不平衡数据集是指类别分布严重偏斜的数据集,例如少数类与多数类的样本比例为 1:100 或 1:1000。
训练集中的这种偏差会影响许多机器学习算法,甚至导致完全忽略少数类,容易导致模型过拟合,泛化能力差。
所以,针对类别分布不均衡的数据集,一般会采取采样的方式,使得类别分布相对均衡,提升模型泛化能力。
下面介绍几种常见的采样方法及其原理,均是基于imbalanced-learn的实现:
随机采样:
- 随机过采样:从少数类中随机选择示例,并进行替换,然后将它们添加到训练数据集中;
- 随机欠采样:从多数类中随机选择示例,并将它们从训练数据集中删除;
朴素重采样,对数据没有任何假设,也没有使用启发式方法。所以,易于实现且执行速度快,这对于非常大和复杂的数据集来说是ok的。
需注意的是,对类分布的更改仅适用于训练数据集,目的是优化模型的拟合;重采样不适用于评估模型性能的测试集。
这种技术对于受偏态分布影响并且给定类的多个重复示例会影响模型拟合的机器学习算法非常有效。
这可能包括迭代学习系数的算法,例如使用随机梯度下降的人工神经网络,它还可能影响寻求数据良好拆分的模型,例如支持向量机和决策树。
调整目标类分布可能很有用,但在某些情况下,为严重不平衡的数据集寻求平衡分布(因为它会精确复制少数类示例),可能会导致受影响的算法过度拟合少数类,从而导致泛化误差增加。最好在过采样后监控训练和测试数据集的性能,并将结果与原始数据集上的相同算法进行比较。
# define oversampling strategy
oversample = RandomOverSampler(sampling_strategy='minority')
指定一个浮点值,指定转换数据集中少数类与多数类示例的比率。比如,对于二元分类问题,假设对少数类进行过采样,以使大多数类的示例数量减少一半,如果多数类有 1,000 个示例,而少数类有 100 个,则转换后的数据集将有 500 个少数类的示例。
# define oversampling strategy
oversample = RandomOverSampler(sampling_strategy=0.5)
# fit and apply the transform
X_over, y_over = oversample.fit_resample(X, y)
完整示例:使用3个重复的 10 折交叉验证进行评估,并在每1折内分别对训练数据集执行过采样
# example of evaluating a decision tree with random oversamplingfrom numpy import mean
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import RandomOverSampler
# define dataset
X, y = make_classification(n_samples=10000, weights=[0.99], flip_y=0)
# define pipeline
steps = [('over', RandomOverSampler()), ('model', DecisionTreeClassifier())]
pipeline = Pipeline(steps=steps)
# evaluate pipeline
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring='f1_micro', cv=cv, n_jobs=-1)
score = mean(scores)
print('F1 Score: %.3f' % score)
随机欠采样涉及从多数类中随机选择示例,并从训练集中删除。
欠采样的一个限制是,删除多数类中可能有用、重要或可能对拟合稳健决策边界至关重要的示例(一不小心把重要数据删了~~)。
鉴于示例是随机删除的,因此无法从多数类中检测或保留好的或包含更多信息的示例。数据的丢失会使少数和多数实例之间的决策边界更难学习,从而导致分类性能下降。
# define undersample strategy
undersample = RandomUnderSampler(sampling_strategy='majority')
..
# define undersample strategy
undersample = RandomUnderSampler(sampling_strategy=0.5)
# fit and apply the transform
X_over, y_over = undersample.fit_resample(X, y)
可以对少数类采用适度的过采样以改善对这些示例的偏差,同时也可以对多数类采用适度的欠采样以减少对该类的偏差。与单独执行一种采样相比,这可以提高模型整体性能。
例如,我们有一个类别分布为 1:100 的数据集,可能首先应用过采样,通过复制少数类的示例来将比例提高到 1:10,然后应用欠采样,通过从多数类中删除示例,将比例进一步提高到 1:2。
# define pipeline
over = RandomOverSampler(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
steps = [('o', over), ('u', under), ('m', DecisionTreeClassifier())]
pipeline = Pipeline(steps=steps)
# example of evaluating a model with random oversampling and undersampling
from numpy import mean
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
# define dataset
X, y = make_classification(n_samples=10000, weights=[0.99], flip_y=0)
# define pipeline
over = RandomOverSampler(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
steps = [('o', over), ('u', under), ('m', DecisionTreeClassifier())]
pipeline = Pipeline(steps=steps)
# evaluate pipeline
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring='f1_micro', cv=cv, n_jobs=-1)
score = mean(scores)
print('F1 Score: %.3f' % score)
RandomOverSampler通过复制少数类的一些原始样本进行过采样,而SMOTE 通过插值生成新样本。
从现有示例中合成新示例,这是少数类数据增强的一种类型,被称为合成少数类过采样技术,简称SMOTE。
SMOTE 的工作原理是选择特征空间中接近的示例,在特征空间中的示例之间绘制一条线,并在该线的某个点处绘制一个新样本。
- SMOTE 首先随机选择一个少数类实例 a 并找到它的 k 个最近的少数类邻居
- 然后通过随机选择 k 个最近邻 b 中的一个并连接 a 和 b ,以在特征空间中形成线段来创建合成实例,合成实例是作为两个选定实例 a 和 b 的凸组合生成的。
建议首先使用随机欠采样来修剪多数类中的示例数量,然后使用 SMOTE 对少数类进行过采样以平衡类分布。SMOTE 和欠采样的组合比普通欠采样表现更好。(关于 SMOTE 的原始论文建议将 SMOTE 与多数类的随机欠采样结合起来)
普遍缺点在于,创建合成示例时没有考虑多数类,如果类有很强的重叠,可能会导致示例不明确。
# Oversample and plot imbalanced dataset with SMOTEfrom collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
from matplotlib import pyplot
from numpy import where
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# summarize class distribution
counter = Counter(y)
print(counter)
# transform the dataset
oversample = SMOTE()
X, y = oversample.fit_resample(X, y)
# summarize the new class distribution
counter = Counter(y)
print(counter)
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
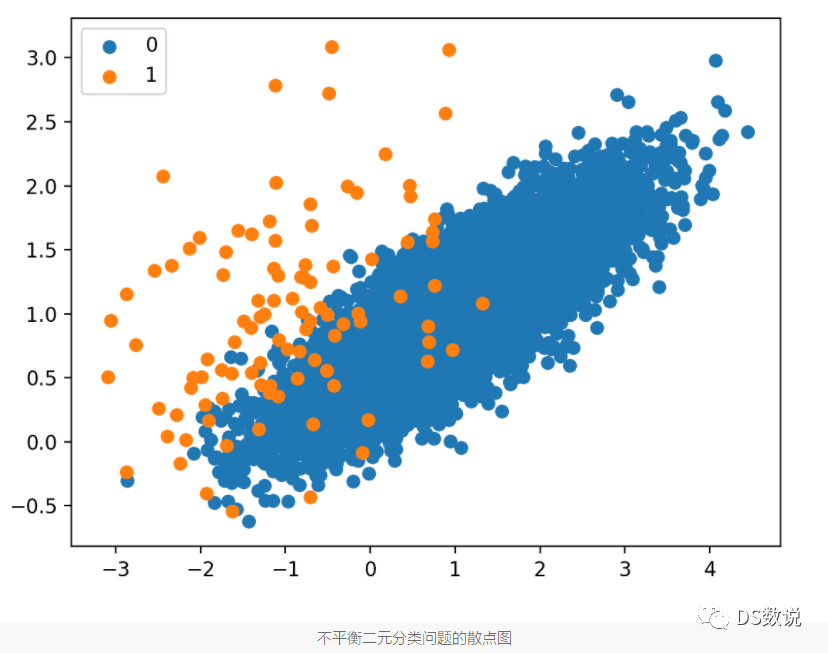
先对少数类smote过采样,再样对多数类欠采样:
# Oversample with SMOTE and random undersample for imbalanced datasetfrom collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
from imblearn.pipeline import Pipeline
from matplotlib import pyplot
from numpy import where
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# summarize class distribution
counter = Counter(y)
print(counter)
# define pipeline
over = SMOTE(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
steps = [('o', over), ('u', under)]
pipeline = Pipeline(steps=steps)
# transform the dataset
X, y = pipeline.fit_resample(X, y)
# summarize the new class distribution
counter = Counter(y)
print(counter)
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
可以对比采样前和采样后的模型性能(这里采样AUC):
# decision tree on imbalanced dataset with SMOTE oversampling and random undersamplingfrom numpy import mean
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# define pipeline
model = DecisionTreeClassifier()
over = SMOTE(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
steps = [('over', over), ('under', under), ('model', model)]
pipeline = Pipeline(steps=steps)
# evaluate pipeline
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1)
print('Mean ROC AUC: %.3f' % mean(scores))
还可以通过调整 SMOTE 的 k 最近邻的不同值(默认是5):
# grid search k value for SMOTE oversampling for imbalanced classificationfrom numpy import mean
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# values to evaluate
k_values = [1, 2, 3, 4, 5, 6, 7]
for k in k_values:
# define pipeline
model = DecisionTreeClassifier()
over = SMOTE(sampling_strategy=0.1, k_neighbors=k)
under = RandomUnderSampler(sampling_strategy=0.5)
steps = [('over', over), ('under', under), ('model', model)]
pipeline = Pipeline(steps=steps)
# evaluate pipeline
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring='roc_auc', cv=cv, n_jobs=-1)
score = mean(scores)
print('> k=%d, Mean ROC AUC: %.3f' % (k, score))
SMOTE过于随机了,从少数类中随机选择一个样本a,找到K近邻后,再从近邻中随机选择一个样本b,连接样本a,b,选择ab直线上一点de作为过采样点。这样很容易生成错误类样本,生成的样本进入到多数类中去了。
直觉:边界上的示例和附近的示例比远离边界的示例更容易被错误分类,因此对分类更重要。
这些错误分类的示例可能是模棱两可的,并且位于决策边界的边缘或边界区域中,类别成员可能重叠。因此,这种修改为 SMOTE 的方法称为 Borderline-SMOTE。
Borderline-SMOTE 方法仅在两个类之间的决策边界上创建合成示例,而不是盲目地为少数类生成新的合成示例。
# borderline-SMOTE for imbalanced datasetfrom collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import BorderlineSMOTE
from matplotlib import pyplot
from numpy import where
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# summarize class distribution
counter = Counter(y)
print(counter)
# transform the dataset
oversample = BorderlineSMOTE()
X, y = oversample.fit_resample(X, y)
# summarize the new class distribution
counter = Counter(y)
print(counter)
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
与Borderline-SMOTE不同的是,使用 SVM 算法而不是 KNN 来识别决策边界上的错误分类示例。
# borderline-SMOTE with SVM for imbalanced datasetfrom collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import SVMSMOTE
from matplotlib import pyplot
from numpy import where
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# summarize class distribution
counter = Counter(y)
print(counter)
# transform the dataset
oversample = SVMSMOTE()
X, y = oversample.fit_resample(X, y)
# summarize the new class distribution
counter = Counter(y)
print(counter)
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
与 Borderline-SMOTE 不同,更多的示例是在远离类重叠区域的地方合成的,例如图的左上角。
通过生成与少数类中示例的密度成反比的合成样本进行过采样
也就是说,在特征空间的少数样本密度低的区域生成更多合成样本,而在密度高的区域生成更少或不生成合成样本。
ADASYN 算法的关键思想是,使用密度分布作为标准,自动决定需要为每个少数数据示例生成的合成样本的数量。
ADASYN 基于根据分布自适应生成少数数据样本的思想:与那些更容易学习的少数样本相比,为更难学习的少数类样本生成更多的合成数据。
# Oversample and plot imbalanced dataset with ADASYNfrom collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import ADASYN
from matplotlib import pyplot
from numpy import where
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# summarize class distribution
counter = Counter(y)
print(counter)
# transform the dataset
oversample = ADASYN()
X, y = oversample.fit_resample(X, y)
# summarize the new class distribution
counter = Counter(y)
print(counter)
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
值得注意的一点是,在进行采样的时候,要注意数据泄露问题。
在将整个数据集拆分为训练分区和测试分区之前对整个数据集进行重采样,这就会导致数据泄露。
-
该模型不会在类分布类似于真实用例的数据集上进行测试。通过对整个数据集进行重新采样,训练集和测试集都可能是平衡的,但是模型应该在不平衡的数据集上进行测试,以评估模型的潜在偏差;
-
重采样过程可能会使用有关数据集中样本的信息来生成或选择一些样本。因此,我们可能会使用样本信息,这些信息将在以后用作测试样本。
References:
- https://imbalanced-learn.org/dev/user_guide.html
- https://zhuanlan.zhihu.com/p/360045341
欢迎关注个人公众号:DS数说