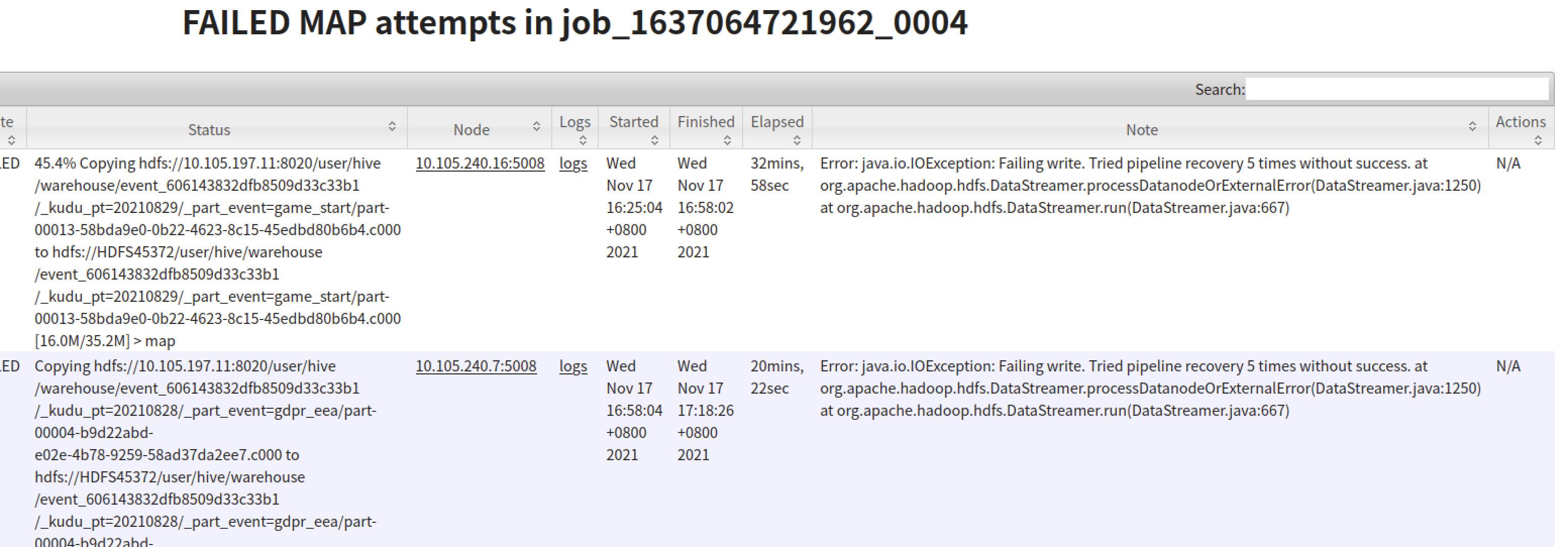
从报错信息看是 distcp 起的map 任务在写 hdfs 的 pipline 失败了,并且重试了5次没有成功,所以这个 task 直接抛出错误失败被 kill 了.
先说解决办法:清空了 hdfs 所以节点的 iptables 防火墙规则
加了参数 -Dmapreduce.map.memory.mb=4096
core-site 里面加了配置 ipc.server.listen.queue.size = 20480
增加超时时间 dfs.client.socket-timeout = 80000, dfs.socket.timeout = 80000
-
首先确认开启了 dfs.client.block.write.replace-datanode-on-failure.
-
接着分析这个map task 日志,查看报错信息,跟截图中的报错一样,重试5次失败了
-
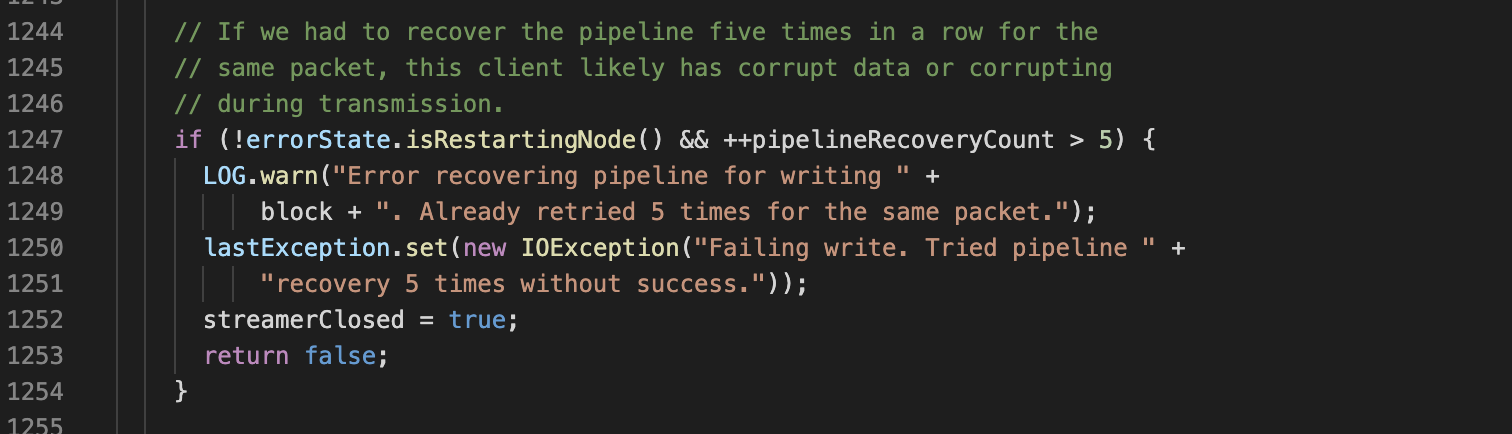
查看源码,首先定位到抛出错误的位置, DataStreamer.java 1250 行
- 没有多少信息,这个时候查看 distcp yarn app 日志,看到一个 warn 告警信息

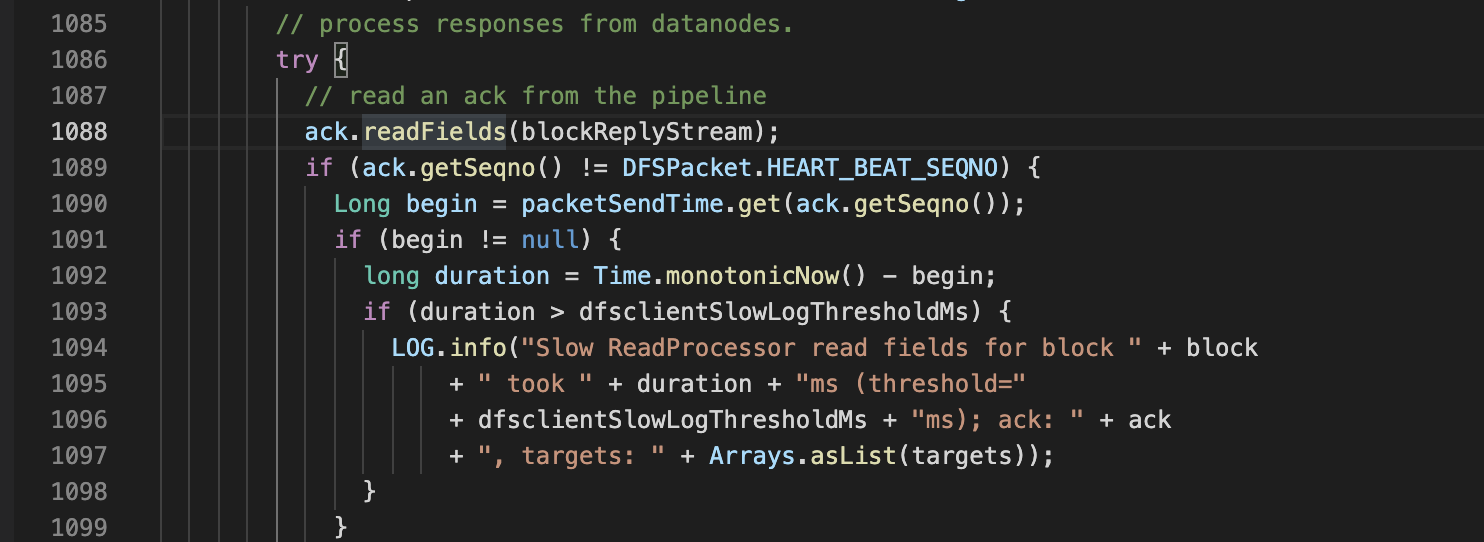
- 追踪报错位置 : DataStreamer.java 1088
- 得到报错前后逻辑,首先上面 1088 行这个方法报错了,然后监控线程标记错误
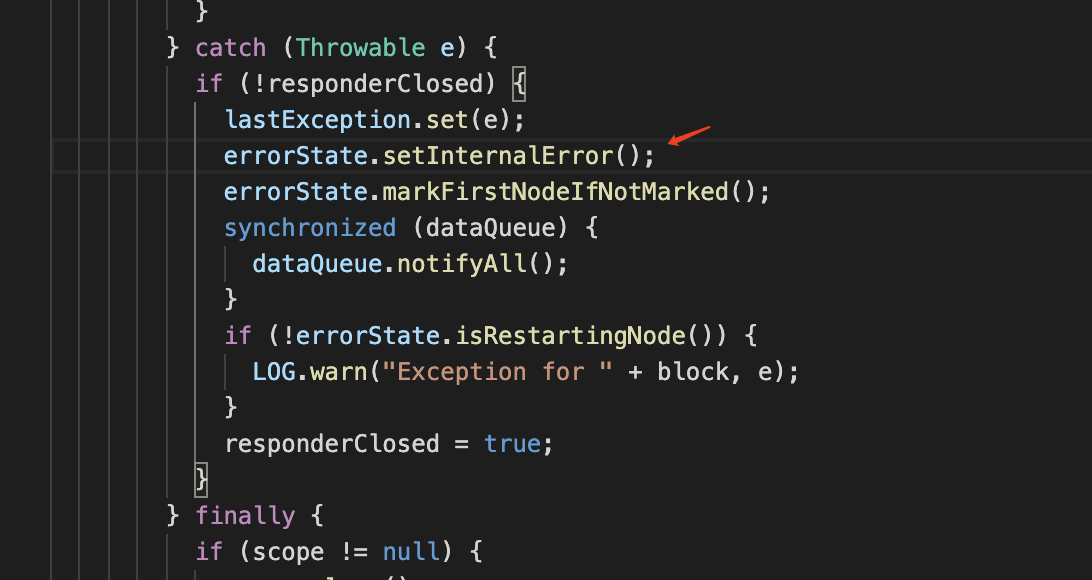
然后DataStreamer 开始重试:
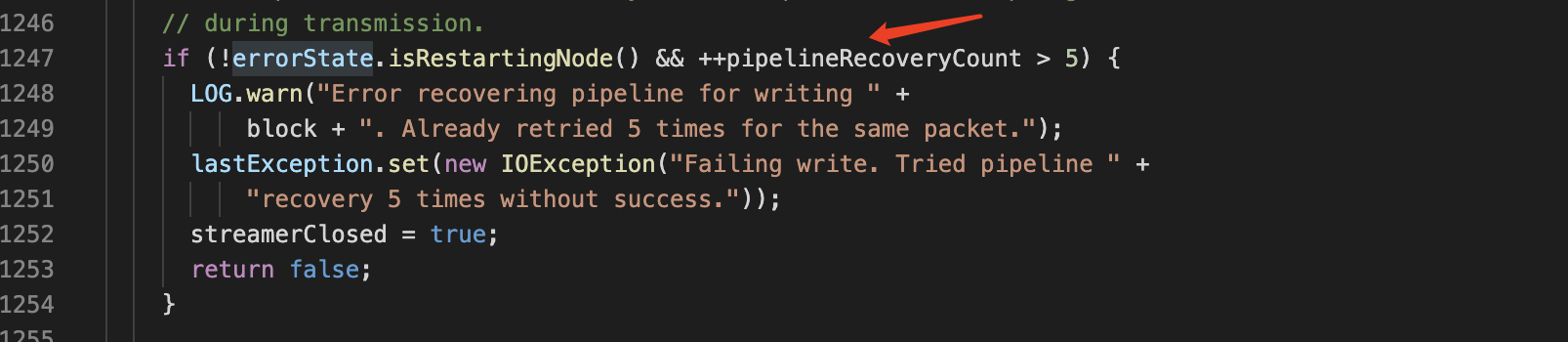
重试5次后这个 map attempts 最终抛出了这个错误.
- 继续 排查 1088 行 readFields 方法为什么会读取异常,这个方法是 client 端获取写入端的 ack,点入方法内,都是 Java io 流,没有什么信息.回过头来看 yarn app 最终 catch 的错误

得到这个写 pipeline 涉及的有个 dn 节点,结合第4点找到的 warn 信息里打印出的 block id ,接着需要追踪这些 block id 在 pipeline 各个 dn 节点中发生了什么.
8.在 dn 节点上的 dn 日志里搜索获得的 block id,最终找到最原始的异常信息:

也就是第7点中 readFields 方法读取的异常
总结:直接原因就是 distcp 任务中起的 map task 中的 client 写 block 到 dn 中超时了.至于为什么超时有很多种因素,主要是网络层面的原因,所以调整上面解决办法中的参数来规避这个问题.从这个问题排查过程可以一窥 hdfs 写文件 pipeline 的流程.