 为什么Google不支持无限分页?
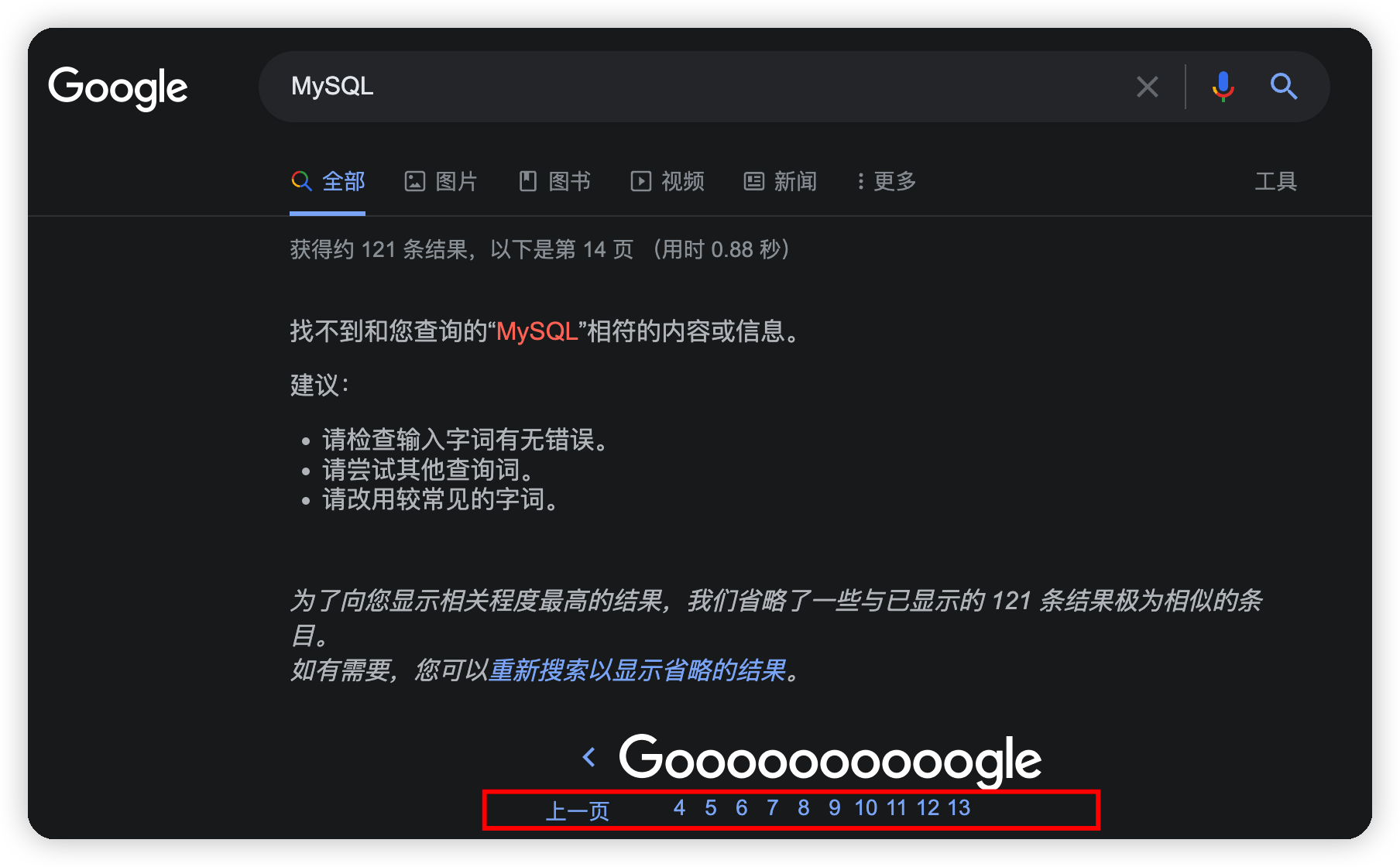
当我用Google搜索MySQL这个关键词的时候,Google只提供了13页的搜索结果,我通过修改url的分页参数试图搜索第14页数据,结果出现了以下的错误提示
为什么Google不支持无限分页?
当我用Google搜索MySQL这个关键词的时候,Google只提供了13页的搜索结果,我通过修改url的分页参数试图搜索第14页数据,结果出现了以下的错误提示

这是一个很有意思却很少有人注意的问题。
当我用Google搜索MySQL这个关键词的时候,Google只提供了13页的搜索结果,我通过修改url的分页参数试图搜索第14页数据,结果出现了以下的错误提示:
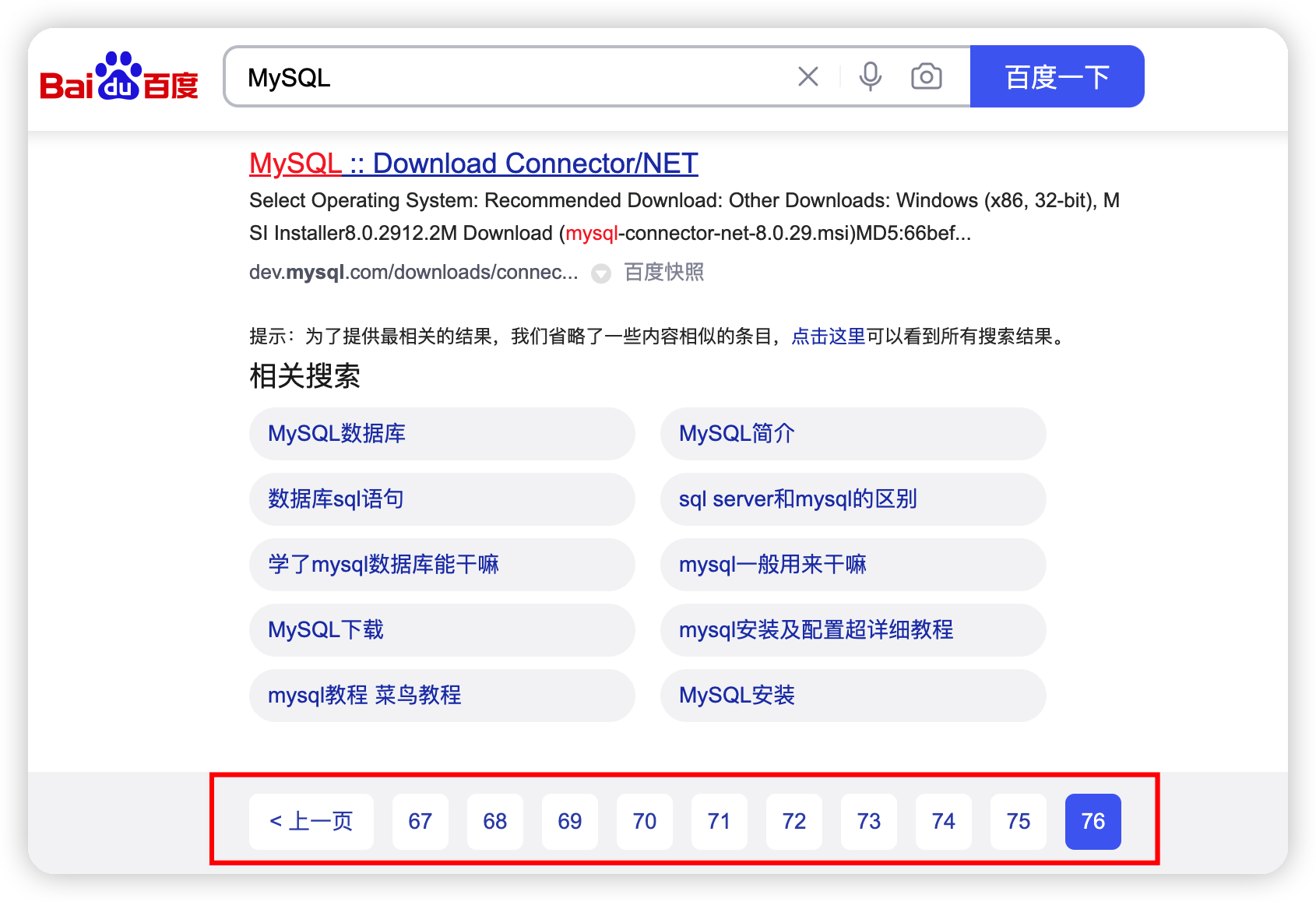
百度搜索同样不提供无限分页,对于MySQL关键词,百度搜索提供了76页的搜索结果。
强如Google搜索,为什么不支持无限分页?无非有两种可能:
- 做不到
- 没必要
「做不到」是不可能的,唯一的理由就是「没必要」。
首先,当第1页的搜索结果没有我们需要的内容的时候,我们通常会立即更换关键词,而不是翻第2页,更不用说翻到10页往后了。这是没必要的第一个理由——用户需求不强烈。
其次,无限分页的功能对于搜索引擎而言是非常消耗性能的。你可能感觉很奇怪,翻到第2页和翻到第1000页不都是搜索嘛,能有什么区别?
实际上,搜索引擎高可用和高伸缩性的设计带来的一个副作用就是无法高效实现无限分页功能,无法高效意味着能实现,但是代价比较大,这是所有搜索引擎都会面临的一个问题,专业上叫做「深度分页」。这也是没必要的第二个理由——实现成本高。
我自然不知道Google的搜索具体是怎么做的,因此接下来我用ES(Elasticsearch)为例来解释一下为什么深度分页对搜索引擎来说是一个头疼的问题。
Elasticsearch(下文简称ES)实现的功能和Google以及百度搜索提供的功能是相同的,而且在实现高可用和高伸缩性的方法上也大同小异,深度分页的问题都是由这些大同小异的优化方法导致的。
ES是一个全文搜索引擎。
全文搜索引擎又是个什么鬼?
试想一个场景,你偶然听到了一首旋律特别优美的歌曲,回家之后依然感觉余音绕梁,可是无奈你只记得一句歌词中的几个字:「伞的边缘」。这时候搜索引擎就发挥作用了。
使用搜索引擎你可以获取到带有「伞的边缘」关键词的所有结果,这些结果有一个术语,叫做文档。并且搜索结果是按照文档与关键词的相关性进行排序之后返回的。我们得到了全文搜索引擎的定义:
全文搜索引擎是根据文档内容查找相关文档,并按照相关性顺序返回搜索结果的一种工具
网上冲浪太久,我们会渐渐地把计算机的能力误以为是自己本身具备的能力,比如我们可能误以为我们大脑本身就很擅长这种搜索。恰恰相反,全文检索的功能是我们非常不擅长的。
举个例子,如果我对你说:静夜思。你可能脱口而出:床前明月光,疑是地上霜。举头望明月,低头思故乡。但是如果我让你说出带有「月」的古诗,想必你会费上一番功夫。
包括我们平时看的书也是一样,目录本身就是一种符合我们人脑检索特点的一种搜索结构,让我们可以通过文档ID或者文档标题这种总领性的标识来找到某一篇文档,这种结构叫做正排索引。

而全文搜索引擎恰好相反,是通过文档中的内容来找寻文档,诗词大会中的飞花令就是人脑版的全文搜索引擎。

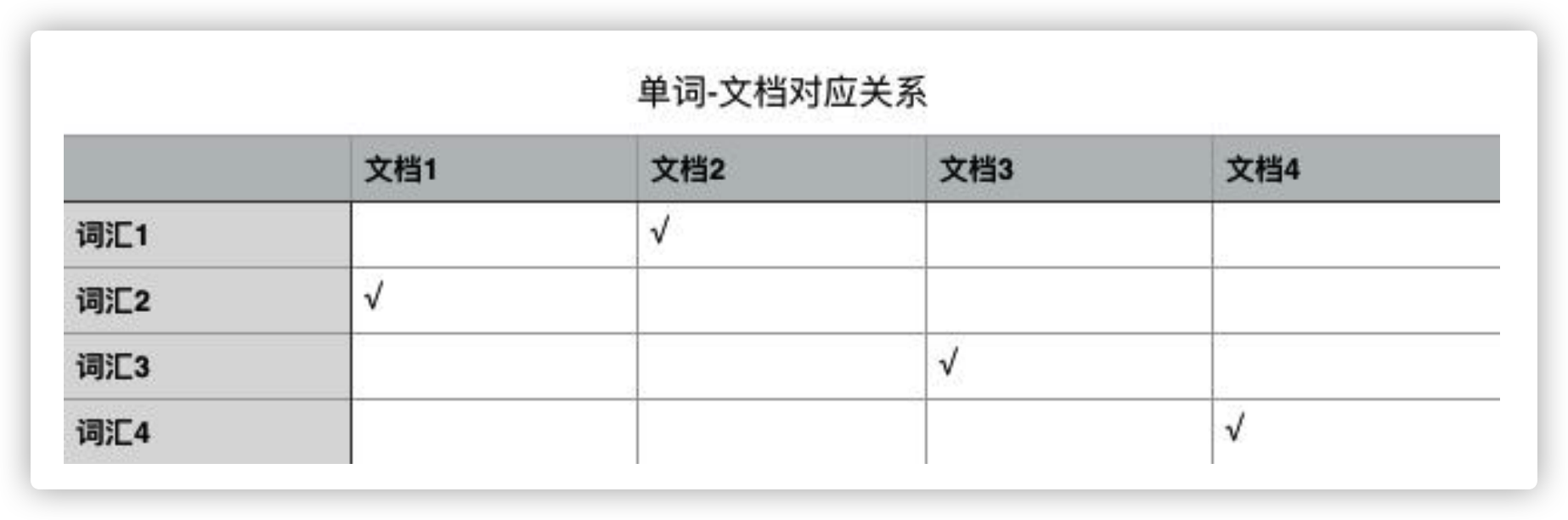
全文搜索引擎依赖的数据结构就是大名鼎鼎的倒排索引(「倒排」这个词就说明这种数据结构和我们正常的思维方式恰好相反),它是单词和文档之间包含关系的一种具体实现形式。
打住!不能继续展开了话题了,赶紧一句话介绍完ES吧!
高可用的秘密——副本(Replication)
ES是一款使用倒排索引数据结构、能够根据文档内容查找相关文档,并按照相关性顺序返回搜索结果的全文搜索引擎
高可用是企业级服务必须考虑的一个指标,高可用必然涉及到集群和分布式,好在ES天然支持集群模式,可以非常简单地搭建一个分布式系统。
ES服务高可用要求其中一个节点如果挂掉了,不能影响正常的搜索服务。这就意味着挂掉的节点上存储的数据,必须在其他节点上留有完整的备份。这就是副本的概念。

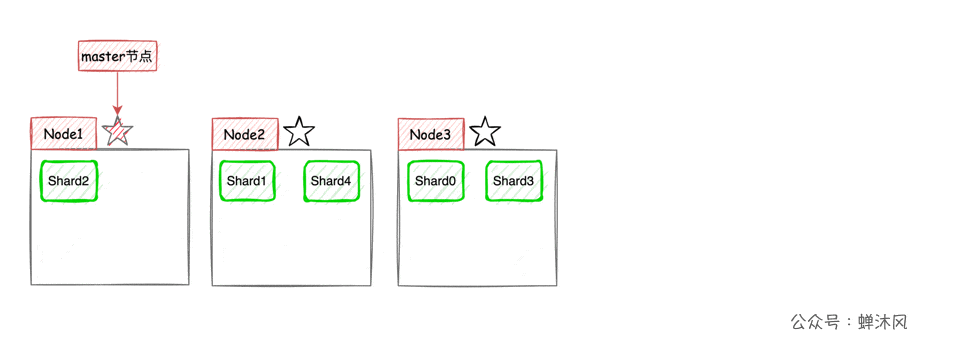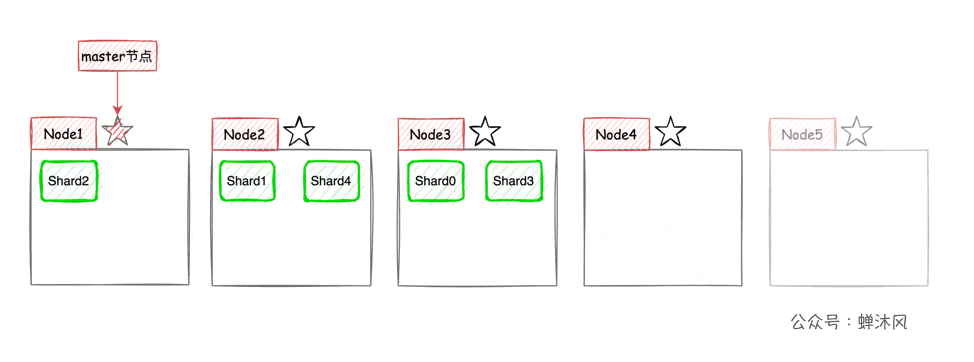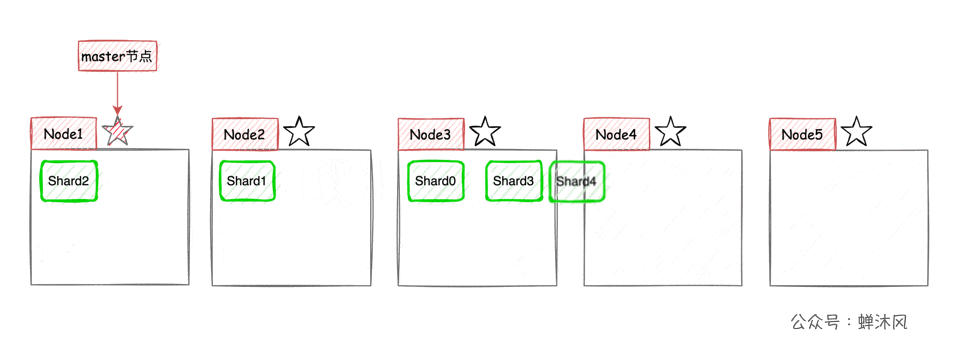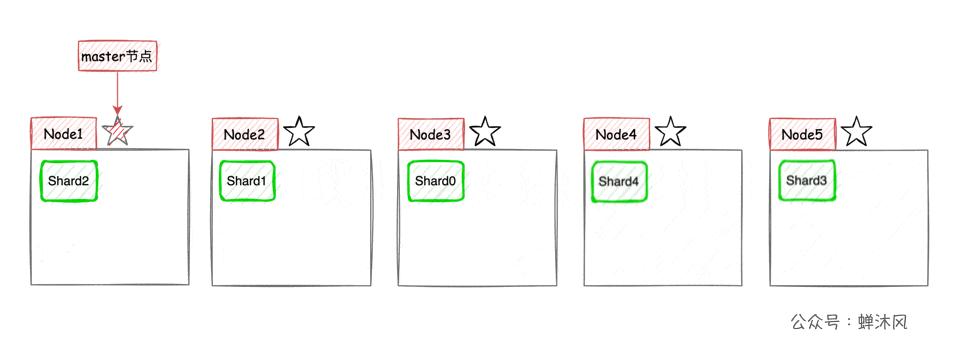
如上图所示,Node1作为主节点,Node2和Node3作为副本节点保存了和主节点完全相同的数据,这样任何一个节点挂掉都不会影响业务的搜索。满足服务的高可用要求。
但是有一个致命的问题,无法实现系统扩容!即使添加另外的节点,对整个系统的容量扩充也起不到任何帮助。因为每一个节点都完整保存了所有的文档数据。
因此,ES引入了分片(Shard)的概念。
ES将每个索引(ES中一系列文档的集合,相当于MySQL中的表)分成若干个分片,分片将尽可能平均地分配到不同的节点上。比如现在一个集群中有3台节点,索引被分成了5个分片,分配方式大致(因为具体如何平均分配取决于ES)如下图所示。
这样一来,集群的横向扩容就非常简单了,现在我们向集群中再添加2个节点,则ES会自动将分片均衡到各个节点之上:
副本和分片功能通力协作造就了ES如今高可用和支持PB级数据量的两大优势。
现在我们以3个节点为例,展示一下分片数量为5,副本数量为1的情况下,ES在不同节点上的分片排布情况:
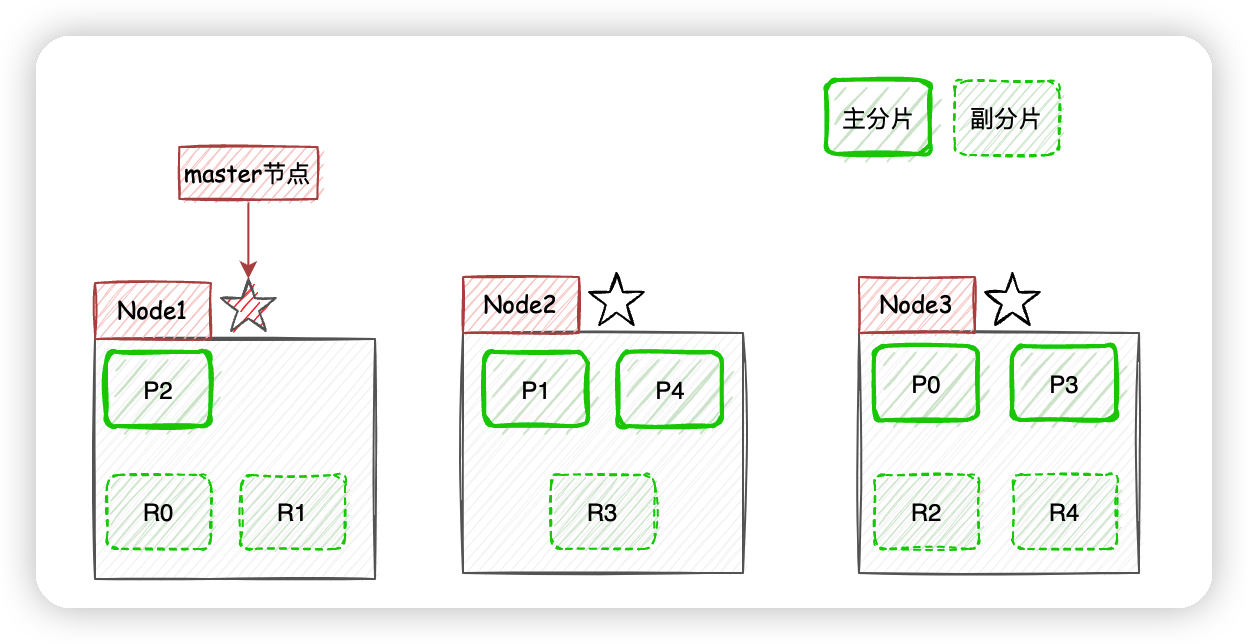
有一点需要注意,上图示例中主分片和对应的副本分片不会出现在同一个节点上,至于为什么,大家可以自己思考一下。
文档的分布式存储ES是怎么确定某个文档应该存储到哪一个分片上呢?

通过上面的映射算法,ES将文档数据均匀地分散在各个分片中,其中routing默认是文档id。
此外,副本分片的内容依赖主分片进行同步,副本分片存在意义就是负载均衡、顶上随时可能挂掉的主分片位置,成为新的主分片。
现在基础知识讲完了,终于可以进行搜索了。
ES的搜索机制一图胜千言:
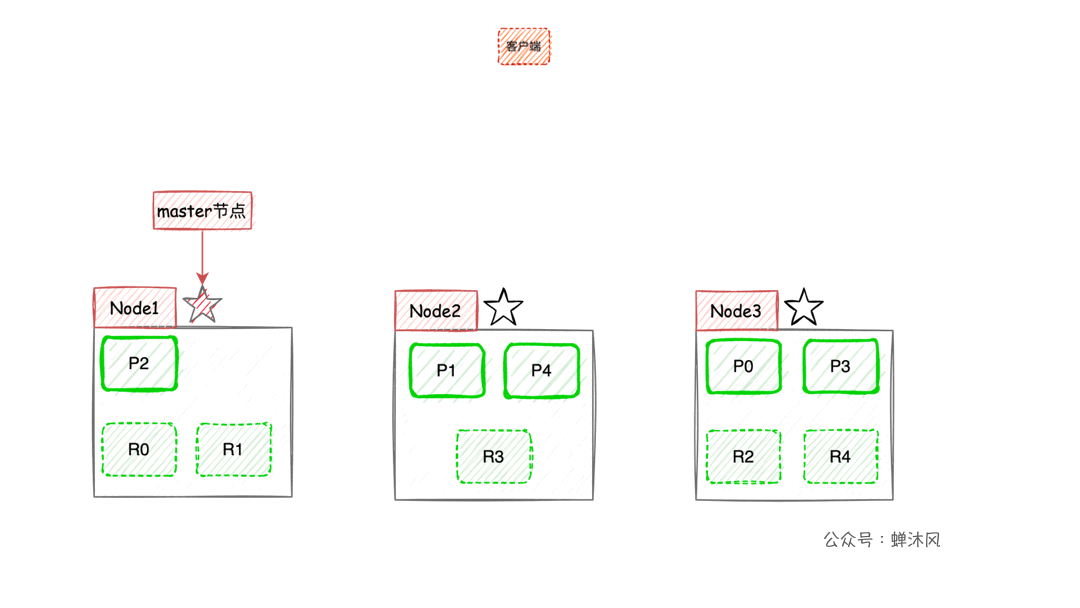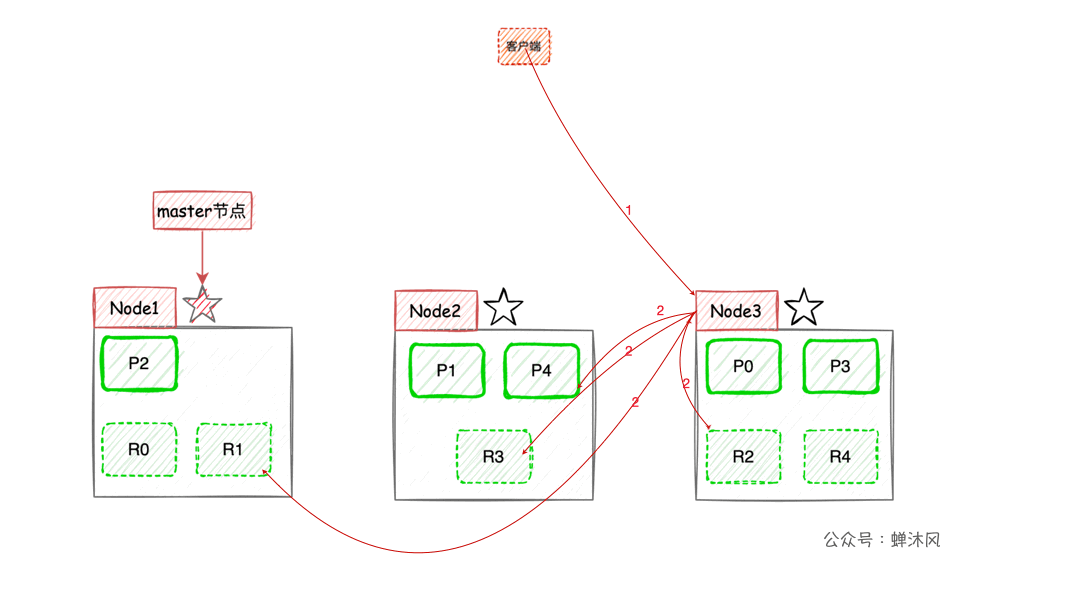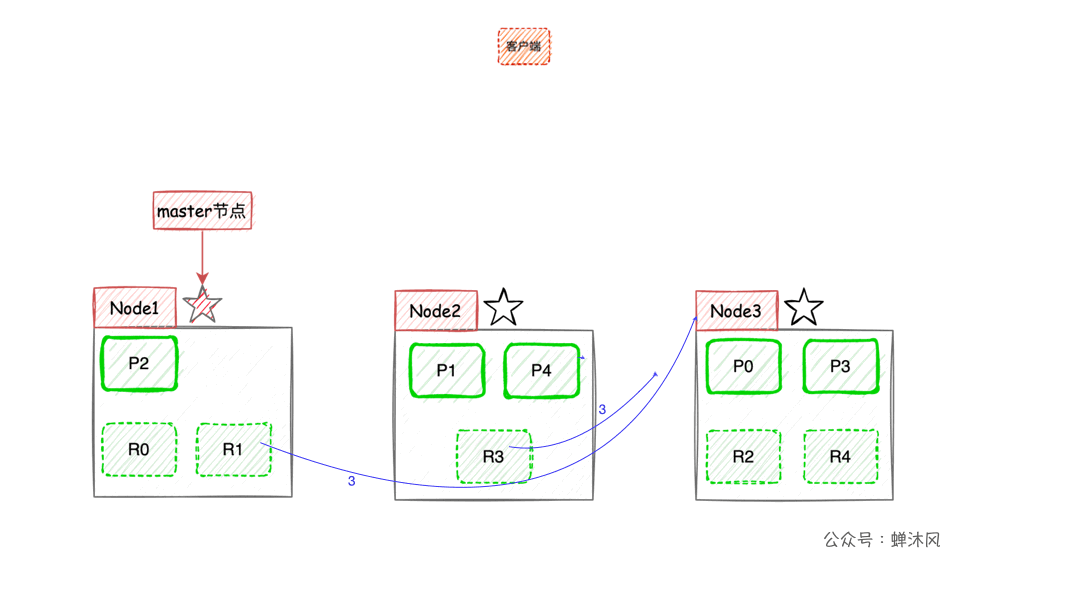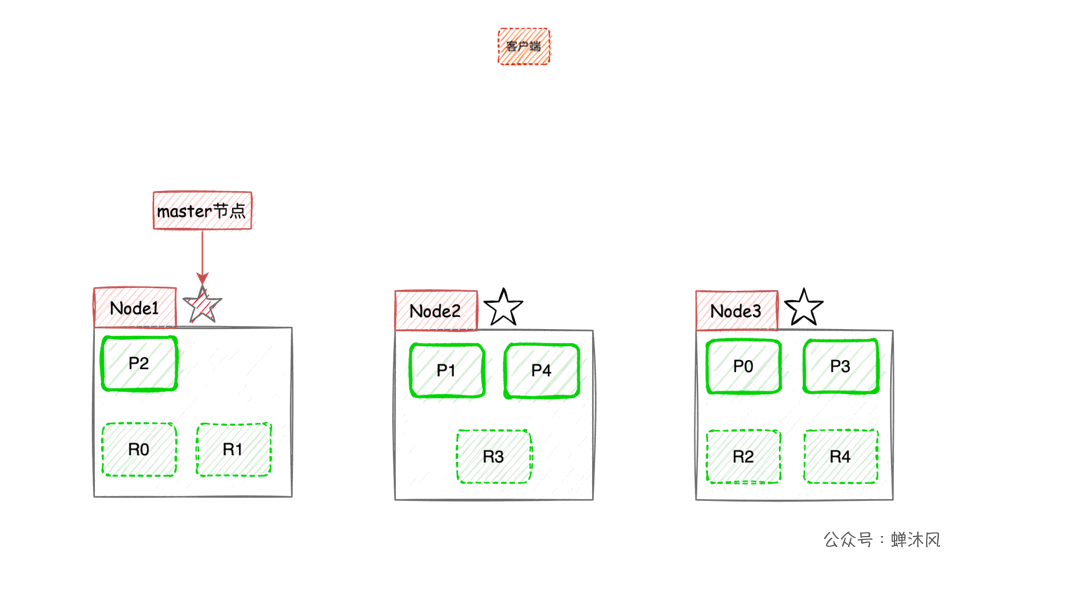
- 客户端进行关键词搜索时,
ES会使用负载均衡策略选择一个节点作为协调节点(Coordinating Node)接受请求,这里假设选择的是Node3节点; Node3节点会在10个主副分片中随机选择5个分片(所有分片必须能包含所有内容,且不能重复),发送search request;- 被选中的5个分片分别执行查询并进行排序之后返回结果给
Node3节点; Node3节点整合5个分片返回的结果,再次排序之后取到对应分页的结果集返回给客户端。
注:实际上
ES的搜索分为Query阶段和Fetch阶段两个步骤,在Query阶段各个分片返回文档Id和排序值,Fetch阶段根据文档Id去对应分片获取文档详情,上面的图片和文字说明对此进行了简化,请悉知。
现在考虑客户端获取990~1000的文档时,ES在分片存储的情况下如何给出正确的搜索结果。
获取990~1000的文档时,ES在每个分片下都需要获取1000个文档,然后由Coordinating Node聚合所有分片的结果,然后进行相关性排序,最后选出相关性顺序在990~1000的10条文档。
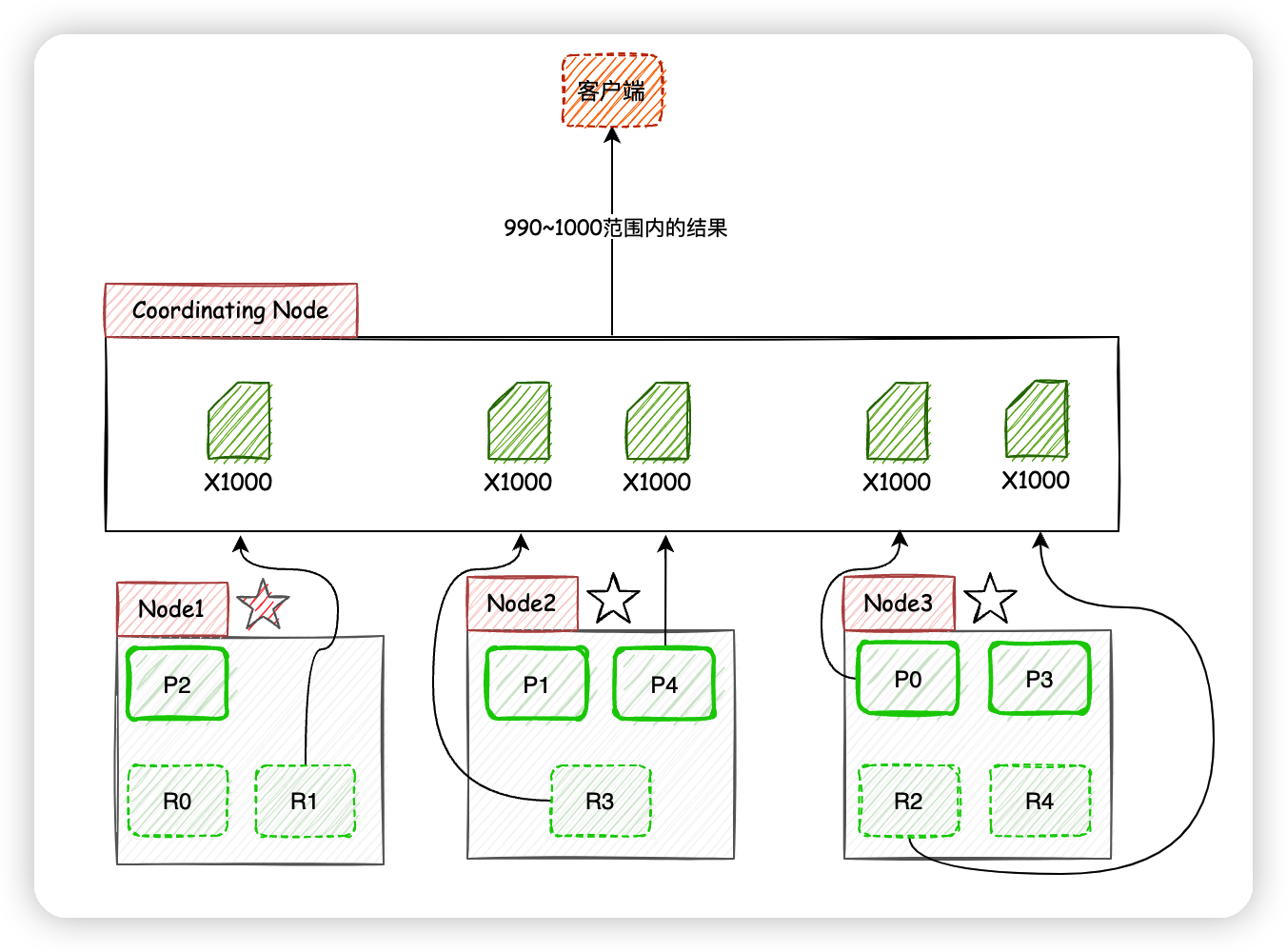
页数越深,每个节点处理的文档也就越多,占用的内存也就越多,耗时也就越长,这也就是为什么搜索引擎厂商通常不提供深度分页的原因了,他们没必要在客户需求不强烈的功能上浪费性能。
公众号「蝉沐风」,关注我,邂逅更多精彩文章
完。