一、问题背景 一个朋友在使用 XGBoost 框架进行机器学习编码,他们的一个demo, 在笔记本的虚拟机(4核)运行的时候,只要8s, 但是在一个64核128G 的物理机上面的虚拟机去跑的时候,发现时
-
一个朋友在使用 XGBoost 框架进行机器学习编码,他们的一个demo, 在笔记本的虚拟机(4核)运行的时候,只要8s, 但是在一个64核128G 的物理机上面的虚拟机去跑的时候,发现时间需要更长。
笔记本执行:

首先看到负载是比较高的,内存占用比较少。因为是计算型的,所以这种状态是正常的。
一开始我觉得是GIL 锁,后面询问是使用了 XGBoost 框架,想去官网看看能不能找到相关内容
XGBoost 多线程支持 文档的一段话提醒了我:
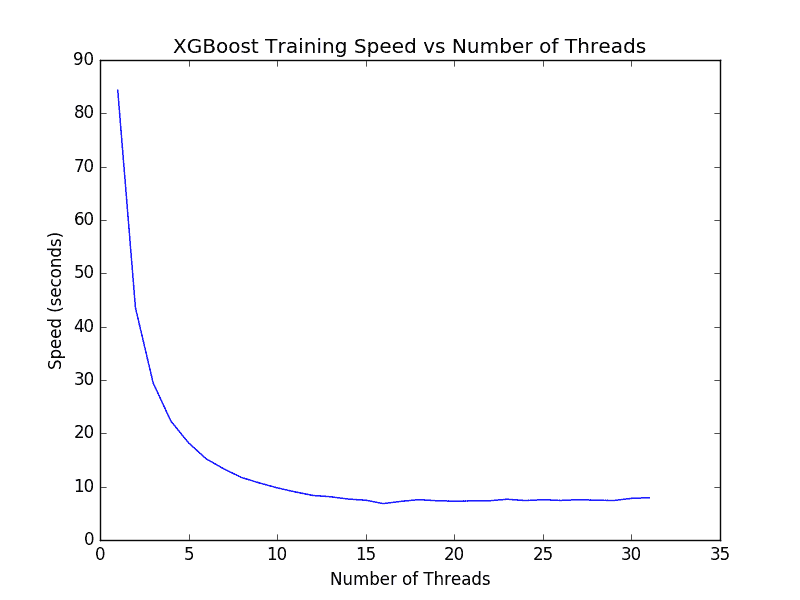
我们可以在具有更多核心的机器上运行相同的代码。例如大型的 Amazon Web Services EC2 具有 32 个核心。我们可以调整上面的代码来计算具有 1 到 32 个核心的模型所需的训练时间。结果如下图。
XGBoost 在 1 到 32 个核心上训练模型所需的时间
值得注意的是,在多于 16 个线程(大约 7 秒)的情况下,我们没有看到太多进步。我想其原因是 Amazon 仅在硬件中提供 16 个内核,而另外的 16 个核心是通过超线程提供额外。结果表明,如果您的计算机具有超线程能力,则可能需要将 num_threads 设置为等于计算机中物理 CPU 核心的数量。
示例: https://github.com/dmlc/xgboost/blob/master/demo/guide-python/sklearn_parallel.py
我们通过示例将 n_job 的值调整为 cpu 核心的一半,
n_jobs=multiprocessing.cpu_count()//2
发现解决了问题
