Redis数据结构(一):对外数据类型和底层数据结构;
Redis数据结构(二):简单动态字符串
Redis数据结构(三):双向链表和压缩链表
1.结构对应关系redis的基本数据类型:String(字符串)、List(列表)、 Hash(哈希)、Set(集合)和 Sorted Set(有序集合),底层数据结构一共有 6 种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。其对应关系如下图所示:

我们总是可以通过一个key去关联string,list,set等等,为什么会有这么多丰富的类型呢?从宏观角度分析如下:
字典是redis服务器中出现最频繁的复合型数据结构,除了hash结构的数据会用到字典外,整个redis数据库的所有key和value也组成了一个全局字典,还有待过期时间的key集合也是一个字典。zset集合中存储value和score值的映射关系也是字典结构,伪代码如下:
struct RedisDb { dict* dict; //全局字典 dict* expires; //过期字典 ... } struct zset { dict *dict; //存放value和score的映射关系 zskiplist *zsl; }
redis中全局字典表的结构与java中的HashMap结构类似(redis叫做hashtable),但是没有用到红黑树结构,如图所示:
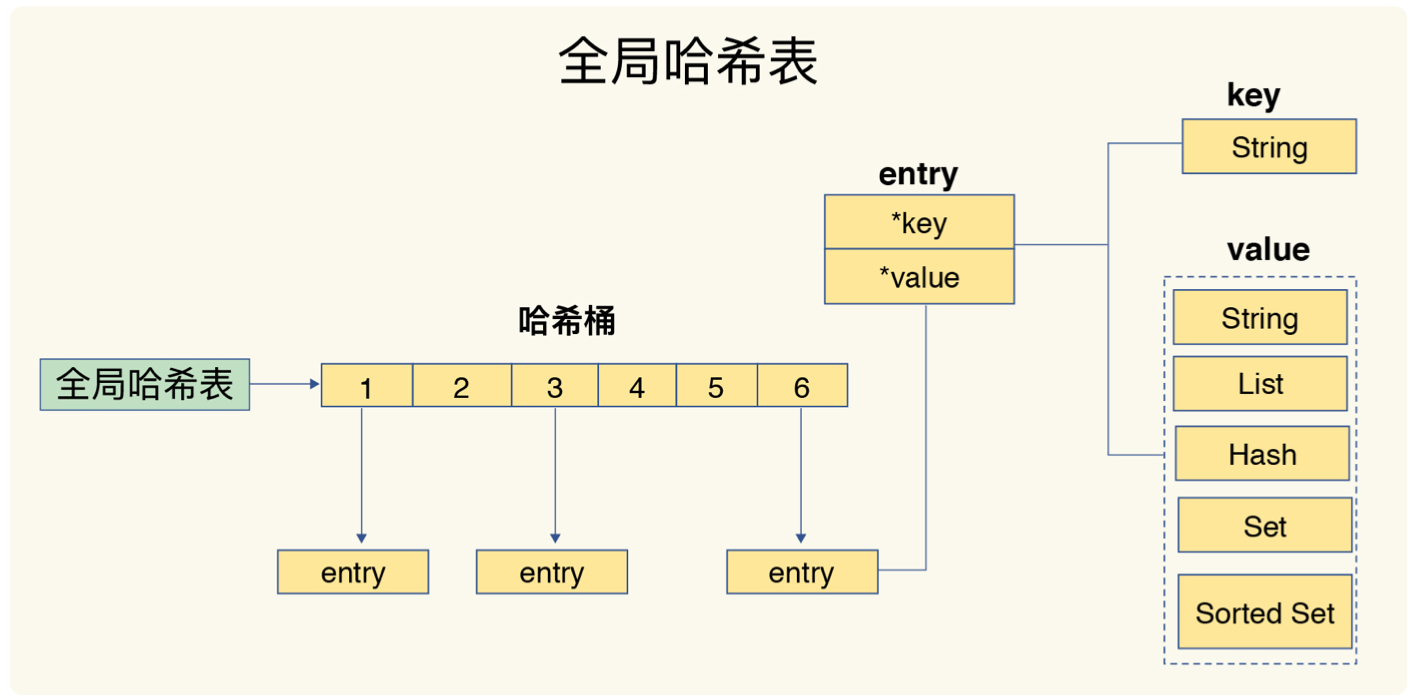
但凡碰见hash表的,就一定会有一个碰撞问题,并且碰撞问题是不能避免的,那么redis采用的呢就是向后探测的方法,也就是说,如果两个key通过hash算法散列到数组里面的时候刚好是同一个位置,那么entry2就会通过next指针挂在entry1之后(类比hashmap中的单项链表)。
那么链式hash的弊端都知道的,就像单链表一样,一个一个往后探测是比较费时间的。redis中也有自己的rehash过程,就是二次散列,redis默认使用两个全局hash表,在源码中是可以看到的。dictht ht[2];初始条件之下是使用hash表1的,随着插入的数据越来越多,在到达一定的条件之下,他会将hash表1中的内容再次映射进hash表2中,将原来的比较臃肿的表再舒展开。很明显rehash的过程就是一次再散列扩容的过程(类似于java中hashMap的长度扩容,不同的是java会有链表变红黑树的逻辑)。
众所周知,redis是单线程的,如果说触发了rehash这个过程,用户总不能一直阻塞等他reash完毕吧,于是redis出现了这样的技术:incremental rehashing,他们都叫渐进式rehash。简单来描述下:
redis正常处理请求,处理第一次请求,就顺便把hash表1第一个索引位置上的entry进行散列,映射到hash表2中,再处理一个请求,就把hash表1第二个索引位置上的entry进行散列
2.过期字典除了全局字典之外,redis还维护了一套过期字典,value存放的是对应key的过期时间,其结构与全局字典表类似
redis提供了以下三种删除策略,可以根据实际业务场景选择合适的删除策略
- 定时删除 对内存友好,对CPU不友好
定时是为每一个key都设置一个定时器,所以对cpu的负荷相当大
- 惰性删除 对内存不友好,对CPU友好
放任键过期不管, 但是每次从键空间中获取键时, 都检查取得的键是否过期, 如果过期的话, 就删除该键;如果没有过期, 就返回该键
- 定期删除 折中方案
定期就对数据库进行检查, 删除里面的过期键,不像定时那样为每一个key都设置定时器,也不像惰性删除那样等很久才删掉
总结:- redis主要由 dict和 expires两个字典构成, 其中 dict字典负责保存键值对,而 expires字典则负责保存键的过期时间;
- redis的键总是一个string对象, 而值则可以是任意一种Redis对象类型;
- redis会采用rehash来解决扩容问题,为防止rehash过程中造成阻塞,采用渐进式rehash分多次迁移数据;
- Redis提供了三种过期键删除策略,实际工作中建议采取惰性删除+定期删除的组合方式进行配置。
后面章节我们针对每一种底层数据类型进行总结,并不定时更新本篇文章,敬请期待……
如发现文章中有错误的知识点,欢迎在评论区指正。
参考链接:
redis(一)redis的数据结构
redis-全局hash表和expires过期字典
详解Redis数据结构——字典
https://www.cnblogs.com/lsgspace/ 原创作品欢迎转载,转载请注明出处