DRY 原则,它的英文描述为:Don’t Repeat Yourself。中文直译为:不要重复自己。也可以理解为:不要写重复的代码。
我们从实现逻辑重复、功能语义重复和代码执行重复,这三种代码重复来说明DRY原则。
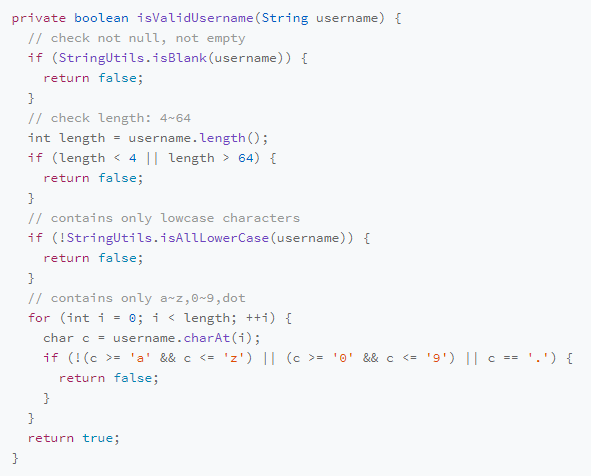
实现逻辑重复例如有两个函数isValidUserName() 和 isValidPassword() ,它们的代码其实是一样的,这个时候如果我们将其合并成一个函数,虽然代码量减少了,也没有重复代码,但却违反了DRY原则,从代码实现逻辑上看起来是重复的,但是从语义上并不重复。所谓“语义不重复”指的是:从功能上来看,这两个函数干的是完全不重复的两件事情,一个是校验用户名,另一个是校验密码,其实两个代码是做不同的事情,如果因为代码一样合并了,后面由于用户名或者密码校验逻辑改变,都将使函数再次拆分成两个函数。

功能语义重复
现在我们再来看另外一个例子。在同一个项目代码中有下面两个函数:isValidIp() 和 checkIfIpValid()。尽管两个函数的命名不同,实现逻辑不同,但功能是相同的,都是用来判定 IP 地址是否合法的。尽管两段代码的实现逻辑不重复,但语义重复,也就是功能重复,我们认为它违反了 DRY 原则。而且如果两个函数功能一样同时存在,且都被调用,这时一个程序员如果只知道一个函数,并修改了其函数逻辑,那么会导致另一个函数的逻辑并没有改变,偶从遗漏修改。

代码执行重复
这段代码,既没有逻辑重复,也没有语义重复,但仍然违反了 DRY 原则。这是因为代码中存在“执行重复”。
重复执行最明显的一个地方,就是在 login() 函数中,email 的校验逻辑被执行了两次。一次是在调用 checkIfUserExisted() 函数的时候,另一次是调用 getUserByEmail() 函数的时候。这个问题解决起来比较简单,我们只需要将校验逻辑从 UserRepo 中移除,统一放到 UserService 中就可以了。
除此之外,代码中还有一处比较隐蔽的执行重复,不知道你发现了没有?实际上,login() 函数并不需要调用 checkIfUserExisted() 函数,只需要调用一次 getUserByEmail() 函数,从数据库中获取到用户的 email、password 等信息,然后跟用户输入的 email、password 信息做对比,依次判断是否登录成功。实际上,这样的优化是很有必要的。因为 checkIfUserExisted() 函数和 getUserByEmail() 函数都需要查询数据库,而数据库这类的 I/O 操作是比较耗时的。我们在写代码的时候,应当尽量减少这类 I/O 操作。

如何提高代码可复用性
提高代码可复用性的一些方法,有以下 7 点。
- 减少代码耦合
- 满足单一职责原则
- 模块化
- 业务与非业务逻辑分离
- 通用代码下沉
- 继承、多态、抽象、封装
- 应用模板等设计模式