目录 1、扩展正则表达式说明 2、练习 (1) + 和 ? 练习 (2) | 和 () 练习 3、注意(重点) 1、扩展正则表达式说明 熟悉正则表达式的童鞋应该很疑惑,在其他的语言中是没有扩展正则
- 1、扩展正则表达式说明
- 2、练习
- (1)
+和?练习 - (2)
|和()练习
- (1)
- 3、注意(重点)
熟悉正则表达式的童鞋应该很疑惑,在其他的语言中是没有扩展正则表达式说法的,在Shell的正则表达式中还可以支持一些元字符,比如+、?、|、()。
其实Linux系统是支持这些字符的,只是grep命令默认不支持而已(grep命令无法识别扩展正则表达式)。
如果要想支持这些字符,必须使用egrep命令或grep -E选项,才能识别扩展正则表达式的字符,所以我们又把这些字符称作扩展字符。
egrep命令和grep -E命令是一样的,所以我们可以把两个命令当做别名来对待。
扩展正则表达式符号如下:
+
前一个字符匹配1次或任意多次。如
go+gle会匹配gogle、google或gooogle,当然如果o有更多个,也能匹配。
?
前一个字符匹配0次或1次。如
colou?r可以匹配colour或color。
`
`
()
匹配其整体为一个字符,即模式单元。可以理解为由多个单字符组成的大字符。如
(dog)+会匹配dog、dogdog、dogdogdog等,因为被()包含的字符会当成一个整体。但`hello (world 2、练习 (1)
+和?练习
如下文本:
Stay hungry, stay foolish. ——Steve Jobs
求知若饥,虚心若愚。——乔布斯
Stay hungry, stay flish. ——Steve Jobs
Stay hungry, stay folish. ——Steve Jobs
Stay hungry, stay fooolish. ——Steve Jobs
Stay hungry, stay foooolish. ——Steve Jobs
Stay hungry, stay fooooolish. ——Steve Jobs
+
+表示匹配前一个字符1次或任意多次。
执行命令:grep -E "fo+l" test2.txt
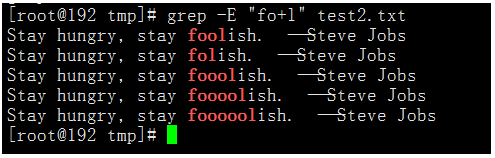
我们可以看到foolish单词中,有o的全部匹配到了,而flish被过滤掉。?
?表示匹配前一个字符0次或1次。
执行命令:grep -E "fo?l" test2.txt
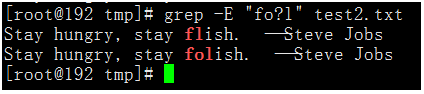
- 最后我们再来看一下
*。
*表示匹配前一个字符匹配0次或任意多次。
执行命令:grep -E "fo*l" test2.txt
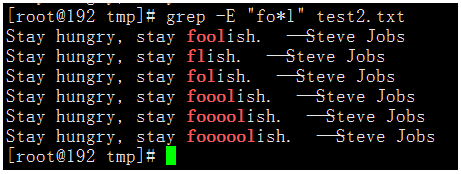
可以看出,+和?就相当于把*从1的位置分成了两部分,?是匹配前一个字符0次或1次,+是匹配前一个字符1次或任意多次。
|和()练习
这两个符号经常会联合使用。
|匹配两个或多个分支选择,表示或者的意思。
()匹配其整体为一个字符,表示整体的意思。
练习:匹配IP地址。
文本内容如下:
192.168.1.222
6666666666666
执行命令:grep -E "^(([0-9]\.)|([1-9][0-9]\.)|(1[0-9][0-9]\.)|(2[0-4][0-9]\.)|(25[0-5]\.)){3}(([0-9])|([1-9][0-9])|(1[0-9][0-9])|(2[0-4][0-9])|(25[0-5]))$" text3.txt

在Shell中能识别的正则表达式就是这些了。
3、注意(重点)通过正则表达式匹配邮箱来说明:
匹配邮箱正则如下:
[0-9a-zA-Z_]+@[0-9a-zA-Z_]+(\.[0-9a-zA-Z_]+){1,3}
说明:
[0-9a-zA-Z_]+(邮箱名称):表示数字、小写字母、大写字母、下划线可以重复最少1次。[0-9a-zA-Z_]+(邮箱域名):表示数字、小写字母、大写字母、下划线可以重复最少1次。(\.[0-9a-zA-Z_]+){1,3}:表示数字、小写字母、大写字母、下划线可以重复最少1次,整体可重复1到3次。比如:处理com.cn格式等。
特别注意:
我们可以看到上边
{1,3},并没有写成基础正则表达式\{1,3\}的样式。是因为
grep -E命令支持标准的正则表达式格式,不再需要对{}进行转义,如果加上转义符,还会报错。这点需要特别注意一下。