MongoDB的部署架构 mongodb常见部署方式如下: 各个节点含义 mongos : 路由节点,为业务程序提供集群单一入口,转发应用端请求。选择合适的数据节点进行读写,合并多个分片数据节点的
mongodb常见部署方式如下:
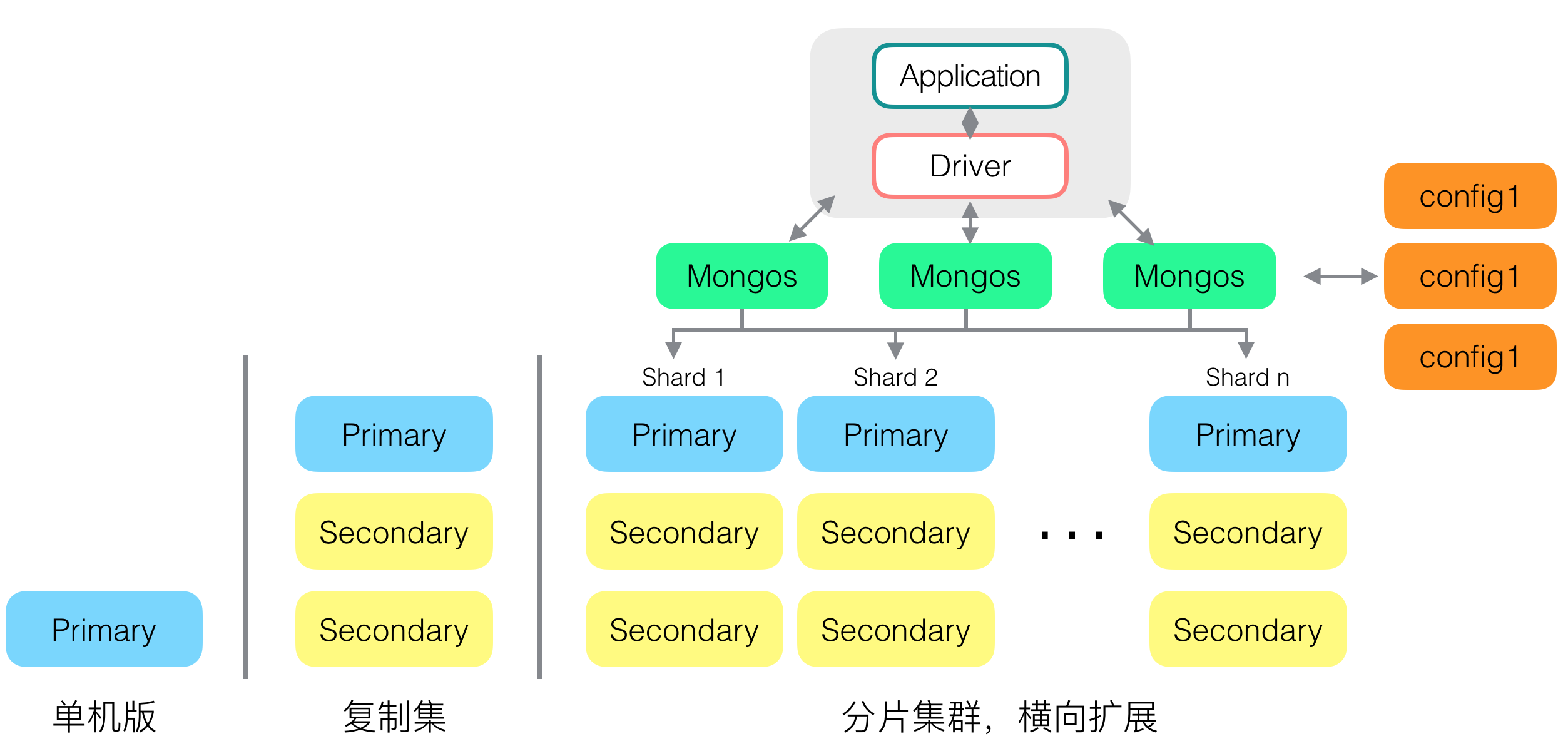
- mongos : 路由节点,为业务程序提供集群单一入口,转发应用端请求。选择合适的数据节点进行读写,合并多个分片数据节点的返回。无状态,至少2个。
- config: 配置节点,提供集群元数据的存储(数据节点有哪些),分片数据分布的映射,例如片键1-1000对应shard1, 片键1001-2000对应shard2。普通的复制集架构。
- Primary, Secondary: 数据节点,每个分片(shard)就是一个复制集,分片之间数据不重复。
- 对应用全透明,不用做修改
- 数据自动均衡
- 动态扩容,无须下线
- 提供三种分片方式
将片键取值范围按序切分成不同chunk
- 优点:查询性能好
- 缺点:数据分布可能不均匀,出现热点数据 e.g. 自增id范围分片,那么新数据总是写“最新”分片,出现“热写”
将片键取值通过hash分布到不同chunk
- 优点:数据分布均匀,写优化
- 缺点:范围查询效率低
给分片打标签,例如根据地域,分为北美,欧洲,国内等等,不同地域数据到不同分片
分片集应用 如何确定是否需要分片,多少分片考虑因素如下:
- 数据量:存储总量,单服务数据可挂载量
- 工作集大小:工作集包括热数据和索引,必须能够容纳进内存
- 并发量:业务端的并发峰值,单服务可支持并发量
考虑因素(其实和索引选择有很多相似点):
- 取值基数(Cardinality,在MySQL索引一章也讲过,是选择索引的参考因素)和取值分布
首先,chunk的个数一定是小于片键取值的个数,基数小的片键,例如只有10个取值,那么会导致大块(单个chunk数据容量大),大块会导致在水平扩展时,迁移chunk非常困难。其次,即使基数大,但分布不均,也会导致大块 - 尽量能够“分散写,集中度”。(写分布+定向查询)
分散写能应用分片集的优势,分担写primary的压力;集中读,能够减少访问多个分片并聚合数据这一步操作的性能损耗即定向性好,对主要查询有定向能力,如果用片键作为查询条件,mongos能定位到去哪个分片查,而不是分发到所有分片,再聚合结果 - 被尽可能多的业务场景用到
- 避免单调递增或递减的片键(避免热数据,热读写一个分片)