ICLR2019。作者单位CMU(Google brain),DeepMind。
解决的问题主要解决的是NAS(神经网络架构搜索)的可扩展性的问题。其实主要解决的就是神经网络搜索计算量要求大、效果并不一定很好的问题。
论文发表时的主流解法及存在的问题主流解法存在的主要问题就是算力要求极高,且可扩展性不强。
主要有强化学习方法、进化算法等。
一些操作包括:设定特殊的搜索空间、对每个独立的架构进行权重或表现估计、多个结构之间的权重共享/继承。
方法总结来说,就是将离散空间的搜索问题松弛之后转换为连续问题,使用梯度下降法处理。这种变为连续的方法并不是首创,但是之前的变为连续的方式基本上都是微调模型中的某个特定方面,本方法是调整一整个模型的架构。以下为搜索过程详细介绍。
搜索空间搜索的目标是结构中的一个cell,对CNN来说需要堆叠这个cell形成最后的网络,对RNN来说则是递归使用这个cell。
在搜索过程中,一个cell可以表示成一个有向无环图。假设每个cell含有N个节点,其中每个节点\(x^{(i)}\)表示一个隐含表示,每一条从i节点到j结点的边\(o^{(i,j)}\)表示一种操作(例如卷积等),每个节点值由之前节点与连接决定。举例:
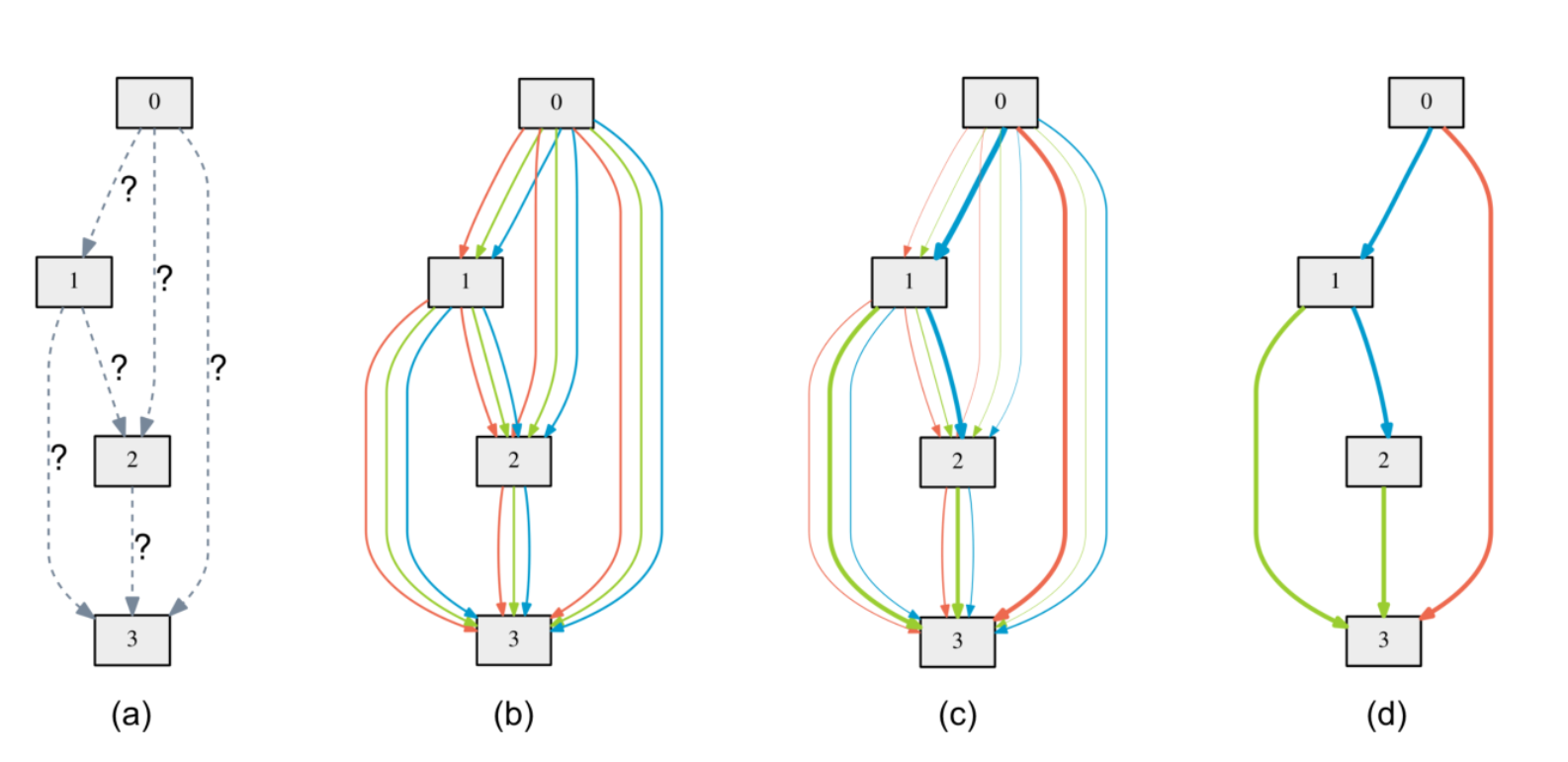
上图中a表示确定一个cell中含有四个节点,需要进行连接,第二张图列出了所有可能的连接方式,第三张图中进行梯度下降之后选出了最有可能的d输出。
松弛与优化O是待选的操作集合(例如卷积,最大池化,zero操作),每个操作都可以看成是对结点的一个函数。则两个节点之间的选择可以松弛如下:
\[o^{(i,j)}(x)=\sum_{o \in O}\frac{exp(\alpha_o^{(i,j)})}{\sum_{o' \in O }exp(\alpha_{o'}^{(i,j)})}o(x) \]其中需要学习的就是\(\alpha\)向量。由于最后使用这个向量来选择操作,所以下述就将这个向量称为结构。
在优化过程中一共有两个需要优化的:结构\(\alpha\)和每个结构对应的内部参数权重w。这就导致了一个二层优化问题如下图所示:
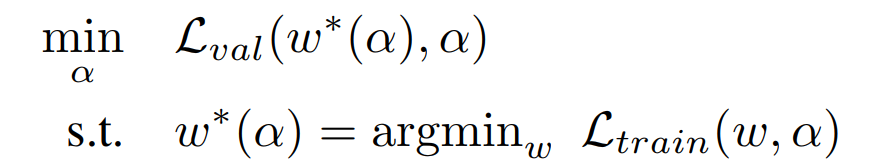
本部分详细数学推导都可以见博客:【论文笔记】DARTS公式推导 - 知乎 (zhihu.com)
由于上述的二层优化比较难进行,因此实际过程中进行如下简化:
\[\nabla_{\alpha}L_{val}(w^*(\alpha),\alpha)\approx \\\nabla_{\alpha}L_{val}(w-\epsilon \nabla _{w}L_{train}(w,\alpha),\alpha) \]对上述式子整理一下可以得到如下式子:
\[\begin{aligned} & \nabla_{\alpha} \mathcal{L}_{v a l}\left(\omega-\xi \nabla_{\omega} \mathcal{L}_{t r a i n}(\omega, \alpha), \alpha\right) \\ =&\nabla_{\alpha} \mathcal{L}_{v a l}\left(\omega^{\prime}, \alpha\right)-\xi \nabla_{\alpha, \omega}^{2} \mathcal{L}_{t r a i n}(\omega, \alpha) \cdot \nabla_{\omega^{\prime}} \mathcal{L}_{v a l}\left(\omega^{\prime}, \alpha\right) \end{aligned} \]再进行一个有限差分之后可以得到如下估计
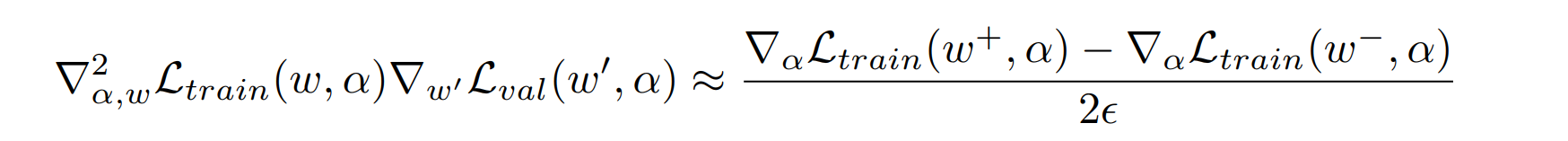
简单来说就是做了一个一阶的泰勒展开。
作者提出可以直接把后面的二阶导数扔掉,但是实验证明估计效果不如不扔。
生成最优模型假设通过之前说的这些流程,架构参数已经训练的挺不错了。那么,接下来就要提取真正的模型了,因为直至目前,架构依然是计算了所有的操作,而所有操作依然是连续组合而不是离散的。 但是,和分类问题一样,我们可以取出每条边上权重最大的 \(k\) 个操作(在CNN中DARTS取2个最大的操作,并忽略0操作)。
优点&创新点 优点- 在图像和自然语言处理任务上性能较优
- 对计算资源的需求显著减少(3个量级)
- 学习出的模型具有一定的迁移能力
离散问题连续化,使用梯度下降处理问题
实验数据CV数据集:CIFAR-10,ImageNet
NLP数据集:PTB,WikiText-2
对比实验结果与分析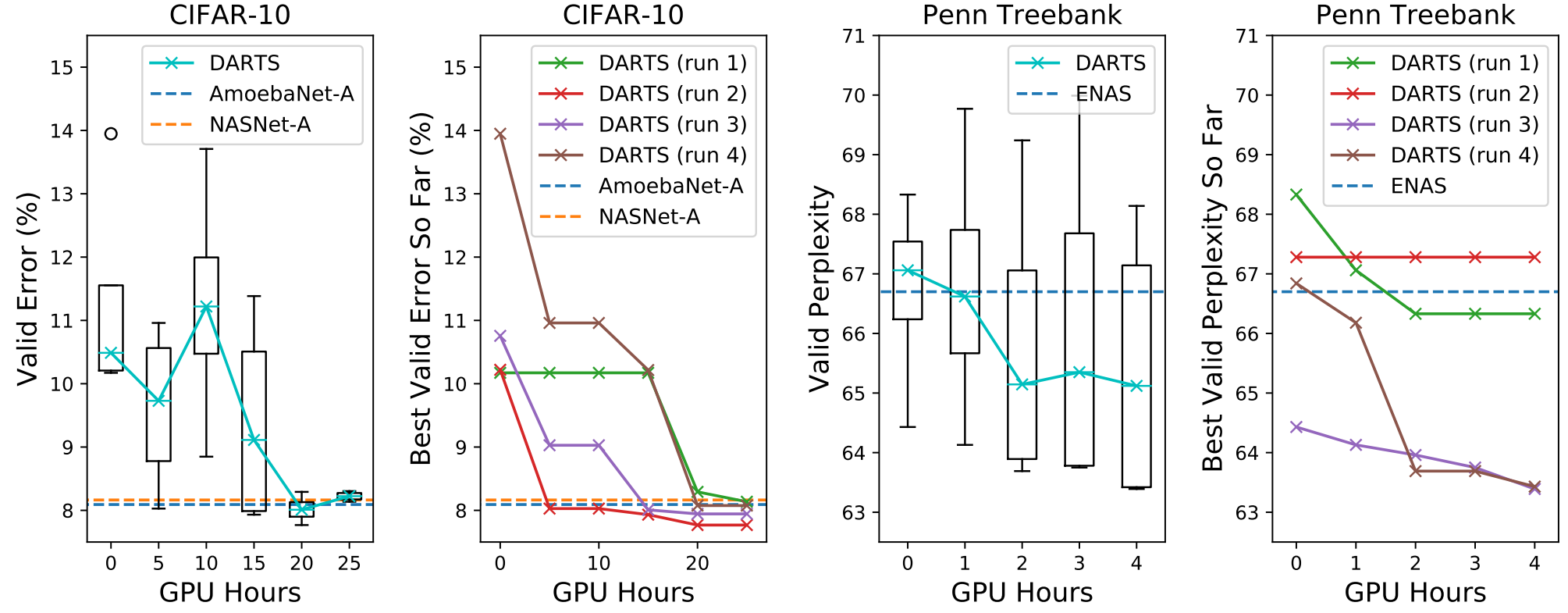
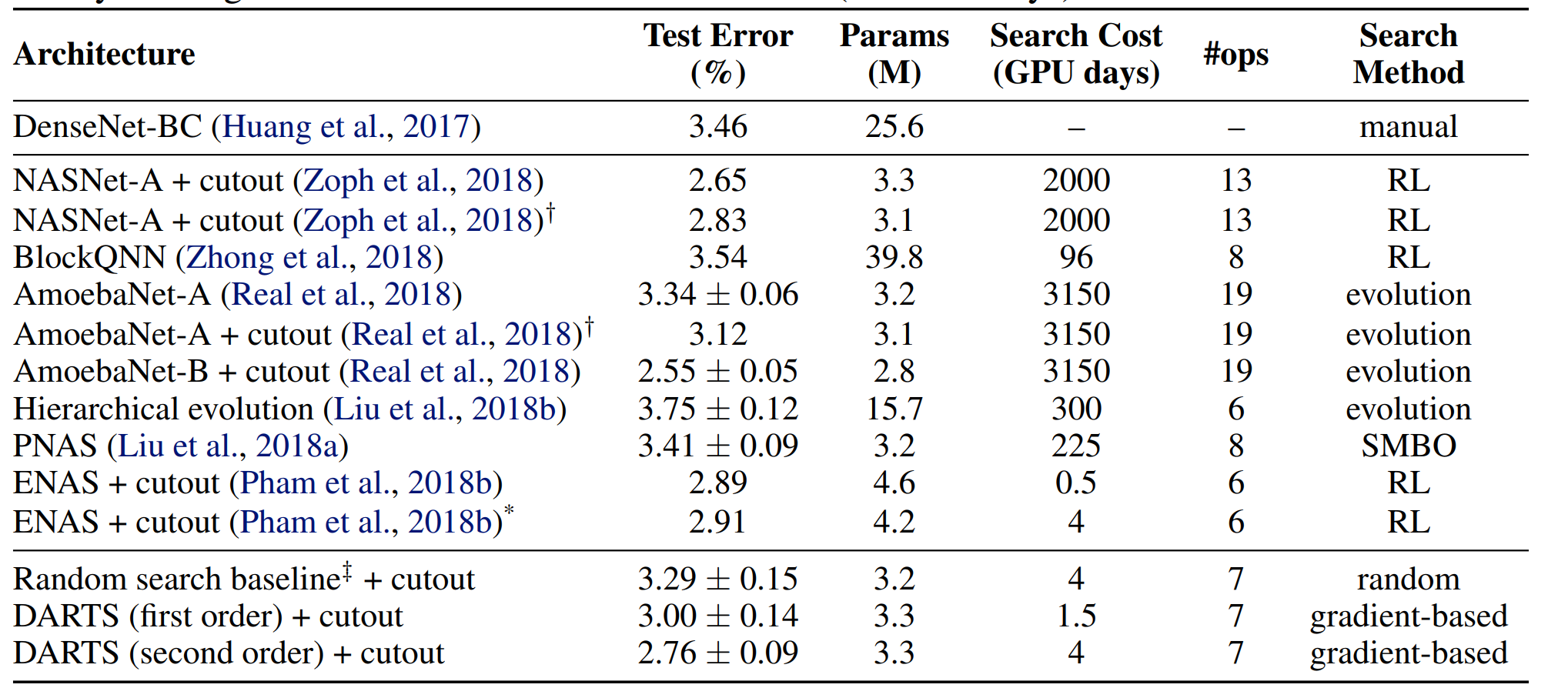
CIFAR-10:
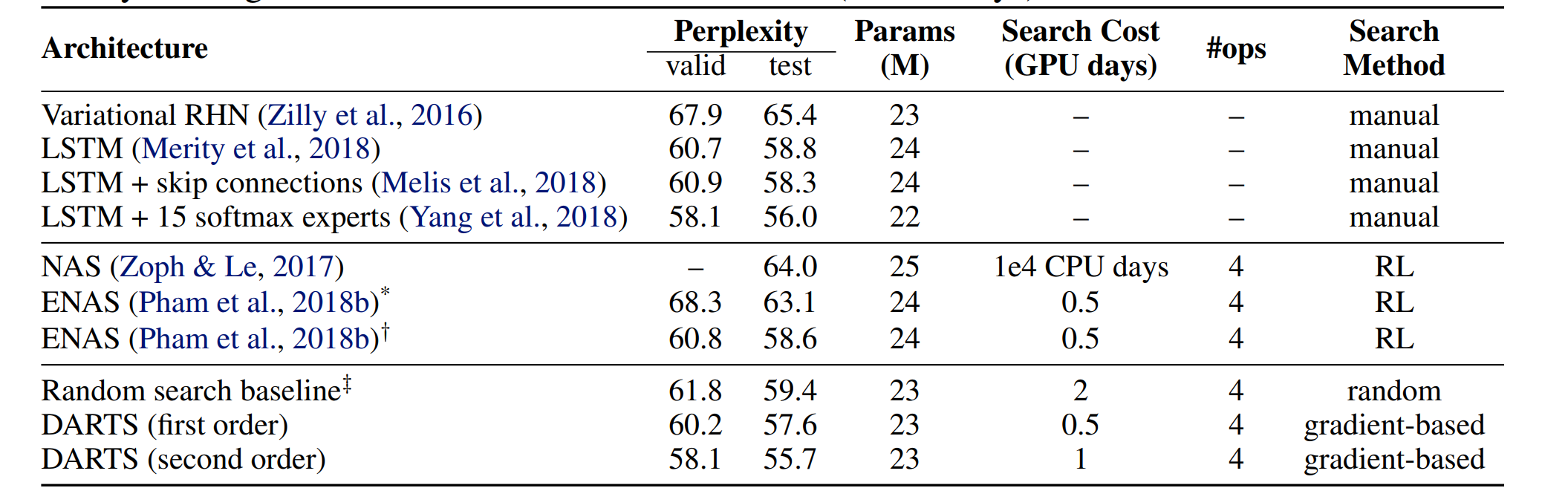
PTB:
迁移到ImageNet:
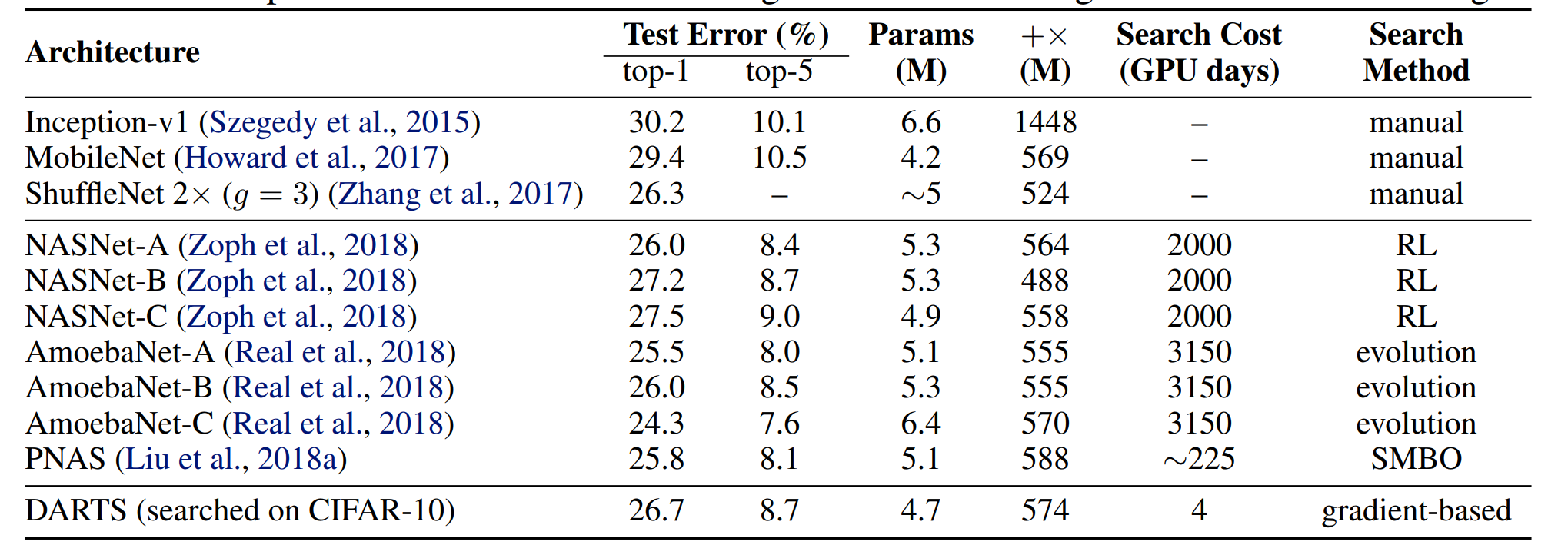
简单来说,时间大大减少,但是性能略有提升。
个人感受DARTS虽然并不完美(也没有哪个模型是真的完美的),但是它提出的这种方法确实很优秀。个人感觉可以修改的点就是其中的一些假设:
- 小数据集上训练出的模型可以迁移到大规模数据集
- zero操作没有影响
- 在验证集上效果最好的模型,在测试集上效果也最好
- 每个cell的输出都是中间节点的输出经过操作之后得到。