Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
一、基本功能Scrapy是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
尽管Scrapy原本是设计用来屏幕抓取(更精确的说,是网络抓取),但它也可以用来访问API来提取数据。 二、架构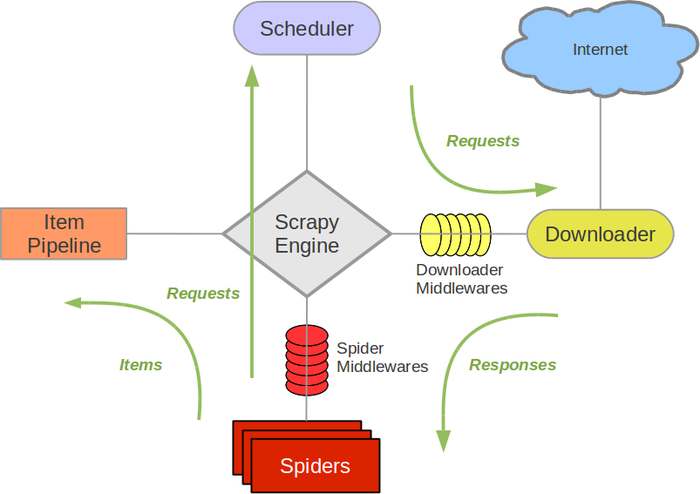
绿线是数据流向
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。 Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。 Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。 Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。 Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。 四、Scrapy安装以及生成项目1、下载方式: widows ,打开一个cmd,安装需要的包
pip install wheel
pip install lxml
pip install twisted
pip install pywin32
pip install scrapy
2、打开cmd ,输入(默认是在C:\Users\Administrator>这个目录下,你可以自行切换)
scrapy startproject 项目名
scrapy genspider 爬虫名 域名
scrapy crawl 爬虫名 (执行爬虫)
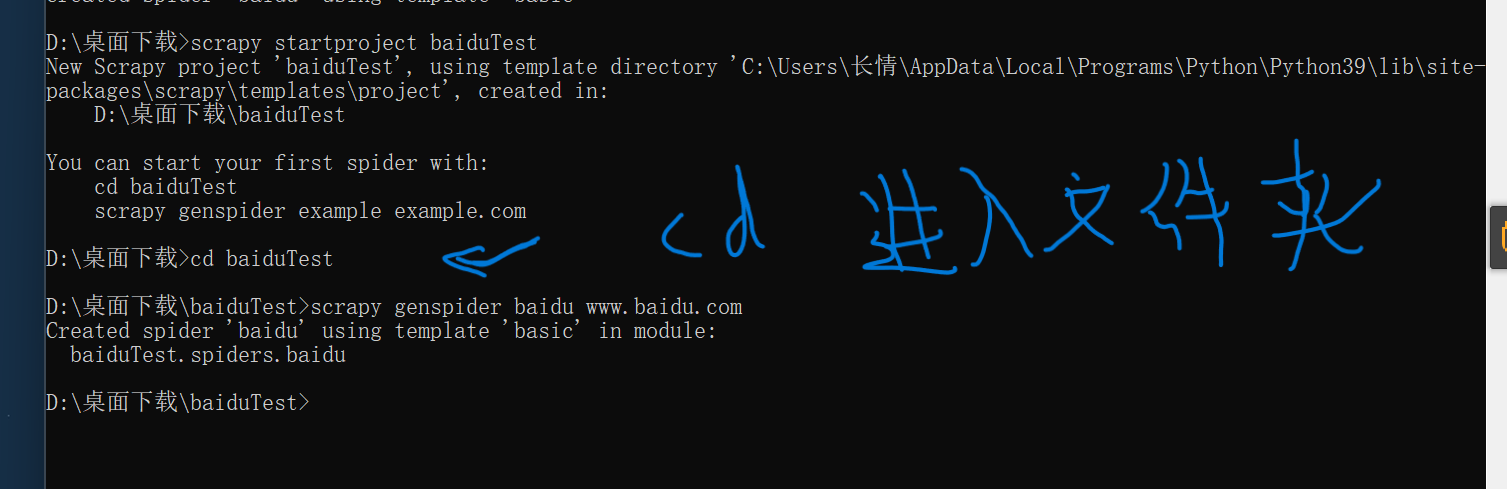
创建后目录大致页如下
|-ProjectName #项目文件夹
|-ProjectName #项目目录
|-items.py #定义数据结构
|-middlewares.py #中间件
|-pipelines.py #数据处理
|-settings.py #全局配置
|-spiders
|-__init__.py #爬虫文件
|-baidu.py
|-scrapy.cfg #项目基本配置文件
3、用pycharm打开文件
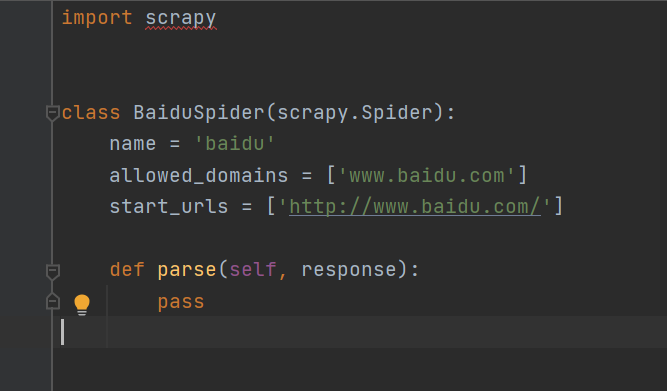
spiders下的baidu.py是scrapy自动为我们生成的
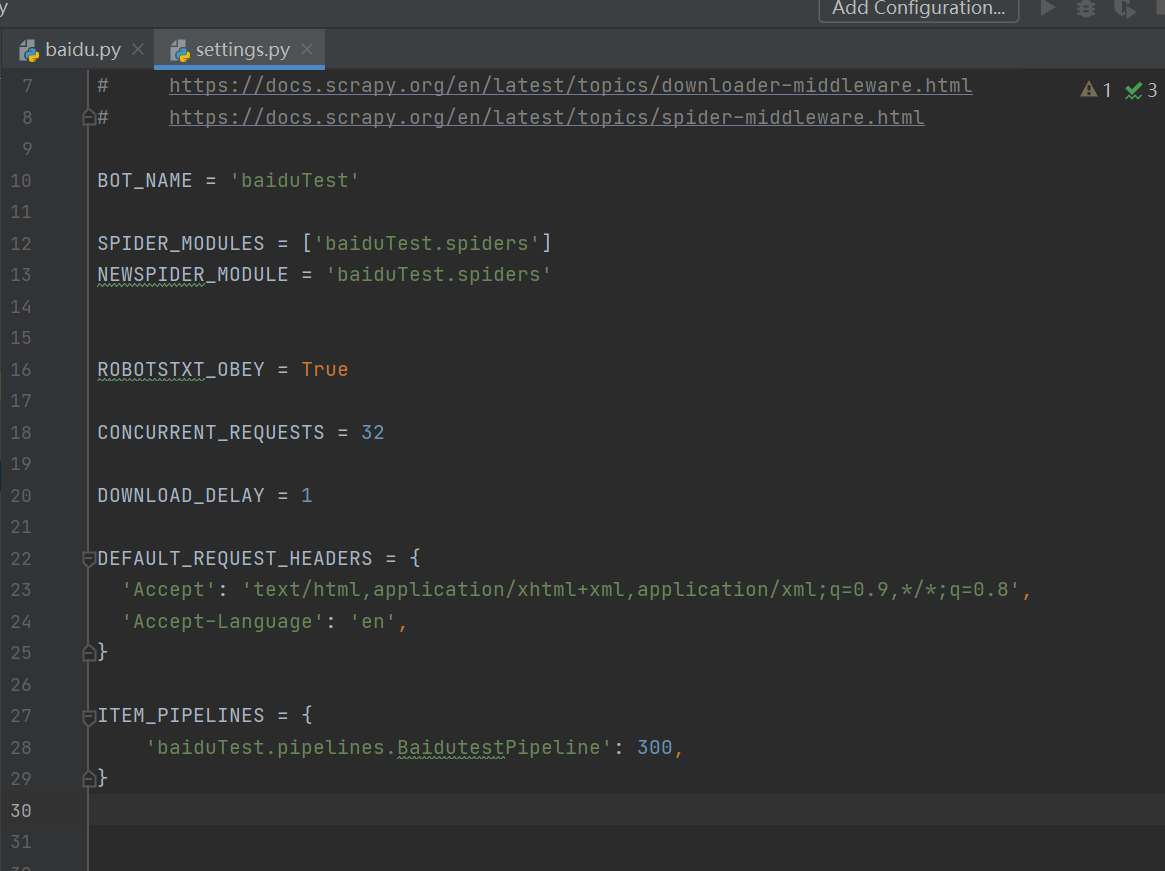
下面再看一下spdier项目的配置文件,打开文件settings.py
- CONCURRENT_ITEMS:项目管道最大并发数
- CONCURRENT_REQUESTS: scrapy下载器最大并发数
- DOWNLOAD_DELAY:访问同一个网站的间隔时间,单位秒。一般默认为0.5*
DOWNLOAD_DELAY到1.5 *DOWNLOAD_DELAY之间的随机值。也可以设置为固定值,由RANDOMIZE_DOWNLOAD_DELAY指定是否固定,默认True随机。这里的同一个网站可以是域名也可以是IP,由CONCURRENT_REQUESTS_PER_IP的值决定。 - CONCURRENT_REQUESTS_PER_DOMAIN:对单个域名的最大并发
- CONCURRENT_REQUESTS_PER_IP:对单个IP的最大并发,如果值不为0,则
CONCURRENT_REQUESTS_PER_DOMAIN参数被忽略,而且DOWNLOAD_DELAY这个参数的同一网站指的是IP - DEFAULT_ITEM_CLASS:执行scrapy shell 命令的默认item类,默认
scrapy.item.Item - DEPTH_LIMIT:爬取的最大深度
- DEPTH_PRIORITY:正值为广度优先(BFO),负值为深度优先(DFO),计算公式:
request.priority = request.priority - ( depth * DEPTH_PRIORITY ) - COOKIES_ENABLED: 是否启用cookie中间件,也就是自动cookie管理
- COOKIES_DEBUG:将请求cookie和响应包含Set-Cookie的写入日志
- DOWNLOADER_MIDDLEWARE:下载器中间件和优先级的字典
- DEFAULT_REQUEST_HEADERS:用于Scrapy HTTP请求的默认标头
- DUPEFILTER_CLASS:去重的类,可以改成使用布隆过滤器,而不使用默认的
- LOG_ENABLED:是否启用日志
- LOG_FILE:日志文件路径,默认为None
- LOG_FORMAT:日志格式化表达式
- LOG_DATEFORMAT:
LOG_FORMAT中的时间格式化表达式 - LOG_LEVEL:最低日志级别,默认DEBUG,可用:CRITICAL, ERROR, WARNING, INFO, DEBUG
- LOG_STDOUT:是否将所有标准输出(和错误)将被重定向到日志,例如print也会被记录在日志
- LOG_SHORT_NAMES:如果为True,则日志将仅包含根路径;如果设置为False,则显示负责日志输出的组件
- LOGSTATS_INTERVAL:每次统计记录打印输出之间的间隔
- MEMDEBUG_ENABLED:是否启用内存调试
- REDIRECT_MAX_TIMES:定义可以重定向请求的最长时间
- REDIRECT_PRIORITY_ADJUST:调整重定向请求的优先级,为正值时优先级高
- RETRY_PRIORITY_ADJUST:调整重试请求的优先级
- ROBOTSTXT_OBEY:是否遵循robot协议
- SCRAPER_SLOT_MAX_ACTIVE_SIZE:正在处理响应数据的软限制(以字节为单位),如果所有正在处理的响应的大小总和高于此值,Scrapy不会处理新的请求。
- SPIDER_MIDDLEWARES:蜘蛛中间件
- USER_AGENT:默认使用的User-Agent
我们主要配置下面五个:
到这里我们尝试用scrapy做一下爬取,打开spider.py下的baidu.py(取决于你scrapy genspider 爬虫名 域名时输入的爬虫名)
输入一下代码,我们使用xpath提取百度首页的标题title
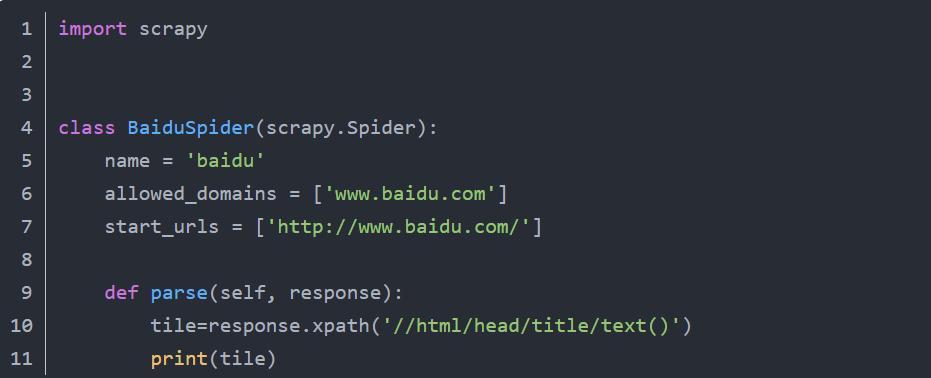
打开一个终端cmd,输入scrapy crawl baidu(爬虫名),就可以看到一大堆输出信息,而其中就包括我们要的内容。但是使用终端运行太麻烦了,而且不能提取数据,我们一个写一个run文件作为程序的入口,splite是必须写的,目的是把字符串转为列表形式,第一个参数是scrapy,第二个crawl,第三个baidu

直接运行就可以在编辑器中输出了

案例推荐:https://blog.csdn.net/ck784101777/article/details/104468780/