- 1、引言
- 2、封闭世界的行人重识别
- 2.1 特征表示学习
- 2.1.1 全局特征表示学习
- 2.1.2 局部特征表示学习
- 2.1.3 辅助特征表示学习
- 2.1.4 视频特征表示学习
- 2.1.5 架构设计
- 2.2 深度度量学习
- 2.2.1 Loss函数设计
- 2.2.2 训练策略
- 2.3 排序优化
- 2.3.1 重排名
- 2.3.2 排名融合
- 2.4 数据集和评估
- 2.4.1 数据集和评估度量
- 2.4.2 深入分析 State-of-The-Arts
- 2.1 特征表示学习
- 3、开放世界的行人再识别
- 3.1 异构Re-ID
- 3.1.1 基于深度的Re-ID
- 3.1.2 文本到图像的Re-ID
- 3.1.3 可见红外Re-ID
- 3.1.4 交叉分辨率Re-ID
- 3.2 端到端Re-ID
- 3.3 半监督和无监督Re-ID
- 3.3.1 无监督Re-ID
- 3.3.2 无监督域自适应
- 3.3.3 无监督Re-ID SOTA
- 3.4 噪声鲁棒的Re-ID
- 3.5 开放集Re-ID及其他
- 3.1 异构Re-ID
- 4、展望:下一个时代的重新识别
- 4.1 mINP:一种新的Re-ID评估指标
- 4.2 单/跨模态重识别的新基线
- 4.3 未充分调查的未解决问题
- 4.3.1 不可控的数据收集
- 4.3.2 人工注释最小化
- 4.3.3 特定领域/通用架构设计
- 4.3.4 动态模型更新
- 4.3.5 高效的模型部署
- 5、结束语
- 应用材料
- A.基于单模态图像的Re-ID实验
- B.基于视频的Re-ID实验
- C. 跨模态重识别实验
- D. Partial Re-ID实验
- E. 本次调查概述
论文地址:https://arxiv.org/abs/2001.04193
代码:https://github.com/mangye16/ReID-Survey
作者知乎讲解:https://zhuanlan.zhihu.com/p/342249413
摘要:行人重识别(Re-ID)旨在通过多个不重叠的摄像头检索感兴趣的行人。随着深度神经网络的进步和智能视频监控需求的增加,它在计算机视觉社区中获得了显着增加的兴趣。通过剖析开发行人Re-ID系统所涉及的组件,我们将其分为封闭世界和开放世界设置。广泛研究的封闭世界环境通常应用于各种以研究为导向的假设,并在许多数据集上使用深度学习技术取得了令人鼓舞的成功。我们首先从深度特征表示学习、深度度量学习和ranking优化三个不同的角度对封闭世界的行人Re-ID进行了全面的概述和深入分析。随着封闭世界设置下的性能饱和,Person Re-ID的研究重点最近转移到了开放世界设置,面临着更具挑战性的问题。该设置更接近特定场景下的实际应用。我们从五个不同方面总结了开放世界的Re-ID。通过分析现有方法的优势,我们设计了一个强大的AGW基线,在四个不同的Re-ID任务的十二个数据集上实现了最先进或至少可比的性能。同时,我们为行人重识别引入了一个新的评估指标(mINP),表示找到所有正确匹配的成本,这为评估重识别系统的实际应用提供了额外的标准。最后,讨论了一些重要但未被充分调查的开放性问题。
关键词:行人重识别、行人检索、文献调查、评估指标、深度学习
行人重新识别(Re-ID)已被广泛研究为跨非重叠摄像机[1]、[2]的特定行人检索问题。给定一个查询感兴趣的人,Re-ID的目标是确定此人是否在不同的相机拍摄的不同时间出现在另一个地方,或者甚至是同一相机在不同的瞬间[3]。查询人可以用图像[4]、[5]、[6]、视频序列[7]、[8],甚至是文本描述[9]、[10]来表示。由于公共安全的迫切需求和越来越多的监控摄像头,Person Re-ID在智能监控系统中势在必行,具有重大的研究影响和现实意义。
由于存在不同的视点[11]、[12]、不同的低图像分辨率[13]、[14]、光照变化[15]、不受约束的姿势[16]、[17]、[18],遮挡[19],[20],异构模式[10],[21],复杂的相机环境,背景杂波[22],不可靠的边界框生成等,Re-ID是一项具有挑战性的任务,。这些导致不同的变化和不确定性。此外,对于实际模型部署,动态更新的相机网络[23]、[24]、具有高效检索的大规模图库[25]、组不确定性[26]、显着的领域转移[27]、看不见的测试场景[28]、增量模型更新[29]和换衣服[30]也大大增加了难度。这些挑战导致Re-ID仍然是未解决的问题。早期的研究工作主要集中在具有身体结构的手工特征构建[31]、[32]、[33]、[34]、[35]或距离度量学习[36]、[37]、[38]、[39]、[40]、[41]。随着深度学习的进步,Person Re-ID在广泛使用的基准测试[5]、[42]、[43]、[44]上取得了令人鼓舞的表现。然而,以研究为导向的场景与实际应用之间仍有很大差距[45]。这促使我们进行全面调查,为不同的Re-ID任务开发强大的基线,并讨论几个未来的方向。
尽管一些调查也总结了深度学习技术[2]、[46]、[47],但我们的调查有三个主要区别:1)我们通过讨论现有深度学习方法的优势和限制,分析最先进的技术。这为未来的算法设计和新主题探索提供了见解。2)我们为未来的发展设计了一个新的强大基线(AGW:Attention Generalized mean pooling with Weighted triplet loss)和一个新的评估指标(mINP:mean Inverse Negative Penalty)。AGW在12个数据集上针对四种不同的Re-ID任务实现了最先进的性能。mINP为现有CMC/mAP提供了一个补充指标,表明找到所有正确匹配的成本。3)我们尝试讨论几个重要的研究方向和未充分研究的开放问题,以缩小封闭世界和开放世界应用之间的差距,向现实世界的Re-ID系统设计迈出一步。
除非另有说明,本次调查中的Person Re-ID是指从计算机视觉角度跨多个监控摄像头的行人检索问题。
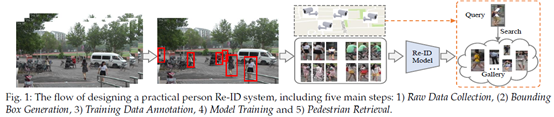
一般来说,针对特定场景构建person Re-ID系统需要五个主要步骤(如图1所示):
1)步骤1:原始数据收集:从监控摄像头获取原始视频数据是实际视频调查的首要要求。这些摄像机通常位于不同环境下的不同地方[48]。最有可能的是,这些原始数据包含大量复杂且嘈杂的背景杂波。
2)第2步:边界框生成:从原始视频数据中提取包含人物图像的边界框。通常,在大规模应用中手动裁剪所有人物图像是不可能的。边界框通常通过行人检测[49]、[50]或跟踪算法[51]、[52]获得。
3)第3步:训练数据注释:注释跨相机标签。由于较大的跨相机变化,训练数据注释通常对于判别性Re-ID模型学习是必不可少的。在存在大域转移[53]的情况下,我们经常需要在每个新场景中对训练数据进行注释。
4)第4步:模型训练:用之前带注释的人物图像/视频训练一个有判别力和鲁棒性的Re-ID模型。这一步是开发Re-ID系统的核心,也是文献中研究最广泛的范例。已经开发了广泛的模型来处理各种挑战,主要集中在特征表示学习[54]、[55]、距离度量学习[56]、[57]或它们的组合上。
5)第5步:行人检索:测试阶段进行行人检索。给定一个感兴趣的人(查询)和一个画廊集,我们使用在前一阶段学习的Re-ID模型提取特征表示。通过对计算的查询到图库的相似度进行排序,获得检索到的排名列表。一些方法还研究了排名优化以提高检索性能[58]、[59]。
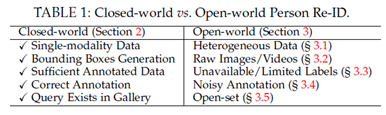
根据上述五个步骤,我们将现有的Re-ID方法分为两大趋势:封闭世界和开放世界设置,如表1所示。逐步比较以下五个方面:
1)单-模态与异构数据:对于步骤1中的原始数据收集,所有人都由封闭世界设置中的单模态可见相机捕获的图像/视频表示[5]、[8]、[31],[42]、[43]、[44]。然而,在实际的开放世界应用中,我们可能还需要处理异构数据,例如红外图像[21]、[60]、草图[61]、深度图像[62],甚至是文本描述[63]。这激发了第3.1节中的异构Re-ID。
2)Bounding Box Generation vs. Raw Images/Videos:对于Step 2中的bounding box生成,封闭世界person Re-ID通常基于生成的bounding box进行训练和测试,其中bounding box主要包含person外观信息。相比之下,一些实际的开放世界应用程序需要从原始图像或视频中进行端到端的行人搜索[55]、[64]。这导致了另一个开放世界主题,即第3.2节中的端到端行人搜索。
3)足够的带注释的数据与不可用/有限的标签:对于步骤3中的训练数据注释,封闭世界的行人Re-ID通常假设我们有足够的带注释的训练数据来进行有监督的Re-ID模型训练。然而,在每个新环境中为每个相机进行标签标注既费时又费力,成本也很高。在开放世界场景中,我们可能没有足够的注释数据(即有限的标签)[65],甚至没有任何标签信息[66]。这激发了第3.3节中对无监督和半监督Re-ID的讨论。
4)正确注释与嘈杂注释:对于第4步,现有的封闭世界行人Re-ID系统通常假设所有注释都是正确的,并带有干净的标签。然而,由于注释错误(即标签噪声)或不完美的检测/跟踪结果(即样本噪声、Partial Re-ID[67]),注释噪声通常是不可避免的。这导致了第3.4节中在不同噪声类型下对噪声鲁棒性行人Re-ID的分析。
5)Query Exists in Gallery vs. Open-set:在行人检索阶段(第5步),大多数现有的封闭世界人物识别工作都假设查询必须在通过计算CMC[68]和mAP [5]设置的画廊中进行。然而,在许多情况下,查询人可能不会出现在图库集[69]、[70]中,或者我们需要执行验证而不是检索[26]。这将我们带到了第3.5节中的开放集行人Re-ID。
该调查首先在第 2 节中介绍了在封闭世界设置下广泛研究的行人Re-ID。在第2.4节中对数据集和最新技术进行了详细审查。然后我们在第3节中介绍了开放世界的行人再识别。第4节介绍了对未来Re-ID的展望,包括一个新的评估指标(第4.1节)、一个新的强大的AGW基线(第4.2节)。我们讨论了几个未充分调查的未解决问题以供未来研究(第4.3节)。结论将在第5节中得出。结构概述见补充。
2、封闭世界的行人重识别本节概述了封闭世界的行人Re-ID。如第1节所述,此设置通常具有以下假设:1)人的外表由单模态可见相机捕获,通过图像或视频;2)人由bounding box表示,其中大部分bounding box区域属于同一个身份;3)训练有足够的带注释的训练数据用于有监督的判别式Re-ID模型学习;4)注释一般是正确的;5)查询人必须出现在图库集中。通常,标准的封闭世界Re-ID系统包含三个主要组件:特征表示学习(第2.1节),专注于开发特征构建策略;深度度量学习(§2.2),旨在设计具有不同损失函数或采样策略的训练目标;Ranking优化(第2.3节),专注于优化检索到的排名列表。第2.4.2节提供了数据集和SOTA的概述以及深入分析。
2.1 特征表示学习我们首先讨论了封闭世界行人Re-ID中的特征学习策略。有四个主要类别(如图2所示):a)全局特征(第2.1.1节),它为每个人的图像提取全局特征表示向量,而无需额外的注释线索[55];b)局部特征(第2.1.2节),它聚合部件级局部特征以制定每个人图像的组合表示[75]、[76]、[77];c)辅助特征(第2.1.3节),它使用辅助信息改进了特征表示学习,例如属性[71]、[72]、[78]、GAN生成的图像[42]等。d)视频特征(第2.1.4节),它使用多个图像帧和时间信息[73]、[74]学习基于视频的Re-ID[7]的视频表示。我们还回顾了第2.1.5节中行人重识别的几个特定架构设计。
2.1.1 全局特征表示学习全局特征表示学习为每个人的图像提取一个全局特征向量,如图2(a)所示。由于深度神经网络最初应用于图像分类[79]、[80],因此早期将先进的深度学习技术集成到Person Re-ID领域时,全局特征学习是首选。

为了捕捉全局特征学习中的细粒度线索,在[81]中开发了一个由单图像表示(SIR)和跨图像表示(CIR)组成的联合学习框架,使用特定的子网络进行triplet loss训练。广泛使用的ID判别嵌入(IDE)模型[55]通过将每个身份视为不同的类,将训练过程构建为多类分类问题。它现在广泛用于Re-ID社区[42]、[58]、[77]、[82]、[83]。钱等人[84]开发了一种多尺度深度表示学习模型来捕捉不同尺度的判别线索。
注意力信息。注意力方案已在文献中得到广泛研究,以增强表示学习[85]。1)第一组:行人图像内的注意力。典型的策略包括像素级注意[86]和通道特征响应重新加权[86]、[87]、[88]、[89]或背景抑制[22]。空间信息集成在[90]中。2)第2组:关注多个人物图像的注意力。[91]中提出了一种上下文感知的注意力特征学习方法,它结合了序列内和序列间的注意力,用于成对的特征对齐和细化。在[92]、[93]中添加了注意力一致性属性。组相似性[94]、[95]是另一种利用跨图像注意力的流行方法,它涉及用于局部和全局相似性建模的多个图像。第一组主要增强对错位/不完美检测的鲁棒性,第二组通过挖掘多个图像之间的关系来改进特征学习。
2.1.2 局部特征表示学习它学习部分/区域聚合特征,使其能够抵抗错位[77],[96]。身体部位要么通过人体解析/姿势估计自动生成(第1组),要么通过大致水平划分(第2组)自动生成。
通过自动身体部位检测,流行的解决方案是结合全身表示和局部特征[97]、[98]。具体来说,多通道聚合[99]、多尺度上下文感知卷积[100]、多级特征分解[17]和双线性池化[97]旨在改善局部特征学习。在[98]中还研究了部件级相似性组合,而不是特征级融合。另一种流行的解决方案是增强对背景杂波的鲁棒性,使用姿势驱动匹配[101]、姿势引导部件注意模块[102]、语义部件对齐[103]、[104]。
对于水平划分的区域特征,在基于部件的卷积基线(PCB)[77]中学习了多个部分级分类器,它现在作为当前最先进的[28],[105],[106]中强大的部件特征学习基线。为了捕捉多个身体部位之间的关系,Siamese Long Short-Term Memory (LSTM)架构[96]、二阶非局部注意力[107]、交互和聚合(IA)[108]旨在加强特征学习。
第一组使用人类解析技术来获得语义上有意义的身体部位,这提供了很好的部件特征。然而,它们需要一个额外的姿态检测器,并且容易出现噪声姿态检测[77]。
第二组采用均匀划分得到横条纹部分,比较灵活,但对重度遮挡和大背景杂波比较敏感。
2.1.3 辅助特征表示学习辅助特征表示学习通常需要额外的注释信息(例如语义属性[71])或生成/增强的训练样本来加强特征表示[19]、[42]。
语义属性。[72]中引入了联合身份和属性学习基线。苏等人[71]通过结合预测的语义属性信息,提出了一个深度属性学习框架,增强了半监督学习方式中特征表示的泛化性和鲁棒性。语义属性和注意方案都被结合起来以改进部件特征学习[109]。[110]中还采用语义属性进行视频Re-ID特征表示学习。它们还被用作无监督学习中的辅助监督信息[111]。
视点信息。视点信息也被用来增强特征表示学习[112],[113]。多级分解网络(MLFN)[112]还尝试在多个语义级别上学习身份判别和视图不变的特征表示。刘等人[113]提取视图通用和视图特定学习的组合。在视点感知特征学习中,[114]中结合了角度正则化。
域信息。域引导丢弃(DGD)算法[54]旨在自适应地挖掘域可共享和域特定的神经元,用于多域深度特征表示学习。Lin等人[115]将每个相机视为一个不同的域,提出了一种多相机一致匹配约束,以在深度学习框架中获得全局最优表示。类似地,相机视图信息或检测到的相机位置也被应用在[18]中,以通过相机特定的信息建模来改进特征表示。
GAN生成。本节讨论使用GAN生成的图像作为辅助信息。郑等人[42]开始首次尝试将GAN技术应用于Person Re-ID。它使用生成的人物图像改进了有监督的特征表示学习。姿势约束被纳入[116]以提高生成的人物图像的质量,生成具有新姿势变体的人物图像。在[117]中设计了一种姿势归一化图像生成方法,它增强了对姿势变化的鲁棒性。相机样式信息[118]也集成在图像生成过程中,以解决跨相机的变化。一个联合判别和生成学习模型[119]分别学习外观和结构代码以提高图像生成质量。使用GAN生成的图像也是无监督域自适应Re-ID[120]、[121]中广泛使用的方法,近似于目标分布。
数据增强。对于Re-ID,自定义操作是随机调整大小、裁剪和水平翻转[122]。此外,生成对抗性遮挡样本[19]以增加训练数据的变化。[123]中提出了一种类似的随机擦除策略,向输入图像添加随机噪声。一批DropBlock[124]随机地在特征图中删除一个区域块以加强注意力集中的特征学习。巴克等人[125]生成在不同光照条件下渲染的虚拟人。这些方法通过增强样本丰富了监督,提高了测试集的泛化性。
2.1.4 视频特征表示学习基于视频的Re-ID是另一个热门话题[126],其中每个人都由具有多个帧的视频序列表示。由于丰富的外观和时间信息,它在ReID社区中引起了越来越多的兴趣。这也给使用多张图像的视频特征表示学习带来了额外的挑战。
主要挑战是准确捕获时间信息。[127]为基于视频的行人Re-ID设计了一种循环神经网络架构,它联合优化了时间信息传播的最终循环层和时间池化层。在[128]中开发了一种用于空间和时间流的加权方案。严等人[129]提出了一种渐进/顺序融合框架来聚合帧级人体区域表示。在[110]中,语义属性也被用于具有特征分离和帧重新加权的视频Re-ID。联合聚合帧级特征和时空外观信息对于视频表示学习[130]、[131]、[132]至关重要。
另一个主要挑战是视频中不可避免的异常跟踪帧。在联合空间和时间注意力池化网络(ASTPN)[131]中选择信息帧,并将上下文信息集成在[130]中。受共同分割启发的注意力模型[132]通过相互一致的估计来检测多个视频帧中的显着特征。采用多样性正则化[133]来挖掘每个视频序列中的多个有区别的身体部位。采用仿射壳来处理视频序列中的异常帧[83]。一项有趣的工作[20]利用多个视频帧来自动完成遮挡区域。这些工作表明,处理噪声帧可以极大地改善视频表示学习。
处理不同长度的视频序列也具有挑战性。Chen等人[134]将长视频序列分成多个短片段,聚合排名靠前的片段以学习紧凑的嵌入。剪辑级学习策略[135]利用空间和时间维度的注意线索来产生强大的剪辑级表示。短期和长期关系[136]都集成在一个自注意力方案中。
2.1.5 架构设计将Person Re-ID 作为一个特定的行人检索问题,现有的大多数工作都采用为图像分类而设计的网络架构[79]、[80]作为主干。一些工作试图修改主干架构以实现更好的Re-ID功能。对于广泛使用的ResNet50主干[80],重要的修改包括将最后一个卷积stripe/大小更改为1[77],在最后一个池化层[77]中采用自适应平均池化,以及在池化后添加具有批量归一化的瓶颈层[82]。
准确性是特定Re-ID网络架构设计以提高准确性的主要关注点,Li等人[43]通过设计一个滤波器配对神经网络(FPNN)开始了第一次尝试,该网络与部分判别信息挖掘共同处理错位和遮挡。王等人[89]提出了一个带有专门设计的WConv层和Channel Scaling层的BraidNet。WConv层提取两个图像的差异信息以增强对未对齐的鲁棒性,通道缩放层优化每个输入通道的缩放因子。多级因子分解网络(MLFN)[112]包含多个堆叠块以在特定级别对各种潜在因子进行建模,并且动态选择因子以制定最终表示。开发了一种具有卷积相似度模块的高效全卷积连体网络[137],以优化多级相似度测量。通过使用深度卷积可以有效地捕获和优化相似度。
效率是Re-ID架构设计的另一个重要因素。一个高效的小规模网络,即OmniScale网络(OSNet)[138],是通过结合逐点卷积和深度卷积来设计的。为了实现多尺度特征学习,引入了由多个卷积流组成的残差块。
随着对自动机器学习的兴趣日益增加,提出了Auto-ReID[139]模型。Auto-Reid基于一组基本架构组件提供高效且有效的自动化神经架构设计,使用部分感知模块来捕获具有判别性的局部ReID特征。这为探索强大的特定领域架构提供了潜在的研究方向。
2.2 深度度量学习 在深度学习时代之前,度量学习已经通过学习马氏距离函数[36]、[37]或投影矩阵[40]得到了广泛的研究。度量学习的作用已被损失函数设计所取代,以指导特征表示学习。我们将首先回顾第
2.2.1节中广泛使用的损失函数,然后在第2.2.2节总结具有特定抽样设计的训练策略。
本次调查仅关注为深度学习设计的损失函数[56]。为手工系统设计的距离度量学习的概述可以在[2]、[143]中找到。在行人Re-ID的文献中,有三种广泛研究的损失函数及其变体,包括身份损失、验证损失和三元组损失。图3显示了三个损失函数的图示。

身份Loss。它将person Re-ID的训练过程视为图像分类问题[55],即每个身份都是一个不同的类。在测试阶段,采用池化层或嵌入层的输出作为特征提取器。给定带有标签yi的输入图像xi,xi被识别为类别yi的预测概率用softmax函数编码,由p(yi|xi)表示。
然后通过交叉熵计算身份损失
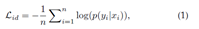
其中n表示每批中的训练样本数。身份损失已广泛用于现有方法[19]、[42]、[82]、[92]、[95]、[106]、[118]、[120]、[140]、[144]。一般来说,在训练过程中很容易训练和自动挖掘困难样本,如[145]所示。一些工作还研究了softmax变体[146],例如[147]中的球体损失和[95]中的AMsoftmax。另一种简单而有效的策略,即标签平滑[42]、[122],通常集成到标准的softmax交叉熵损失中。其基本思想是避免模型拟合过度自信的注释标签,提高泛化性[148]。
验证损失。它使用对比损失[96]、[120]或二元验证损失[43]、[141]优化成对关系。对比损失改进了相对成对距离比较,公式为
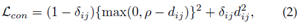
其中dij表示两个输入样本xi和xj的嵌入特征之间的欧几里得距离。δ_ij是一个二元标签指示符(当xi和xj属于同一身份时δ_ij=1,否则δ_ij=0)。ρ是一个边距参数。有几种变体,例如,与[81]中的排序SVM的成对比较。
二进制验证[43]、[141]区分输入图像对的正负。通常,差分特征fij由fij=(fj-fi)2[141]获得,其中fi和fj是两个样本xi和xj的嵌入特征。验证网络对差分特征进行分类分为正面或负面。我们使用p(δ_ij |f_ij)来表示输入对(xi和xj)被识别为δ_ij(0或1)的概率。具有交叉熵的验证损失为
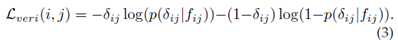
验证通常与身份损失相结合,以提高性能[94]、[96]、[120]、[141]。
Triplet Loss。它将Re-ID模型训练过程视为检索排序问题。基本思想是正对之间的距离应该比负对小一个预定义的边距[57]。通常,一个三元组包含一个锚样本xi、一个具有相同身份的正样本xj和一个来自不同身份的负样本xk。带边距参数的三元组损失表示为
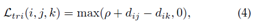
其中d(·)测量两个样本之间的欧几里得距离。如果我们直接优化上述损失函数,大部分容易三元组将主导训练过程,导致可辨别性有限。为了缓解这个问题,已经设计了各种信息丰富的三元组挖掘方法[14]、[22]、[57]、[97]。基本思想是选择信息丰富的三元组[57]、[149]。具体来说,在[149]中引入了具有权重约束的适度正挖掘,直接优化了特征差异。赫尔曼斯等人[57]证明每个训练批次中最难的正负挖掘有利于判别式Re-ID模型学习。一些方法还研究了用于信息三元组挖掘的点设置相似性策略[150],[151]。这通过软硬挖掘方案增强了对异常值样本的鲁棒性。
为了进一步丰富三元组监督,在[152]中开发了一个四元组深度网络,其中每个四元组包含一个锚样本、一个正样本和两个挖掘的负样本。四联体是用基于边际的在线硬负挖掘来制定的。优化四元组关系会导致更小的类内变异和更大的类间变异。
Triplet loss和identity loss的结合是深度Re-ID模型学习最流行的解决方案之一[28]、[87]、[90]、[93]、[103]、[104]、[116]、[137]、[142]、[153]、[154]。这两个组件对于判别特征表示学习是互惠互利的。
OIM Loss。除了上述三种损失函数外,还设计了一种在线实例匹配(OIM)损失[64],并采用了内存库方案。内存库{vk,k=1,2,…,c}包含存储的实例特征,其中c表示类号。然后OIM损失由下式表示
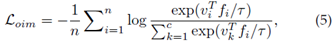
其中vi表示yi类对应的存储记忆特征,并且是控制相似性空间的温度参数[145]。v_i^T f_i衡量在线实例匹配分数。进一步包括与未标记身份的记忆特征集的比较,以计算分母[64],处理大量非目标身份的实例。这种记忆方案也被用于无监督域自适应Re-ID[106]。
2.2.2 训练策略批量采样策略在判别式Re-ID模型学习中起着重要作用。这是具有挑战性的,因为每个身份的注释训练图像的数量变化很大[5]。同时,严重不平衡的正负样本对增加了训练策略设计的额外难度[40]。
处理不平衡问题最常用的训练策略是身份抽样[57]、[122]。对于每个训练批次,随机选择一定数量的身份,然后从每个选定的身份中抽取几张图像。这种批量采样策略保证了信息丰富的正负挖掘。
为了处理正负之间的不平衡问题,自适应采样是调整正负样本贡献的流行方法,例如采样率学习(SRL)[89],课程采样[87]。另一种方法是样本重新加权,使用样本分布[87]或相似性差异[52]来调整样本权重。[155]中设计了一个有效的参考约束,将成对/三元组相似度转换为样本到参考相似度,解决不平衡问题并增强可辨别性,这对异常值也具有鲁棒性。
为了自适应地组合多个损失函数,多重损失动态训练策略[156]自适应地重新加权身份损失和三重损失,提取它们之间共享的适当分量。这种多损失训练策略可以带来一致的性能提升。
2.3 排序优化排序优化对于提高测试阶段的检索性能起着至关重要的作用。给定一个初始排名列表,它通过自动图库到图库相似性挖掘[58]、[157]或人类交互[158]、[159]优化排名顺序。Rank/Metric fusion[160]、[161]是另一种流行的方法,用于通过多个排名列表输入来提高排名性能。
2.3.1 重排名重新排序的基本思想是利用画廊间的相似度来优化初始排名列表,如图4所示。在[157]中提出了排名靠前的相似性拉动和排名靠后的不相似性推送。广泛使用的k-reciprocal reranking[58]挖掘上下文信息。[25]中应用了类似的上下文信息建模思想。白等人[162]利用底层流形的几何结构。通过整合跨邻域距离,引入了一种扩展的跨邻域重排序方法[18]。局部模糊重新排序[95]采用聚类结构来改进邻域相似度测量。
查询自适应。考虑到查询的差异,一些方法设计了查询自适应检索策略来代替统一的搜索引擎来提高性能[163],[164]。安迪等人[163]提出了一种使用局部保持投影的查询自适应重新排序方法。[164]中提出了一种有效的在线局部度量自适应方法,该方法通过为每个探针挖掘负样本来学习严格的局部度量。
人际交往。它涉及使用人工反馈来优化排名列表[158]。这在重新排序过程中提供了可靠的监督。[159]中提出了一种混合人机增量学习模型,该模型从人的反馈中累积学习,提高了实时的Re-ID排名性能。
 2.3.2 排名融合
2.3.2 排名融合
排名融合利用通过不同方法获得的多个排名列表来提高检索性能[59]。郑等人[165]在“L”形观察之上提出了一种查询自适应后期融合方法来融合方法。在[59]中开发了一种利用相似性和相异性的秩聚合方法。Person Re-ID中的等级融合过程被表述为使用图论[166]的基于共识的决策问题,将多个算法获得的相似度得分映射到带有路径搜索的图中。最近为度量融合设计了统一集成扩散(UED)[161]。UED保留了三种现有融合算法的优势,并通过新的目标函数和推导进行了优化。在[160]中也研究了度量集成学习。
2.4 数据集和评估 2.4.1 数据集和评估度量数据集。我们首先回顾了封闭世界环境中广泛使用的数据集,包括11个图像数据集(VIPeR[31]、iLIDS[167]、GRID[168]、PRID2011[126]、CUHK0103[43]、Market-1501[5],DukeMTMC[42],Airport[169]和MSMT17[44])和7个视频数据集(PRID-2011[126],iLIDS-VID[7],MARS[8],Duke-Video[144],Duke-Tracklet[170]、LPW[171]和LS-VID[136])。这些数据集的统计数据如表2所示。本次调查仅关注深度学习方法的一般大规模数据集。可以在[169]及其网站1(https://github.com/NEU-Gou/awesome-reid-dataset)中找到对Re-ID数据集的全面总结。就近年来的数据集收集而言,可以提出几点意见:
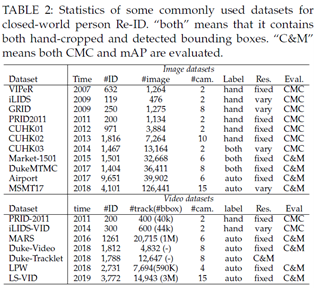
1)数据集规模(#image和#ID)迅速增加。一般来说,深度学习方法可以从更多的训练样本中受益。这也增加了封闭世界行人Re-ID所需的注释难度。2)摄像头数量也大幅增加,以逼近实际场景中的大规模摄像头网络。这也为动态更新网络中的模型泛化性带来了额外的挑战。3)边界框的生成通常是自动检测/跟踪的,而不是手动裁剪的。这模拟了具有跟踪/检测错误的真实场景。
评估指标。为了评估Re-ID系统,累积匹配特性(CMC)[68]和平均平均精度(mAP)[5]是两个广泛使用的测量方法。
CMC-k(又名,Rank-k匹配精度)[68]表示正确匹配出现在排名前k的检索结果中的概率。当每个查询只存在一个基本事实时,CMC是准确的,因为它只考虑评估过程中的第一个匹配项。但是,画廊集通常包含大型相机网络中的多个ground truths,CMC不能完全反映模型跨多个相机的可辨别性。
另一个指标,即平均平均精度(mAP)[5],衡量了多个真实情况的平均检索性能。它最初广泛用于图像检索。对于Re-ID评估,它可以解决两个系统在搜索第一个基本事实时表现相同的问题(可能很容易匹配,如图4所示),但对于其他硬匹配具有不同的检索能力。
考虑到训练Re-ID模型的效率和复杂性,最近的一些工作[138]、[139]还报告了每秒浮点操作数(FLOPs)和网络参数大小作为评估指标。当训练/测试设备的计算资源有限时,这两个指标至关重要。
2.4.2 深入分析 State-of-The-Arts我们从基于图像和基于视频的角度回顾了最先进的技术。我们包括过去三年在顶级CV场所发表的方法。
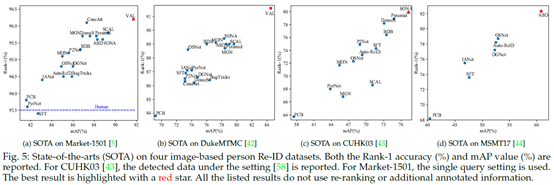
基于图像的Re-ID。基于图像的Re-ID2(https://paperswithcode.com/task/person-re-identification)已经发表了大量论文。我们主要回顾了2019年发表的作品以及2018年的一些代表性作品。具体包括PCB[77]、MGN[172]、PyrNet[6]、Auto-ReID[139]、ABD-Net[173]、BagTricks[122]、OSNet[138]、DGNet[119]、SCAL[90]、MHN[174]、P2Net[104]、BDB[124]、SONA[107]、SFT[95]、ConsAtt[93]、DenseS[103]、Pyramid[156]、IANet[108]、VAL[114]。我们总结了四个数据集的结果(图5)。该概述激发了五个主要见解,如下所述。
首先,随着深度学习的进步,大多数基于图像的Re-ID方法在广泛使用的Market-1501数据集上实现了比人类更高的rank-1准确率(93.5%[175])。特别是,VAL[114]在Market-1501数据集上获得了91.6%的最佳mAP和96.2%的Rank-1准确度。VAL的主要优点是使用视点信息。使用重新排序或度量融合时可以进一步提高性能。在这些封闭世界数据集上深度学习的成功也促使人们将重点转移到更具挑战性的场景,即大数据量[136]或无监督学习[176]。
其次,部件级级特征学习有利于判别式Re-ID模型学习。全局特征学习直接学习整个图像的表示,没有部件约束[122]。当人检测/跟踪可以准确定位人体时,它是有区别的。当人物图像遭受大背景杂乱或严重遮挡时,部分级特征学习通常通过挖掘有区别的身体区域来获得更好的性能[67]。由于其在处理错位/遮挡方面的优势,我们观察到最近开发的大多数最先进的方法都采用了特征聚合范式,结合了部分级和全身特征[139]、[156]。
第三,注意力有利于区分性的Re-ID模型学习。我们观察到在每个数据集上实现最佳性能的所有方法(ConsAtt[93]、SCAL[90]、SONA[107]、ABD-Net[173])都采用了注意力方案。注意力捕捉不同卷积通道、多个特征图、分层级、不同身体部位/区域甚至多个图像之间的关系。同时,判别性[173]、多样化[133]、一致[93]和高阶[107]属性被并入以增强注意力特征学习。考虑到强大的注意力方案和Re-ID问题的特殊性,专注的深度学习系统很有可能继续主导Re-ID社区,并具有更多特定领域的属性。
第四,多损失训练可以改善Re-ID模型的学习。不同的损失函数从多视图的角度优化网络。结合多个损失函数可以提高性能,最先进的方法中的多重损失训练策略证明了这一点,包括ConsAtt[93]、ABD-Net[173]和SONA[107]。此外,[156]中设计了一种动态多损失训练策略,以自适应地集成两个损失函数。身份损失和三元组损失与硬挖掘相结合是首选。此外,由于不平衡问题,样本加权策略通常通过挖掘信息丰富的三元组来提高性能[52]、[89]。
最后,由于数据集规模不断扩大、环境复杂、训练样本有限,还有很大的改进空间。例如,新发布的MSMT17数据集[44]上的Rank-1准确率(82.3%)和mAP(60.8%)远低于Market-1501(Rank1:96.2%和mAP91.7%)和DukeMTMC(Rank-1:91.6%和mAP84.5%)。在其他一些训练样本有限的具有挑战性的数据集上(例如,GRID[168]和VIPeR[31]),性能仍然非常低。此外,Re-ID模型通常在跨数据集评估[28]、[54]中受到严重影响,并且在对抗性攻击下性能急剧下降[177]。我们乐观地认为,Person Re-ID将会有重要的突破,具有更高的可辨别性、鲁棒性和普遍性。
基于视频的Re-ID。与基于图像的Re-ID相比,基于视频的Re-ID受到的关注较少。我们回顾了深度学习的Re-ID模型,包括CoSeg[132]、GLTR[136]、STA[135]、ADFD[110]、STC[20]、DRSA[133]、Snippet[134]、ETAP[144]、DuATM[91]、SDM[178]、TwoS[128]、ASTPN[131]、RQEN[171]、Forest[130]、RNN[127]和IDEX[8]。我们还总结了四个视频Re-ID数据集的结果,如图6所示。从这些结果中,可以得出以下观察结果。

首先,随着深度学习技术的发展,多年来可以看到性能提高的明显趋势。具体来说,在PRID-2011数据集上,Rank-1准确度从70%(RNN[127],2016年)提高到95.5%(GLTR[136],2019年);在iLIDS-VID数据集上,从58%(RNN[127])提高到86.3%(ADFD[110])。在大规模MARS数据集上,Rank-1准确率/mAP从68.3%/49.3%(IDEX[8])提高到88.5%/82.3%(STC[20])。在Duke-Video数据集[144]上,STA[135]的Rank-1准确率也达到了96.2%,mAP为94.9%。
其次,空间和时间建模对于判别式视频表示学习至关重要。我们观察到所有方法(STA[135]、STC[20]、GLTR[136])都设计了时空聚合策略来提高视频Re-ID性能。与基于图像的ReID类似,跨多帧[110]、[135]的注意力方案也大大增强了可辨别性。[20]中另一个有趣的观察表明,利用视频序列中的多个帧可以填充被遮挡区域,这为将来处理具有挑战性的遮挡问题提供了可能的解决方案。
最后,这些数据集的性能已经达到饱和状态,这四个视频数据集的准确度增益通常不到1%。但是,对于具有挑战性的案例,仍有很大的改进空间。例如,在新收集的视频数据集LS-VID[136]上,GLTR[136]的Rank1 accuracy/mAP只有63.1%/44.43%,而GLTR[136]可以达到state-of-the-art或至少在其他四个数据集上具有可比的性能。LS-VID[136]包含明显更多的身份和视频序列。这为基于视频的Re-ID的未来突破提供了具有挑战性的基准。
3、开放世界的行人再识别本节回顾第1节中讨论的开放世界行人Re-ID,包括通过跨异构模式匹配行人图像的异构Re-ID(第3.1节)、来自原始图像/视频的端到端Re-ID(第3.2节)、半/带有有限/不可用注释标签的无监督学习(第3.3节),具有噪声注释的鲁棒Re-ID模型学习(第3.4节)以及在图库中没有出现正确匹配时的开放集行人Re-ID(第3.5节)。
3.1 异构Re-ID本小节总结了四种主要的异构Re-ID,包括深度和RGB图像之间的Re-ID(第3.1.1节)、文本到图像的Re-ID(第3.1.2节)、可见到红外的Re-ID(§3.1.3)和交叉分辨率Re-ID(§3.1.4)。
3.1.1 基于深度的Re-ID深度图像捕捉身体形状和骨骼信息。这为在照明/换衣环境下进行Re-ID提供了可能性,这对于个性化的人类交互应用也很重要。[179]中提出了一种基于循环注意力的模型来解决基于深度的行人识别问题。在强化学习框架中,他们结合卷积和循环神经网络来识别人体的小的、有区别的局部区域。卡里亚纳基斯等人[180]利用大型RGB数据集设计了一种拆分率RGB到深度的传输方法,该方法弥合了深度图像和RGB图像之间的差距。他们的模型进一步结合了时间关注来增强深度Re-ID的视频表示。一些方法[62]、[181]还研究了RGB和深度信息的组合以提高Re-ID性能,解决换衣服的挑战。
3.1.2 文本到图像的Re-IDText-to-image Re-ID 解决了文本描述和RGB图像[63]之间的匹配问题。当无法获取查询人的视觉图像时,必须提供,只能提供文字描述。
具有循环神经网络的门控神经注意力模型[63]学习文本描述和人物图像之间的共享特征。这使得文本到图像行人检索的端到端训练成为可能。程等人[182]提出了一种全局判别图像-语言关联学习方法,在重建过程中捕获身份判别信息和局部重建图像-语言关联。交叉投影学习方法[183]还通过图像到文本匹配来学习共享空间。在[184]中设计了一个深度对抗图注意力卷积网络,其中包含图关系挖掘。然而,文本描述和视觉图像之间的巨大语义差距仍然具有挑战性。同时,如何将文字与手绘素描图像结合起来也值得今后研究。
3.1.3 可见红外Re-IDVisible-Infrared Re-ID处理白天可见光和夜间红外图像之间的交叉模态匹配。这在低光照条件下很重要,在这种情况下,图像只能由红外摄像机[21]、[60]、[185]捕获。
吴等人[21]通过提出一个深度零填充框架[21]来自适应地学习模态可共享特征,开始了解决这个问题的第一次尝试。在[142]、[186]中引入了一个双流网络来对模态共享和特定信息进行建模,同时解决模态内和跨模态的变化。除了交叉模态共享嵌入学习[187],分类器级别的差异也在[188]中进行了研究。最近的方法[189]、[190]采用GAN技术生成跨模态人物图像,以减少图像和特征级别的跨模态差异。[191]中对分层交叉模态解缠结因素进行了建模。[192]中提出了一种双注意力聚合学习方法来捕获多级关系。
3.1.4 交叉分辨率Re-IDCross-Resolution Re-ID在低分辨率和高分辨率图像之间进行匹配,解决大分辨率变化[13]、[14]。级联SR-GAN[193]以级联方式生成高分辨率人物图像,并结合身份信息。李等人[194]采用对抗学习技术来获得分辨率不变的图像表示。
3.2 端到端Re-ID端到端的Re-ID减轻了对生成边界框的额外步骤的依赖。它涉及从原始图像或视频中重新识别行人,以及多摄像头跟踪。
原始图像/视频中的重识别 此任务要求模型在单个框架中联合执行行人检测和重识别[55]、[64]。由于两个主要组成部分的侧重点不同,因此具有挑战性。
郑等人[55]提出了一个两阶段框架,并系统地评估了后期行人Re-ID的行人检测的好处和局限性。肖等人[64]使用单个卷积神经网络设计端到端行人搜索系统,用于联合行人检测和重新识别。开发了一种神经行人搜索机(NPSM)[195],通过充分利用查询和检测到的候选区域之间的上下文信息来递归地细化搜索区域并定位目标人。类似地,在图学习框架中学习上下文实例扩展模块[196]以改进端到端行人搜索。使用Siamese挤压和激励网络开发了一个查询引导的端到端行人搜索系统[197],以通过查询引导的区域提议生成来捕获全局上下文信息。[198]中引入了一种具有判别性Re-ID特征学习的定位细化方案,以生成更可靠的边界框。身份鉴别注意力强化学习(IDEAL)方法[199]为自动生成的边界框选择信息区域,从而提高Re-ID性能。
山口等人[200]研究一个更具挑战性的问题,即从带有文本描述的原始视频中搜索人。提出了一种时空人物检测和多模态检索的多阶段方法。预计沿着这个方向进一步探索。
多摄像头跟踪。端到端行人重识别也与多人、多摄像头跟踪密切相关[52]。为多人跟踪[201]提出了一种基于图的公式来链接人的假设,其中将整个人体和身体姿势布局的整体特征组合为每个人的表示。里斯塔尼等人[52]通过硬身份挖掘和自适应加权三元组学习来学习多目标多摄像机跟踪和行人Re-ID之间的相关性。最近,提出了一种具有相机内和相机间关系建模的局部感知外观度量(LAAM)[202]。
早期的无监督Re-ID主要学习不变的组件,即字典[203]、度量[204]或显着性[66],这导致可区分性或可扩展性有限。
对于深度无监督的方法,跨相机标签估计是一种流行的方法[176],[205]。动态图匹配(DGM)[206]将标签估计公式化为二分图匹配问题。为了进一步提高性能,利用全局相机网络约束[207]进行一致匹配。刘等人通过逐步度量提升[204]逐步挖掘标签。一种鲁棒的锚嵌入方法[83]迭代地将标签分配给未标记的轨迹,以扩大锚视频序列集。通过估计的标签,可以应用深度学习来学习Re-ID模型。
对于端到端无监督Re-ID,在[205]中提出了一种迭代聚类和Re-ID模型学习。类似地,样本之间的关系被用于层次聚类框架[208]。软多标签学习[209]从参考集中挖掘软标签信息以进行无监督学习。Tracklet Association无监督深度学习(TAUDL)框架[170]共同进行相机内tracklet关联并模拟跨相机tracklet相关性。类似地,一种无监督的相机感知相似性一致性挖掘方法[210]也在粗到细的一致性学习方案中提出。相机内挖掘和相机间关联应用于图关联框架[211]。可转移联合属性-身份深度学习(TJAIDL)框架[111]也采用了语义属性。然而,使用新到达的未标记数据进行模型更新仍然具有挑战性。
此外,一些方法还尝试基于观察到局部部分的标签信息比整个图像更容易挖掘标签信息来学习部分级表示。PatchNet[153]旨在通过挖掘补丁级别的相似性来学习有区别的补丁特征。自相似分组(SSG)方法[212]以自定进度的方式迭代地进行分组(利用全局身体和局部部位的相似性进行伪标记)和Re-ID模型训练。
半/弱监督Re-ID。 在标签信息有限的情况下,[213]中提出了一种一次性度量学习方法,该方法结合了深度纹理表示和颜色度量。[144]中提出了一种基于视频的Re-ID逐步单次学习方法(EUG),逐渐从未标记的轨迹中选择一些候选者来丰富标记的轨迹集。多实例注意力学习框架[214]使用视频级标签进行表示学习,减轻了对完整注释的依赖。
3.3.2 无监督域自适应无监督域适应(UDA)将标记的源数据集上的知识转移到未标记的目标数据集[53]。由于源数据集中的大域转移和强大的监督,它是另一种没有目标数据集标签的无监督Re-ID的流行方法。
目标图像生成。使用GAN生成将源域图像转换为目标域样式是UDA Re-ID的一种流行方法。使用生成的图像,这可以在未标记的目标域中进行有监督的Re-ID模型学习。魏等人[44]提出了一种行人迁移生成对抗网络(PTGAN),将知识从一个标记的源数据集传输到未标记的目标数据集。保留的自相似性和域相异性[120]使用保留相似性的生成对抗网络(SPGAN)进行训练。异构学习(HHL)方法[215]同时考虑了同质学习的相机不变性和异构学习的域连通性。自适应传输网络[216]将自适应过程分解为某些成像因素,包括光照、分辨率、相机视图等。这种策略提高了跨数据集的性能。黄等人[217]尝试抑制背景偏移以最小化域偏移问题。陈等人[218]设计了一种实例引导的上下文渲染方案,将人的身份从源域转移到目标域中的不同上下文中。此外,还添加了一个姿势解纠缠方案来改进图像生成[121]。在[219]中还开发了一种相互平均教师学习方案。然而,实际大规模变化环境的图像生成的可扩展性和稳定性仍然具有挑战性。
巴克等人[125]生成具有不同照明条件的合成数据集,以模拟真实的室内和室外照明。合成的数据集增加了学习模型的泛化性,并且可以很容易地适应新的数据集而无需额外的监督[220]。
目标域监督挖掘。一些方法使用来自源数据集的训练有素的模型直接挖掘对未标记目标数据集的监督。示例记忆学习方案[106]将三个不变线索视为监督,包括示例不变性、相机不变性和邻域不变性。域不变映射网络(DIMN)[28]为域迁移任务制定了一个元学习管道,并在每个训练集对源域的一个子集进行采样以更新内存库,从而增强可扩展性和可辨别性。摄像机视图信息也在[221]中用作监督信号以减少域间隙。一种具有渐进增强的自我训练方法[222]联合捕获目标数据集上的局部结构和全局数据分布。最近,一种具有混合记忆的自定进度对比学习框架[223]取得了巨大成功,它可以动态生成多级监督信号。
时空信息也被用作TFusion[224]中的监督。TFusion使用贝叶斯融合模型将在源域中学习到的时空模式转移到目标域。同样,开发了Query Adaptive Convolution(QAConv)[225]以提高跨数据集的准确性。
3.3.3 无监督Re-ID SOTA近年来,无监督Re-ID获得了越来越多的关注,顶级CV的出版物数量不断增加就是明证。我们回顾了SOTA在两个广泛使用的基于图像的Re-ID数据集上的无监督深度学习方法。结果总结在表3中。从这些结果中,可以得出以下见解。
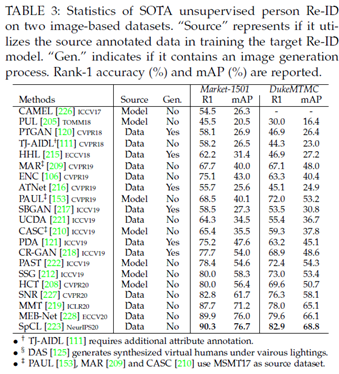
首先,无监督的Re-ID性能多年来显着提高。Market-1501数据集的Rank-1准确率/mAP在三年内从54.5%/26.3%(CAMEL[226])增加到90.3%/76.7%(SpCL[223])。DukeMTMC数据集的性能从30.0%/16.4%提高到82.9%/68.8%。监督和无监督学习之间的差距显着缩小。这证明了无监督Re-ID与深度学习的成功。
其次,目前的无监督Re-ID仍然不发达,可以在以下方面进一步改进:1)有监督的ReID方法中强大的注意力方案很少应用于无监督的ReID。2)目标域图像生成已在某些方法中被证明是有效的,但它们并未应用于两种最佳方法(PAST[222],SSG[212])。3)在目标域的训练过程中使用带注释的源数据有利于跨数据集学习,但也不包括在上述两种方法中。这些观察结果为进一步改进提供了潜在基础。
第三,无监督和有监督的Re-ID之间仍然存在很大差距。例如,有监督的ConsAtt[93]在Market1501数据集上的rank-1准确率已达到96.1%,而无监督SpCL[223]的最高准确率约为90.3%。最近,何等人[229]已经证明,具有大规模未标记训练数据的无监督学习能够在各种任务上优于监督学习[230]。我们预计未来无监督Re-ID会取得一些突破。
3.4 噪声鲁棒的Re-ID由于数据收集和注释困难,Re-ID通常会遇到不可避免的噪声。我们从三个方面回顾了噪声鲁棒性Re-ID:具有严重遮挡的Partial Re-ID、具有由检测或跟踪错误引起的样本噪声的Re-ID,以及具有由注释错误引起的标签噪声的Re-ID。
Partial Re-ID。这解决了重度遮挡的Re-ID问题,即只有人体的一部分是可见的[231]。采用全卷积网络[232]为不完整的人物图像生成固定大小的空间特征图。深度空间特征重建(DSR)被进一步结合,以避免通过利用重建误差进行显式对齐。孙等人[67]设计了一个可见性感知零件模型(VPM)来提取可共享的区域级特征,从而抑制不完整图像中的空间错位。前景感知金字塔重建方案[233]也试图从未被遮挡的区域中学习。Pose-Guided Feature Alignment(PGFA)[234]利用姿势界标从遮挡噪声中挖掘有区别的部分信息。然而,由于严重的部分错位、不可预测的可见区域和分散注意力的未共享身体区域,它仍然具有挑战性。同时,如何针对不同的查询自适应地调整匹配模型仍需进一步研究。
使用样本噪声重新识别。这是指人物图像或视频序列包含边缘区域/帧的问题,这可能是由于检测不佳/跟踪结果不准确造成的。为了处理人物图像中的外围区域或背景杂乱,利用了姿势估计线索[17]、[18]或注意力线索[22]、[66]、[199]。基本思想是抑制噪声区域在最终整体表示中的贡献。对于视频序列,集级特征学习[83]或帧级重新加权[134]是减少噪声帧影响的常用方法。侯等人[20]还利用多个视频帧来自动完成遮挡区域。预计未来会有更多特定领域的样本噪声处理设计。
使用标签噪声重识别。由于标注错误,标签噪声通常是不可避免的。郑等人采用标签平滑技术来避免标签过度拟合问题[42]。[235]中提出了一种对特征不确定性进行建模的分布网络(DNet),用于针对标签噪声进行稳健的Re-ID模型学习,从而减少具有高特征不确定性的样本的影响。与一般分类问题不同,鲁棒的Re-ID模型学习受到每个身份的训练样本有限[236]的影响。此外,未知的新身份增加了鲁棒Re-ID模型学习的额外难度。
3.5 开放集Re-ID及其他Open-set Re-ID 通常被表述为一个人验证问题,即区分两个人图像是否属于同一身份[69]、[70]。验证通常需要学习条件,即sim(query;gallery)>T。早期的研究设计了手工系统[26]、[69]、[70]。对于深度学习方法,[237]中提出了Adversarial PersonNet(APN),它联合学习了GAN模块和Re-ID特征提取器。该GAN的基本思想是生成逼真的类似目标的图像(冒名顶替者)并强制特征提取器对生成的图像攻击具有鲁棒性。[235]中还研究了建模特征不确定性。然而,实现高真实目标识别并保持低错误目标识别率仍然相当具有挑战性[238]。
组重识别。 它旨在将人与群体而不是个人联系起来[167]。早期的研究主要集中在稀疏字典学习[239]或协方差描述符聚合[240]的组表示提取上。多粒度信息集成在[241]中,以充分捕捉群体的特征。最近,图卷积网络被应用在[242]中,将组表示为一个图。组相似性也应用于端到端行人搜索[196]和个体重新识别[197]、[243]以提高准确性。然而,组Re-ID仍然具有挑战性,因为组变化比个体更复杂。
动态多摄像机网络。 动态更新的多相机网络是另一个具有挑战性的问题[23]、[24]、[27]、[29],它需要对新相机或探测器进行模型调整。[24]中引入了一种人工在环增量学习方法来更新Re-ID模型,使表示适应不同的探针库。早期研究还将主动学习[27]应用于多摄像头网络中的连续Re-ID。[23]中介绍了一种基于稀疏非冗余代表选择的连续自适应方法。传递推理算法[244]旨在利用基于测地线流内核的最佳源相机模型密集人群和社会关系中的多个环境约束(例如,相机拓扑)被集成到一个开放世界的行人Re-ID系统[245]。摄像机的模型适应和环境因素在实际的动态多摄像机网络中至关重要。此外,如何将深度学习技术应用于动态多摄像头网络的研究还较少。
4、展望:下一个时代的重新识别本节首先在第4.1节中介绍了一个新的评估指标,然后介绍行人Re-ID的强基线(在第4.2节中)。它为未来的Re-ID研究提供了重要的指导。最后,我们将在第4.3节中讨论一些未充分调查的未解决问题。
4.1 mINP:一种新的Re-ID评估指标
对于一个好的Re-ID系统,目标人应该被尽可能准确地检索到,即所有正确的匹配应该具有低排名值。考虑到目标人物在排名靠前的检索列表中不应被忽视,尤其是对于多摄像头网络,从而准确跟踪目标。当目标人物出现在多个时间戳集合中时,最难正确匹配的排名位置决定了检查员进一步调查的工作量。然而,目前广泛使用的CMC和mAP指标无法评估该属性,如图7所示。在相同的CMC下,rank list 1比rank list 2获得更好的AP,但需要更多的努力才能找到所有正确的匹配项.为了解决这个问题,我们设计了一种计算效率高的度量,即负惩罚(NP),它测量惩罚以找到最难的正确匹配
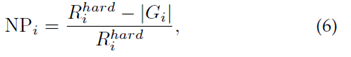
其中Rhardi表示最难匹配的排名位置,|Gi|表示查询i的正确匹配总数。自然,较小的NP代表更好的性能。为了与CMC和mAP保持一致,我们更喜欢使用逆负惩罚(INP),它是NP的逆运算。总体而言,所有查询的平均INP表示为
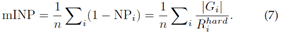
mINP的计算非常高效,可以无缝集成到CMC/mAP计算过程中。mINP避免了mAP/CMC评估中容易匹配的支配。一个限制是与小型画廊相比,大型画廊的mINP值差异会小得多。但它仍然可以反映Re-ID模型的相对性能,为广泛使用的CMC和mAP指标提供补充。
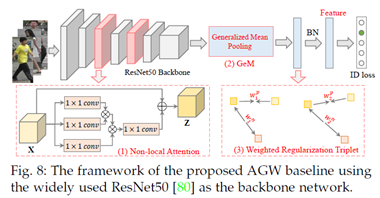
4.2 单/跨模态重识别的新基线根据第2.4.2节中的讨论,我们为person Re-ID设计了一个新的AGW3基线,它在单模态(图像和视频)和跨模态Re-ID任务上都取得了竞争性能。具体来说,我们的新基线是在BagTricks[122]之上设计的,AGW包含以下三个主要改进组件:
(1)非局部注意力(Att)块。如第2.4.2节所述,注意方案在判别式Re-ID模型学习中起着至关重要的作用。我们采用强大的非局部注意力块[246]来获得所有位置特征的加权和,表示为
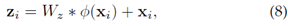
其中Wz是要学习的权重矩阵,∅(∙)表示非局部操作,+xi制定残差学习策略。细节可以在[246]中找到。我们采用[246]中的默认设置来插入非局部注意力块。
(2)广义平均(GeM)池化。作为细粒度的实例检索,广泛使用的最大池化或平均池化无法捕获特定领域的判别特征。我们采用了一个可学习的池化层,称为广义均值(GeM)池化[247],其公式为
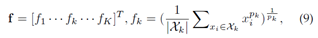
其中fk表示特征图,K是最后一层中特征图的数量。Xk是特征图k∈{1,2,…,K}的WxH激活集;pk是一个池化超参数,在反向传播过程中学习[247]。当p_k→∞时,上述操作近似于最大池化,当p_k=1时,上述操作近似于平均池化。
(3)加权正则化三元组(WRT)损失。除了使用softmax交叉熵的基线身份损失之外,我们还集成了另一个加权正则化三元组损失:
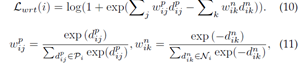
其中(I,j,k)表示每个训练批次中的硬三元组。对于anchor i,Pi是对应的正集,Ni是负集。dpij/dnik表示正/负样本对的成对距离。上述加权正则化继承了正负对之间相对距离优化的优点,但它避免引入任何额外的边距参数。我们的加权策略类似于[248],但我们的解决方案没有引入额外的超参数。
AGW的总体框架如图8所示。其他组件与[122]完全相同。在测试阶段,采用BN层的输出作为Re-ID的特征表示。实施细节和更多实验结果在补充材料中。
单模态图像重识别结果。我们首先在表4中的基于图像的两个数据集(Market1501和DukeMTMC)上评估每个组件。我们还列出了两种最先进的方法,BagTricks[122]和ABD-Net[173]。我们在表5中报告了CUHK03和MSMT17数据集的结果。我们获得了以下两个观察结果:
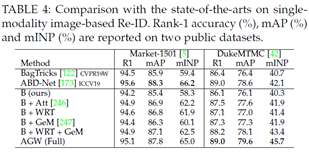
1)所有组件始终有助于提高准确性,并且AGW在各种指标下的表现都比原始BagTricks好得多。AGW为未来的改进提供了强有力的基准。我们还尝试结合部件级特征学习[77],但大量实验表明它并没有提高性能。如何将part-level的特征学习与AGW进行聚合,未来需要进一步研究。
2)与当前最先进的ABD-Net[173]相比,AGW在大多数情况下表现良好。特别是,我们在DukeMTMC数据集上实现了更高的mINP,分别为45.7%和42.1%。这表明AGW找到所有正确匹配项所需的工作更少,验证了mINP的能力。

单模态视频重识别结果。我们还在广泛使用的基于单模态视频的四个数据集(MARS[8]、DukeVideo[144]、PRID2011[126]和iLIDS-VID[7])上评估了提议的AGW,如表6所示。我们还比较了两种状态最先进的方法,BagTricks[122]和Co-Seg[132]。对于视频数据,我们开发了一个变体(AGW+)来捕获时间信息,通过帧级平均池化来进行序列表示。同时,约束随机抽样策略[133]用于训练。与Co-Seg[132]相比,我们的AGW+在大多数情况下获得了更好的Rank-1、mAP和mINP。
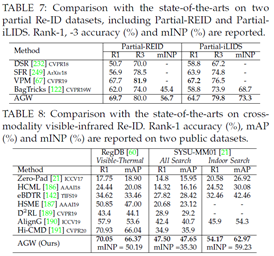
Partial Re-ID的结果。我们还在两个Partial Re-ID数据集上测试了AGW的性能,如表7所示。实验设置来自DSR[232]。我们还使用最先进的VPM方法[67]实现了可比的性能。该实验进一步证明了AGW在开放世界Partial Re-ID任务中的优越性。同时,mINP也展示了这个开放世界Re-ID问题的适用性。
跨模态重识别的结果。我们还在跨模态可见红外Re-ID任务上使用双流架构测试了AGW的性能。在两个数据集上与当前最先进技术的比较如表8所示。我们按照AlignG[190]中的设置进行实验。结果表明,AGW比现有的跨模态Re-ID模型实现了更高的准确度,验证了开放世界Re-ID任务的有效性。
 4.3 未充分调查的未解决问题
4.3 未充分调查的未解决问题
我们根据§1中的五个步骤从五个不同方面讨论开放问题,包括不可控的数据收集、人工注释最小化、特定领域/可概括的架构设计、动态模型更新和高效模型部署。
4.3.1 不可控的数据收集大多数现有的Re-ID作品在定义明确的数据收集环境中评估他们的方法。然而,真实复杂环境中的数据采集是不可控的。数据可能是从不可预测的模态、模态组合,甚至是换衣数据中获取的[30]。
多异构数据。在实际应用中,ReID数据可能是从多种异构模态中捕获的,即人物图像的分辨率变化很大[193],查询集和图库集可能包含不同的模态(可见、热[21]、深度[62]或文字描述[10])。这导致了具有挑战性的多个异类行人Re-ID。一个好的行人重识别系统将能够自动处理不断变化的分辨率、不同的模式、各种环境和多个领域。预计未来的工作具有广泛的普遍性,评估他们针对不同Re-ID任务的方法。
换装数据。在实际的监控系统中,很可能会包含大量正在换衣服的目标行人。服装变化感知网络(CCAN)[250]通过分别提取面部和身体上下文表示来解决这个问题,并且在[251]中应用了类似的想法。杨等人[30]提出了一种空间极坐标变换(SPT)来学习跨服装不变表示。但是,它们仍然严重依赖面部和身体外观,这在实际场景中可能不可用且不稳定。进一步探索其他判别线索(例如步态、形状)来解决换布问题的可能性会很有趣。
4.3.2 人工注释最小化除了无监督学习,主动学习或人机交互[24]、[27]、[154]、[159]提供了另一种可能的解决方案来减轻对人工注释的依赖。
主动学习。结合人工交互,可以轻松地为新到达的数据提供标签,并且可以随后更新模型[24]、[27]。成对子集选择框架[252]通过首先构建一个边加权的完整kpartite图,然后将其作为一个无三角形子图最大化问题来解决,从而最大限度地减少了人工标记工作。沿着这条线,深度强化主动学习方法[154]迭代地改进学习策略,并在人工环内监督下训练一个Re-ID网络。对于视频数据,设计了一种具有顺序决策的可解释强化学习方法[178]。主动学习在实际的Re-ID系统设计中至关重要,但在研究界却很少受到关注。此外,即使对人类来说,新出现的身份也极具挑战性。未来有望实现高效的人类在环主动学习。
学习虚拟数据。这为最小化人工注释提供了替代方案。在[220]中收集了一个合成数据集进行训练,当在这个合成数据集上训练时,它们在真实世界的数据集上取得了有竞争力的表现。巴克等人[125]生成具有不同照明条件的新合成数据集,以模拟逼真的室内和室外照明。在[105]中收集了一个大规模的合成PersonX数据集,以系统地研究视点对行人Re-ID系统的影响。最近,[253]还研究了3D人物图像,从2D图像生成3D身体结构。然而,如何弥合合成图像和真实世界数据集之间的差距仍然具有挑战性。
4.3.3 特定领域/通用架构设计Re-ID特定架构。现有的Re-ID方法通常采用为图像分类设计的架构作为主干。一些方法修改架构以实现更好的Re-ID功能[82]、[122]。最近,研究人员已经开始设计特定领域的架构,例如具有全方位特征学习的OSNet[138]。它在一定尺度上检测小尺度的判别特征。OSNet是极其轻量级的并且实现了具有竞争力的性能。随着自动神经架构搜索(例如,Auto-ReID[139])的进步,更多特定领域的强大架构有望解决特定于任务的Re-ID挑战。Re-ID中有限的训练样本也增加了架构设计的难度。
域可泛化的Re-ID。众所周知,不同数据集[56]、[225]之间存在很大的域差距。大多数现有方法采用域适应进行跨数据集训练。一个更实用的解决方案是学习具有多个源数据集的域泛化模型,这样学习的模型可以推广到新的未见数据集,以进行有区别的ReID,而无需额外的训练[28]。胡等人[254]通过引入部件级CNN框架研究了跨数据集的行人Re-ID。Domain-Invariant Mapping Network (DIMN)[28]设计了一个用于域可泛化Re-ID的元学习管道,学习人物图像与其身份分类器之间的映射。域泛化性对于在未知场景下部署学习到的Re-ID模型至关重要。
4.3.4 动态模型更新固定模型不适用于实际的动态更新监控系统。为了缓解这个问题,动态模型更新势在必行,无论是针对新域/相机还是适应新收集的数据。
模型适应新领域/相机。模型适应新领域已在文献中被广泛研究为领域适应问题[125],[216]。在实际的动态摄像机网络中,新的摄像机可能会临时插入到现有的监控系统中。
模型适应对于多摄像头网络中的连续识别至关重要[23]、[29]。为了使学习模型适应新相机,传递推理算法[244]旨在利用基于测地线流内核的最佳源相机模型。但是,当新相机新收集的数据具有完全不同的分布时,仍然具有挑战性。此外,隐私和效率问题[255]也需要进一步考虑。
使用新到达的数据更新模型。使用新收集的数据,从头开始训练先前学习的模型是不切实际的[24]。在[24]中设计了一种增量学习方法以及人类交互。对于深度学习的模型,将使用协方差损失[256]的加法集成到整体学习功能中。然而,由于深度模型训练需要大量的训练数据,这个问题没有得到很好的研究。此外,新到达的数据中未知的新身份难以识别用于模型更新。
4.3.5 高效的模型部署设计高效且自适应的模型以解决实际模型部署的可扩展性问题非常重要。
快速重识别。为了快速检索,哈希算法已被广泛研究以提高搜索速度,近似于最近邻搜索[257]。跨相机语义二进制变换(CSBT)[258]将原始的高维特征表示转换为紧凑的低维身份保持二进制代码。在[259]中开发了一种粗到细(CtF)哈希码搜索策略,互补地使用短码和长码。但是,特定领域的哈希算法仍然需要进一步研究。
轻量级模型。解决可扩展性问题的另一个方向是设计一个轻量级的Re-ID模型。在[86][138]、[139]中研究了修改网络架构以实现轻量级模型。模型蒸馏是另一种方法,例如,在[260]中提出了一种多教师自适应相似性蒸馏框架,该框架从多个教师模型中学习用户指定的轻量级学生模型,而无需访问源域数据。
资源感知重识别。根据硬件配置自适应地调整模型也提供了处理可扩展性问题的解决方案。Deep Anytime ReID(DaRe)[14]采用简单的基于距离的路由策略来自适应地调整模型,以适应具有不同计算资源的硬件设备。
5、结束语本文从封闭世界和开放世界的角度进行了全面调查,并进行了深入分析。我们首先从特征表示学习、深度度量学习和排名优化三个方面介绍封闭世界设置下广泛研究的Person Re-ID。借助强大的深度学习,封闭世界行人Re-ID在多个数据集上实现了性能饱和。相应地,开放世界的设置最近受到越来越多的关注,努力应对各种实际挑战。我们还设计了一个新的AGW基线,它在各种指标下的四个Re-ID任务上实现了具有竞争力的性能。它为未来的改进提供了强有力的基准。该调查还引入了一个新的评估指标来衡量找到所有正确匹配项的成本。我们相信这项调查将为未来的Re-ID研究提供重要的指导。
应用材料这份补充材料与我们的主要手稿一起提供了实施细节和更全面的实验。我们首先介绍了两个单模态封闭世界Re-ID任务的实验,包括A节中四个数据集上的基于图像的Re-ID和B节中四个数据集上的基于视频的Re-ID。然后我们介绍了在两个开放世界的Re-ID任务,包括C节中两个数据集上的可见红外跨模态ReID和D节中两个数据集上的Partial Re-ID。此外,最后总结了我们调查的结构概述。
A.基于单模态图像的Re-ID实验架构设计。我们提出的用于单模态Re-ID的AGW基线的整体结构(https://github.com/mangye16/ReID-Survey)在第4节(图R1)中进行了说明。我们采用在ImageNet上预训练的ResNet50作为我们的骨干网络,并将全连接层的维度更改为与训练数据集中的身份数量一致。骨干网络中最后一次空间下采样操作的步幅从2变为1。因此,当输入分辨率为256x128的图像时,输出特征图的空间大小从8x4变为16x8。在我们的方法中,我们将原始ResNet50中的全局平均池化替换为广义均值(GeM)池化。广义均值池化的池化超参数pk初始化为3.0。一个名为BNNeck的BatchNorm层插入在GeM池化层和全连接层之间。训练阶段采用GeM池化层的输出计算中心损失和三元组损失,而测试推理阶段使用BNNeck后的特征计算行人图像之间的距离。
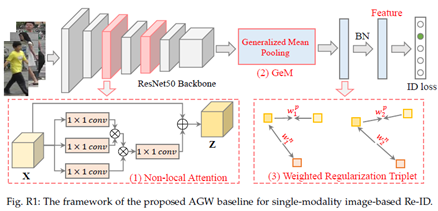
非局部注意力。ResNet包含4个残差阶段,即conv2_x、conv3_x、conv4_x和conv5_x,每个阶段都包含瓶颈残差块的堆栈。我们分别在conv3_3、conv3_4、conv4_4、conv4_5和conv4_6之后插入了五个非本地块。我们在实验中采用了瓶颈为512个通道的非本地块的点积版本。对于每个非局部块,在表示Wz的最后一个线性层之后添加一个BatchNorm层。这个BatchNorm层的仿射参数被初始化为零,以确保非局部块可以插入到任何预训练的网络中,同时保持其初始行为。
训练策略。在训练阶段,我们随机抽取16个身份和每个身份的4张图像,形成大小为64的mini-batch。每张图像被调整为256x128个像素,用0填充10个像素,然后随机裁剪成256x128像素。数据增强也分别采用了0.5概率的随机水平翻转和随机擦除。
具体来说,随机擦除增强[123]随机选择一个面积比为re的矩形区域与整个图像,并用图像的平均值擦除其像素。此外,该区域的纵横比在r1和r2之间随机初始化。在我们的方法中,我们将上述超参数设置为0.02<re<0.4,r1=0.3和r2=3.33。最后,我们对每幅图像的RGB通道进行归一化,均值分别为0.485、0.456、0.406,标准偏差分别为0.229、0.224、0.225,与[122]中的设置相同。
训练损失。在训练阶段,结合三种损失进行优化,包括身份分类损失(Lid)、中心损失(Lct)和我们提出的加权正则化三元组损失(Lwrt)。
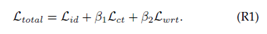
中心损失(1)的平衡权重设置为0.0005,加权正则化三元组损失的权重(2)设置为1.0。采用标签平滑来改善原始身份分类损失,这鼓励模型在训练过程中不那么自信,并防止过度拟合分类任务。具体来说,它将one-hot标签更改如下:
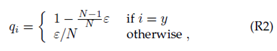
其中N是身份总数,是一个小常数,用于降低真实身份标签y的置信度,qi被视为训练的新分类目标。在我们的方法中,我们设置为0.1。
优化器设置。采用权重衰减0.0005的Adam优化器来训练我们的模型。初始学习率设置为0.00035,在第40轮和第70轮分别降低0.1。该模型总共训练了120个epoch。此外,还采用了预热学习率方案来提高训练过程的稳定性并引导网络以获得更好的性能。
具体来说,在前10个epoch中,学习率从3.5e-5线性增加到3.5e-4。Epoch t的学习率lr(t)可以计算为:
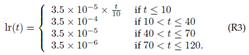 B.基于视频的Re-ID实验
B.基于视频的Re-ID实验
实施细节。我们通过对基于单模图像的Re-ID模型的主干结构和训练策略进行一些小的更改,将我们提出的AGW基线扩展到基于视频的Re-ID模型。基于视频的AGW基线将视频序列作为输入并提取帧级特征向量,然后在BNNeck层之前将其平均为视频级特征向量。此外,基于视频的AGW基线总共训练了400个epoch,以更好地拟合视频人物Re-ID数据集。学习率每100个epoch衰减10倍。为了形成输入视频序列,我们采用约束随机采样策略[133]采样4帧作为原始行人轨迹的摘要。BagTricks[122]基线以与AGW基线相同的方式扩展到基于视频的Re-ID模型,以进行公平比较。此外,我们还开发了AGW基线的变体,称为AGW+,用于对行人轨迹中更丰富的时间信息进行建模。AGW+基线在测试阶段采用密集采样策略形成输入视频序列。密集采样策略将行人轨迹中的所有帧组成输入视频序列,从而获得更好的性能但更高的计算成本。为了进一步提高AGW+baseline在视频re-ID数据集上的性能,我们还移除了预热学习率策略,并在线性分类层之前添加了dropout操作。
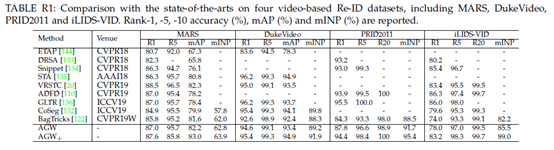
详细比较。在本节中,我们将AGW基线与其他最先进的基于视频的行人Re-ID方法进行性能比较,包括ETAP[144]、DRSA[133]、STA[135]Snippet[134]、VRSTC[20]、ADFD[110]、GLTR[136]和CoSeg[132]。表R1列出了四个视频人Re-ID数据集(MARS、DukeVideo、PRID2011和iLIDS-VID)的比较结果。我们可以看到,通过简单地将视频序列作为输入并采用平均池化来聚合帧级特征,我们的AGWbaseline在MARS和DukeVideo这两个大规模视频Re-ID数据集上取得了有竞争力的结果。此外,AGW基线在多个评估指标下的表现也明显优于BagTricks[122]基线。通过进一步建模更多的时间信息和调整训练策略,AGW+基线获得了巨大的改进,并且在PRID2011和iLIDS-VID数据集上也取得了有竞争力的结果。AGW+基线在MARS、DukeVideo和PRID2011数据集上优于大多数最先进的方法。这些基于视频的行人重识别方法中的大多数通过设计复杂的时间注意机制来利用行人视频中的时间依赖性来实现最先进的性能。我们相信我们的AGW基线可以帮助视频Re-ID模型通过适当设计的机制实现更高的性能,以进一步利用空间和时间依赖性。
 C. 跨模态重识别实验
C. 跨模态重识别实验
架构设计。我们采用双流网络结构作为跨模态可见红外ReID5(https://github.com/mangye16/Cross-Modal-Re-ID-baseline)的主干。与单模态人Re-ID中的单流架构(图8)相比,主要区别在于,即第一个块特定于两种模态以捕获特定于模态的信息,而其余块是共享的学习模态共享特征。与[142]、[261]中广泛使用的只有一个共享嵌入层的双流结构相比,我们的设计捕获了更多可共享的组件。图R2显示了跨模态可见红外Re-ID的图示。
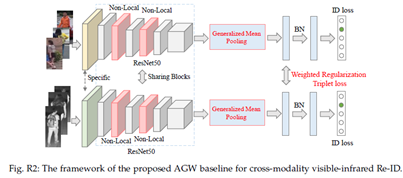
训练策略。在每个训练步骤中,我们从整个数据集中随机抽取8个身份。然后为每个身份随机选择4个可见图像和4个红外图像。总共,每个训练批次包含32个可见图像和32个红外图像。这保证了从两种模态中进行信息丰富的硬三元组挖掘,即,我们直接从模态内和模态间选择硬阳性和阴性。这近似于双向中心约束顶级损失的想法,同时处理模态间和模态内的变化。
为了公平比较,我们完全按照[142]中的设置进行图像处理和数据增强。对于红外图像,我们保留原来的三个通道,就像可见的RGB图像一样。两种模式的所有输入图像首先调整为288x144,并采用零填充随机裁剪和随机水平翻转进行数据论证。两种模态的裁剪图像大小均为256x128。图像归一化完全遵循单模态设置。
训练损失。在训练阶段,我们结合了身份分类损失(Lid)和我们提出的加权正则化三元组损失(Lwrt)。将身份损失和加权正则化三元组损失相结合的权重设置为1,与单模态设置相同。池化参数pk设置为3。为了稳定训练,我们对两种异构模式采用相同的身份分类器,挖掘可共享的信息。
优化器设置。我们在两个数据集上将初始学习率设置为0.1,并在20和50个epoch分别将其衰减0.1和0.01。训练epoch的总数为60。我们还采用了预热学习率方案。我们采用随机梯度下降(SGD)优化器进行优化,动量参数设置为0.9。我们在跨模态Re-ID任务上尝试了相同的Adam优化器(用于单模态Re-ID),但由于使用大的学习率,性能远低于SGD优化器。这是至关重要的,因为对红外图像采用了ImageNet初始化。
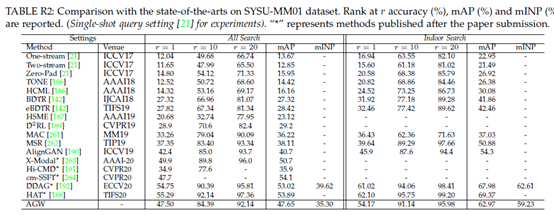
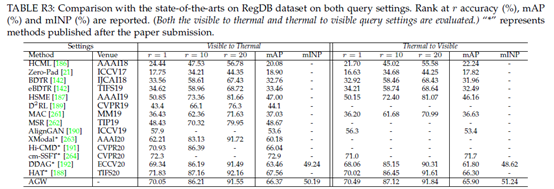
详细比较。本节与最先进的跨模态VI-ReID方法进行比较,包括eBDTR[142]、HSME[187]、D2RL[189]、MAC[261]、MSR[262]和对齐GAN[190]。这些方法是在过去两年中发表的。AlignGAN[190]发表于ICCV2019,通过将特征级别和像素级别的交叉模态表示与GAN生成的图像对齐,实现了最先进的性能。两个数据集的结果显示在表R2和R3中。我们观察到,所提出的AGW始终优于当前最先进的技术,而无需耗时的图像生成过程。对于RegDB数据集上的不同查询设置,我们提出的基线通常保持相同的性能。我们提出的基线已广泛用于许多最近开发的方法中。我们相信我们的新基线将为提升跨模式Re-ID提供良好的指导。
 D. Partial Re-ID实验
D. Partial Re-ID实验
实施细节。我们还评估了我们提出的AGW基线在两个常用的Partial Re-ID数据集Partial-REID和Partial-iLIDS上的性能。Re-ID AGW基线模型的整体骨干结构和训练策略与基于单模态图像的Re-ID模型相同。Partial-REID和Partial-iLIDS数据集都只提供查询图像集和图库图像集。因此,我们在Market-1501数据集的训练集上训练AGW基线模型,然后在两个Partial Re-ID数据集的测试集上评估其性能。我们采用相同的方法来评估BagTricks[122]基线在这两个Partial Re-ID数据集上的性能,以便更好地进行比较和分析。
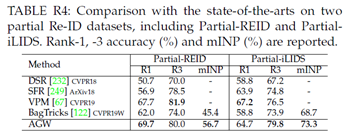
详细比较。我们将AGW基线的性能与其他最先进的Partial Re-ID方法进行了比较,包括DSR[232]、SFR[249]和VPM[67]。所有这些方法都是近年来发表的。Partial-REID和Partial-iLIDS数据集的比较结果如表R4所示。VPM[67]通过自我监督感知区域的可见性并提取区域级特征,实现了非常高的性能。仅考虑全局特征,与两个数据集上的当前最先进技术相比,我们提出的AGW基线仍然取得了具有竞争力的结果。此外,与BagTricks[122]相比,AGW基线在多个评估指标下带来了显着的改进,证明了它对Partial Re-ID问题的有效性。
 E. 本次调查概述
E. 本次调查概述
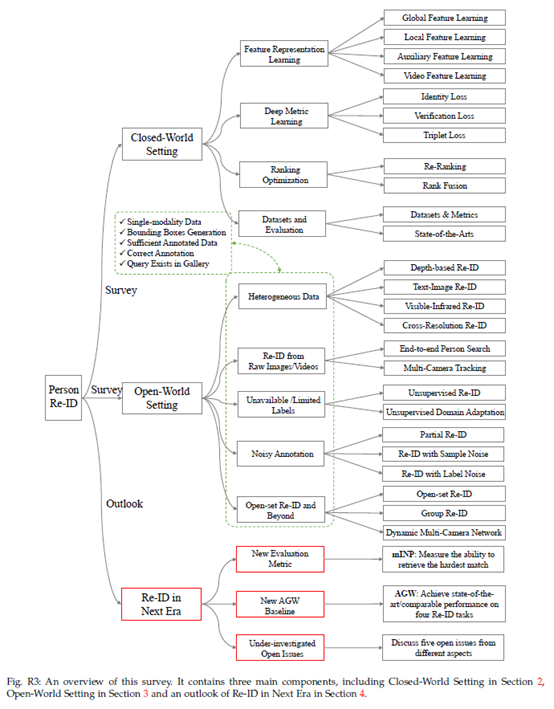
本次调查总览图如图R3 所示。根据开发行人Re-ID系统的五个步骤,我们在封闭世界和开放世界设置中进行了调查。封闭世界设置在三个不同方面进行了详细说明:特征表示学习、深度度量学习和排名优化。然后,我们从基于图像和视频的角度总结数据集和SOTA。对于开放世界的人Re-ID,我们将其总结为五个方面:包括异构数据、来自原始图像/视频的Re-ID、不可用/有限的标签、嘈杂的注释和开放集的Re-ID。
在总结之后,我们提出了对未来行人Re-ID的展望。我们设计了一个新的评估指标(mINP)来评估找到所有正确匹配项的难度。通过分析现有Re-ID方法的优势,我们为未来的发展开发了强大的AGW基线,在四个Re-ID任务上实现了竞争性能。最后,讨论了一些研究不足的未解决问题。我们的调查全面总结了不同子任务中现有的最新技术。
同时,对未来发展方向进行分析,以供进一步发展指导。
Acknowledgement.作者要感谢匿名审稿人提供宝贵的反馈意见,以提高本次调查的质量。作者还要感谢行人重新识别和其他相关领域的先驱研究人员。本作品由CAAI-HuaweiMindSpore开放基金赞助。