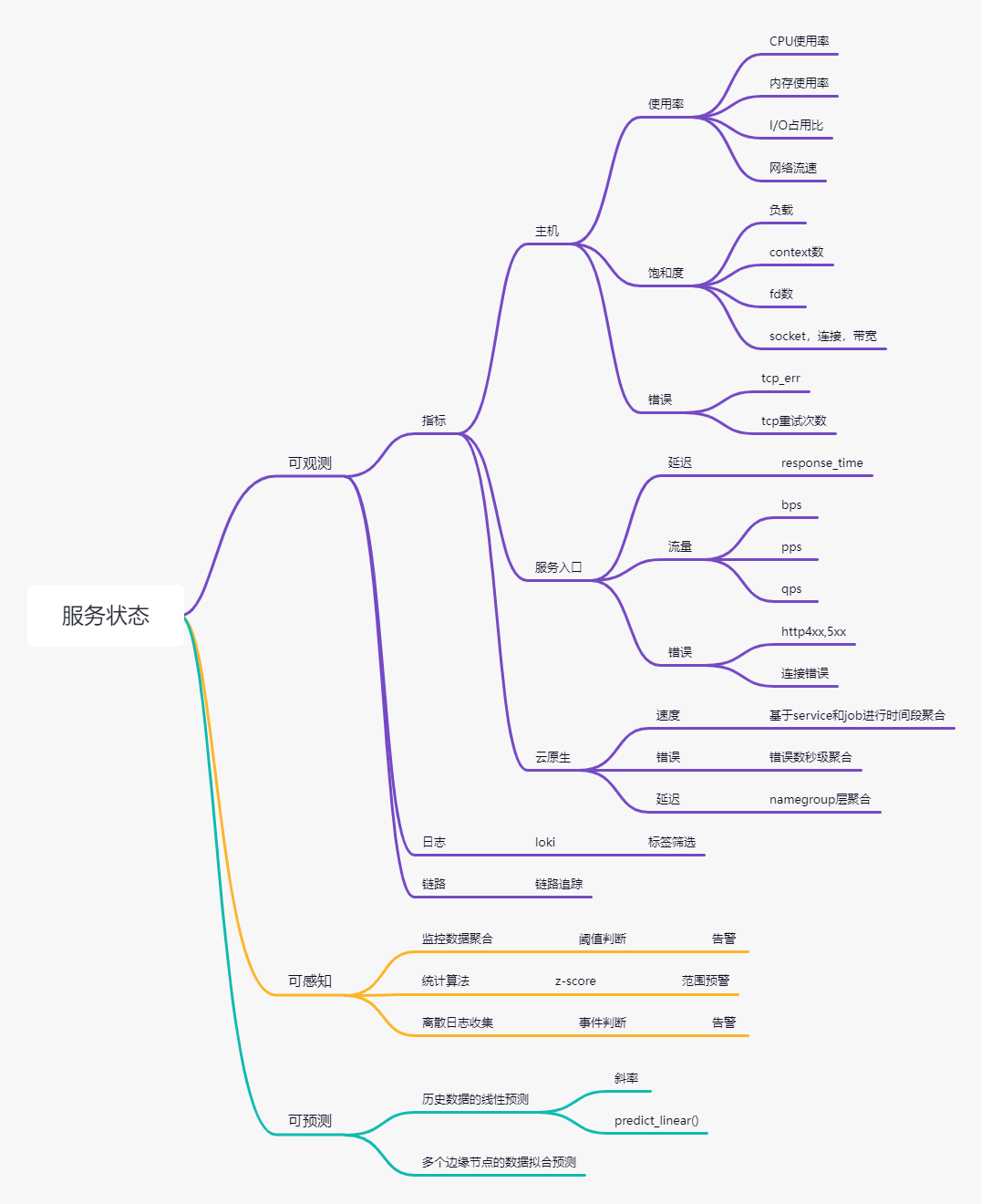
可观测
1. 监控系统
Prometheus + grafana + alert
搭建方法网上很多,忽略。
2. 日志系统
loki,官方文档之外,可以参考“云原生小白”写的一系列loki的文章。https://blog.csdn.net/weixin_49366475
3. 链路追踪(未实现)
Jaeger,eBPF(https://developer.aliyun.com/article/875115?utm_content=g_1000329007)
可感知
监控以及告警规则使用k8s-sidecar配置,注册config-map,agent和alert监控该config-map名进行reload操作。
k8s-sidecat项目地址:https://github.com/kiwigrid/k8s-sidecar
1. 告警规则
NODE告警
nodealertrules:
groups:
- name: node_monitor
rules:
- alert: node_status
expr: up == 0
for: 5m
labels:
ds: 32
severity: error
annotations:
summary: "{{$labels.instance}}:不可用"
description: "{{$labels.instance}}:状态为down超过5分钟"
- alert: CPU_critical
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(ks_ops_haique_tech_com_nodegroup,instance,job)* 100) > 80 and count(node_cpu_seconds_total{mode='system'}) by (ks_ops_haique_tech_com_nodegroup,instance,job) > 1
for: 10m
labels:
ds: 32
severity: critical
annotations:
summary: "{{$labels.instance}} CPU使用率过高!"
description: "{{$labels.instance }} CPU使用大于80%(目前使用:{{$value}}%),{{$labels.ks_ops_haique_tech_com_nodegroup}}"
- alert: CPU_softirq
expr: avg(irate(node_cpu_seconds_total{mode="softirq"}[5m])) by(ks_ops_haique_tech_com_nodegroup,instance,job)* 100 >40 and count(node_cpu_seconds_total{mode='system'}) by (ks_ops_haique_tech_com_nodegroup,instance,job) > 1
for: 10m
labels:
ds: 32
severity: error
annotations:
summary: "{{$labels.instance}} CPU软中断si使用率过高!"
description: "{{$labels.instance }} CPU软中断si使用率大于40%(目前使用:{{$value}}%),{{$labels.ks_ops_haique_tech_com_nodegroup}}"
- alert: CPU_load5
expr: avg(node_load5) by (ks_ops_haique_tech_com_nodegroup,instance,job) - count(node_cpu_seconds_total{mode='system'}) by (ks_ops_haique_tech_com_nodegroup,instance,job) *2 > 0 and count(node_cpu_seconds_total{mode='system'}) by (ks_ops_haique_tech_com_nodegroup,instance,job) > 1
for: 10m
labels:
ds: 32
severity: error
annotations:
summary: "{{$labels.instance}} CPU负载高!"
description: "{{$labels.instance }} CPU平均负载持续10分钟超过CPU核数2倍(目前超过:{{$value}}),{{$labels.ks_ops_haique_tech_com_nodegroup}}"
- alert: HostOutOfMemory
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
for: 3m
labels:
ds: 32
severity: error
annotations:
summary: "{{$labels.instance}} 内存使用率过高!"
description: "{{$labels.instance}} 内存剩余小于10%(目前剩余:{{$value}}%),{{$labels.ks_ops_haique_tech_com_nodegroup}}"
- alert: HostOomKillDetected
expr: increase(node_vmstat_oom_kill[1m]) > 0
for: 0m
labels:
ds: 32
severity: error
annotations:
summary: "{{ $labels.instance }}出现OOM"
description: "{{ $labels.instance }}出现OOM,出现{{$value}}次,{{$labels.ks_ops_haique_tech_com_nodegroup}}"
- alert: IO
expr: irate(node_disk_io_time_seconds_total{device=~"vd.*"}[1m]) *100 > 40
for: 5m
labels:
ds: 32
severity: error
annotations:
summary: "{{$labels.instance}} 磁盘I/O耗时高!"
description: "{{$labels.instance }} 磁盘I/O操作耗时占比大于40%(目前使用:{{$value}}),{{$labels.ks_ops_haique_tech_com_nodegroup}}"
- alert: mount_error
expr: (node_filesystem_size_bytes{fstype=~"ext.*|xfs"}-node_filesystem_free_bytes{fstype=~"ext.*|xfs"}) *100/(node_filesystem_avail_bytes {fstype=~"ext.*|xfs"}+(node_filesystem_size_bytes{fstype=~"ext.*|xfs"}-node_filesystem_free_bytes{fstype=~"ext.*|xfs"})) > 80
for: 1m
labels:
ds: 32
severity: error
annotations:
summary: "{{$labels.instance}} {{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.instance}} {{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%),{{$labels.ks_ops_haique_tech_com_nodegroup}}"
- alert: mount_critical
expr: (node_filesystem_size_bytes{fstype=~"ext.*|xfs"}-node_filesystem_free_bytes{fstype=~"ext.*|xfs"}) *100/(node_filesystem_avail_bytes {fstype=~"ext.*|xfs"}+(node_filesystem_size_bytes{fstype=~"ext.*|xfs"}-node_filesystem_free_bytes{fstype=~"ext.*|xfs"})) > 95
for: 1m
labels:
ds: 32
severity: critical
annotations:
summary: "{{$labels.instance}} {{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.instance}} {{$labels.mountpoint }} 磁盘分区使用大于95%(目前使用:{{$value}}%),{{$labels.ks_ops_haique_tech_com_nodegroup}}"
- alert: HostConntrackLimit
expr: node_nf_conntrack_entries / node_nf_conntrack_entries_limit > 0.8
for: 5m
labels:
ds: 32
severity: error
annotations:
summary: "{{ $labels.instance }} 连接数接近limit值"
description: "{{ $labels.instance }} 连接跟踪的数量与limit的比值大于0.8(目前使用:{{$value}}),{{$labels.ks_ops_haique_tech_com_nodegroup}}"
POD告警
podalertrules:
groups:
- name: pod_monitor
rules:
- alert: pod_cpu
expr: sum(rate(container_cpu_usage_seconds_total{container !="",container!="POD"}[2m])) by (container, pod) / sum(kube_pod_container_resource_limits{resource="cpu",unit="core",container !="",container!="POD"} > 0) by (container, pod) * 100 > 80
for: 10m
labels:
ds: 32
severity: warning
annotations:
summary: "{{$labels.pod}}:cpu使用率高于80%"
description: "{{$labels.pod}},{{$labels.container}},cpu使用率{{$value}}%"
- alert: pod_mem
expr: sum(container_memory_working_set_bytes{container !="",container!="POD"}) by (container, pod) / sum(container_spec_memory_limit_bytes{container !="",container!="POD"} > 0) by (container, pod) * 100 > 80
for: 10m
labels:
ds: 32
severity: warning
annotations:
summary: "{{$labels.pod}}:mem使用率高于80%"
description: "{{$labels.pod}},{{$labels.container}},mem使用率{{$value}}%"
- alert: pod_restartNum
expr: increase(kube_pod_container_status_restarts_total{container!="POD"}[3h])> 3
for: 0m
labels:
ds: 32
severity: error
annotations:
summary: "{{$labels.pod}}:容器经常重启"
description: "{{$labels.pod}},{{$labels.container}},重启近3小时重启次数大于3,共重启{{$value}}次"
2. 告警渠道
使用开源工具Prometheusalert做告警模板。https://github.com/feiyu563/PrometheusAlert
钉钉告警模板
{{ range $k,$v:=.alerts }}
{{if eq $v.status "firing"}}
**[Prometheus告警]**
- 告警级别:{{$v.labels.severity}}
- 告警时间:{{GetCSTtime $v.startsAt}}
- 故障主机IP:{{$v.labels.instance}}
- 节点:{{$v.labels.ds}}
- 摘要:{{$v.annotations.summary}}
- 详情:{{$v.annotations.description}}
- 监控图像(https://dashboard.ks.dana-tech.com/d/dovc2Vc7z/node-exporter-for-prometheus-dashboard-cn?orgId=1&var-ds={{$v.labels.ds}}&var-job={{$v.labels.job}}&var-node={{$v.labels.instance}})
{{else}}
*[Prometheus恢复]*
- 恢复时间:{{GetCSTtime $v.endsAt}}
- 故障主机IP:{{$v.labels.instance}}
- 节点:{{$v.labels.ds}}
- {{$v.annotations.description}}
{{end}}
{{ end }}
可预测
可参考我另一篇文章。
使用z-score异常检测算法进行监控告警 - 沄持的学习记录 - 自由互联 (cnblogs.com)
1. 异常检测算法
时间向量数据,特别适合应用于一些基础的统计学算法。计算很快,而且Prometheus自带的PQL自带标准差、方差、平局值、对数等,数据聚合特别方便。
我在实际生产中,使用z-score算法。这个算法很简单,现在使用了有半年了,目前看在业务流量、连接数、QPS、PV这类有比较明显的高低峰的指标类型上,告警上很准确且灵敏。
z-score公式:z = (x-u)/σ
其中x是当前数据,u是均值,σ为标准差。
z值符合正太分布,99.7%的数据落在[-3,3],z值离0越远则越有可能是异常点。
2. 使用案例
假设指标名qps
x=sum(qps{env="prod"})by(instance)
u=avg_over_time(sum(qps{env="prod"})by(instance)[1d])
σ=stddev_over_time(sum(qps{env="prod"})by(instance)[1d])
平均值和标准差所选时间段不能太小,按参考文档所述,选取1000个左右的点比较合适,我这里选的1d,实际差不多1k-3k个点。

告警规则
(sum(qps{name="env"}) by (instance) - avg_over_time(sum(qps{name="env"}) by (instance)[1d])) /stddev_over_time(sum(qps{name="env"}) by (instance)[1d]) >3
or
(sum(qps{name="env"}) by (instance) - avg_over_time(sum(qps{name="env"}) by (instance)[1d])) /stddev_over_time(sum(qps{name="env"}) by (instance)[1d]) < -3
数据聚合的时候,聚合维度一定要保持一致,不然无法计算。我这里全都用的by (instance)这个维度聚合数据。其实可以直接取绝对值大于3,这里用大于3或小于-3是为了体现数据偏离方向。