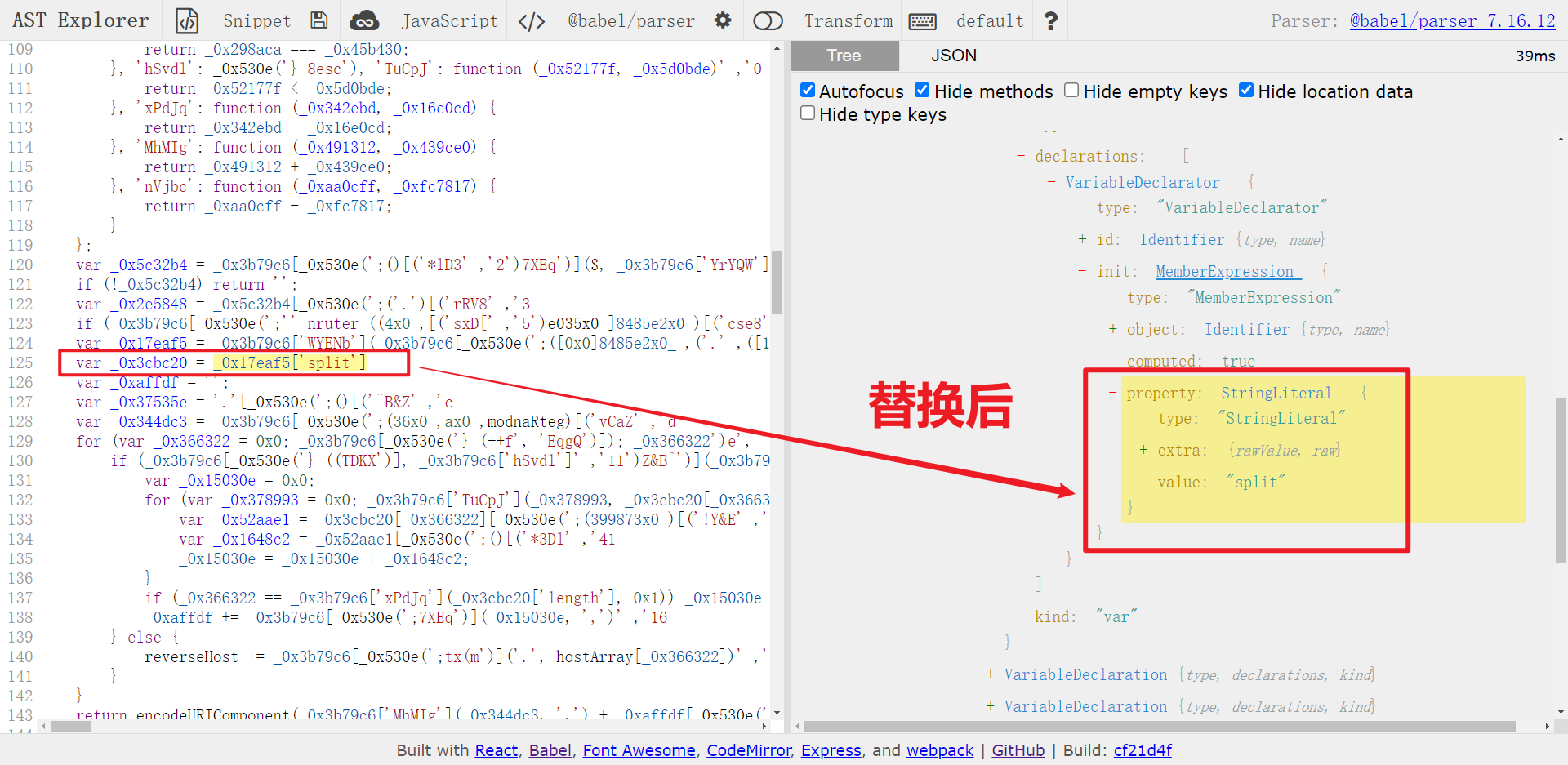
可以看到节点由原来的 CallExpression 变成了 StringLiteral,所以我们可以遍历 CallExpression,如果函数名为解密函数名,那就通过 path.toString() 方法获取节点源码,也就类似 _0x530e('b', 'Zp9G') 的源码,然后 eval 执行一下获取其真实值,再使用 types.stringLiteral() 构建 StringLiteral 节点,最后通过 path.replaceInline() 方法替换节点,遍历代码如下:
// 将加密函数赋值给整个 AST 节点,此时整个节点就没有大数组、自执行函数和解密函数了
astCode.program.body = encryptFunction
// 调用解密函数,直接计算出类似以下方法的值并替换
// 混淆代码:_0x530e('b', 'Zp9G')
// 还原后:split
const visitor1 = {
CallExpression(path){
if (path.node.callee.name === decryptFunctionName && path.node.arguments.length === 2){
path.replaceInline(types.stringLiteral(eval(path.toString())))
}
}
}
// 遍历节点
traverse(astCode, visitor1)
// 将 AST 节点转换成 JS 代码并写入到新文件里
const result = generate(astCode, {concise:true}).code
fs.writeFile("./generatetokenNew.js", result, (err => {console.log(err)}))
自此,第一步的解密函数还原就完成了,可以看一下还原前后的对比,如下图所示浅蓝色标记的地方,所有调用 _0x530e() 的地方都被还原了:
初步还原后我们的代码里就只剩下以下四个方法:
generateKey()generateHostKey()generateWordKey()getRandom()
再观察代码,发现每个方法一开始都有个大的对象,他们分别是:
_0x3b79c6_0x278b2d_0x4115c4_0xd8ec33
后续的代码也在不断调用这个对象的方法,比如 _0x3b79c6["esdtg"](_0x2e5848["length"], 0x4) 实际上就是 _0x2e5848["length"] != 0x4,如下图所示:
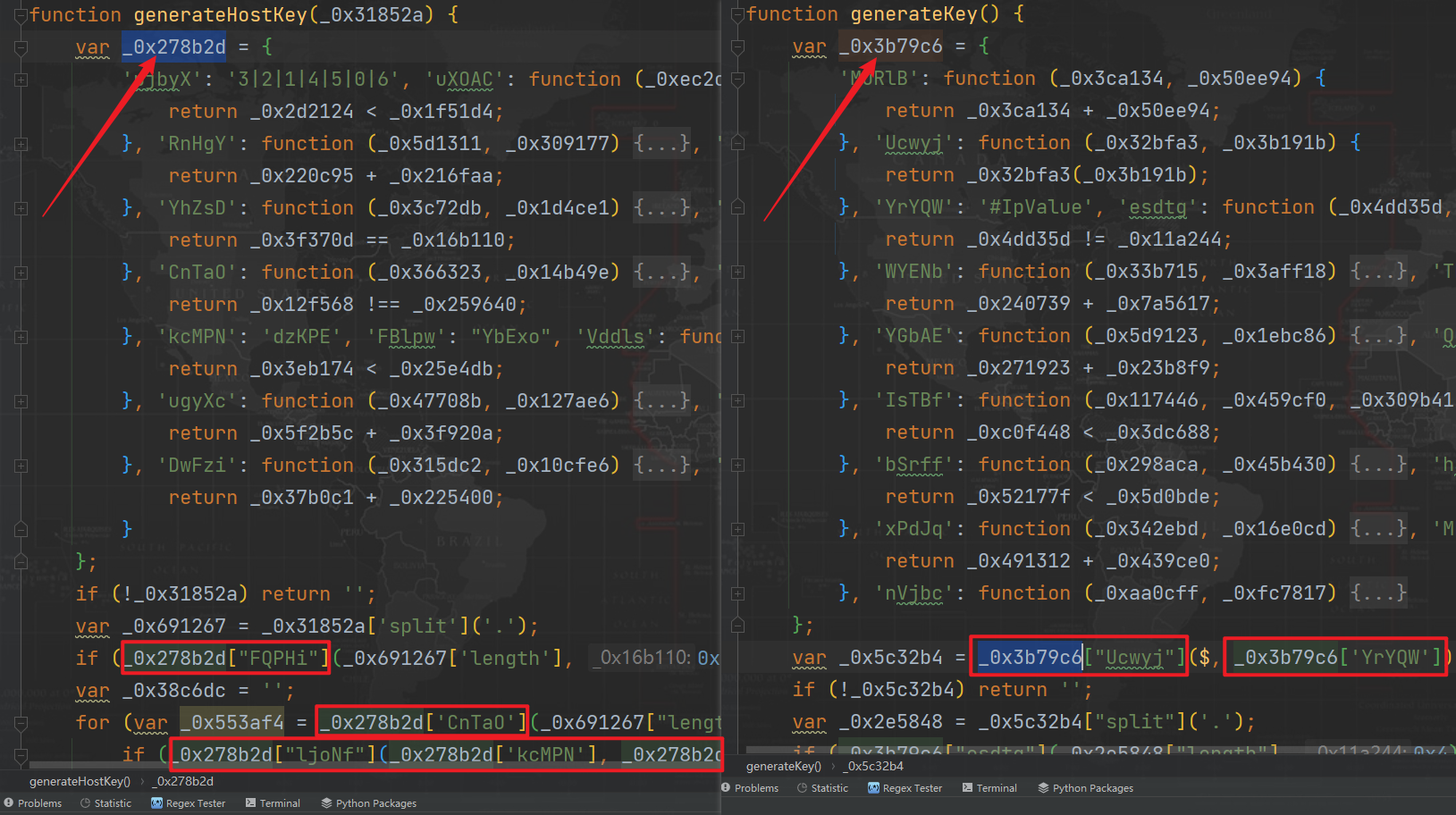
首先我们将这四个大的对象单独提取出来,还是保持原来的键值对样式,提取完成后删除这两个节点,遍历代码如下:
let functionName = {
"_0x3b79c6": {},
"_0x278b2d": {},
"_0x4115c4": {},
"_0xd8ec33": {}
}
// 单独提取出四个大对象
const visitor2 = {
VariableDeclarator(path){
for (let key in functionName){
if (path.node && path.node.id.name == key) {
const properties = path.node.init.properties
for (let i=0; i<properties.length; i++){
functionName[key][properties[i].key.value] = properties[i].value
}
// 写入对象后就可以删除该节点了
path.remove()
}
}
}
}
这里要注意,大的对象里面,有 +、-、== 之类的二项式计算,也有直接为字符串的,还有变成函数调用的,如下所示:
var _0x3b79c6 = {
'MuRlB': function (_0x3ca134, _0x50ee94) {
return _0x3ca134 + _0x50ee94;
},
'Ucwyj': function (_0x32bfa3, _0x3b191b) {
return _0x32bfa3(_0x3b191b);
},
'YrYQW': '#IpValue'
}
针对不同的情况有不同的处理方法,同时还要注意传参和 return 返回的参数位置,不要还原后把 a - b 搞成 b - a 了,当然在本例中传入和返回的顺序是一样的,就不需要考虑这个问题。
首先来看字符串,有以下几种情况:
- 以
_0x3b79c6['YrYQW']为例,实际上其值为字符串'#IpValue',观察其结构,是一个MemberExpression,在一个列表里; - 以
_0x278b2d['pjbyX']为例,实际上其值为字符串'3|2|1|4|5|0|6',观察其结构,是一个MemberExpression,在一个字典里; - 以
_0x278b2d['CnTaO']为例,虽然也是一个MemberExpression,也在一个字典里。但实际上是二项式计算,所以要排除在外。
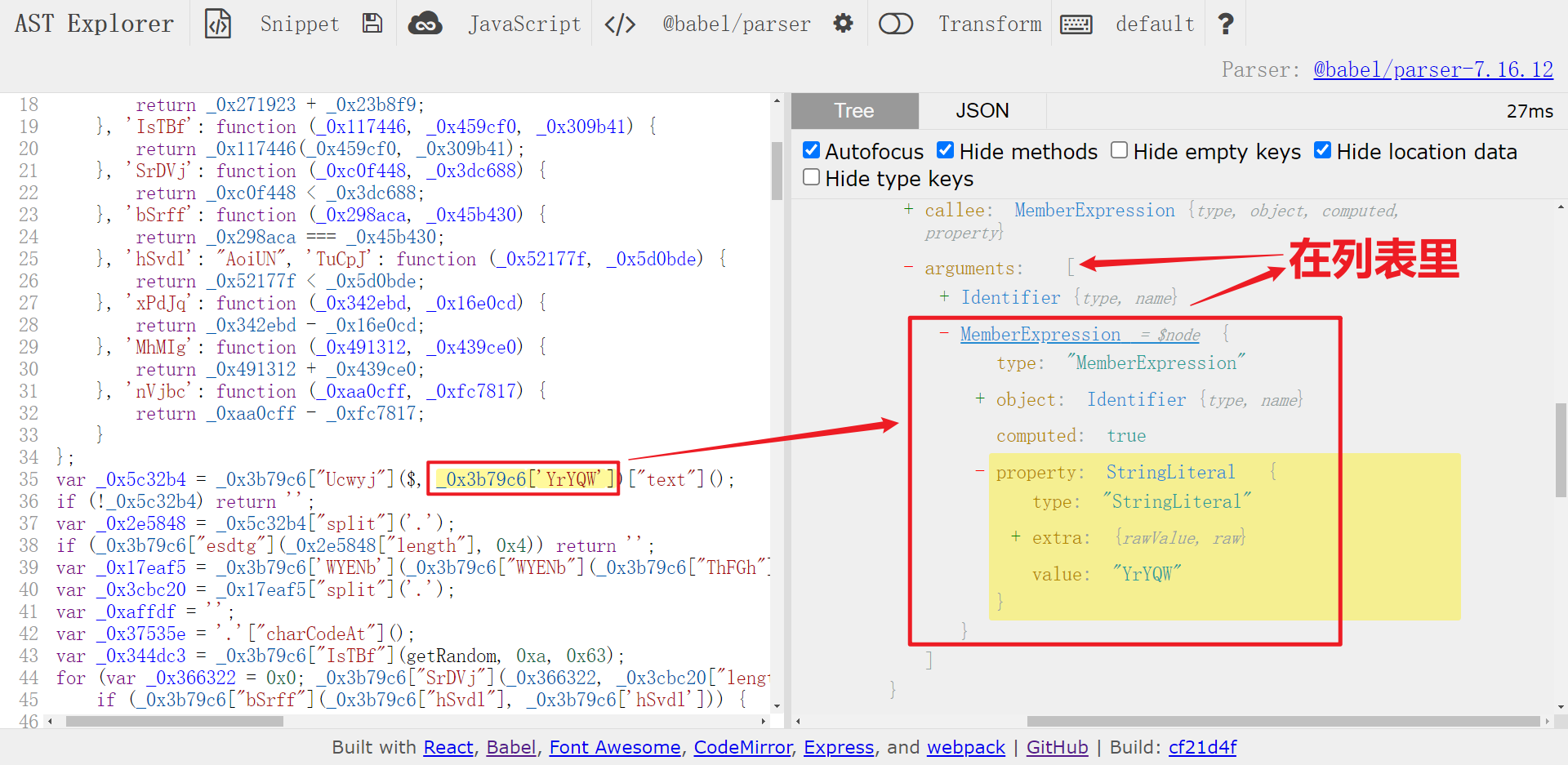
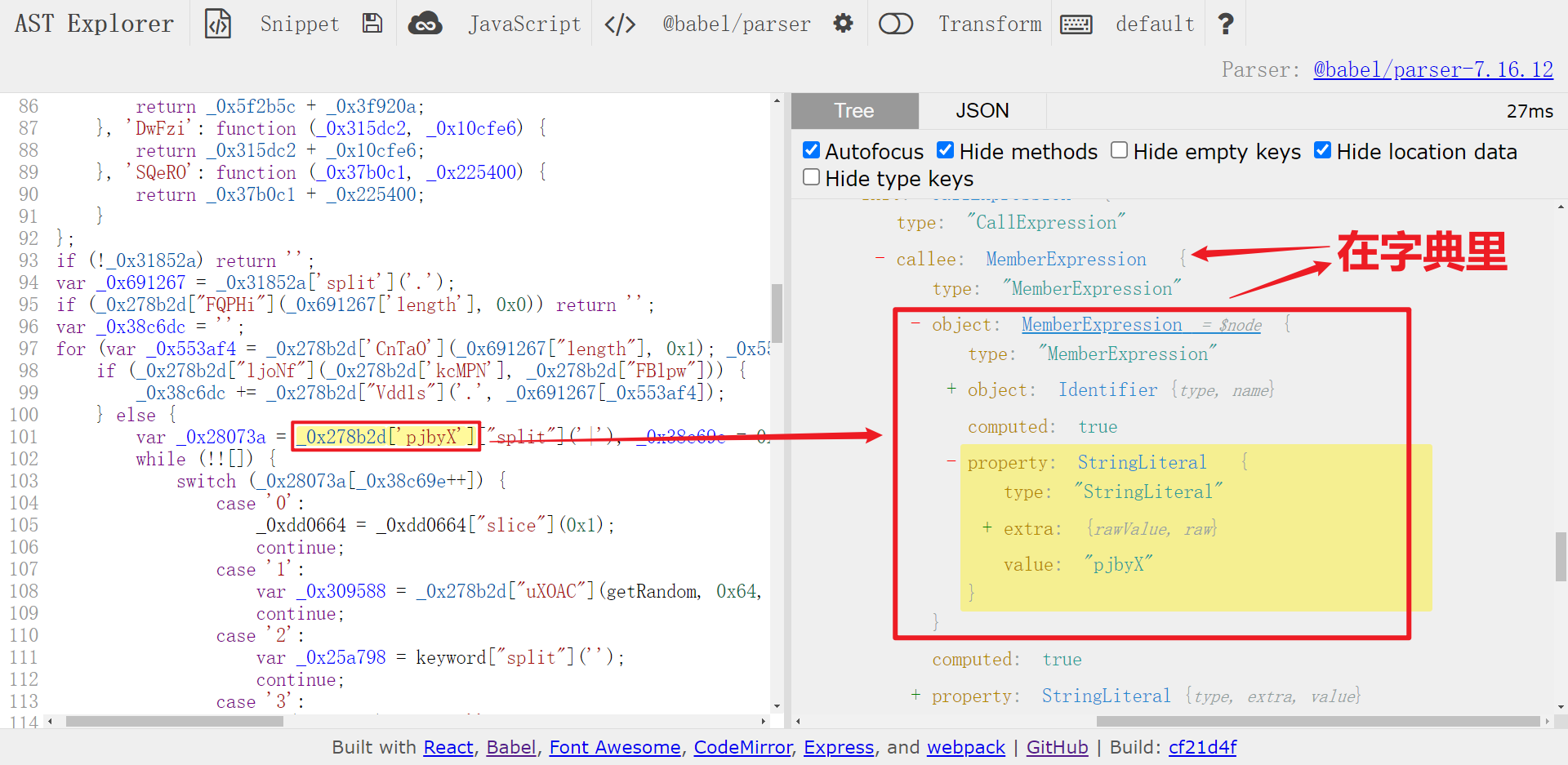
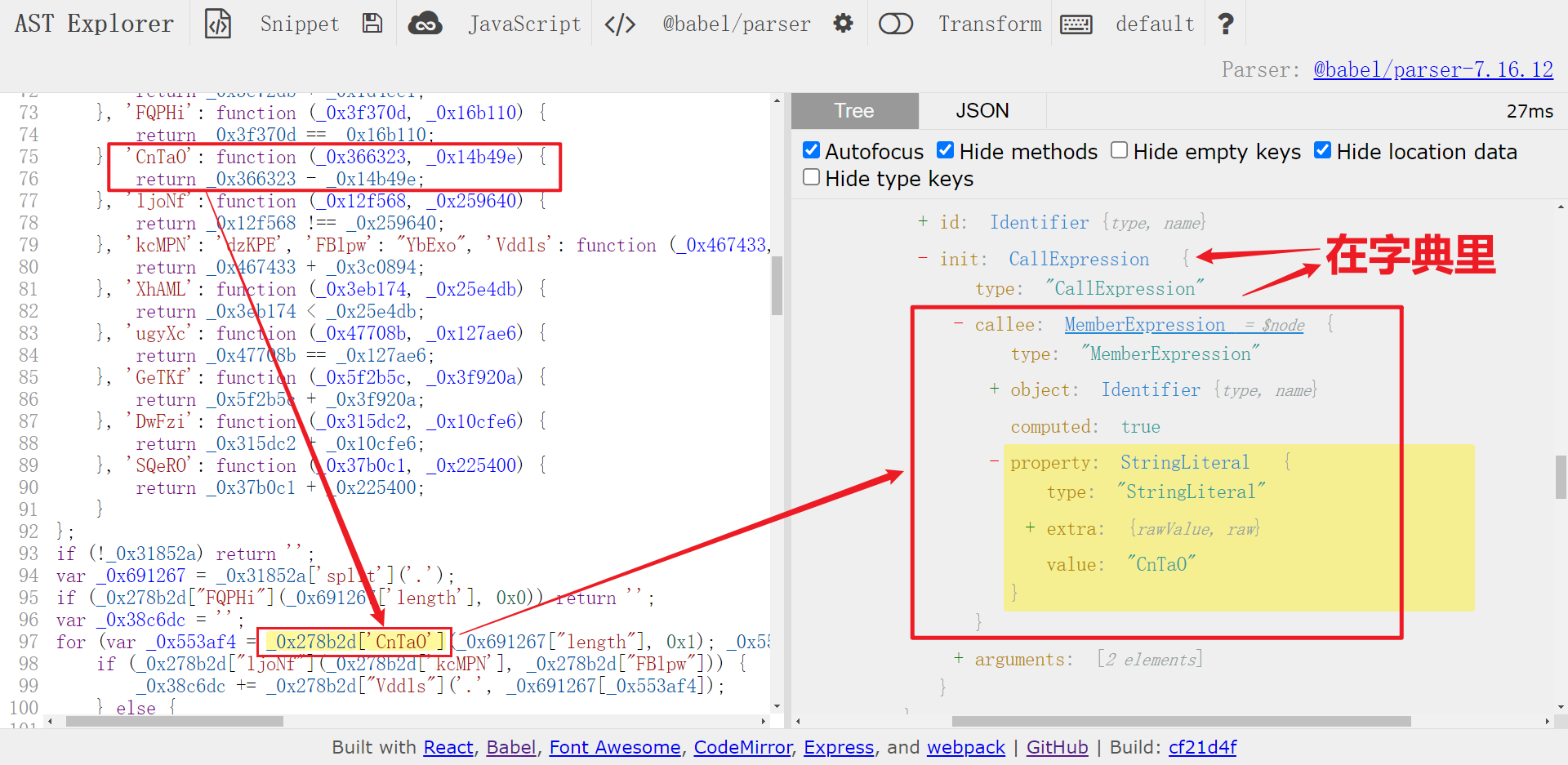
所以我们在写遍历代码时,同时要注意这三种情况,满足条件后直接取原来大对象对应的节点进行替换即可,遍历代码如下所示:
// 函数替换,字符串替换:将类似 _0x3b79c6['YrYQW'] 变成 '#IpValue'
const visitor3 = {
MemberExpression(path) {
for (let key in functionName){
if (path.node.object && path.node.object.name == key && path.inList ) {
path.replaceInline(functionName[key][path.node.property.value])
}
if (path.node.object && path.node.object.name == key && path.parent.property && path.parent.property.value == "split") {
path.replaceInline(functionName[key][path.node.property.value])
}
}
}
}
再来看看二项式计算的情况,以 _0x278b2d['CnTaO'](_0x691267["length"], 0x1) 为例,实际上是做减法运算,即 _0x691267["length"] - 0x1,看一下替换前后对比:
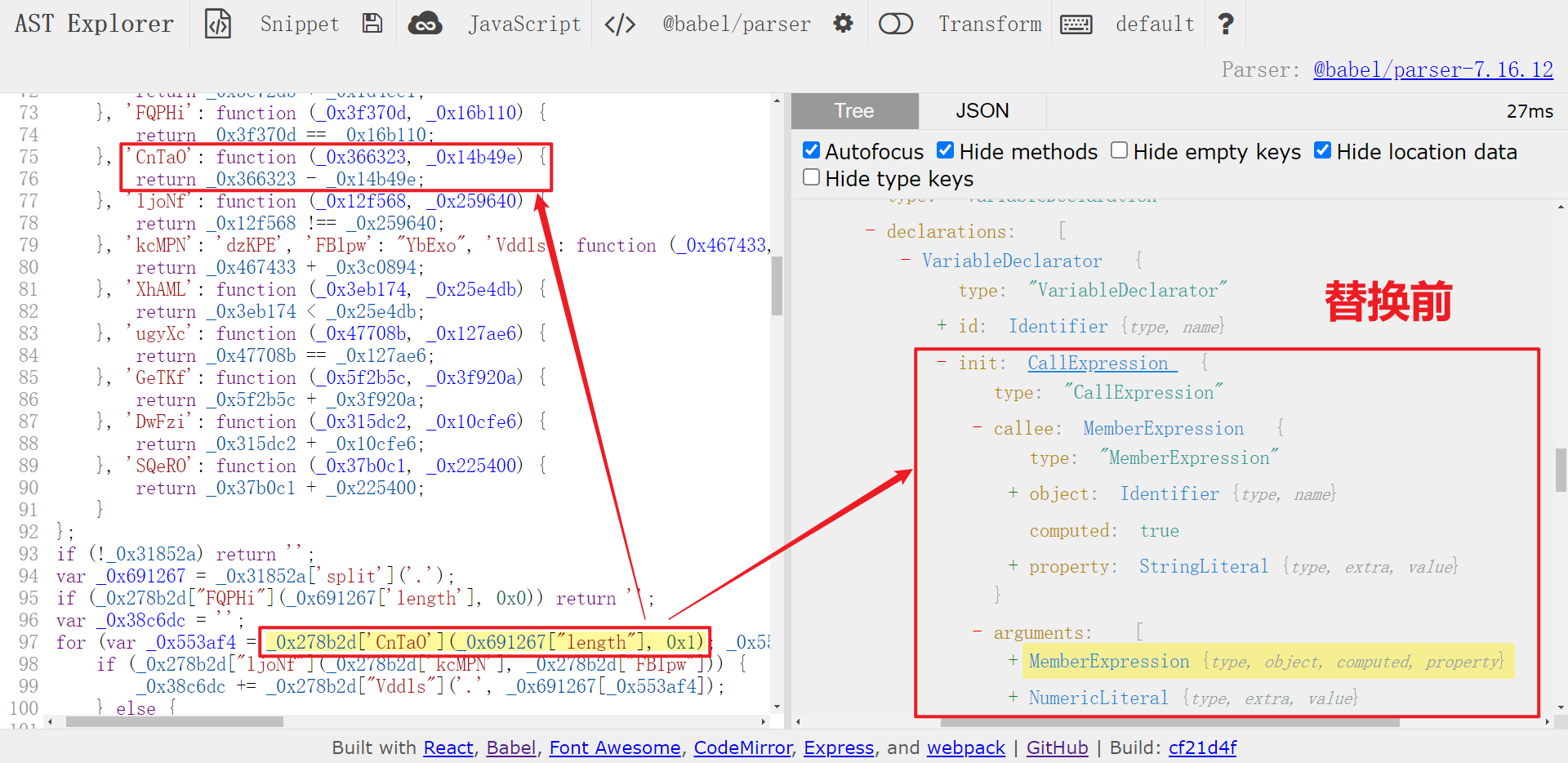
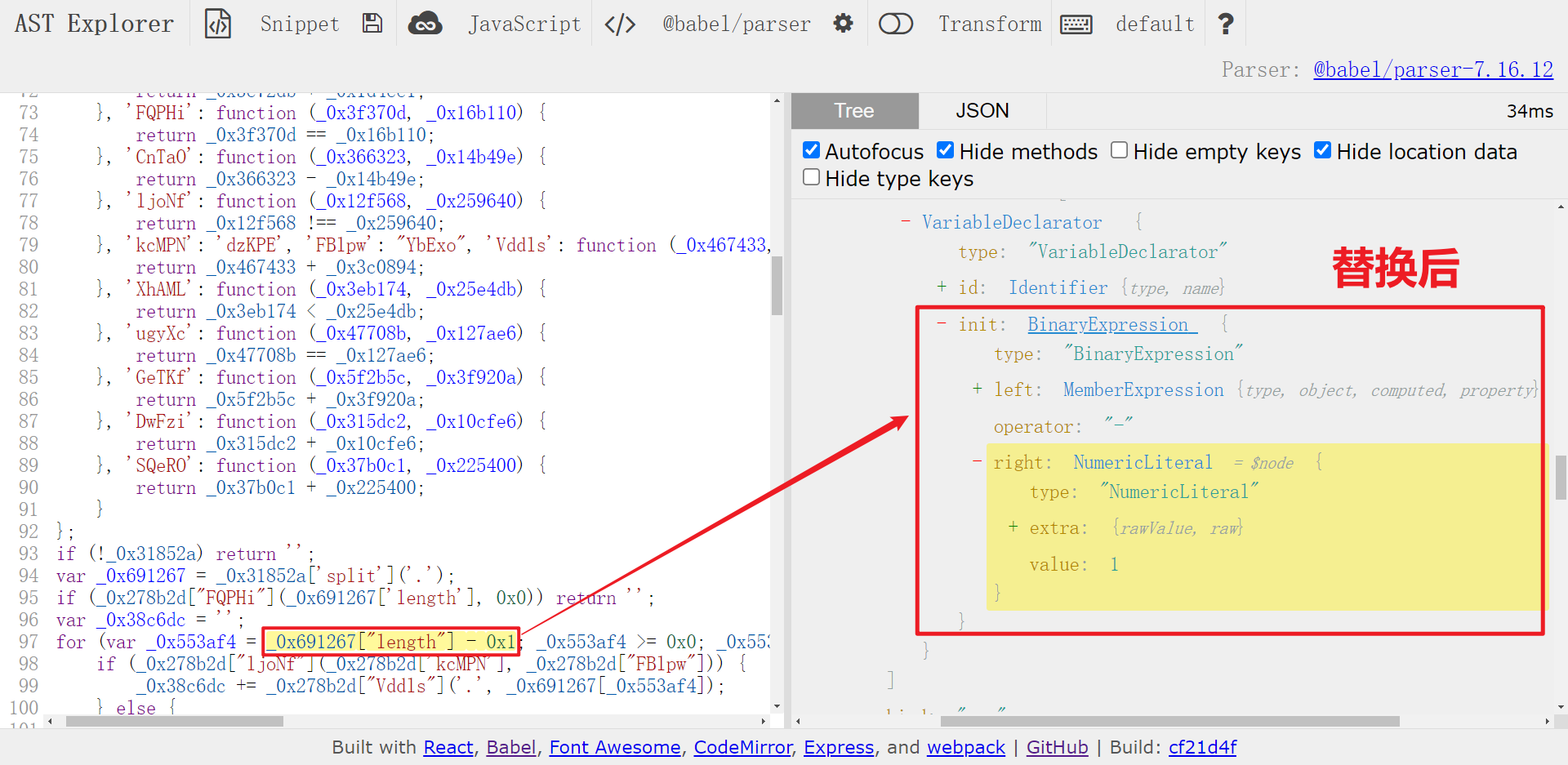
对于这种情况,我们可以直接提取两个参数,然后提取大对象里对应方法的操作符,然后将参数和操作符直接连接起来组成新的节点(binaryExpression)并替换即可,遍历代码如下:
// 函数替换,二项式计算:将类似 _0x278b2d['CnTaO'](_0x691267["length"], 0x1) 变成 _0x691267["length"] - 0x1
const visitor4 = {
CallExpression(path){
for (let key in functionName) {
if (path.node.callee && path.node.callee.object && path.node.callee.object.name == key) {
let func = functionName[key][path.node.callee.property.value]
if (func.body.body[0].argument.type == "BinaryExpression") {
let operator = func.body.body[0].argument.operator
let left = path.node.arguments[0]
let right = path.node.arguments[1]
path.replaceInline(types.binaryExpression(operator, left, right))
}
}
}
}
}
以 _0x4115c4["PJbSm"](getRandom, 0x64, 0x3e7) 为例,实际上是 getRandom(0x64, 0x3e7),看一下替换前后对比:
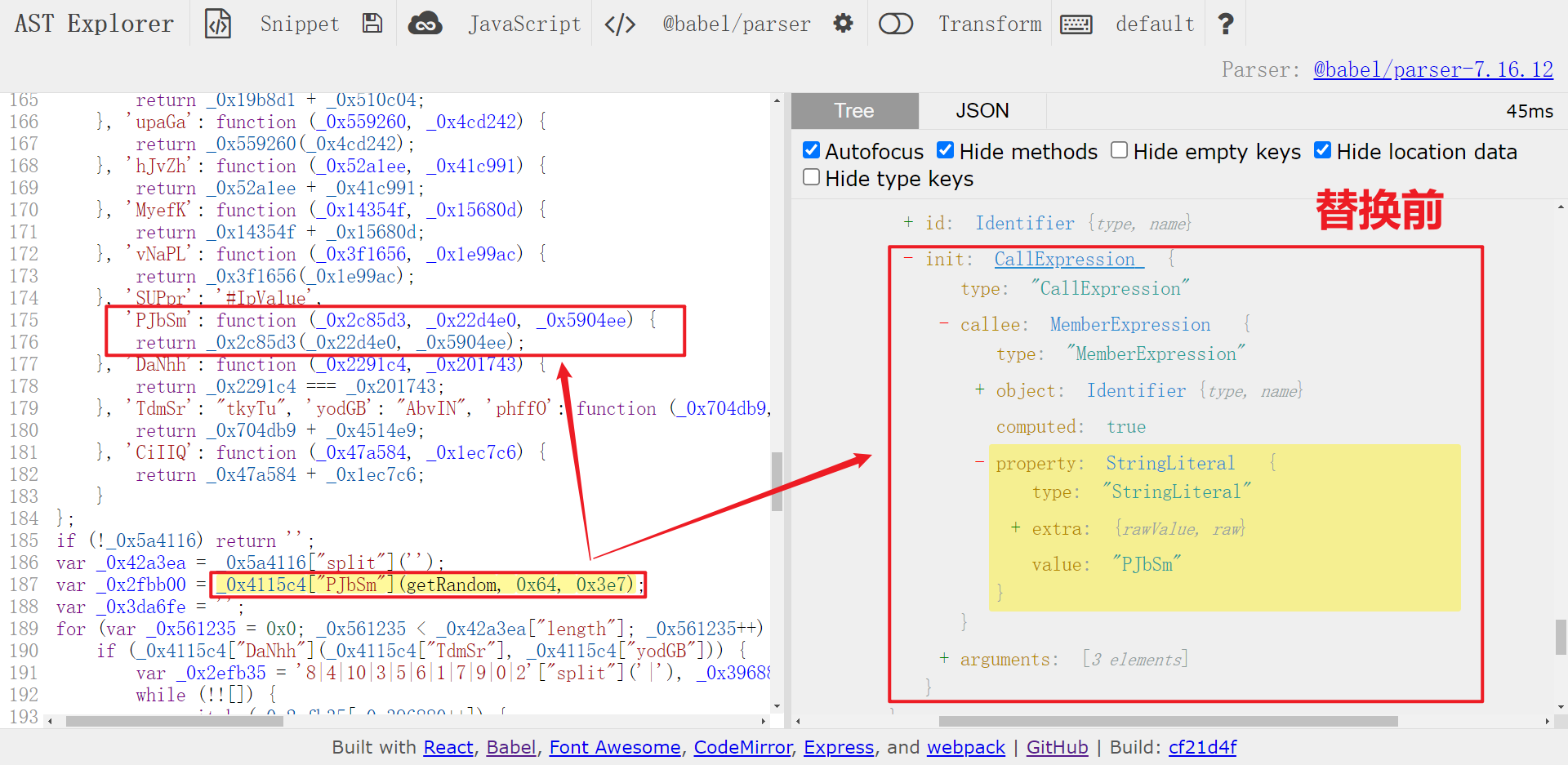
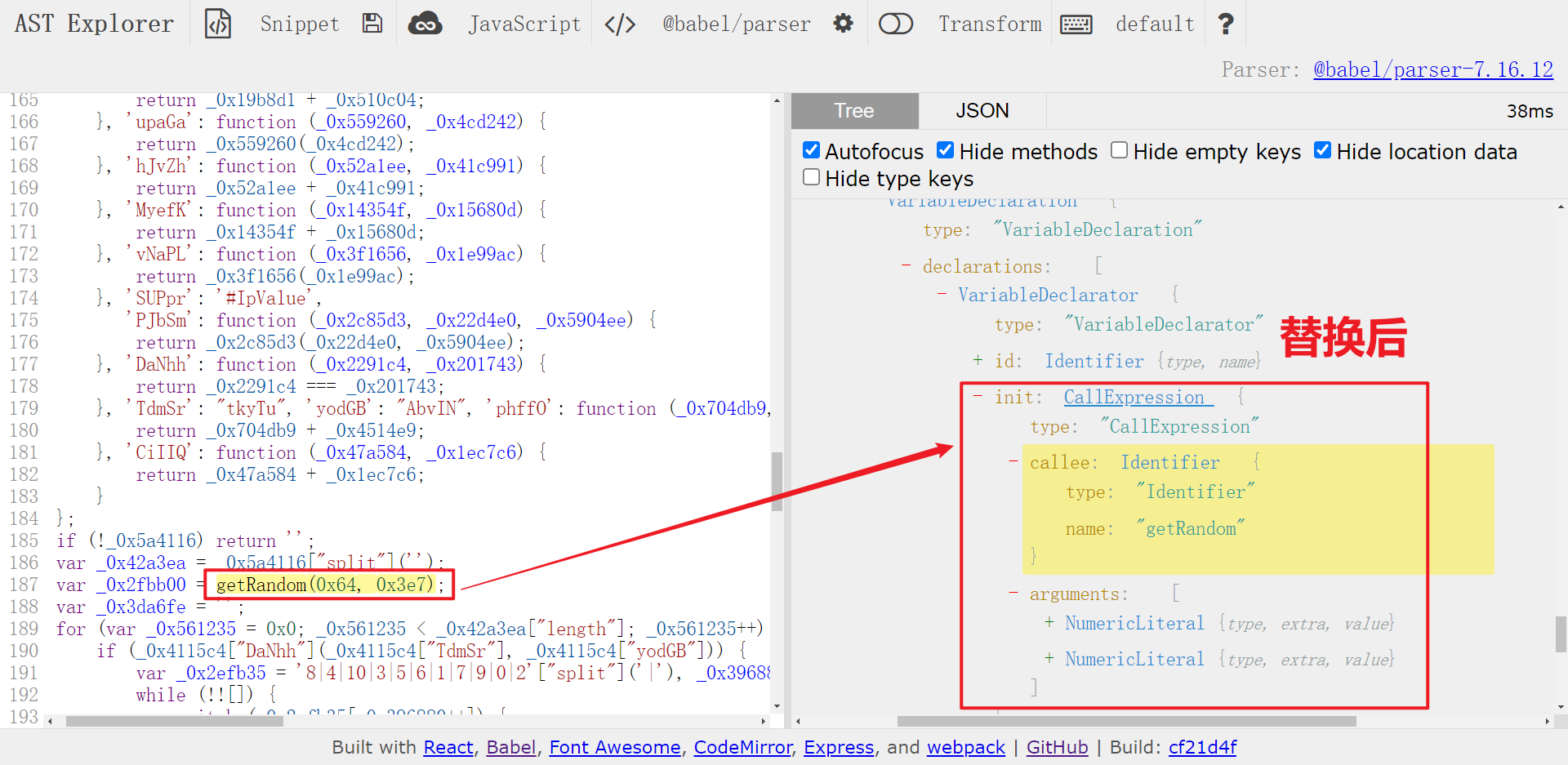
对于这种情况,传入的第一个参数为方法名称,后面的都是参数,那么可以直接取第一个元素为方法名称,使用 slice(1) 方法取后面所有的参数(因为后面的参数个数是不一定的),然后构造新的节点(callExpression)并替换即可,这部分遍历代码可以和前面二项式的替换相结合,代码如下:
// 函数替换,二项式计算:将类似 _0x278b2d['CnTaO'](_0x691267["length"], 0x1) 变成 _0x691267["length"] - 0x1
// 函数替换,方法调用:将类似 _0x4115c4["PJbSm"](getRandom, 0x64, 0x3e7) 变成 getRandom(0x64, 0x3e7)
const visitor4 = {
CallExpression(path){
for (let key in functionName) {
if (path.node.callee && path.node.callee.object && path.node.callee.object.name == key) {
let func = functionName[key][path.node.callee.property.value]
if (func.body.body[0].argument.type == "BinaryExpression") {
let operator = func.body.body[0].argument.operator
let left = path.node.arguments[0]
let right = path.node.arguments[1]
path.replaceInline(types.binaryExpression(operator, left, right))
}
if (func.body.body[0].argument.type == "CallExpression") {
let identifier = path.node.arguments[0]
let arguments = path.node.arguments.slice(1)
path.replaceInline(types.callExpression(identifier, arguments))
}
}
}
}
}
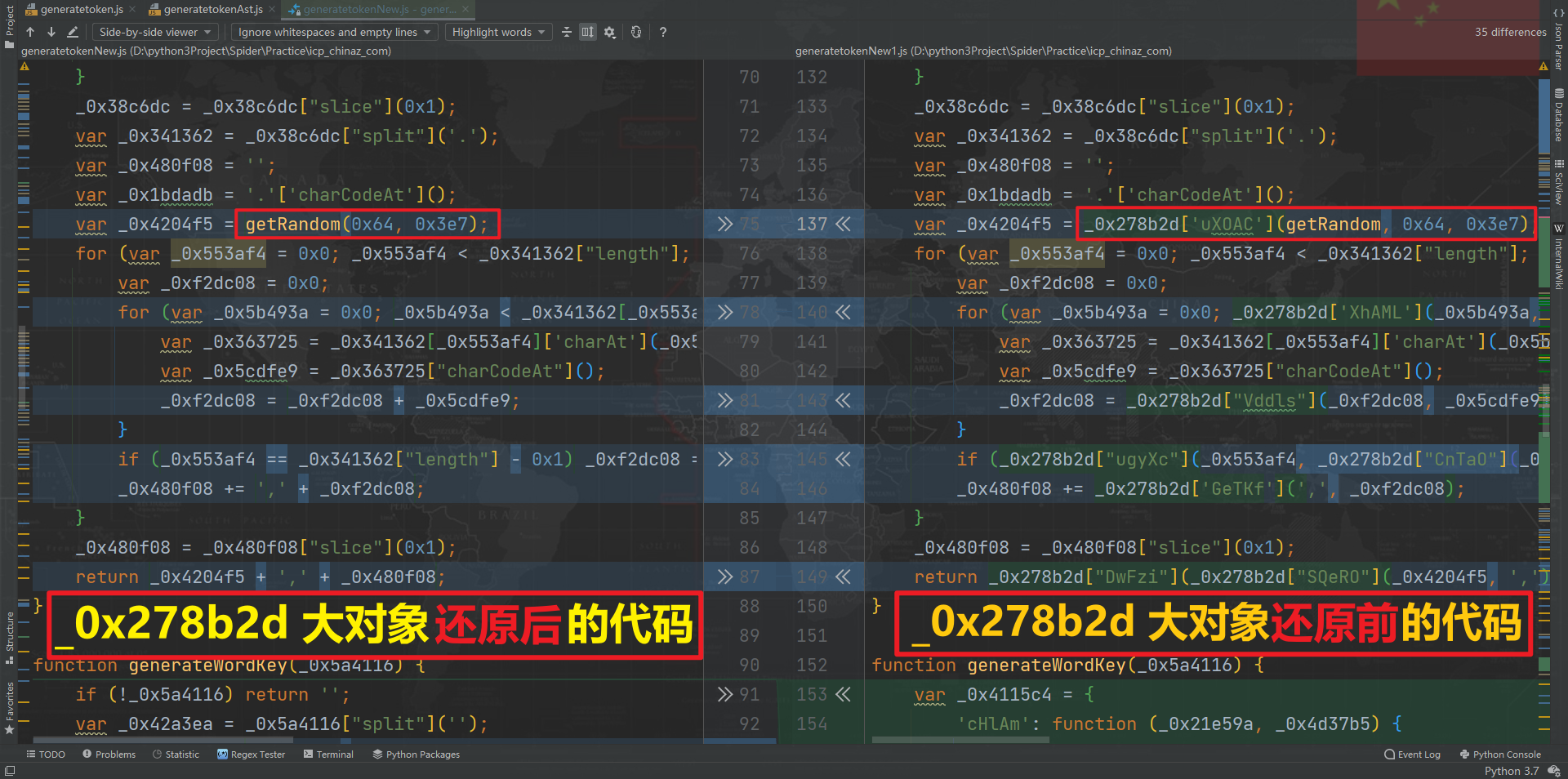
自此,第二步的大对象还原就完成了,可以看一下还原前后的对比,如下图所示浅蓝色标记的地方,所有调用四个大对象(_0x3b79c6、_0x278b2d、_0x4115c4、_0xd8ec33)的地方都被还原了:
经过前面几步的还原之后,我们发现 generateHostKey()、generateWordKey()、getRandom() 方法里都有一个 switch-case 的控制流,关于反控制流平坦化的讲解在我上期文章有很详细的介绍,不理解的可以看看上期文章,此处也不再赘述了,直接贴代码了:
// switch-case 反控制流平坦化
const visitor5 = {
WhileStatement(path) {
// switch 节点
let switchNode = path.node.body.body[0];
// switch 语句内的控制流数组名,本例中是 _0x28073a、_0x2efb35、_0x187fb8
let arrayName = switchNode.discriminant.object.name;
// 获取控制流数组绑定的节点
let bindingArray = path.scope.getBinding(arrayName);
// 获取节点整个表达式的参数、分割方法、分隔符
let init = bindingArray.path.node.init;
let object = init.callee.object.value;
let property = init.callee.property.value;
let argument = init.arguments[0].value;
// 模拟执行 '3|2|1|4|5|0|6'['split']('|') 语句
let array = object[property](argument)
// 也可以直接取参数进行分割,方法不通用,比如分隔符换成 , 就不行了
// let array = init.callee.object.value.split('|');
// switch 语句内的控制流自增变量名,本例中是 _0x38c69e、_0x396880、_0x3b3dc7
let autoIncrementName = switchNode.discriminant.property.argument.name;
// 获取控制流自增变量名绑定的节点
let bindingAutoIncrement = path.scope.getBinding(autoIncrementName);
// 可选择的操作:删除控制流数组绑定的节点、自增变量名绑定的节点
bindingArray.path.remove();
bindingAutoIncrement.path.remove();
// 储存正确顺序的控制流语句
let replace = [];
// 遍历控制流数组,按正确顺序取 case 内容
array.forEach(index => {
let consequent = switchNode.cases[index].consequent;
// 如果最后一个节点是 continue 语句,则删除 ContinueStatement 节点
if (types.isContinueStatement(consequent[consequent.length - 1])) {
consequent.pop();
}
// concat 方法拼接多个数组,即正确顺序的 case 内容
replace = replace.concat(consequent);
}
);
// 替换整个 while 节点,两种方法都可以
path.replaceWithMultiple(replace);
// path.replaceInline(replace);
}
}
到这里其实大部分混淆都已经还原了,已经很容易分析其逻辑了,还剩下一些细节,我们也还原一下,主要有以下细节:
- 十六进制、Unicode 编码等,转正常字符;
- 对象属性还原,比如
_0x3cbc20['length']转换成_0x3cbc20.length; - 表达式还原,比如
!![]直接计算成 true; - 删除未引用的变量,比如
_0xodD= "jsjiami.com.v6";; - 删除冗余逻辑代码,只保留 if 为 true 的。
这些还原代码在我上期文章有详细讲过,结合代码,在 astexplorer.net 对照其结构看,也能理解,同样也不赘述了,直接贴代码:
const visitor5 = {
// 十六进制、Unicode 编码等,转正常字符
"StringLiteral|NumericLiteral"(path){
delete path.node.extra;
},
// _0x3cbc20["length"] 转换成 _0x3cbc20.length
MemberExpression(path){
if (path.node.property.type == "StringLiteral") {
path.node.computed = false
path.node.property = types.identifier(path.node.property.value)
}
},
// 表达式还原,!![] 直接计算成 true
"BinaryExpression|UnaryExpression"(path) {
let {confident, value} = path.evaluate()
if (confident){
path.replaceInline(types.valueToNode(value))
}
},
// 删除未引用的变量,比如 _0xodD = "jsjiami.com.v6";
AssignmentExpression(path){
let binding = path.scope.getBinding(path.node.left.name);
if (!binding) {
path.remove();
}
}
}
// 删除冗余逻辑代码,只保留 if 为 true 的
const visitor6 = {
IfStatement(path) {
if(path.node.test.type == "BooleanLiteral") {
if(path.node.test.value) {
path.replaceInline(path.node.consequent.body)
} else {
path.replaceInline(path.node.alternate.body)
}
}
}
}
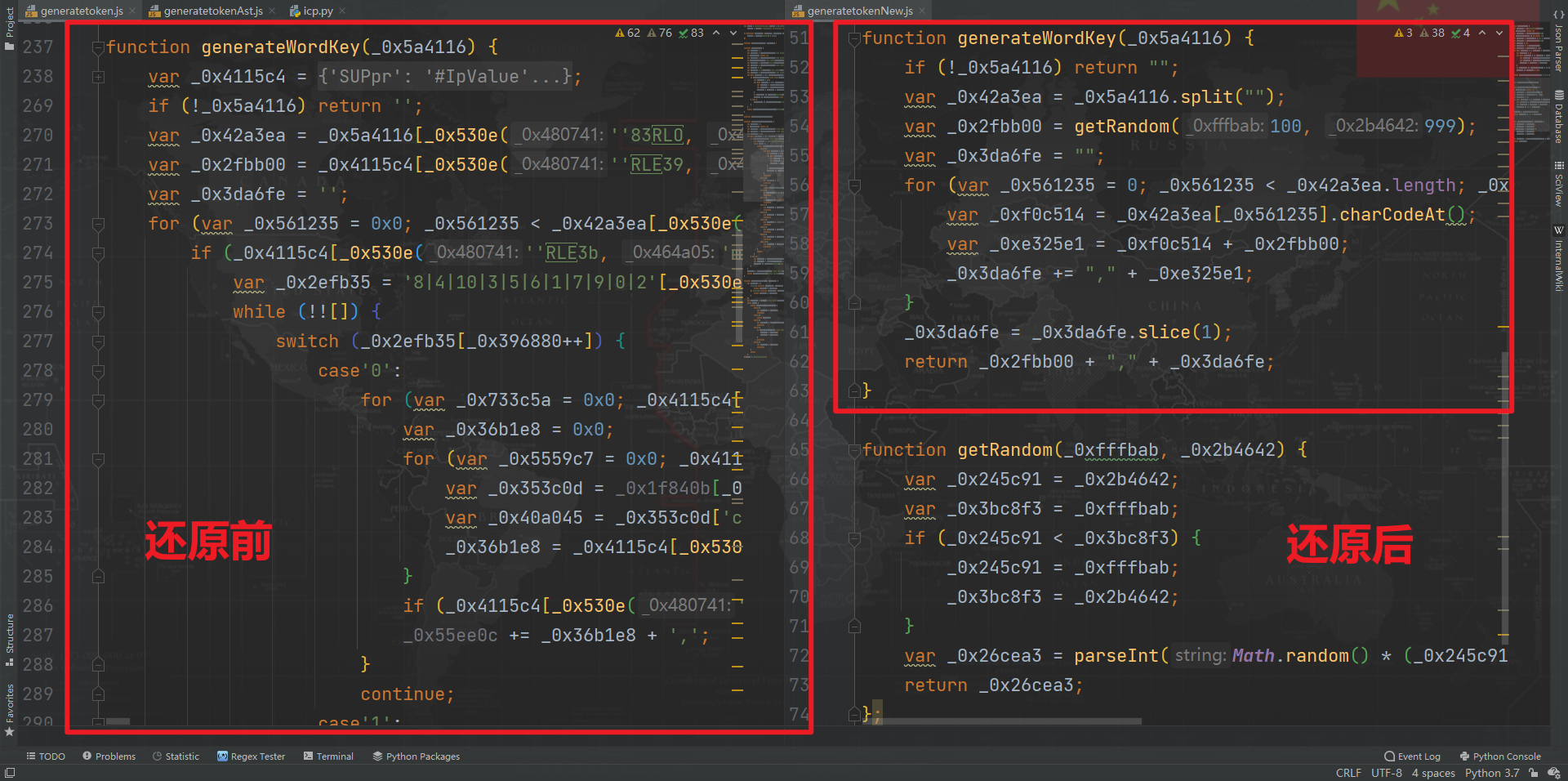
自此 jajiami v6 混淆就还原完毕了,还原前后对比一下,代码量缩短了很多,逻辑也更加清楚了,如下图所示:
最后结合 Python 代码,携带生成的 hostToken 和 permitToken,成功拿到备案号:
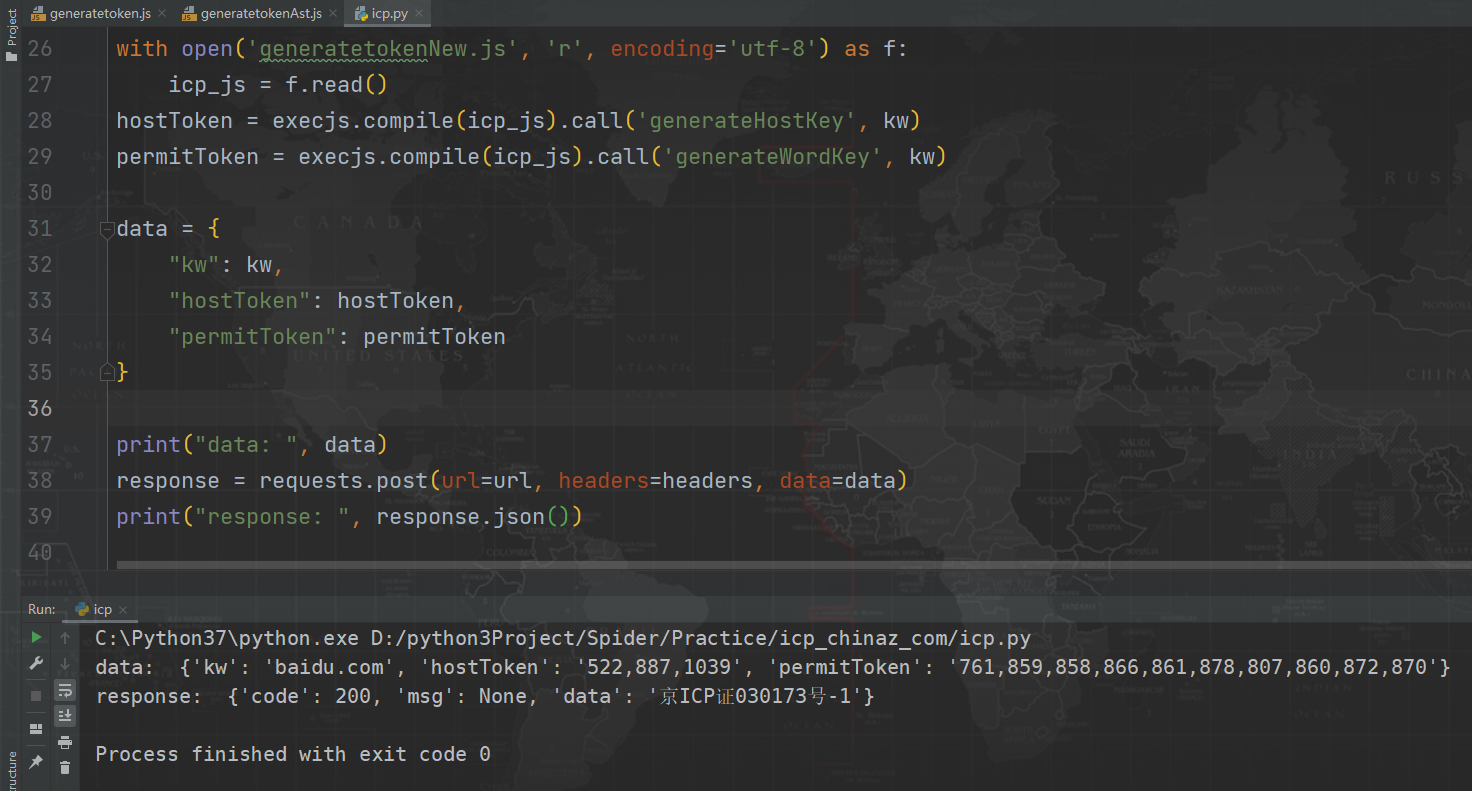
原混淆代码 generatetoken.js、AST 脱混淆代码 generatetokenAst.js、还原后的代码 generatetokenNew.js,以及 Python 测试代码均在 GitHub,均有详细注释,欢迎 Star。所有内容仅供学习交流,严禁用于商业用途、非法用途,否则由此产生的一切后果均与作者无关,在仓库中下载的文件学习完毕之后请于 24 小时内删除!
代码地址:https://github.com/kgepachong/crawler/tree/main/icp_chinaz_com
