目录 优美图库 一、 网址分析 二、 编写代码 1、 获取每类图片的地址 2、 获取每张图片的地址 3、 得到每张图片下载地址 4、 下载每张图片 三、 总代码 优美图库一、 网址分析 打开网
- 优美图库
- 一、 网址分析
- 二、 编写代码
- 1、 获取每类图片的地址
- 2、 获取每张图片的地址
- 3、 得到每张图片下载地址
- 4、 下载每张图片
- 三、 总代码
打开网址里面对应的美女图片专栏通过分析工具可得:
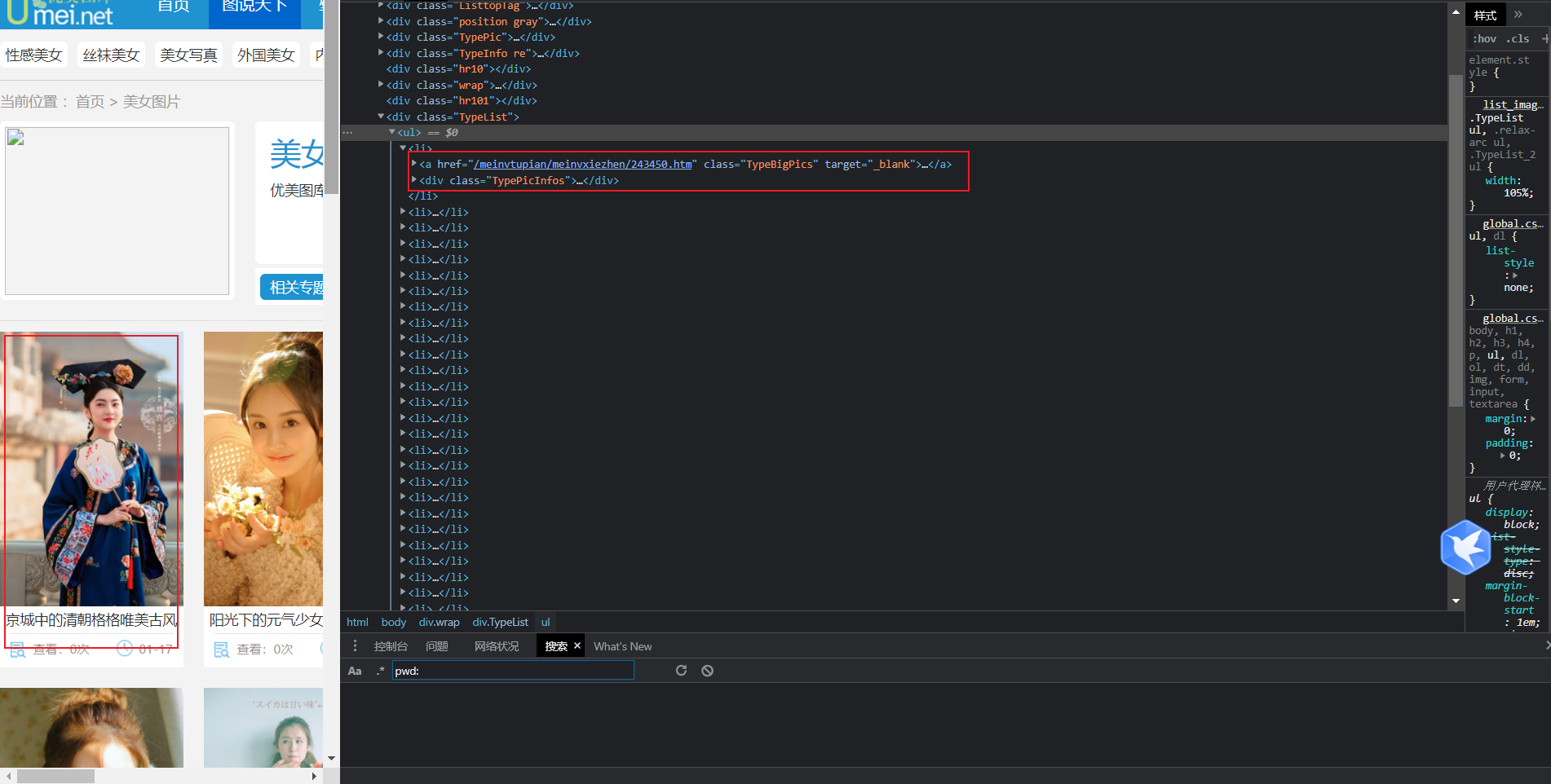
由此可得,图片导航所对应的 url ,都存在一个 li 标签里面
点开其中一个页面
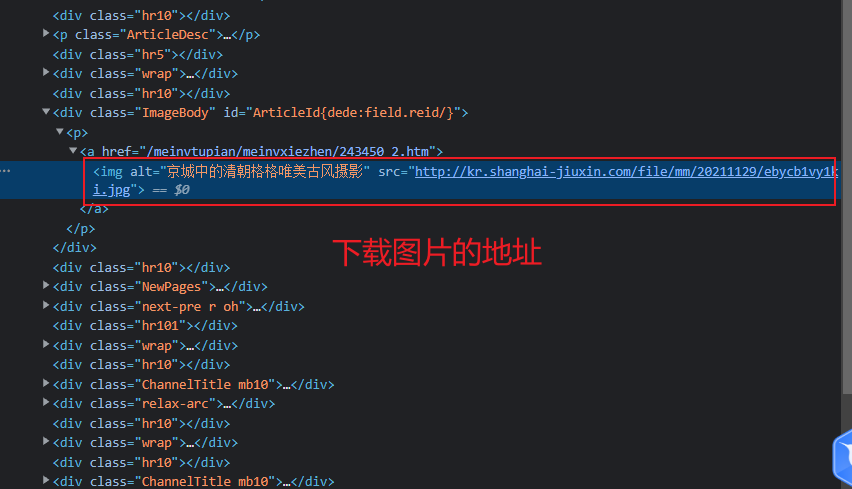
同时分析每一个页面的地址可得
https://www.umeitu.com/meinvtupian/meinvxiezhen/243450.htm 第一页
https://www.umeitu.com/meinvtupian/meinvxiezhen/243450_2.htm 第二页
https://www.umeitu.com/meinvtupian/meinvxiezhen/243450_3.htm 第三页
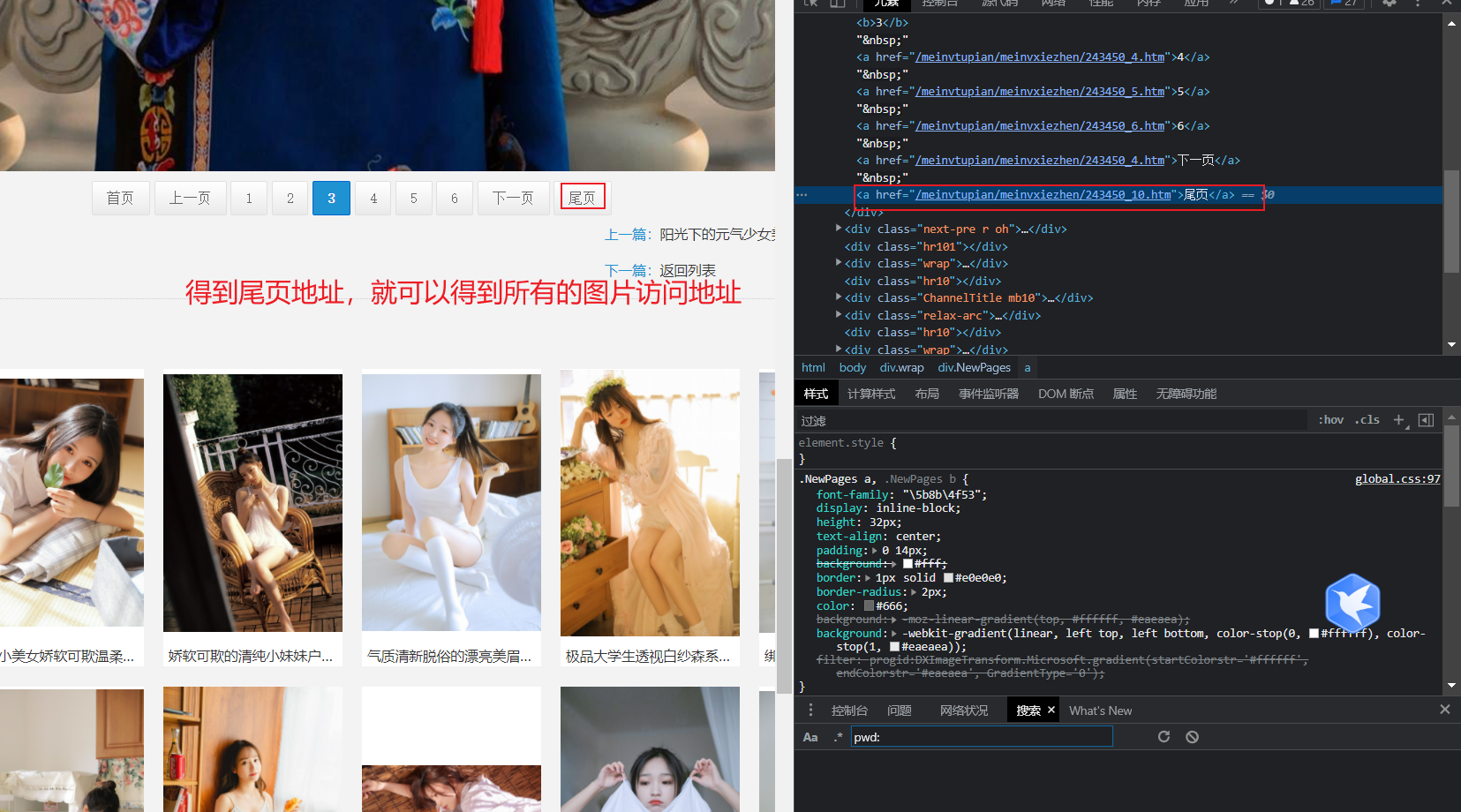
二、 编写代码 1、 获取每类图片的地址通过访问的地址就可以解析出下载地址,然后下载图片
from requests import get
from pyquery import PyQuery
from fake_useragent import UserAgent
class Spider:
def __init__(self, url):
self.url = url # 传入 url
self.__add_url = "https://www.umeitu.com" # 拼接 url
self.__class_href = [] # 存放每一类图片入口的 url
def __get_class_href(self) -> """获取 每一类图片入口 url""":
page_source = self.__get_page_source(self.url) # 调用函数
doc = PyQuery(page_source)(".wrap > .TypeList > ul > li")
for i in range(len(doc)):
href = doc.eq(i)("a").attr("href") # 获取 href 值
add_href = self.__add_url + href # 拼接 href
self.__class_href.append(add_href) # 存储 href 值
print(self.__class_href)
def __get_page_source(self, url) -> """访问 网址,传入 url 使其可以重复使用""":
while True:
try:
resp = get(url=url, headers={
"user-agent": UserAgent().random,
}, timeout=10)
except: # 防止出现报错
resp = None
if resp:
break
return resp.text # 得到页面源码
def main(self) -> """函数 入口""":
self.__get_class_href() # 获取每一类图片的 href
def __get_every_pic(self) -> """获取 每张图片的访问地址,并且下载图片""":
self.__get_class_href() # 得到每一类图片的 href
for i in self.__class_href: # 逐一访问
self.__dir_name = i.split("/")[-1] # 得到文件夹名字
if not path.exists(f"./{self.__dir_name}"):
mkdir(f"./{self.__dir_name}") # 创建文件夹,存储文件
page_source = self.__get_page_source(i) # 访问网址
doc = PyQuery(page_source)(".wrap > .NewPages > a").eq(-1).attr("href") # 得到图片数量
num = doc.split("_")[-1].split(".")[0]
for j in range(int(num)):
if j == 0:
self.__every_href.append(i)
else:
base = i.split("https://www.umeitu.com/")[-1].split(".")
href = "https://www.umeitu.com/" + base[0] + f"_{j + 1}." + base[-1]
self.__every_href.append(href) # 存储每个图片的访问地址
# print(self.__every_href)
# break
self.__get_download_url() # 得到图片下载地址
with ThreadPoolExecutor(int(num)) as pool: # 根据图片数量下载图片,下载图片
pool.map(self.__download_img, self.__pic_href) # 开启线程下载图片
self.__pic_href.clear() # 清空内容,防止被重复使用
# break
sleep(3)
def __get_download_url(self):
for i in self.__every_href: # for 循环遍历
page_source = self.__get_page_source(i)
href = PyQuery(page_source)(".ImageBody > p img").attr("src") # 得到存储图片的 href
self.__pic_href.append(href) # 收集 url
# print(href)
# break
self.__every_href.clear() # 清空列表中的内容
def __download_img(self, href):
resp = get(url=href).content
name = href.split("/")[-1]
with open(f"./{self.__dir_name}/{name}", "wb") as file:
file.write(resp)
from requests import get
from pyquery import PyQuery
from fake_useragent import UserAgent
from os import mkdir, path
from concurrent.futures import ThreadPoolExecutor
from time import sleep
from loguru import logger
class Spider:
def __init__(self, url):
self.url = url # 传入 url
self.__add_url = "https://www.umeitu.com" # 拼接 url
self.__dir_name = None # 存放图片名称
self.__class_href = [] # 存放每一类图片入口的 url
self.__every_href = [] # 存放每一张图片的入口 url
self.__pic_href = [] # 存放图片的 href
def __get_page_source(self, url) -> """访问 网址,传入 url 使其可以重复使用""":
while True:
try:
resp = get(url=url, headers={
"user-agent": UserAgent().random,
}, timeout=10)
except: # 防止出现报错
resp = None
if resp:
logger.info(f"{url}解析完成!")
break
return resp.text # 得到页面源码
def __get_class_href(self) -> """获取 每一类图片入口 url""":
page_source = self.__get_page_source(self.url) # 调用函数
doc = PyQuery(page_source)(".wrap > .TypeList > ul > li")
for i in range(len(doc)):
href = doc.eq(i)("a").attr("href") # 获取 href 值
add_href = self.__add_url + href # 拼接 href
self.__class_href.append(add_href) # 存储 href 值
# print(self.__class_href)
def __get_every_pic(self) -> """获取 每张图片的访问地址,并且下载图片""":
self.__get_class_href() # 得到每一类图片的 href
for i in self.__class_href: # 逐一访问
self.__dir_name = i.split("/")[-1] # 得到文件夹名字
if not path.exists(f"./{self.__dir_name}"):
mkdir(f"./{self.__dir_name}") # 创建文件夹,存储文件
page_source = self.__get_page_source(i) # 访问网址
doc = PyQuery(page_source)(".wrap > .NewPages > a").eq(-1).attr("href") # 得到图片数量
num = doc.split("_")[-1].split(".")[0]
for j in range(int(num)):
if j == 0:
self.__every_href.append(i)
else:
base = i.split("https://www.umeitu.com/")[-1].split(".")
href = "https://www.umeitu.com/" + base[0] + f"_{j + 1}." + base[-1]
self.__every_href.append(href) # 存储每个图片的访问地址
# print(self.__every_href)
# break
self.__get_download_url() # 得到图片下载地址
with ThreadPoolExecutor(int(num)) as pool: # 根据图片数量下载图片,下载图片
pool.map(self.__download_img, self.__pic_href) # 开启线程下载图片
self.__pic_href.clear() # 清空内容,防止被重复使用
# break
sleep(3)
def __get_download_url(self):
for i in self.__every_href: # for 循环遍历
page_source = self.__get_page_source(i)
href = PyQuery(page_source)(".ImageBody > p img").attr("src") # 得到存储图片的 href
self.__pic_href.append(href) # 收集 url
# print(href)
# break
self.__every_href.clear() # 清空列表中的内容
def __download_img(self, href):
resp = get(url=href).content
name = href.split("/")[-1]
logger.info(f"正在下载{name}")
with open(f"./{self.__dir_name}/{name}", "wb") as file:
file.write(resp)
def main(self) -> """函数 入口""":
self.__get_every_pic()
def thread(u) -> """开启多线程时 使用""":
s = Spider(u) # 实例化对象
s.main() # 调用接口
if __name__ == '__main__':
lis = [f"https://www.umeitu.com/meinvtupian/index_{i}.htm" for i in range(2, 546)]
lis.append("https://www.umeitu.com/meinvtupian/index.htm")
for url in lis:
s = Spider(url) # 实例化对象
s.main() # 调用接口
# break
sleep(5)
# # 使用多线程
# with ThreadPoolExecutor(20) as pool:
# pool.map(thread, lis)