注意:适用于springboot或者springcloud框架 1.首先下载相关文件 2.然后需要去启动相关的启动文件 3、导入相关jar包(如果有相关的依赖包不需要导入)以及配置配置文件,并且写一个dao接
注意:适用于springboot或者springcloud框架
1.首先下载相关文件
2.然后需要去启动相关的启动文件
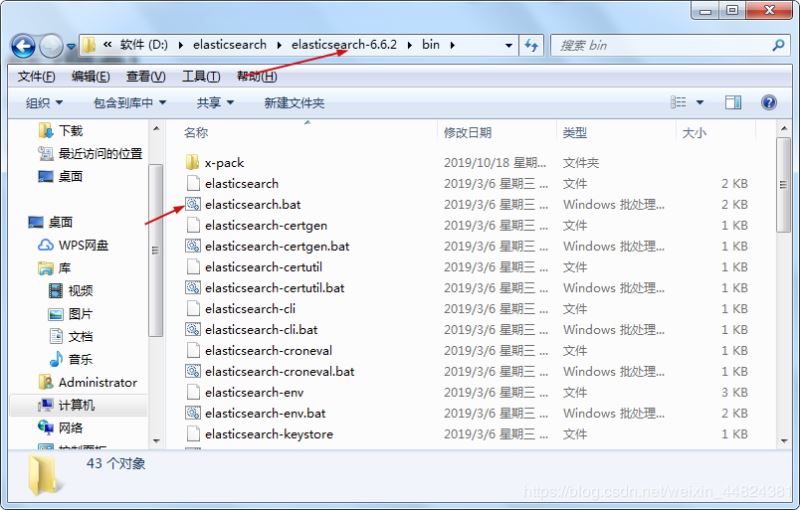

3、导入相关jar包(如果有相关的依赖包不需要导入)以及配置配置文件,并且写一个dao接口继承一个类,在启动类上标注地址
<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>
## ElasticSearch - start #开启 Elasticsearch 仓库(默认值:true) spring.data.elasticsearch.repositories.enabled=true spring.data.elasticsearch.cluster-nodes=localhost:9300 spring.data.elasticsearch.cluster-name=myes
Shop:是下面创建的实体类名称(不能写错),String(传参时的类型,我这里id也给的String,因为integer报错)
import com.jk.user.model.Shop;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface EsDao extends ElasticsearchRepository<Shop,String> {
}
启动类上加上注解,后面跟的是dao的包名
@EnableElasticsearchRepositories(basePackages = "com.jk.web.dao")
4.实体类
indexName相当于数据库名, type 相当于表名 ,必须加上id,type 类型,analyzer 分词器名称(ik分词)
@Document(indexName = "zth",type = "t_shangpin")
public class Shop implements Serializable {
private static final long serialVersionUID = 2006762641515872124L;
private String id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
//商品名称
private String shopname;
//优惠价格
private Long reducedprice;
}
5.然后写controller层(这里直接注入dao接口),这里新增我选的是对象循环赋值,其实可以直接赋集合(参考)
//elasticsearch 生成表
// @RequestMapping("el")
// @ResponseBody
// public void el(){
// List<ElasticsearchBean> list=shoppService.queryelasticsearch();
// for (ElasticsearchBean ss: list) {
// ss.setScrenicName(ss.getScrenicName()+""+ss.getHotelName());
// }
// elasticsearch.saveAll(list);
// }
@Autowired
private EsDao esDao;
// 查询时需要
@Autowired
private ElasticsearchTemplate elasticsearchTemplate ;
//更新es服务器数据
@RequestMapping("addEs")
public boolean addShopEs() {
List<TShangpin> list = webUserService.queryShouye();//先去后台查出数据在赋值
Shop shop = new Shop();
try {
for (int i = 0; i < list.size(); i++) {
shop.setId(list.get(i).getShopid().toString());
shop.setShopname(list.get(i).getShopname());
esDao.save(shop);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
//es搜索商品
@RequestMapping("queryShop")
public List ellist(String name, HttpSession session, Integer page, Integer rows){
if (name==null||"".equals(name)){
name = session.getAttribute("name").toString();
}
page=1;
rows=3;
HashMap<String, Object> resultMap = new HashMap<>();
//创建一个要搜索的索引库
SearchRequestBuilder searchRequestBuilder = elasticsearchTemplate.getClient().prepareSearch("zth").setTypes("t_shangpin");
//创建组合查询
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
if (name!=null && !"".equals(name)){
boolQueryBuilder.should(QueryBuilders.matchQuery("shopname",name));
}
//设置查询的类型
searchRequestBuilder.setSearchType(SearchType.DFS_QUERY_THEN_FETCH);
searchRequestBuilder.setQuery(boolQueryBuilder);
//分页
searchRequestBuilder.setFrom((page-1)*rows);
searchRequestBuilder.setSize(rows);
//设置高亮字段
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("shopname")
.preTags("<font color='red'>")
.postTags("</font>");
searchRequestBuilder.highlighter(highlightBuilder);
//直接搜索返回响应数据 (json)
SearchResponse searchResponse = searchRequestBuilder.get();
SearchHits hits = searchResponse.getHits();
//获取总条数
long totalHits = hits.getTotalHits();
resultMap.put("total",totalHits);
ArrayList<Map<String,Object>> list = new ArrayList<>();
//获取Hits中json对象数据
SearchHit[] hits1 = hits.getHits();
for (int i=0;i<hits1.length;i++){
//获取Map对象
Map<String, Object> sourceAsMap = hits1[i].getSourceAsMap();
//获取高亮字段
Map<String, HighlightField> highlightFields = hits1[i].getHighlightFields();
//!!如果有高亮字段就取出赋给上面sourceAsMap中原有的名字给他替换掉!!
if (name!=null && !"".equals(name)){
sourceAsMap.put("shopname",highlightFields.get("shopname").getFragments()[0].toString());
}
list.add(sourceAsMap);
}
return list;
}
6.最后 如果无法搜索,可能是需要加一个ik的json文件,因为在实体类中规定了是ik分词器,如果不规定当它存进去后其实是还没有分词。
film-mapping.json
{
"film":
{
"_all":
{
"enabled": true
},
"properties":
{ "id":
{
"type": "integer"
},"name":
{
"type": "text", "analyzer": "ikSearchAnalyzer", "search_analyzer": "ikSearchAnalyzer", "fields":
{ "pinyin": {
"type": "text", "analyzer": "pinyinSimpleIndexAnalyzer", "search_analyzer": "pinyinSimpleIndexAnalyzer"
} } },
"nameOri": { "type": "text"
},"publishDate":
{ "type": "text" },"type":
{ "type": "text"
},"language":
{ "type": "text"
},"fileDuration":
{ "type": "text"
},"director":
{ "type": "text",
"index": "true", "analyzer": "ikSearchAnalyzer"
},"created":
{
"type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
} } } }
film-setting.json
{ "index": { "analysis":
{ "filter":
{ "edge_ngram_filter":
{ "type": "edge_ngram", "min_gram": 1, "max_gram": 50
},"pinyin_simple_filter":
{
"type": "pinyin", "first_letter": "prefix", "padding_char": " ", "limit_first_letter_length": 50, "lowercase": true
}
},"char_filter":
{
"tsconvert": { "type": "stconvert", "convert_type": "t2s"
}
},"analyzer":
{ "ikSearchAnalyzer":
{ "type": "custom", "tokenizer": "ik_max_word", "char_filter": [ "tsconvert" ]
},"pinyinSimpleIndexAnalyzer":
{ "tokenizer": "keyword", "filter": [ "pinyin_simple_filter", "edge_ngram_filter", "lowercase" ]
} } } } }
总结
到此这篇关于es(elasticsearch)整合SpringCloud(SpringBoot)搭建教程详解的文章就介绍到这了,更多相关elasticsearch 整合SpringCloud内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!