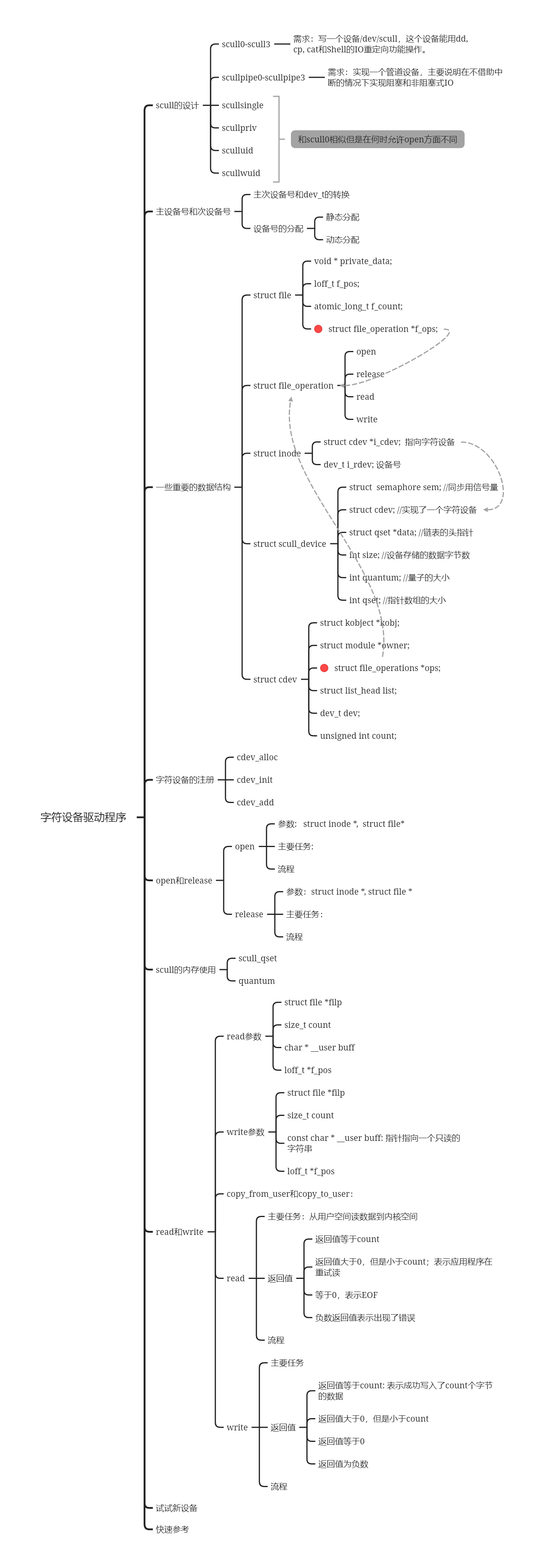
实现一个设备/dev/scull,这个设备能用dd, cp, cat和Shell的IO重定向功能操作。
设备号Linux用主次两个设备号去唯一的表示一个设备。其中主设备号表示一类驱动,而次设备号用来给具体的设备编号。内核可以通过此设备号得到一个设备指针
除了主次设备号,内核也使用专门的dev_t类型去给设备编号,dev_t是一个32位的整型变量。其中前12位用来表示主设备号,低20位用来表示次设备号。
设备号的转换主次设备号和devt_t的转换通过以下三个宏实现:
MAJOR(dev_t dev); //从设备编号中提取主设备号
MAJOR(dev_t dev); //从设备编号中提取从设备号
MKDEV(int major, int minor); //根据主从设备号计算出dev_t类型的设备号
(1)struct file
struct file {
void * private_data; //驱动程序常用字段,本文使用该字段表示量子集的头指针
loff_t f_pos; //读写文件的位置表示当前进程读写到了文件的那一个部分
atomic_long_t f_count; //结构体被进程引用的次数---引用计数
struct file_operation *f_ops; //表示在该文件上可以执行的操作
};
该结构体表示一个打开的设备或文件,在task_struct中,存在一个打开文件表,表中的每一项都是一个struct file结构体。
(2)struct file_operation
struct file_operation {
int (*open) (struct inode *, struct file *);
int (*release) (struct inode *, struct file *);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
};
该结构体是一个类似OOP中接口的东西,只定义了一系列操作函数的参数和返回值。具体怎么实现有实现他的结构体去决定。
(3)struct inode
struct inode {
struct cdev *i_cdev;
dev_t i_rdev;
};
文件系统中使用inode指向一个文件在磁盘中的位置。但是驱动程序中主要使用的主要是涉及到设备的字段,i_rdev表示设备编号,i_cdev指向一个设备
(4)struct scull_device
struct scull_device {
struct semaphore sem; //同步用信号量
struct cdev; //实现了一个字符设备
struct qset *data; //链表的头指针
int size; //设备存储的数据字节数
int quantum; //量子的大小
int qset; //指针数组的大小
};
scull设备,在用户态抽象成/dev/scull。
(5)struct cdev
struct cdev {
struct kobject *kobj; //指向一个kobject类型
struct module *owner; //表示该设备属于那个厂商
struct file_operations *ops; //留坑
struct list_head list; //链接系统内所有的字符设备
dev_t dev; //设备编号
unsigned int count;
};
(1)cdev_alloc
struct cdev * cdev_alloc (void);
cdev_alloc内部会调用kmalloc给设备分配空间
(2)cdev_init
void cdev_init (struct cdev * cdev,
const struct file_operations * fops);
cdev_init主要是用来初始化file_operations结构
(3)cdev_add
int cdev_add (struct cdev * p,
dev_t dev,
unsigned count);
把一个设备添加到系统里,需要注意执行这个操作之后,设备会立即生效,设备可以开始读写。
(4)scull中的设备注册
struct scull_device封装了字符设备,因此scull中的字符设备不需要cdev_alloc去分配空间。同时scull的设备注册放到了模块初始化中完成。主要流程为:
- cdev_init中使用全局的file_operations结构初始化字符设备
- 调用cdev_add把设备添加到系统
(1) open
进程使用设备需要申请和释放,而open和release就分别用于实现这两个目的。open函数的签名如下:
int (*open)(struct inode *inode, struct file *filp);
它接受两个参数:inode主要用于从获取字符设备指针,filp是文件指针,前文提到的进程的打开文件表中的就是filp
scull中open流程如下:
-
通过设备指针inode->i_cdev获取struct scull_dev设备指针,并且让filp的private_data字段指向scull_dev设备指针。
-
如果是以只写模式打开设备,还需要调用scull_trim去清空量子集里全部的数据
int(*release)(struct inode *, struct file *)
(2) release
release的主要工作有两个:
a. 释放file指针中的private字段
b. 在最后一次close的时候关闭设备
scull的内存结构scull设备实际上就是内核内存中一片可读写的区域,这片区域使用链表结构去表示,链表中的每个节点表示一个
独立的读写区域,最小的读写单元称作量子。链表的每个节点称作量子集。
默认情况下,每个量子集存储有1000个量子,每个量子能存储4000字节的数据,一个量子集存储4M数据。
在scull源码中SCULL_QUANTUM表示量子存储的默认字节数,SCULL_QSET表示每个量子集存储的量子个数。
struct scull_qset {
void **data;
struct scull_qset *next;
};
struct scull_device中的data字段表示链表的头指针
[此处缺张图]
scull的读写和清空操作(1) read
1.获取当前进程分配的设备指针
2.计算量子集存储的总字节数,计算方式是量子大小 * 量子集里量子个数
3.进程访问文件的位置比设备大小要大,说明已经读到了EOF,函数返回0
4.如果本次读操作会越界,则缩小count到文件边界
5.使用f_pos换算当前访问到了哪个量子集---除法,并且换算出占用最后一个量子集多少字节的空间
6.使用scull_follow定位到要读取的量子集
7.如果本次会读取会超过最后一个量子的边界,则缩小count
8.从指定位置开始拷贝count字节的数据,更新失败返回-EFAULT
9.更新f_pos和设置函数返回值
【此处缺张图】
定位要读取的量子集
(2) write
1.计算每个量子集的大小,设置函数默认返回值为ENOMEM
2.计算item, rest
3.计算s_pos,q_pos
4.调用scull_follow定位要写入的原子集的位置
5.如果data或者data[s_pos]为空,则给他们分配内存
6.如果写入count字节会导致量子溢出,则修改count
7.执行拷贝操作,失败返回-EFAULT
8.更新f_pos和返回值
9.如果dev->size小于f_pos,更新dev->size为f_pos
参考1.LDD3