大家好,这是一个为了梦想而保持学习的博客。这个专题会记录我对于 KAFKA 的学习和实战经验,希望对大家有所帮助。
【生产 / 消费者模型】
从上一节,我们知道消息中间件是由生产 / 消费者模型独立演化出来的,将对应的内存队列单独抽取成一个服务进行部署,以应对各个进程之间的需求。

之后,我们的重点会落在 Broker 端的设计,真正的看一下,我们的服务端做了哪些架构设计,分别有什么作用?
【Topic】
Topic,我们称之为主题。一句话概括它的作用:Topic 是我们进行生产 / 消费的宏观概念。
翻译一下:就是我们生产者在生产消息的时候,要指定某个 Topic;我们消费者在消费消息的时候,也要指定某些 Topic。
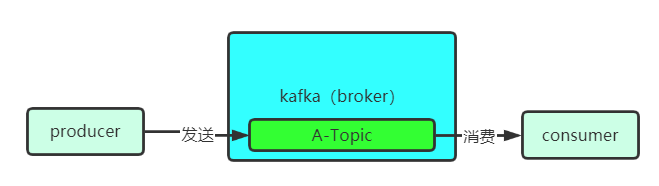
我们再细究一下上面的话,为什么说 Topic 是一个宏观的概念呢?
【Partition】
Partition,我们称之为分区。一句话概括它的作用:Partition 是我们进行生产 / 消费的真正实体。
翻译一下:就是我们生产者在生产消息的时候,实际上是写到了某个 Topic 的某个分区中;我们消费者在消费消息的时候,实际上也是消费的某个 Topic 的某些分区。
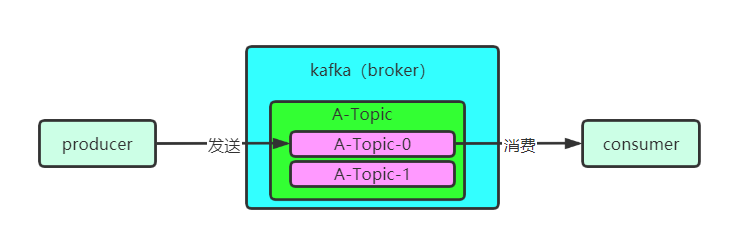
从上图,我们就可以明白一件事:Topic 是某一类消息的逻辑集合,内部包含一个个分区实体,我们生产消费的实际对象都是某个 Topic 的某个分区。
就像上图中的,【A-Topic-0】,这是什么意思呢,也就是【主题名称 - 分区编号】
主题名称呢,一般代表着这个 Topic 是用来存放什么类型的数据的,例如 Order-Topic,就是用来存放订单相关的数据的。
分区编号呢,就是我们在创建 Topic 的时候需要指定分区个数,上图中就有两个 Partition,然后分区的编号都是从 0 开始的,所以我们就能看到这样的一个表示。
【Replica】
Replica,我们称之为副本。一句话概括它的作用:Replica 是针对 Partition 进行数据冗余,以实现数据的的高可靠,还有整个服务的高可用 (这个后续章节细说)。
翻译一下:副本就是把某个分区的数据全量拷贝 N 份,然后分散到不同的机器上,这样就能防止某台机器宕机之后数据丢失的问题。
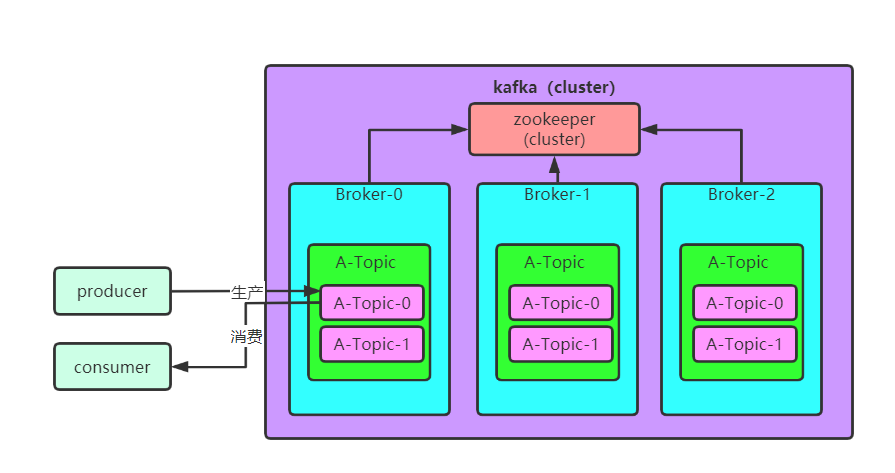
以上图为例,存在以下角色:
主题名称:A-Topic
分区数量:2
副本数量:3
上图就是一个 KAFKA 集群完整的角色模型概览图,我们最后一起统一概述一下上面的三个角色:
Topic 是一类消息的逻辑概念,而实际上进行生产消费的是 Topic 下的一个个分区,而每个分区会有一份份的数据冗余分在在集群不同 Broker 上,这些数据冗余,我们称之为 Replica(副本)。