最近,部门要求将 Tomcat 应用全部迁移到了 Weblogic,好巧不巧,我就是那个负责迁移的人。虽然项目不是我开发的,但奈何我懂一点点 Weblogic 的使用(注意是使用),就被拉出来顶上去了。在经历了几周的煎熬,各种奇怪问题,依赖不兼容问题后,终于将大大小小十几个项目全部部署到 Weblogic 上。
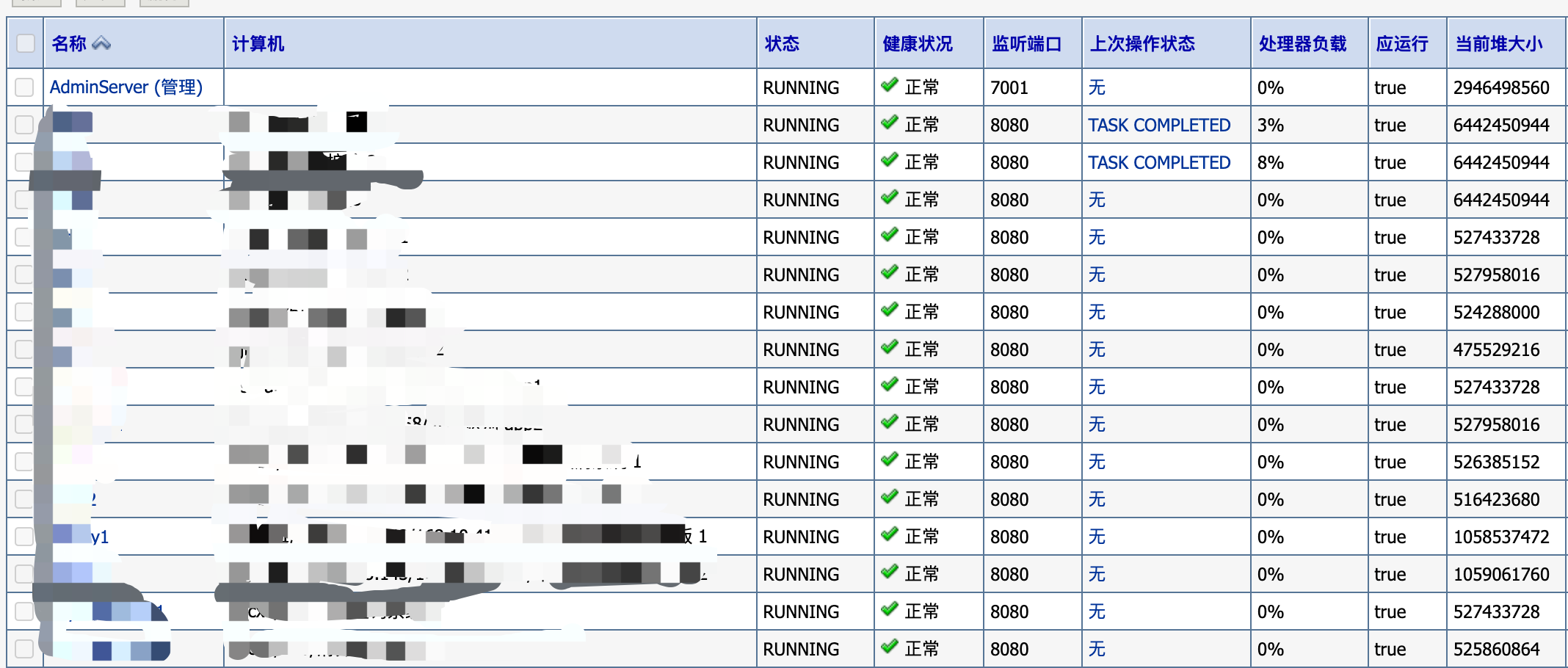
正当我心满意足的盯着一屏绿油油的对号时,忽然发现有两台服务器非常刺眼,他们的状态是 Warning。

呵呵,这又有什么关系呢,嘴上说正经程序员谁在乎 Warning 啊,但心里还是有点忐忑的,怀着不安的心情下班回家找妹子去了。
第二天,果然还是遭了报应。当我还在美梦中洋洋得意,接到上司的急电,用户反映这个应用坏了。我说怎么会坏呢呢,明明昨天还好好的,领导让我先使用重启大法--其实我也没别的主意,重启之后好了,继续我的美梦。
本想着事情就这么过去了,可没想到到了下午,又有人反应无法使用,这好办,我继续重启呗。
接下来的想必各位读者也能想到,这种接二连三的重启持续了好几天,于是喊负责这个应用的同事去看看是不是有什么 BUG。同事瞪大眼看了一圈儿,给出了很简单的解决方案:配置不够了,加台机器。
这还不简单,对于领导来说,只要能加机器解决的,都不是问题,4C 16G 马上安排一台,于是,这两位 Warning 的兄弟又多了个帮手,这下总该好了吧,第二天高峰我兴冲冲的一看:

原来你也是一路货色啊。

同事又努力改了改配置,将原本默认的 JVM 配置,改成了
-Xms3G -Xmx3G -XX:+UseG1GC
指定了最小内存,加大了可用内存,并且使用 G1 来避免长时间停顿,第二天早上我终于没再接到处理电话,本想着就此就解决了,没想到第三天下午又双叒叕 Down 了,状态还是 Warning。
身为老员工的我,必须出面帮一把了(其实主要是不想再被电话吵醒),拍拍胸脯说:好弟弟,哥哥我来给你看看怎么回事。
这种服务未宕机,但无响应的情况,大概率是服务器由于某种原因无法处理请求了,什么原因呢?会不会是内存泄漏,或者内存满了一直在 GC,没有空闲时间呢?第一时间登录服务器上查看该应用的 GC 情况和配置。
# 使用 jps 找到进程的 ID
[weblogic@xxy-app1 ~]$ jps -lv | grep xxy
29773 weblogic.Server -Xms3G -Xmx3G -XX:+UseStringDeduplication -XX:+PrintGCDetails -Djava.rmi.server.hostname=127.0.0.1 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -XX:CompileThreshold=8000 -Dlaunch.use.env.classpath=true -Dweblogic.Name=xxy1 -Djava.security.policy=/opt/bea/weblogic/Oracle_Home/wlserver/server/lib/weblogic.policy -Dweblogic.system.BootIdentityFile=/opt/bea/weblogic/Oracle_Home/user_projects/domains/m_domain/servers/xxy1/data/nodemanager/boot.properties -Dweblogic.nodemanager.ServiceEnabled=true -Dweblogic.nmservice.RotationEnabled=true -Dweblogic.ReverseDNSAllowed=false -Djava.system.class.loader=com.oracle.classloader.weblogic.LaunchClassLoader -javaagent:/opt/bea/weblogic/Oracle_Home/wlserver/server/lib/debugpatch-agent.jar -da -Dwls.home=/opt/bea/weblogic/Oracle_Home/wlserver/server -Dweblogic.home=/opt/bea/weblogic/Oracle_Home/wlserver/server -Dweblogic.management.server=http
- 查看 GC 配置
[weblogic@xxy-app1 ~]$ jmap -heap 29773
Attaching to process ID 29773, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.231-b11
using thread-local object allocation.
Garbage-First (G1) GC with 8 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 3221225472 (3072.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 1932525568 (1843.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 1048576 (1.0MB)
Heap Usage:
G1 Heap:
regions = 3072
capacity = 3221225472 (3072.0MB)
used = 936989376 (893.5827026367188MB)
free = 2284236096 (2178.4172973632812MB)
29.08797860145569% used
G1 Young Generation:
Eden Space:
regions = 709
capacity = 1837105152 (1752.0MB)
used = 743440384 (709.0MB)
free = 1093664768 (1043.0MB)
40.46803652968037% used
Survivor Space:
regions = 68
capacity = 71303168 (68.0MB)
used = 71303168 (68.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 118
capacity = 1312817152 (1252.0MB)
used = 121197248 (115.58270263671875MB)
free = 1191619904 (1136.4172973632812MB)
9.231845258523862% used
80291 interned Strings occupying 9232280 bytes.
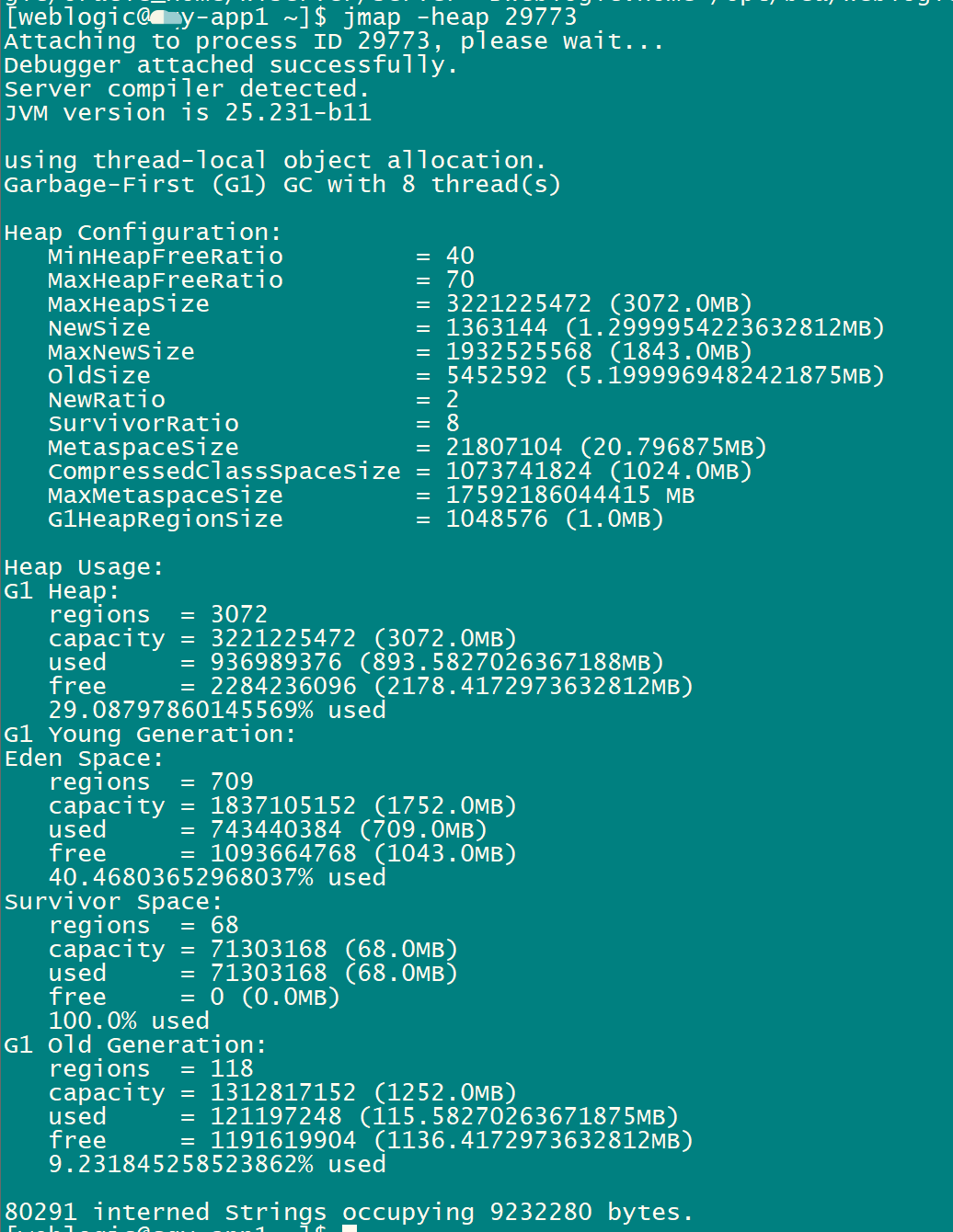
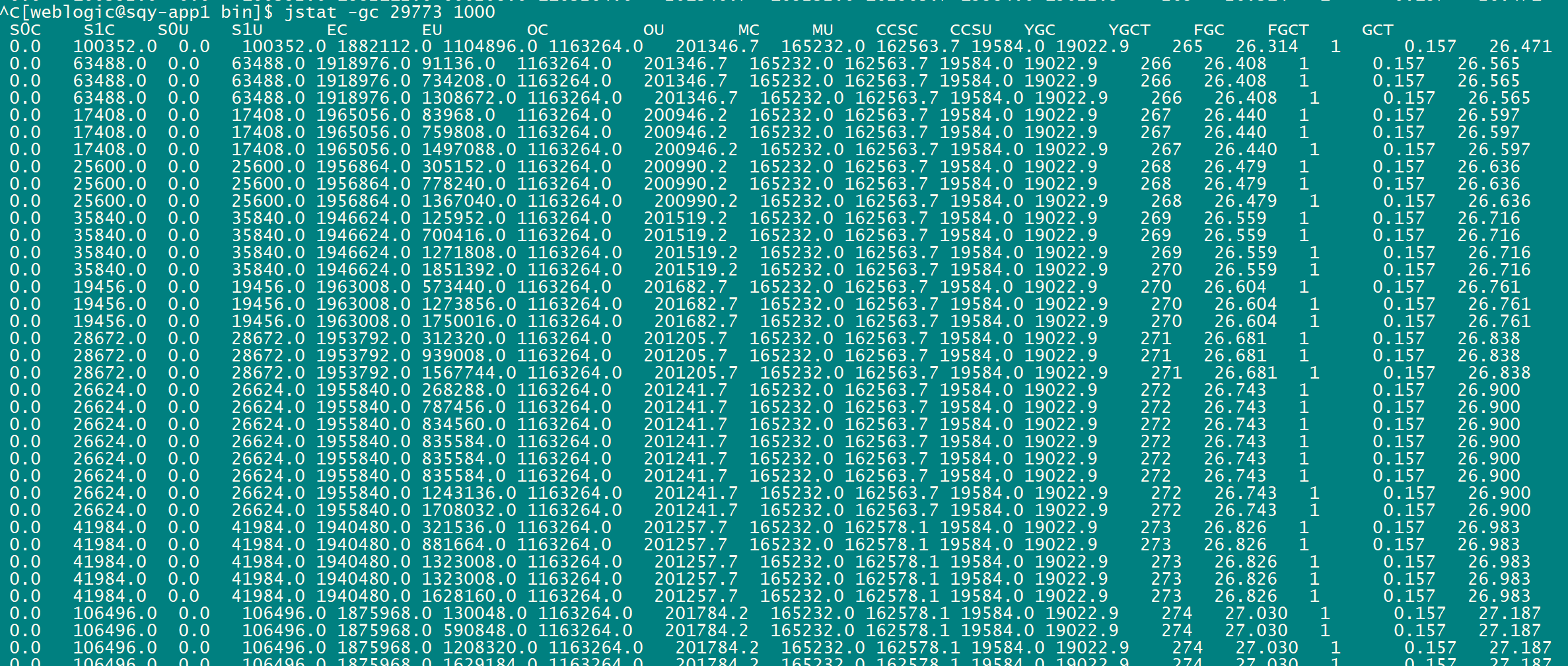
嗯,没错,知道同事设置的是 3G,我就是确认下。上面这张图也是我后来用 Jmeter 压测的,不是当时的真实情况(太可惜了!),从 GC 情况没有分析出什么异常情况,只知道占用非常高,使用 jmap 命令 dump 出内存快照看一下。
$ jmap -dump:live,format=b,file=/tmp/xxy.hprof 29773
然后把文件拉到自己电脑上看一下,好家伙,好几 G 的文件,可拉了好一阵儿
我们使用大名鼎鼎的 Eclipse Memory Analyzer(简称 MAT)进行分析,打开以后将文件拖入工具。首次竟然导入失败了,因为这个文件是在太大了,需要增加给 mat 工具配置的可用内存。
在 macOS 下,右键显示包内容,在MemoryAnalyzer.ini文件中添加 -Xmx 配置,这里我直接给了 6G,然后关了电脑上的大部分程序避免太卡。

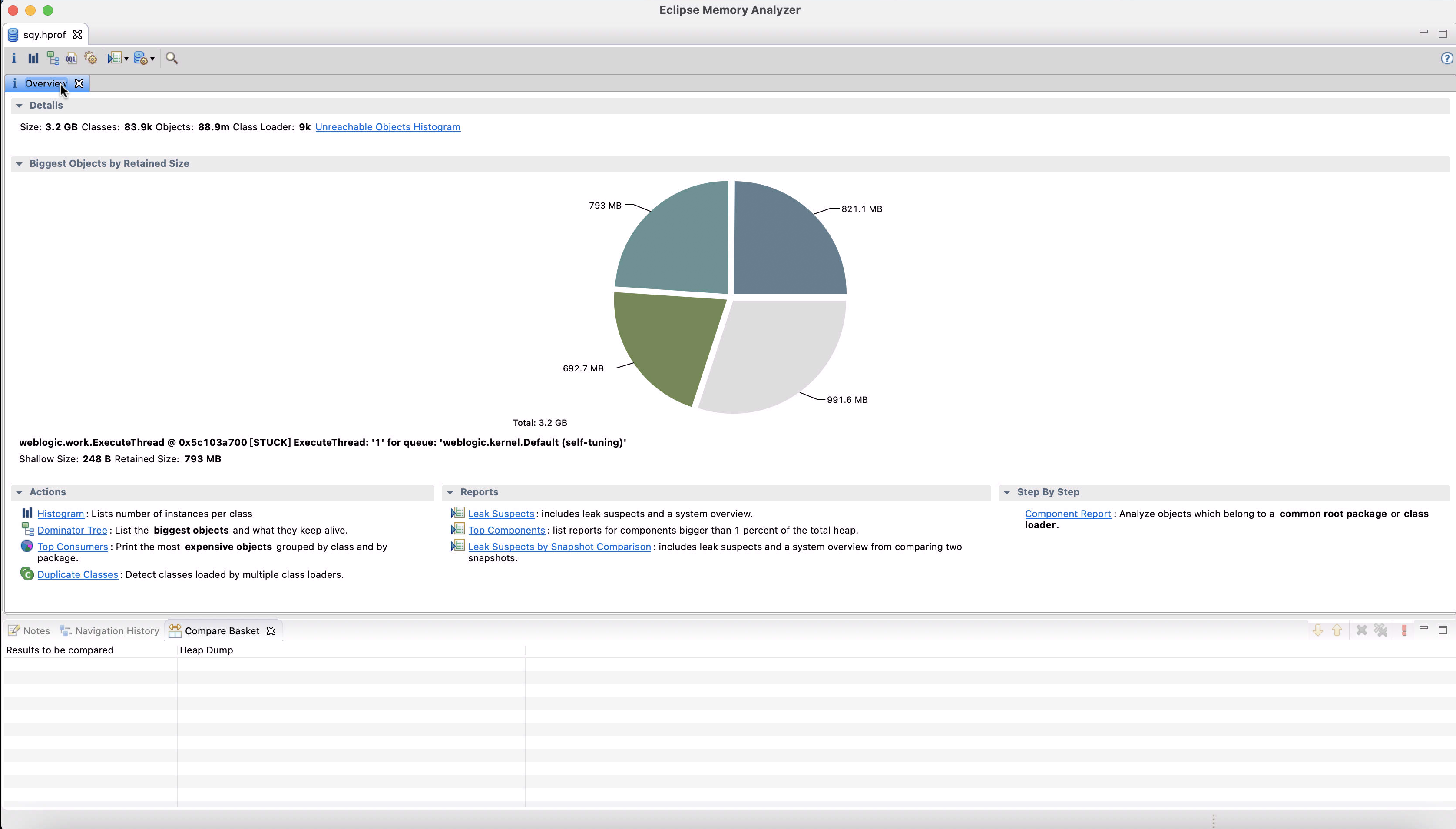
经过漫长的导入后,终于打开了,点击Overview查看,发现若干个 weblogic.work.ExecuteThread带 STUCK 的线程,每个占用 700 MB 左右,几个线程就占这么多,十有八九是有问题了。
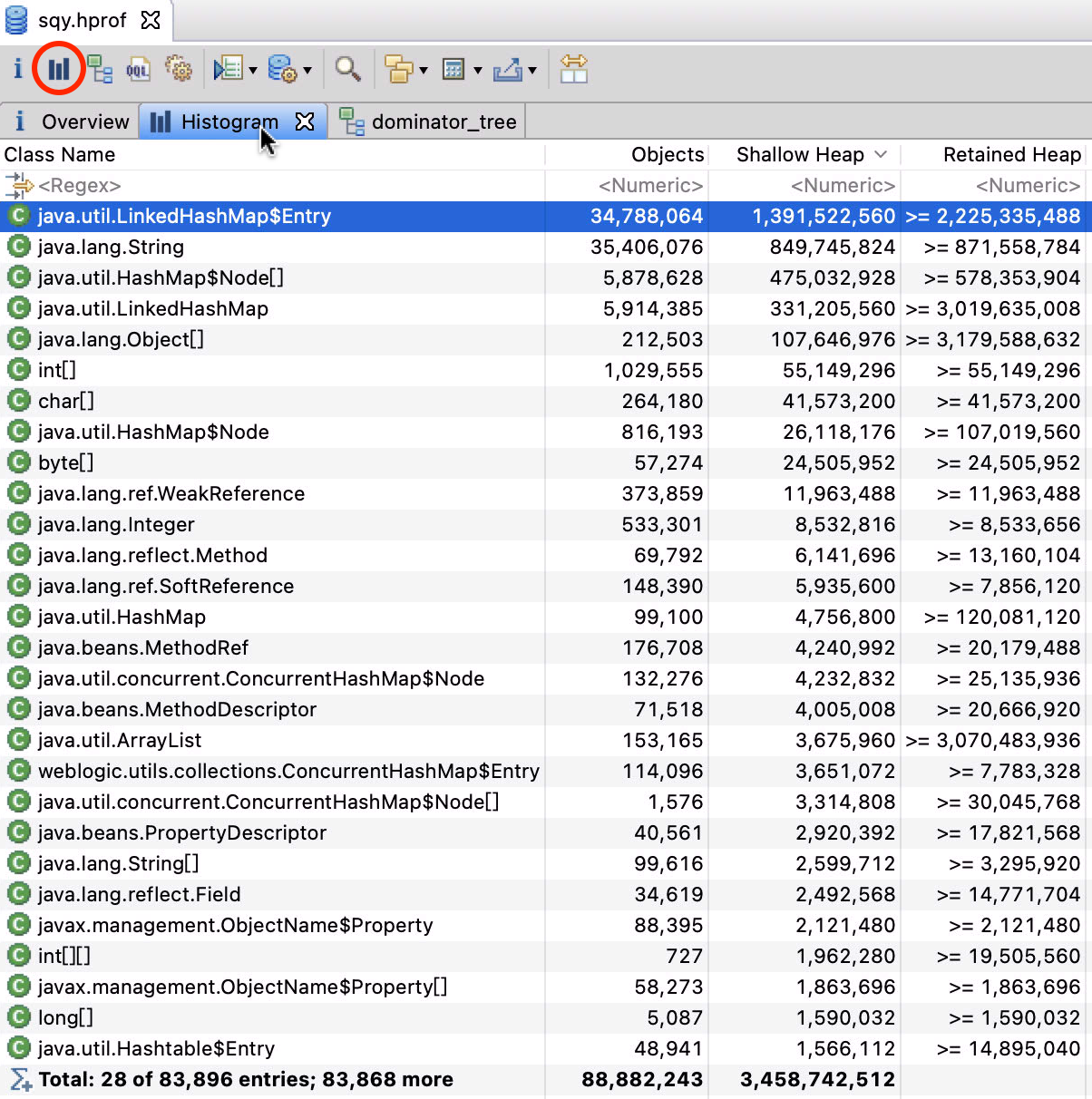
我们点击 mat 上这个柱状图的按钮,查看对象分布,发现大部分都是 LinkedHashMap$Entry 和 String
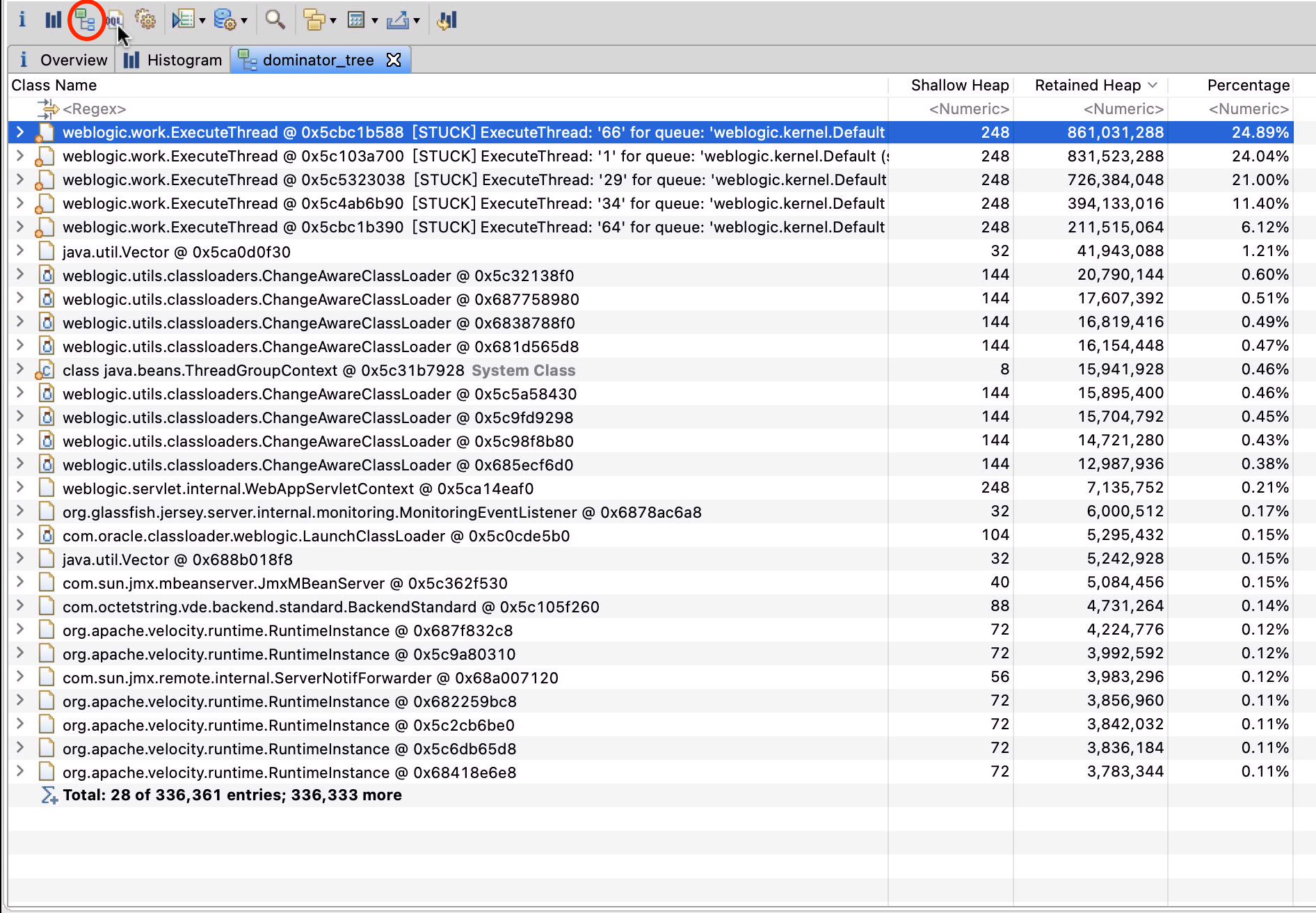
点击图中的树桩查看按钮,可以按照线程查看调用依赖图,发现有 5 个带STUCK字样的线程,他们加起来占用几乎 90%的内存空间!STCUK是什么鬼,Java 原生中线程可没有这个状态啊。
点开调用链路图,一大堆方法,各种类型,一下子看到我们公司的包名com.xxxx...,可是这最后的方法名,y00013Service不知为何意。
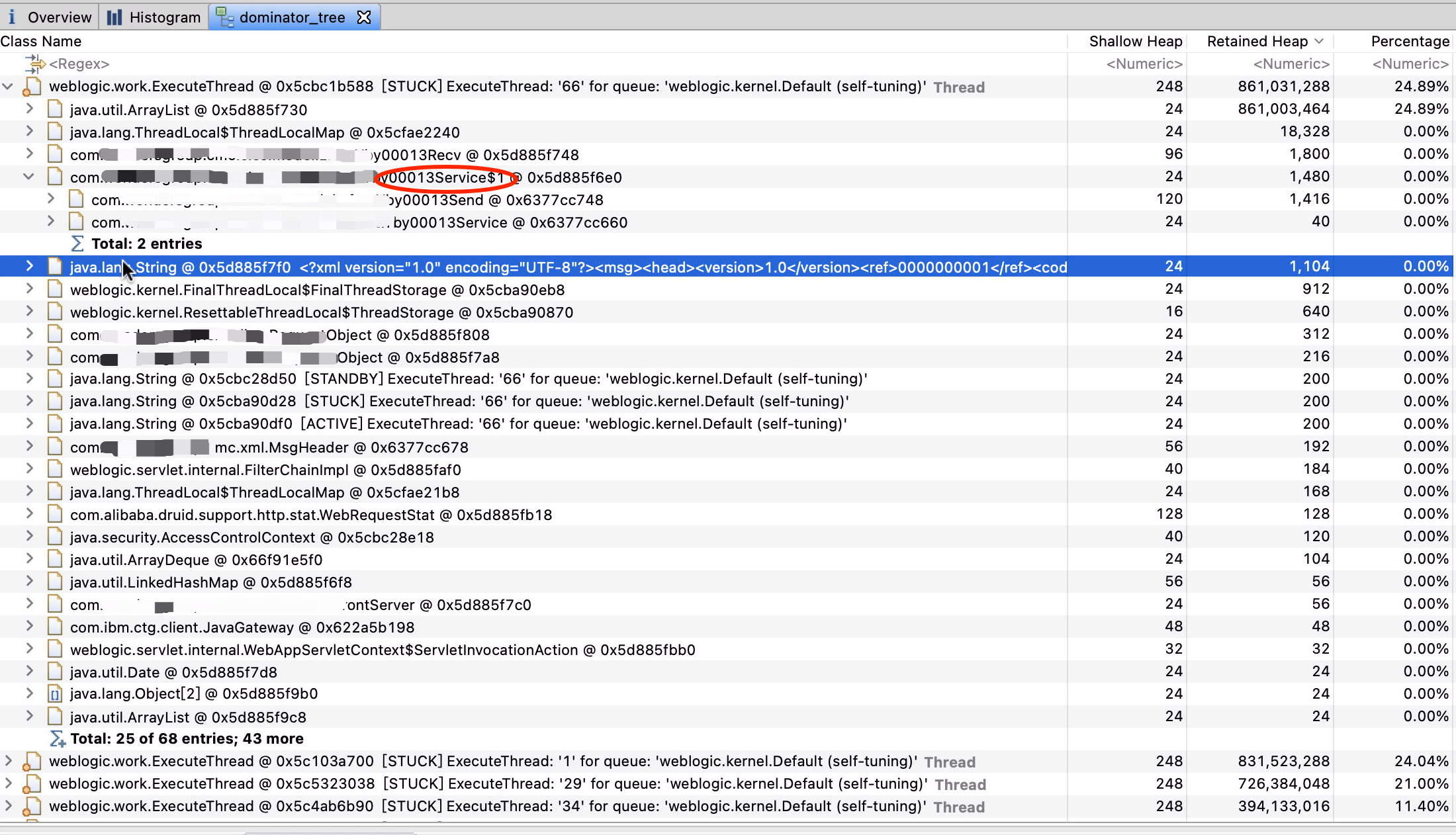
占用最高的 ArrayList 一级级展开,复制其中的一个 Value
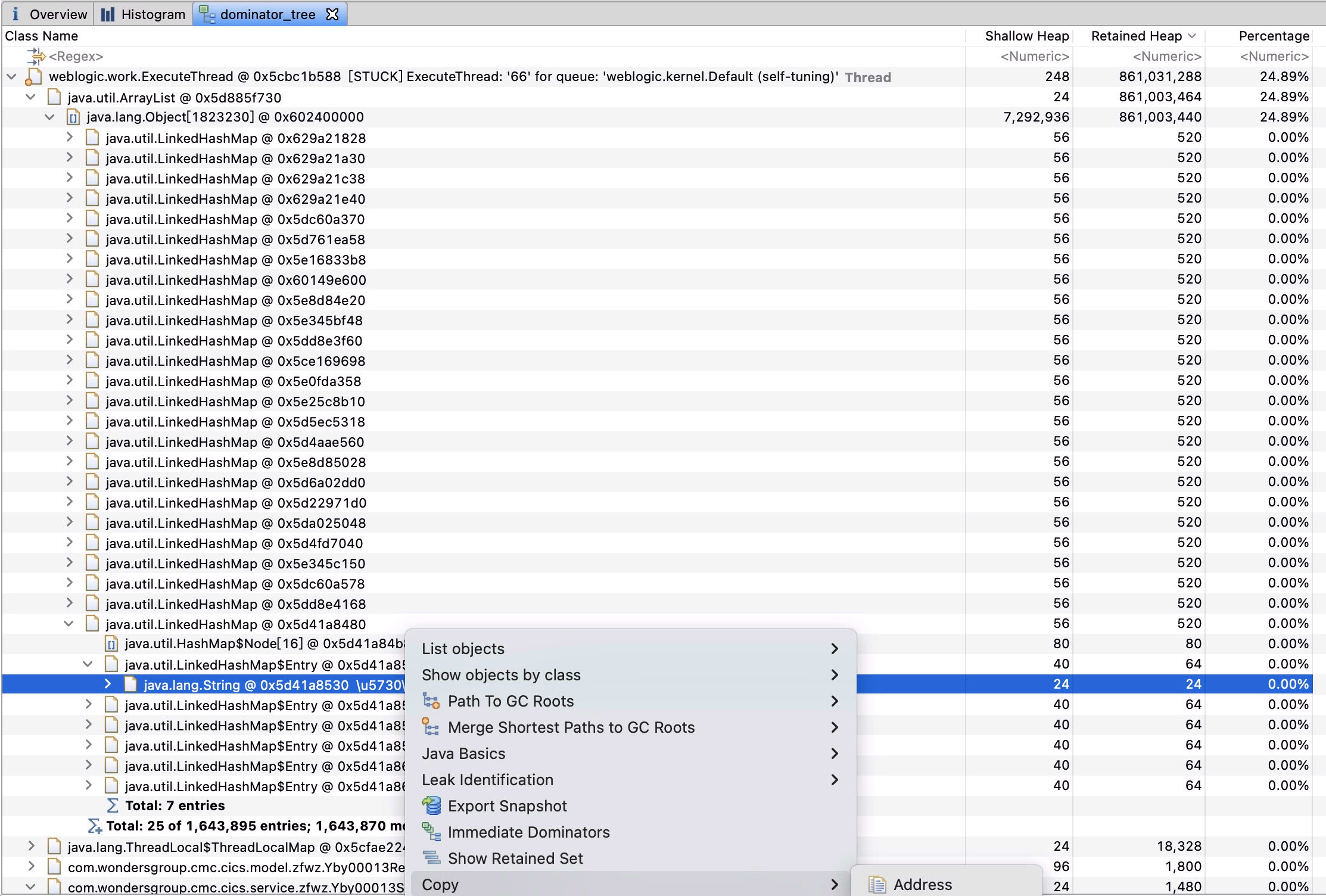
Unicode 转义后的值是 地塞米松

好像是一种药品名啊!
把负责该项目的同事喊来,他一眼看出,这就是一个项目中的一个接口啊,那个什么什么查询某种药品的(早知道刚开始就该带着他一起看,自己在这费劲看半天)。
立马翻出这个部分的代码查看,发现这是一个纯接口,它接收请求,然后去调用另一个服务接口查询数据,拼装组合一下再返回给调用方(你小子原来是个中间商啊)。
这个应用调用后端查询数据的时候,后端接口是支持分页的,他会不断的去多次调用来获取完整数据。

问题出在,这个应用在提供接口给外部的时候,没有做分页支持,并且所有传入参数都是可选的,没有校验,没有必填。
当没有任何参数填入的情况下,会遍历后端表中所有的数据。我去了解了下,大概有 7000 条数据,说多倒也不算多,测试显示一次调用还是能正常返回的,但是返回大概需要 20 秒以上。
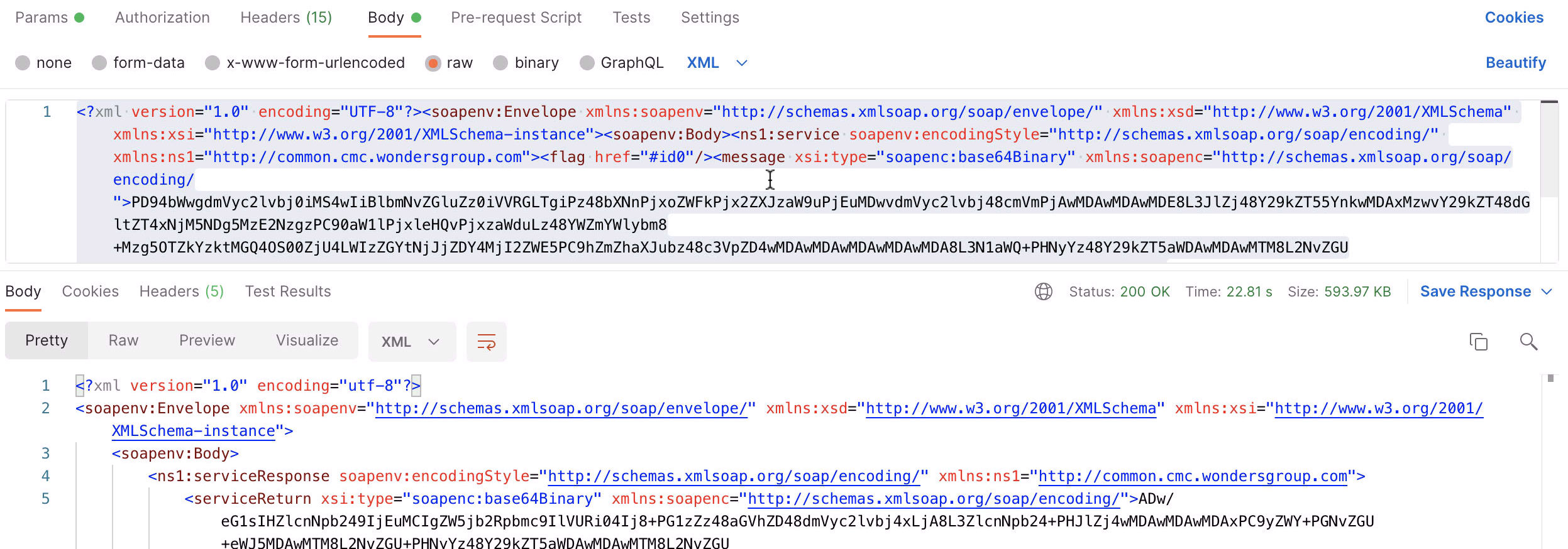
你说这用户受得了吗?不好意思,我们独一家,用户没得选。

那大概就是高峰期请求支撑不住了?为什么这个线程状态是 STCUK 呢,去 Oracle 官网文档找到两篇相关说明
Tuning stuck thread detection behavior
Tuning the Execute Thread Detection Behavior
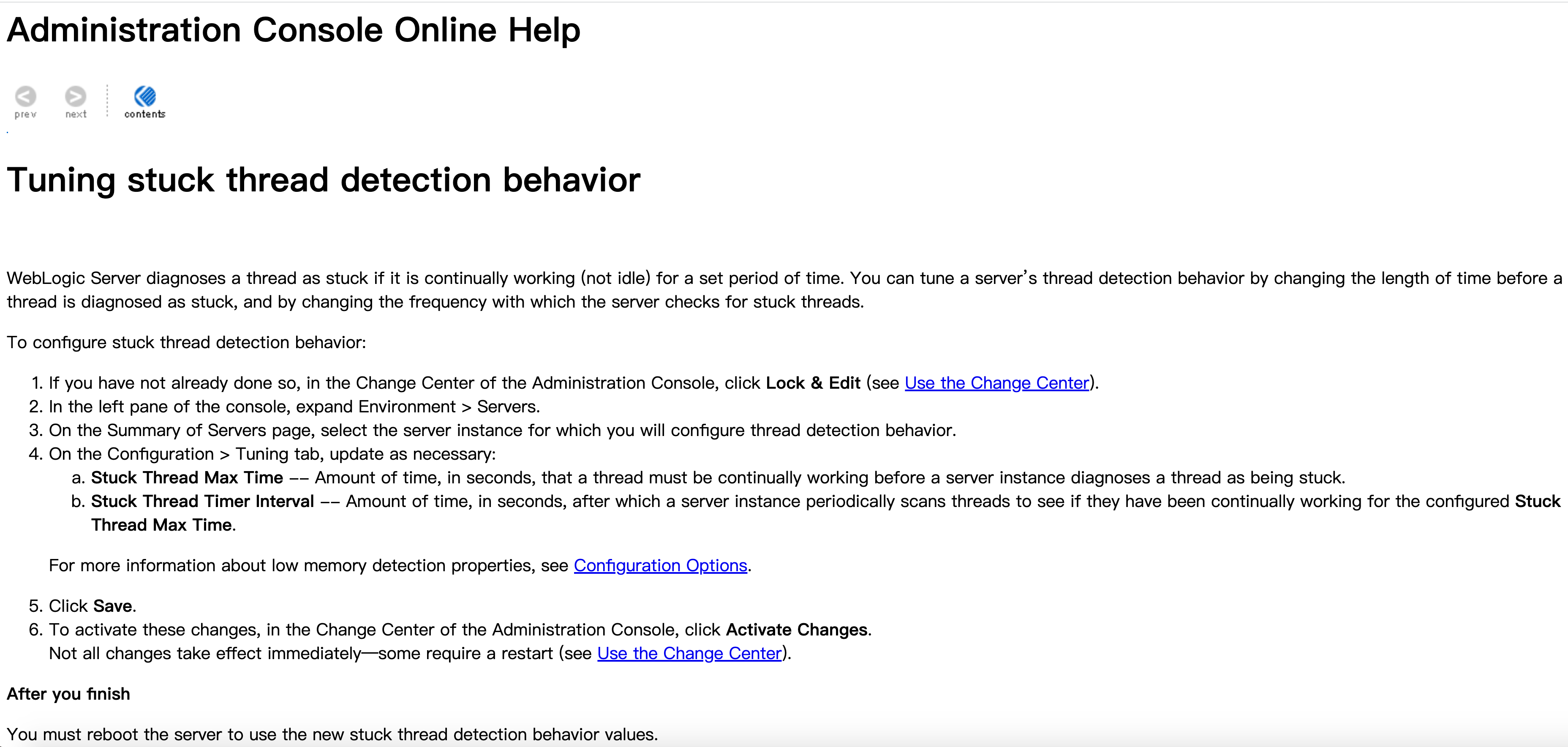

按照官网文档描述,STCUK 是 WebLogic 认为这个线程运行太久了有问题,于是标记为STUCK并且挂起这个线程,不再给时间运行,这个线程就一直占用着放在那里了。
那么问题来了,为什么以前好好的,并且默认配置是 60S 才挂起,现在的接口测试只需要 20S 就返回了,为什么就撑不住了呢?
立马上 Git 看看谁最近改了什么代码!--没有收获,最近的确没有变动代码。
去打听了一圈,才知道,这个接口业务侧有变动,以前只有十几个 B 端机构在用,现在开放给了普通个人用户,一下子几万人在用,压力骤增,这谁顶得住?

如此大的访问压力下,高峰期的响应时间可能会超过 60S,超过时间的会被 WebLogic 挂起,一直占着内存不释放。
原来如此!终于搞清楚了,秉着送佛送到西的精神,我继续给同事提供了几个处理方案:
- 使用缓存:调用后端另一个服务的地方加缓存,据说这个表中的固化数据据说几年都不变化的,完全可以用缓存下来。
- 对外接口变更,支持分页
- 对外接口处传入参数加校验,要求起码传 1~2 个参数,避免一次性查询太多数据,实际上用户根本看不了那么多数据
同事听了以后觉得很有道理,于是去跟领导汇报了,后来就没再听说有问题了,我也终于过的清净了。
某天,我上去维护,忽然发现这几台服务器还是 Warning,大吃一惊,问同事:之前的方案不好使吗?最近也没见喊我重启。
他说,解决了,领导大手一挥:加机器!我寻思这还能加到哪去?登录服务器一看

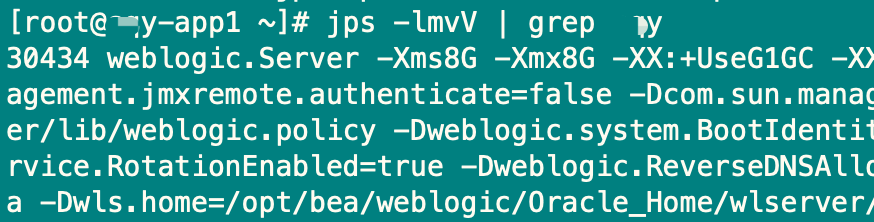
三台全部加到了 8C64G!
或许这就是金钱的力量吧。
