本篇对一些常用的java知识做一个整合,三大特性、IO操作、线程处理、类集处理,目的在于能用这些只是实现一个网页爬虫的功能。
Ⅰ 首先对于一个java开发的项目有一个整体性的了解认知,项目开发流程:
项目阶段:
1)项目准备:
a)根据开会得到会议纪要,了解客户的需求情况
b)需求分析(需求分析文档)
c)数据库设计和网站(产品)原型设计
d)架构设计
2)项目开发
a)项目组长(PM,PL)进行项目的时间规划,并划分好每个人的工作任务
b)程序员主要完成项目代码编写和详细设计文档编写。(用户手册)
3)测试
a)单元测试
b)集成测试
c)压力测试
d)回归测试
4)上线实施
Ⅱ 三大特性(封装、继承、多态)
封装
1、 封装重点在于一个private关键字,目的是为了让类中的属性不能直接修改或取得。也就是说,建立一个类时,所有的属性都必须通过private进行封装。
既然属性被封装了,那么如果想设置或取得属性,就必须编写getter/setter方法。
同时,类中在创建对象时,为了方便,一般建议编写一些带参数的构造方法。
如果不编写构造方法,程序会自动加入一个无参的构造,但是,如果自己声明了构造方法,那么必须就手工加入一个无参构造,为了让其他的框架可以通过无参数构造来创建对象。
2、 如果数据库中有一张表,则需要你能根据表编写一个这样的类。
这种类被称为:VO(Value Object)、TO(Transfer Object)、POJO(Plain Olds Java Object)、DTO(DaTa Object)等
class Person {
private String name;
private Integer age;
public Person() {
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return this.name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public void setName(String name) {
this.name = name;
}
}
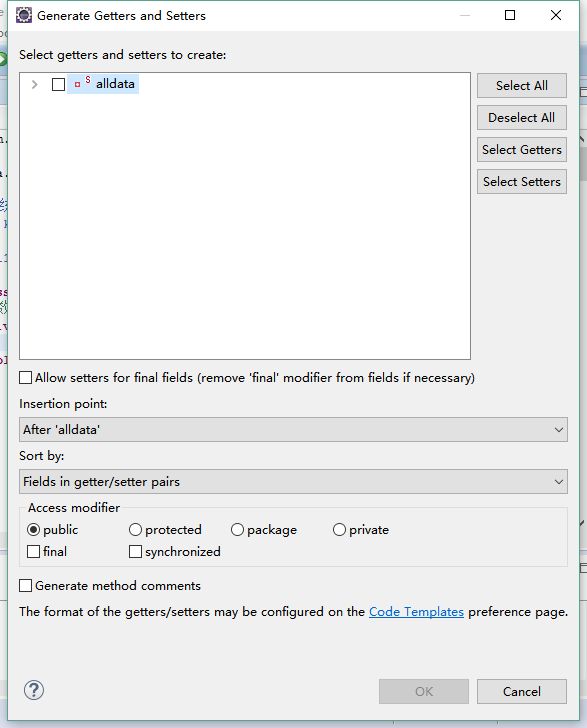
技巧:在eclipse中编写封装类,可以声明变量后,按shift+Alt+s键出现Generate Getters and Setters提示创建getter和setter方法。
继承关系
继承所使用的关键字:extends,接口实现所使用的关键字是:implements。
Java开发中对于接口和抽象类区别主要是单继承和多继承。
真正开发中接口用的更多,几乎不编写抽象类。
一般都是以接口作为标准来进行声明。
这部分我们要求能够掌握接口的声明和实现方法。
interface Animal {
public void cry();
public void run();
}
class Cat implements Animal {
@Override
public void cry() {
System.out.println("miao");
}
@Override
public void run() {
System.out.println("猫爬树");
}
}
多态
其实就是在继承的基础上进行方法覆写和子类转型。
package org.liky.test;
public class InterfaceDemo {
public static void main(String[] args) {
Animal a1 = new Cat();
Animal a2 = new Dog();
a1.cry();
a2.cry();
}
}
interface Animal {
public void cry();
public void run();
}
class Cat implements Animal {
@Override
public void cry() {
System.out.println("miao");
}
@Override
public void run() {
System.out.println("猫爬树");
}
}
class Dog implements Animal {
@Override
public void cry() {
System.out.println("Wang");
}
@Override
public void run() {
System.out.println("狗游泳");
}
}
单例设计模式
单例模式有以下特点:
1、单例类只能有一个实例。
2、单例类必须自己创建自己的唯一实例。
3、单例类必须给所有其他对象提供这一实例。
package org.liky.test;
public class TestSingleton {
public static void main(String[] args) {
Singleton s1 = Singleton.getInstance();
Singleton s2 = Singleton.getInstance();
Singleton s3 = Singleton.getInstance();
//其实只创建了一个对象
System.out.println(s1 + " --> " + s2 + " --> " + s3);
}
}
class Singleton {
private static final Singleton instance = new Singleton();
private Singleton() {
}
public static Singleton getInstance() {
return instance;
}
}
Ⅲ IO操作
文件内容读取:
File、FileReader、FileWriter、BufferedReader、BufferedWriter、Scanner、InputStreamReader
文件夹遍历:
File
文件复制操作
如果想操作文件的内容(对内容进行写出和读取),需要使用到的就是IO流中的输入输出操作。
这种输入和输出的操作流有两种:
1)字符流:主要操作文本文件(编写爬虫操作时,肯定要使用字符流来完成)
a)读:FileReader
b)写:FileWriter
2)字节流:所有文件都可以使用这种流操作
a)读:InputStream
b)写:OutputStream
需要能够通过我们这里的FileReader和FileWriter配合文件类:File,完成内容的读取和写出。
/**
* IO流操作的演示类,用来演示文本文件的写出和读取
*
* @author Liky
*
*/
public class FileTest {
public static void main(String[] args) {
// 写出内容
// writeData(
// "D:/test.txt",
// "这是“吉林一号”视频卫星 8月9日11时25分拍摄的 九寨沟县视频 显示了九寨沟县的地形地貌 县城呈狭长分布 周边山体有明显滑坡痕迹 视频中还可见县城道路大部分完好 有车辆通行 一架飞机飞过 地面与空中交通并未中断 图像提供:长光卫星技术有限公司 技术支持:北京爱太空科技发展有限公司");
System.out.println(readData("D:/test.txt"));
}
/**
* 写出数据
*
* @param filePath
* 文件保存的位置
* @param data
* 要保存的文件内容数据
*/
public static void writeData(String filePath, String data) {
// 先有一个文件,来保存要写出的数据
File file = new File(filePath);
// 建立输出流对象
try {
FileWriter writer = new FileWriter(file);
// 开始完成内容的输出
writer.write(data);
// 资源必须回收,也就是必须将流关闭
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 读取数据
*
* @param filePath
* 要读取的文件所在的完整路径
* @return 读取出来的文档内容
*/
public static String readData(String filePath) {
// 也要建立文件对象
File file = new File(filePath);
// 建立读取的输入流对象
try {
FileReader reader = new FileReader(file);
// 每次调用read可以读取一个字符,
// 按照int类型返回,返回的是字符的编码,
// 需要通过强制类型转换,变为char类型
// Java中对于String这个类一般不建议反复修改,因为会占用内存。
StringBuilder builder = new StringBuilder();
// 因为文件中有很多的字符,因此需要循环来进行内容的读取。
// 就需要判断是否还有字符进行读取
int value = -1;
// 每次读取时,如果读到内容,则会返回 0 - 65535 的char类型字符
// 如果没有读取到内容,则返回 -1 ,因此我们可以根据这个 -1 来判断后面是否还有内容
while ((value = reader.read()) != -1) {
// 将读取到的内容保存下来
char c = (char) value;
// 把字符放入到StringBuilder里
builder.append(c);
}
// 没有读取到内容,说明循环结束,已经到了文件的末尾
return builder.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
目前这样编写已经可以实现内容的输入和输出操作了。
但是还不支持换行操作,如果想换行,需要人工进行\r\n的编写。
如果不想人工编写换行,就可以使用以下两个类来完成输入。
PrintWriter(打印流)
BufferedWriter(缓冲流)
public static void writeData(String filePath, String... data) {
// 先有一个文件,来保存要写出的数据
File file = new File(filePath);
// 建立输出流对象
try {
// FileWriter writer = new FileWriter(file);
PrintWriter pw = new PrintWriter(file);
// 开始完成内容的输出
for (String str : data) {
pw.println(str);
}
// 资源必须回收,也就是必须将流关闭
pw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
使用时,注意我们这里加入了可变参数来动态传入多个字符串(即String... data)。
当读取数据时,如果我们使用普通的读取方式,对于换行的处理不方便。
如果想按行读取内容,可以使用BufferedReader,Scanner
Scanner是JDK1.5新的
BufferedReader是JDK1.0就有的,所以使用BufferedReader。
为什么现在还使用BufferedReader,因为Scanner不支持编码的转换。
public static String readData(String filePath) {
// 也要建立文件对象
File file = new File(filePath);
// 建立读取的输入流对象
try {
FileReader reader = new FileReader(file);
BufferedReader bw = new BufferedReader(reader);
// 每次调用read可以读取一个字符,
// 按照int类型返回,返回的是字符的编码,
// 需要通过强制类型转换,变为char类型
// Java中对于String这个类一般不建议反复修改,因为会占用内存。
StringBuilder builder = new StringBuilder();
// 因为文件中有很多的字符,因此需要循环来进行内容的读取。
// 就需要判断是否还有字符进行读取
String line = null;
// 每次读取时,如果读到内容,则会返回 0 - 65535 的char类型字符
// 如果没有读取到内容,则返回 -1 ,因此我们可以根据这个 -1 来判断后面是否还有内容
while ((line = bw.readLine()) != null) {
// 将读取到的内容保存下来
// 把字符放入到StringBuilder里
builder.append(line);
System.out.println(line);
}
// 没有读取到内容,说明循环结束,已经到了文件的末尾
return builder.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
例如,将一个D盘的test.txt的内容读取出来,再写出到E盘的test.txt中
public static void copyFile(String inputFile, String outputPath) {
// 首先建立输入和输出的文件
File input = new File(inputFile);
File output = new File(outputPath);
// 建立输入和输出流
try {
BufferedReader br = new BufferedReader(new FileReader(input));
PrintWriter pw = new PrintWriter(output);
// 每次读入一行,所以准备一个变量来接收
String line = null;
while ((line = br.readLine()) != null) {
pw.println(line);
}
pw.close();
br.close();
} catch (Exception e) {
e.printStackTrace();
}
}
文件夹迭代
这里只需要用到一个File类,但需要用里面的一些方法来判断是文件还是文件夹
isFile():是否是文件
isDirectory():是否是文件夹
还需要通过递归操作,将目录下的所有子目录也进行迭代。
多线程处理
使用多线程的目的肯定是为了提升程序的效率。
因为在进行网络数据爬取时,一般都是同时爬取多个网页的数据,而不是单个网页,因此在项目开发中我们需要通过多线程,来让程序同时完成多个操作。
多线程有两种实现方式:
1)继承Thread类
2)实现Runnable接口
使用多线程时,还有两个必须注意的方法:
1)start()启动线程
2)run()编写线程执行的主体。
先来完成一个倒计时功能:
public class ThreadDemo {
public static void main(String[] args) {
// new MyThread().start();
// new Thread() {
// public void run() {
// for (int i = 10; i >= 0; i--) {
// System.out.println("剩余时间:" + i);
// try {
// Thread.sleep(100);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// }
// }
// }.start();
// new Thread(new MyRunnable()).start();
}
}
//继承Thread类必须重写run类
class MyThread extends Thread {
@Override
public void run() {
for (int i = 10; i >= 0; i--) {
System.out.println("剩余时间:" + i);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 10; i >= 0; i--) {
System.out.println("剩余时间:" + i);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
类集处理
List:允许重复,可以根据下标来取得数据,会按照放入的顺序来存储数据。
ArrayList:以数组的形式存储,适合不经常变动,但经常查询的数据集。
LinkedList:以链表的形式存储,适合经常变动的数据集,但是不经常查询
public class ListDemo {
public static void main(String[] args) {
LinkedList<Integer> list1 = new LinkedList<>();
for (int i = 0; i <= 100000; i++) {
list1.add(i);
}
long start = System.currentTimeMillis();
for (int i = 0; i <= 100000; i++) {
list1.get(i);
}
long end = System.currentTimeMillis();
System.out.println("ArrayList: " + (end - start) + " ms");
}
}
Set:不允许重复,存储顺序看心情,没办法根据下标取得数据
HashSet:散列排序(没有顺序)
TreeSet:二叉树排序,按照固定的规则来排序,TreeSet中的内容必须实现一个Comparable的接口,并且必须覆写compareTo的方法,根据给定的规则来排序。
public class SetDemo {
public static void main(String[] args) {
Set<Person> set = new TreeSet<>();
set.add(new Person("张三", 12));
set.add(new Person("李四", 22));
set.add(new Person("王五", 42));
set.add(new Person("王八", 42));
set.add(new Person("赵六", 32));
System.out.println(set);
}
}
class Person implements Comparable<Person> {
private String name;
private Integer age;
public Person() {
super();
}
public Person(String name, Integer age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Person o) {
if (this.age > o.age) {
return 1;
} else if (this.age < o.age) {
return -1;
}
if (this.name.equals(o.name)) {
return 0;
}
return 1;
}
}
Map:key-value形式,可以根据key取得value,key按照Set集合的模式来保存。
HashMap:散列
TreeMap:有顺序
对于Map集合,要求能够循环迭代出里面的所有数据。
所以必须掌握Map的循环方法。
public class MapDemo {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("方便面", 20);
map.put("火腿肠", 120);
map.put("矿泉水", 20);
map.put("可乐", 30);
// Map集合如果想迭代必须先按照key来进行迭代,
// 再根key查找value
Set<String> keySet = map.keySet();
for (String key : keySet) {
System.out.println(key + " ---> " + map.get(key));
}
}
}
小结:
本篇对于java封装、继承、多态三大特性,IO操作,线程管理,类集处理(List、Set、Map)进行了阐述以及代码实现。
到此,对于网页数据的爬写的知识准备的可以了,下一篇我会先对一个文件进行数据爬取,然后再对网页上的数据代码实现爬虫功能
到此这篇关于Java实现网络数据提取所需知识点的文章就介绍到这了,更多相关Java实现网络数据提取内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!