Gcc内置原子操作__sync_系列函数简述及例程 Gcc 4.1.2版本之后,对X86或X86_64支持内置原子操作。就是说,不需要引入第三方库(如pthread)的锁保护,即可对1、2、4、8字节的数值或指针类型
Gcc 4.1.2版本之后,对X86或X86_64支持内置原子操作。就是说,不需要引入第三方库(如pthread)的锁保护,即可对1、2、4、8字节的数值或指针类型,进行原子加/减/与/或/异或等操作。
- __sync_fetch_and_add系列一共有十二个函数,有加/减/与/或/异或/等函数的原子性操作函
__snyc_fetch_and_add : 先fetch然后自加,返回的是自加以前的值
__snyc_add_and_fetch : 先自加然后返回,返回的是自加以后的值 (参照 ++i 和 i++)
__snyc_fetch_and_add的一个简单使用:
int count = 4;
__sync_fetch_and_add(&count, 1); // __sync_fetch_and_add(&count, 1) == 4
cout<<count<<endl; //--->count=5
2.对于多线程对全局变量进行自加,我们就再也不用理线程锁了。
下面这行代码,和上面被pthread_mutex保护的那行代码作用是一样的,而且也是线程安全的。
__sync_fetch_and_add( &global_int, 1 );
将__sync_系列17个函数声明整理简化如下:
type __sync_fetch_and_add (type *ptr, type value, ...);
type __sync_fetch_and_sub (type *ptr, type value, ...);
type __sync_fetch_and_or (type *ptr, type value, ...);
type __sync_fetch_and_and (type *ptr, type value, ...);
type __sync_fetch_and_xor (type *ptr, type value, ...);
type __sync_fetch_and_nand (type *ptr, type value, ...);
type __sync_add_and_fetch (type *ptr, type value, ...);
type __sync_sub_and_fetch (type *ptr, type value, ...);
type __sync_or_and_fetch (type *ptr, type value, ...);
type __sync_and_and_fetch (type *ptr, type value, ...);
type __sync_xor_and_fetch (type *ptr, type value, ...);
type __sync_nand_and_fetch (type *ptr, type value, ...);
__sync_fetch_and_add,速度是线程锁的6~7倍
type可以是1,2,4或者8字节长度的int类型,即:
int8_t
uint8_t
int16_t
uint16_t
int32_t
uint32_t
int64_t
uint64_t
3.例程
并编写了一个简单小例子,测试多个工作线程同时对同一个全局变量g_iSum进行加法操作时,使用__sync_fetch_and_add()原子操作进行原子加法,和不使用原子操作进行普通加法,观察它们运行结果的区别。每个工作线程加500万次,共10个工作线程,预期结果是5000万。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int g_iFlagAtom = 1;
#define WORK_SIZE 5000000
#define WORKER_COUNT 10
pthread_t g_tWorkId[WORKER_COUNT];
int g_iSum;
void* thr_work(void *arg)
{
printf("Work Thread %08X Startup\n", (unsigned int)pthread_self());
int i;
for(i = 0; i < WORK_SIZE; i++)
{
if(g_iFlagAtom)
__sync_fetch_and_add(&g_iSum, 1);
else
g_iSum++;
}
return NULL;
}
void* thr_management(void *arg)
{
printf("Management Thread %08X Startup\n", (unsigned int)pthread_self());
int i;
for(i = 0; i < WORKER_COUNT; i++)
{
pthread_join(g_tWorkId[i], NULL);
}
printf("All Work Thread Finished!\n");
return NULL;
}
int main(int argc, const char* argv[])
{
pthread_t tManagementId;
pthread_create(&tManagementId, NULL, thr_management, NULL);
int i;
for(i = 0; i < WORKER_COUNT; i++)
{
pthread_create(&g_tWorkId[i], NULL, thr_work, NULL);
}
printf("create %d worker threads\n", i);
pthread_join(tManagementId, NULL);
printf("the sum:%d\n", g_iSum);
return 0;
}
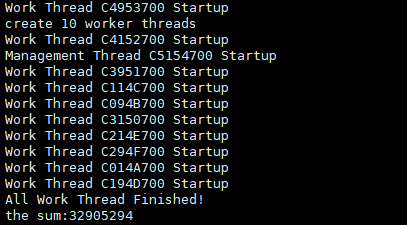
将g_iFlagAtom = 0,即不使用原子操作,可以看到输出结果无法达到预期的50000000,而且每次执行都可能得到不同的值。
gcc -Wall -o atom atom.cc -l pthread
./atom
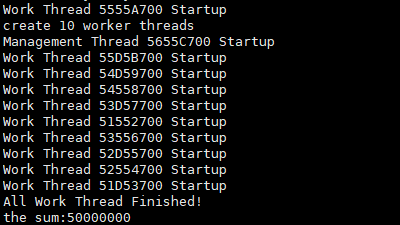
将g_iFlagAtom = 1,即使用原子操作,可以看到输出结果为预期的50000000,而且每次执行都得到这个值不变。
gcc -Wall -o atom1 atom.cc -l pthread
./atom1