在下半年选修了机器学习的关键课程Machine learning and deep learning,但由于Macbook Pro显卡不支持cuda,因此无法使用GPU来训练网络。教授推荐使用Google Colab作为训练神经网络的平台。在高强度
 Colab一般配合Google Drive使用(下文会提到这一点)。因此如有必要,我建议拓展谷歌云端硬盘的储存空间,个人认为性价比较高的是基本版或标准版。在购买完额外的空间后,头像外部会出现一个四色光环,就像作者一样。
Colab一般配合Google Drive使用(下文会提到这一点)。因此如有必要,我建议拓展谷歌云端硬盘的储存空间,个人认为性价比较高的是基本版或标准版。在购买完额外的空间后,头像外部会出现一个四色光环,就像作者一样。
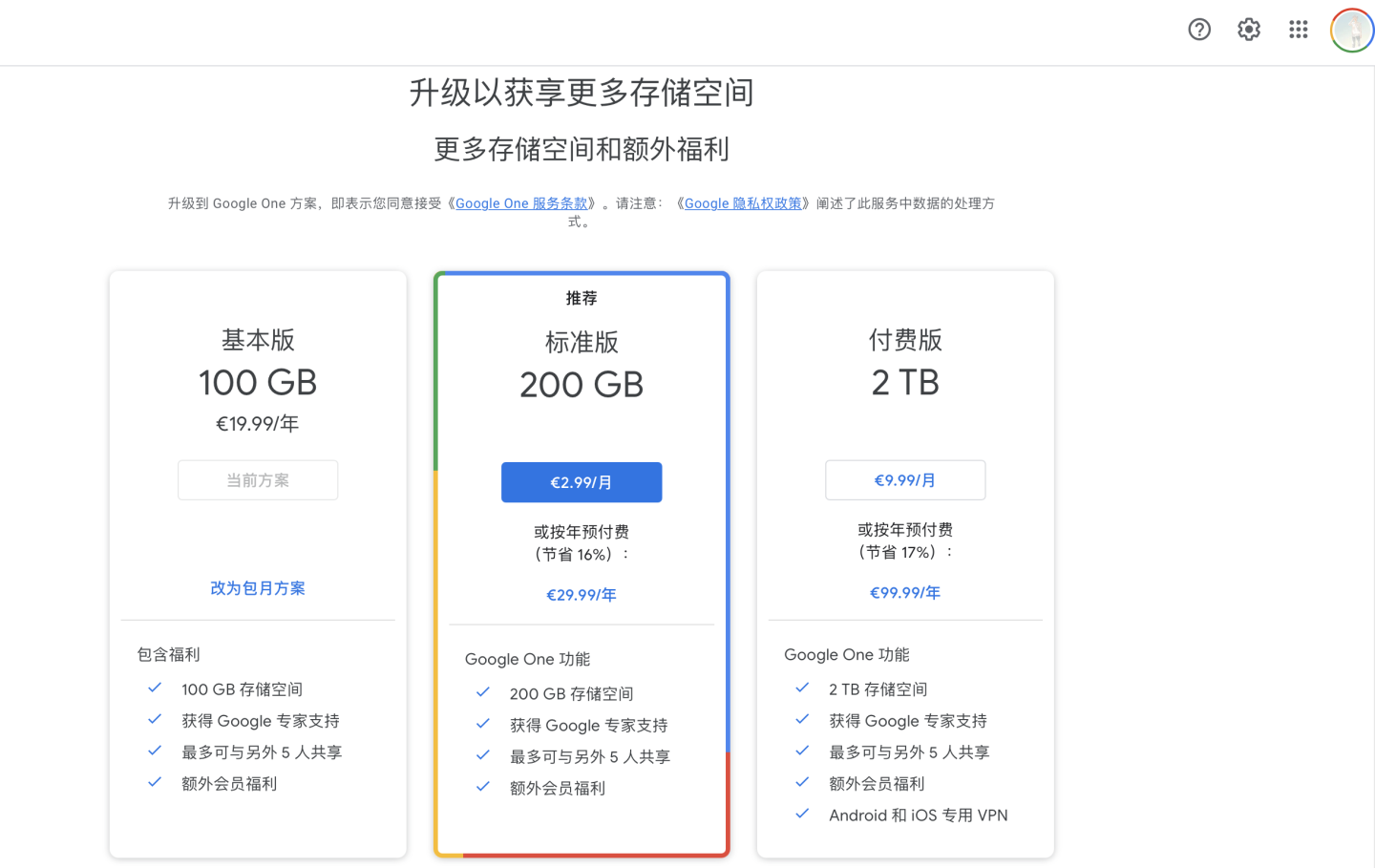 新建笔记本
有两种方法可以新建一个笔记本,第一种是在在云端硬盘中右键创建。
新建笔记本
有两种方法可以新建一个笔记本,第一种是在在云端硬盘中右键创建。
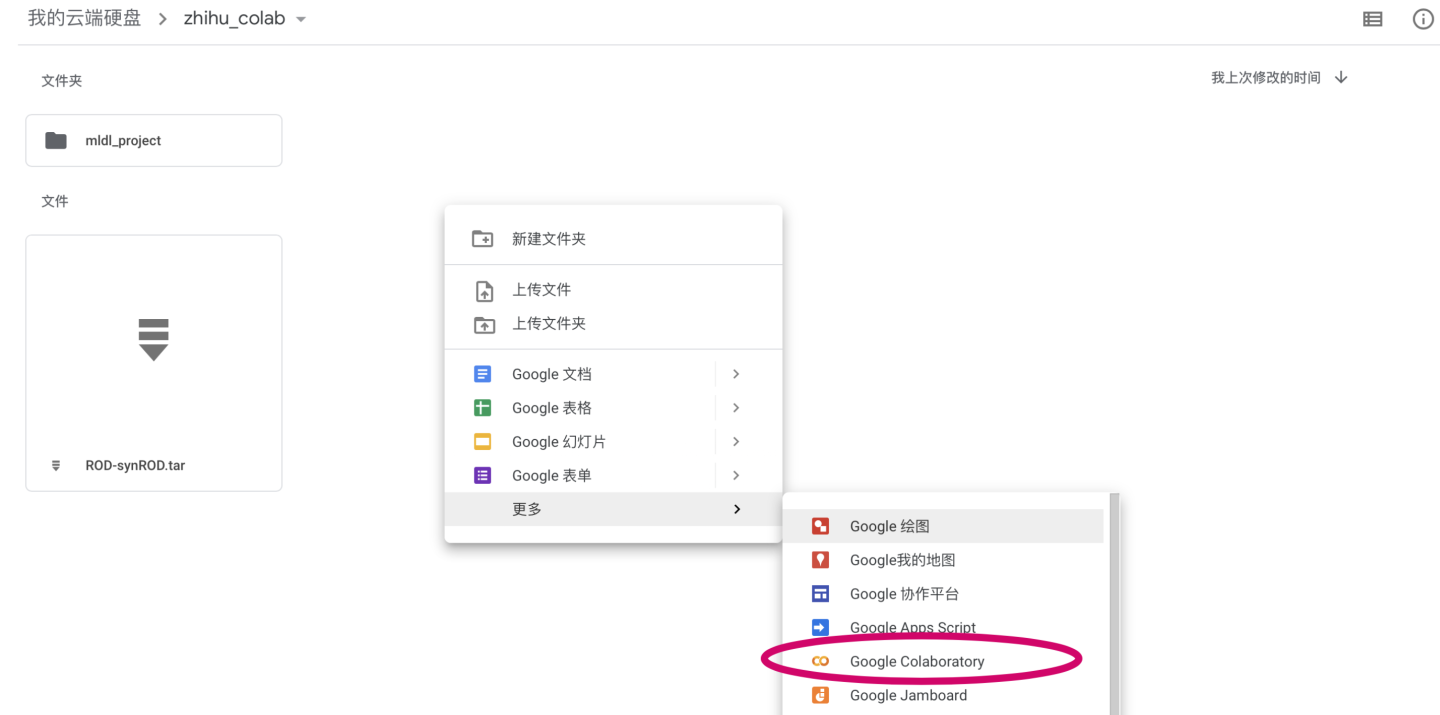
如果右键后没有发现有这一个选项,那是因为云端硬盘还没有安装Colab。这时在右击后选择“关联更多应用”,然后搜索colab并下载,之后就可以通过右键创建了。
如果右键后没有发现有这一个选项,那是因为云端硬盘还没有安装Colab。这时在右击后选择“关联更多应用”,然后搜索colab并下载,之后就可以通过右键创建了。
 第二种方法是直接在浏览器中输入https://colab.research.google.com,进入Colab的页面后点击新建笔记本即可。使用这种方法新建的笔记本时,会在云端硬盘的根目录自动创建一个叫Colab Notebook的文件夹,新创建的笔记本就保存在这个文件夹中。
第二种方法是直接在浏览器中输入https://colab.research.google.com,进入Colab的页面后点击新建笔记本即可。使用这种方法新建的笔记本时,会在云端硬盘的根目录自动创建一个叫Colab Notebook的文件夹,新创建的笔记本就保存在这个文件夹中。
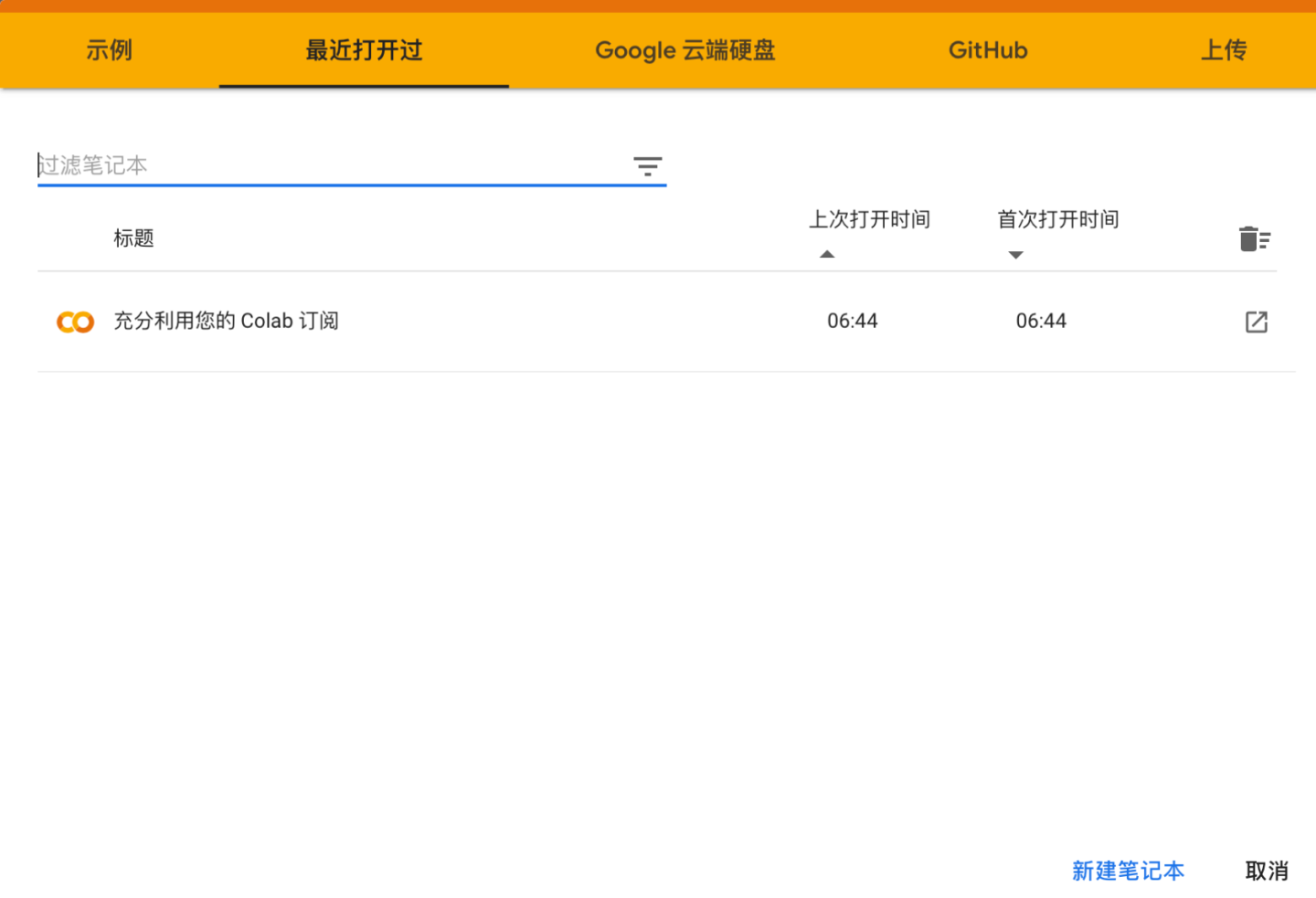
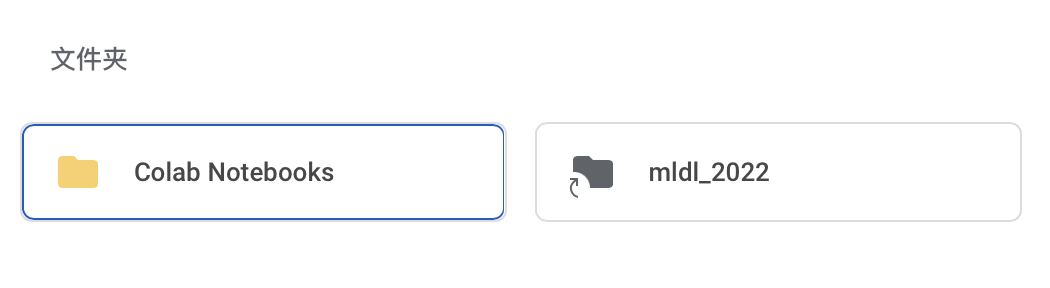 载入笔记本
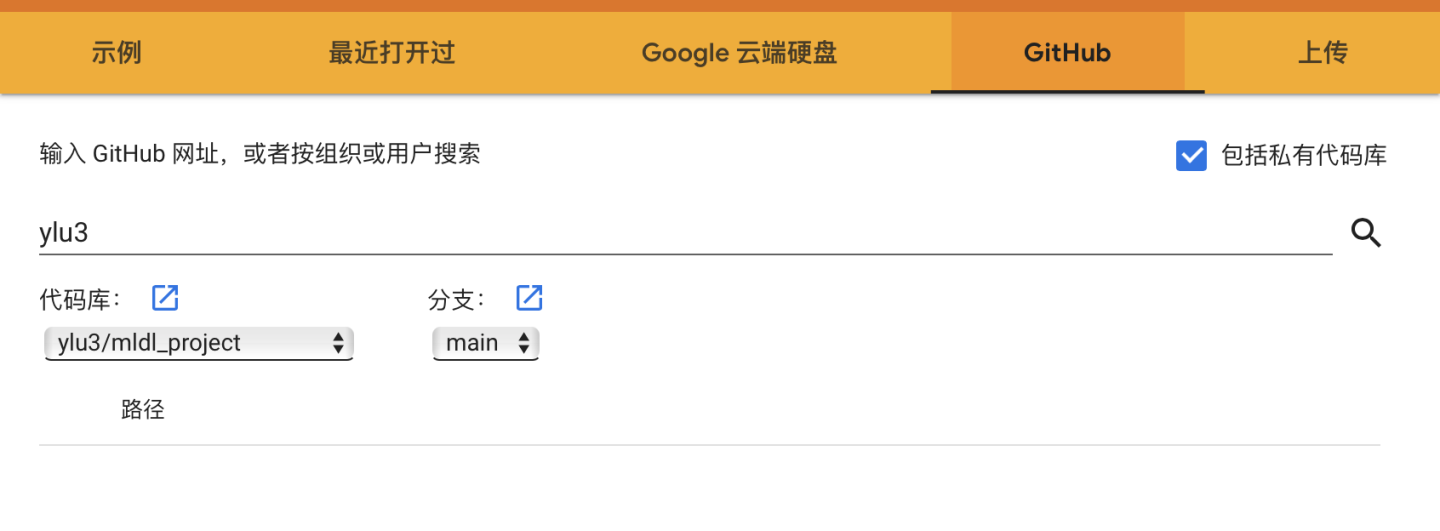
可以打开云端硬盘中的已经存在的笔记本,还可以从Github中导入笔记本。如果关联了Github账户,可以选择一个账户中的Project,如果其中有ipynb文件就可以在Colab中打开。注意:关联Github不是把Github中的项目文件夹加载到实例空间!
载入笔记本
可以打开云端硬盘中的已经存在的笔记本,还可以从Github中导入笔记本。如果关联了Github账户,可以选择一个账户中的Project,如果其中有ipynb文件就可以在Colab中打开。注意:关联Github不是把Github中的项目文件夹加载到实例空间!
 笔记本界面
笔记本界面
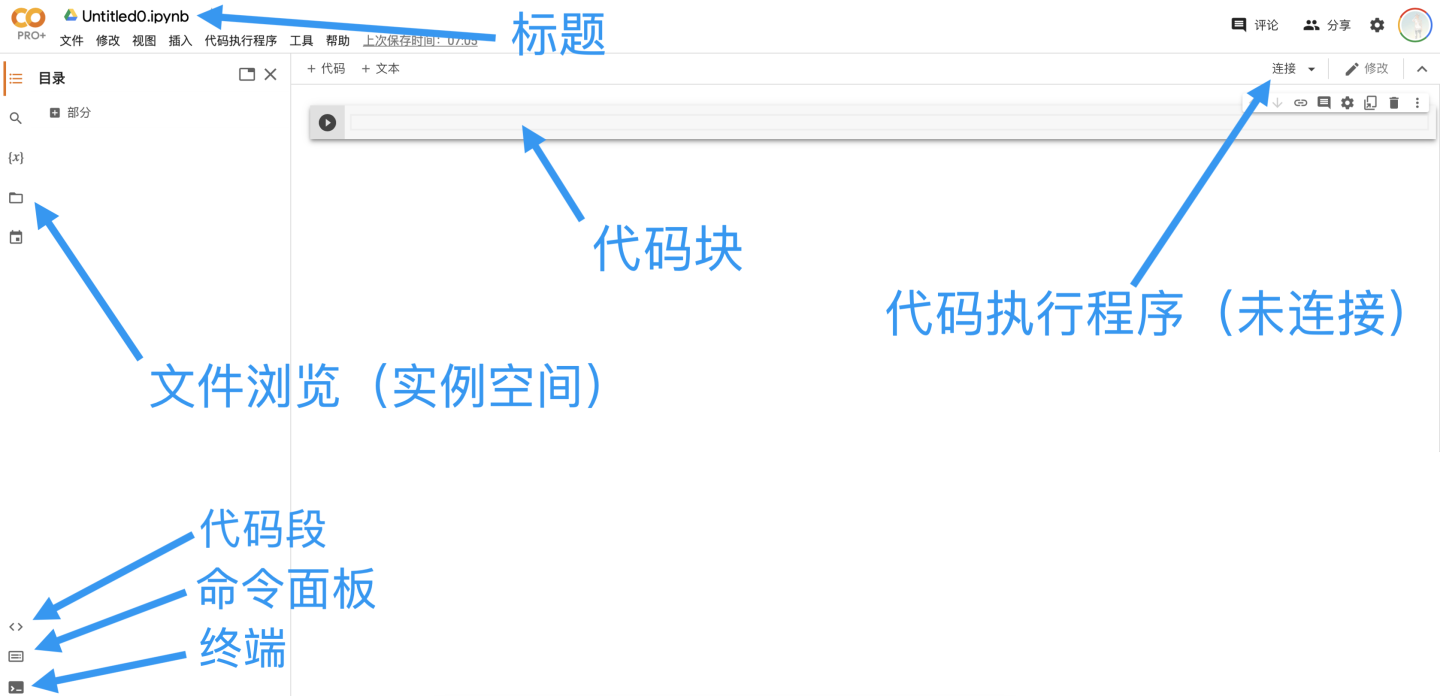 标题:笔记本的名称
代码块:分块执行的代码
文件浏览:Colab为笔记本分配的实例空间
代码执行程序:用于执行笔记本程序的服务器
代码段:常用的代码段,比如装载云端硬盘
命令面板:常用的命令,比如查找/替换
终端:文件浏览下的终端(非常卡,不建议使用)
连接代码执行程序
点击连接按钮即可在5s左右的时间内连接到代码执行程序,此时可以看到消耗的RAM和磁盘
RAM:虚拟机运行内存,更大内存意味着更大的算力(之后会在Colab Pro中介绍)
磁盘:虚拟机文件的储存空间,要注意的是购买更多云端硬盘存储空间不能增加可用磁盘空间
标题:笔记本的名称
代码块:分块执行的代码
文件浏览:Colab为笔记本分配的实例空间
代码执行程序:用于执行笔记本程序的服务器
代码段:常用的代码段,比如装载云端硬盘
命令面板:常用的命令,比如查找/替换
终端:文件浏览下的终端(非常卡,不建议使用)
连接代码执行程序
点击连接按钮即可在5s左右的时间内连接到代码执行程序,此时可以看到消耗的RAM和磁盘
RAM:虚拟机运行内存,更大内存意味着更大的算力(之后会在Colab Pro中介绍)
磁盘:虚拟机文件的储存空间,要注意的是购买更多云端硬盘存储空间不能增加可用磁盘空间
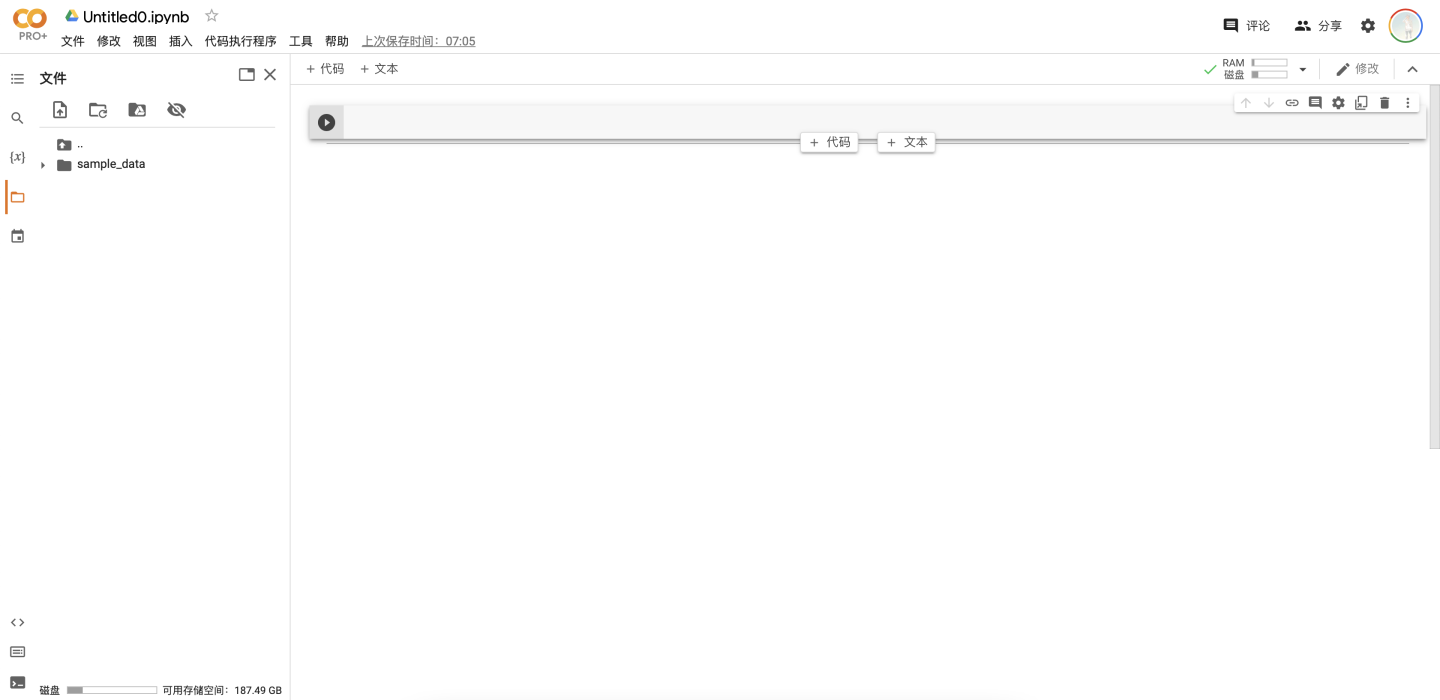 在打开笔记本后,我们默认的文件路径是"/content",这个路径也是执行笔记本时的路径,同时我们一般把用到的各种文件也保存在这个路径下。在点击".."后即可返回查看根目录"/"(如下图),可以看到根目录中保存的是一些虚拟机的环境变量和预装的库等等。不要随意修改根目录中的内容,以避免运行出错,我们所有的操作都应在"/content"中进行。
在打开笔记本后,我们默认的文件路径是"/content",这个路径也是执行笔记本时的路径,同时我们一般把用到的各种文件也保存在这个路径下。在点击".."后即可返回查看根目录"/"(如下图),可以看到根目录中保存的是一些虚拟机的环境变量和预装的库等等。不要随意修改根目录中的内容,以避免运行出错,我们所有的操作都应在"/content"中进行。
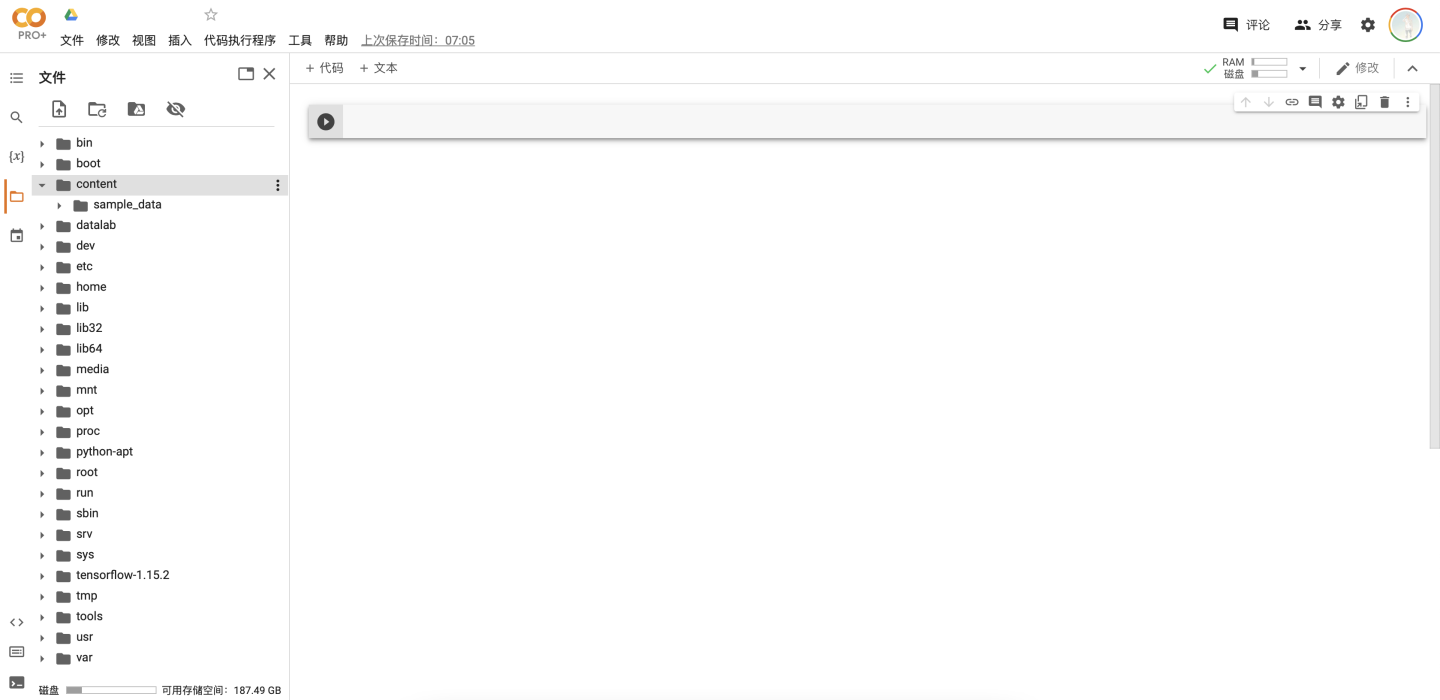 执行代码块
.ipynb文件通过的代码块来执行代码,同时支持通过"!<command>"的方式来执行UNIX终端命令(比如"!ls"可以查看当前目录下的文件)。Colab已经预装了大多数常见的深度学习库,比如pytorch,tensorflow等等,如果有需要额外安装的库可以通过"!pip3 install <package>"命令来安装。下面是一些常见的命令。
执行代码块
.ipynb文件通过的代码块来执行代码,同时支持通过"!<command>"的方式来执行UNIX终端命令(比如"!ls"可以查看当前目录下的文件)。Colab已经预装了大多数常见的深度学习库,比如pytorch,tensorflow等等,如果有需要额外安装的库可以通过"!pip3 install <package>"命令来安装。下面是一些常见的命令。
# 加载云端硬盘 from google.colab import drive drive.mount('/content/drive') # 查看分配到的GPU gpu_info = !nvidia-smi gpu_info = '\n'.join(gpu_info) if gpu_info.find('failed') >= 0: print('Not connected to a GPU') else: print(gpu_info) # 安装python包 !pip3 install <package>点击“播放”按钮执行代码块。代码块开始执行后,按钮就会进入转圈的状态,表示“正在执行”,外部的圆圈是实线。如果在有代码块执行的情况下继续点击其他代码块的“播放”按钮,则这些代码块进入“等待执行”的状态,按钮也就会进入转圈的状态,但外部的圆圈是虚线。在当前代码块结束后,会之前按照点击的顺序依次执行这些代码块。
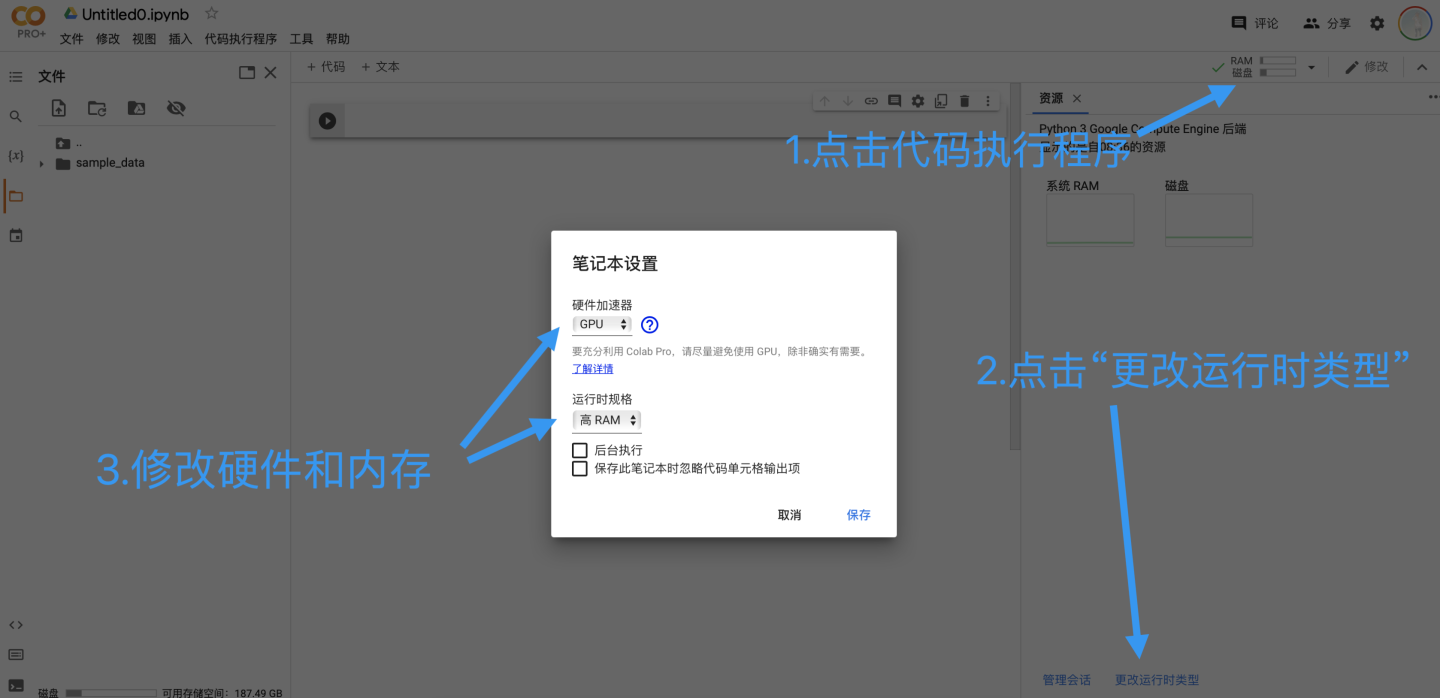
 设置笔记本的运行时类型
笔记本在打开时的默认硬件加速器是None,运行规格是标准。在深度学习中,我们希望使用GPU来进行深度计算,同时如果购买了pro,我们希望使用高内存模式。点击代码执行程序,然后点击“更改运行时类型即可”。由于免费的用户所能使用的GPU运行时有限,由于免费的用户所能使用的GPU运行时有限,因此建议在模型训练结束后调回None模式或直接结束会话。
设置笔记本的运行时类型
笔记本在打开时的默认硬件加速器是None,运行规格是标准。在深度学习中,我们希望使用GPU来进行深度计算,同时如果购买了pro,我们希望使用高内存模式。点击代码执行程序,然后点击“更改运行时类型即可”。由于免费的用户所能使用的GPU运行时有限,由于免费的用户所能使用的GPU运行时有限,因此建议在模型训练结束后调回None模式或直接结束会话。
 如果希望主动断开代码执行程序,则点击代码执行程序后选择“断开连接并删除运行时”即可。
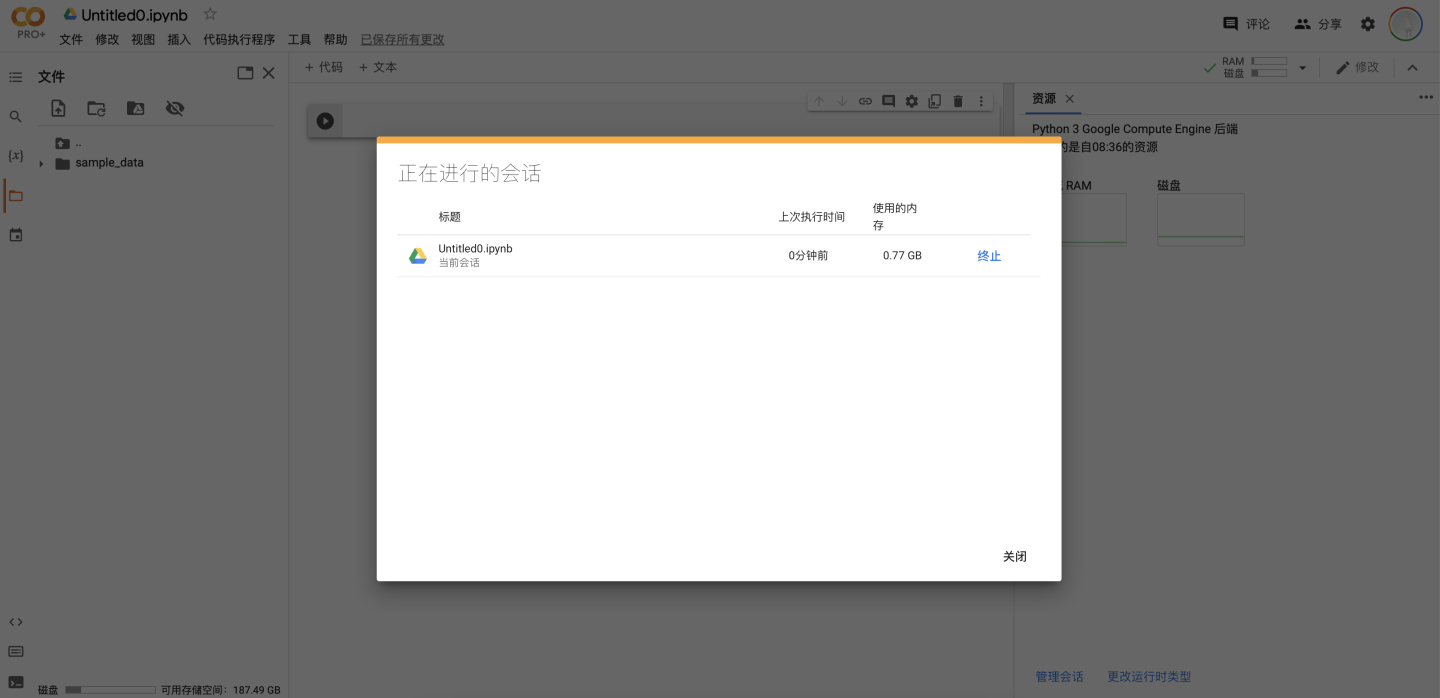
管理会话Session
会话就是当前连接到代码执行程序的笔记本,通过点击“管理会话”即可查看当前的所有会话,点击“终止”即可断开代码执行程序。用户所能连接的会话数量是有限的,因此到达上限时再开启新会话需要主动断开之前的会话。
如果希望主动断开代码执行程序,则点击代码执行程序后选择“断开连接并删除运行时”即可。
管理会话Session
会话就是当前连接到代码执行程序的笔记本,通过点击“管理会话”即可查看当前的所有会话,点击“终止”即可断开代码执行程序。用户所能连接的会话数量是有限的,因此到达上限时再开启新会话需要主动断开之前的会话。
 三、Colab重要特性
在这一部分,我们进一步了解Colab平台的一些重要特性和使用Colab训练模型时的一些策略
资源使用的限制
Google Colab为用户提供免费的GPU,因此资源使用必然会受到限制(即使是Colab Pro+用户也不例外),而这种限制无处不在。
有限的实例空间:实例空间的内存和磁盘都是有限制的,如果模型训练的过程中超过了内存或磁盘的限制,那么程序运行就会中断并报错。实例空间内的文件保存不是永久的,当代码执行程序被断开时,实例空间内的所有资源都会被释放(我们在"/content"目录下上传的文件也会全部消失)。
三、Colab重要特性
在这一部分,我们进一步了解Colab平台的一些重要特性和使用Colab训练模型时的一些策略
资源使用的限制
Google Colab为用户提供免费的GPU,因此资源使用必然会受到限制(即使是Colab Pro+用户也不例外),而这种限制无处不在。
有限的实例空间:实例空间的内存和磁盘都是有限制的,如果模型训练的过程中超过了内存或磁盘的限制,那么程序运行就会中断并报错。实例空间内的文件保存不是永久的,当代码执行程序被断开时,实例空间内的所有资源都会被释放(我们在"/content"目录下上传的文件也会全部消失)。

 有限的连接时间:笔记本连接到代码执行程序的时长是有限制的,这体现在三个方面:如果关闭浏览器,代码执行程序会在短时间内断开而不是在后台继续执行(这个“短时间”大概在几分钟左右,如果只是切换一下wifi之类是不会有影响的);如果空闲状态过长(无互动操作或正在执行的代码块),则会立即断开连接;如果连接时长到达上限(免费用户最长连接12小时),也会立刻断开连接。
有限的连接时间:笔记本连接到代码执行程序的时长是有限制的,这体现在三个方面:如果关闭浏览器,代码执行程序会在短时间内断开而不是在后台继续执行(这个“短时间”大概在几分钟左右,如果只是切换一下wifi之类是不会有影响的);如果空闲状态过长(无互动操作或正在执行的代码块),则会立即断开连接;如果连接时长到达上限(免费用户最长连接12小时),也会立刻断开连接。
 有限的GPU运行时:无论是免费用户还是colab pro用户,每天所能使用的GPU运行时间都是有限的。到达时间上限后,代码执行程序将被立刻断开且用户将被限制在当天继续使用任何形式的GPU(无论是否为高RAM形式)。在这种情况下我们只能等待第二天重置。
有限的GPU运行时:无论是免费用户还是colab pro用户,每天所能使用的GPU运行时间都是有限的。到达时间上限后,代码执行程序将被立刻断开且用户将被限制在当天继续使用任何形式的GPU(无论是否为高RAM形式)。在这种情况下我们只能等待第二天重置。
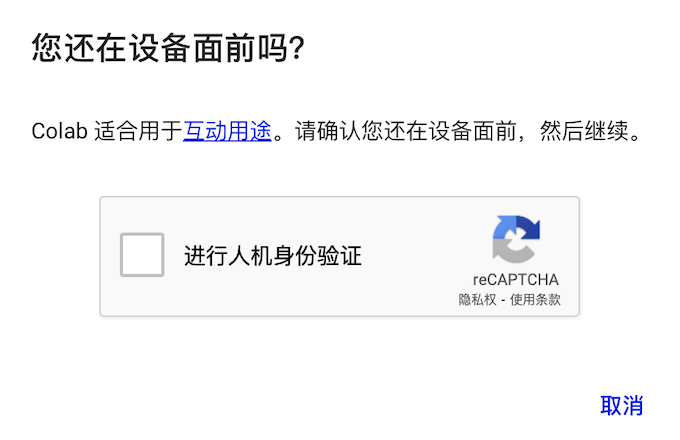
 频繁的互动检测:当一段时间没有检测到活动时,Colab就会进行互动检测,如果长时间不点击人机身份验证,代码执行程序就会断开。此外,如果频繁地执行“断开-连接”代码执行程序,也会出现人机身份验证。
频繁的互动检测:当一段时间没有检测到活动时,Colab就会进行互动检测,如果长时间不点击人机身份验证,代码执行程序就会断开。此外,如果频繁地执行“断开-连接”代码执行程序,也会出现人机身份验证。
 有限的会话数量:每个用户所能开启的会话数量都是有限的,免费用户只能开启1个会话,Pro用户则可以开启多个会话。不同的用户可以在一个笔记本上可以进行多个会话,但只能有一个代码块开始执行。如果某个代码块已经开始执行,另一个用户连接到笔记本的会话会显示“忙碌状态”,需要等待代码块执行完后才能执行其他的代码块。注意:掉线重连、切换网络、刷新页面等操作也会使笔记本进入“忙碌状态”。
有限的会话数量:每个用户所能开启的会话数量都是有限的,免费用户只能开启1个会话,Pro用户则可以开启多个会话。不同的用户可以在一个笔记本上可以进行多个会话,但只能有一个代码块开始执行。如果某个代码块已经开始执行,另一个用户连接到笔记本的会话会显示“忙碌状态”,需要等待代码块执行完后才能执行其他的代码块。注意:掉线重连、切换网络、刷新页面等操作也会使笔记本进入“忙碌状态”。
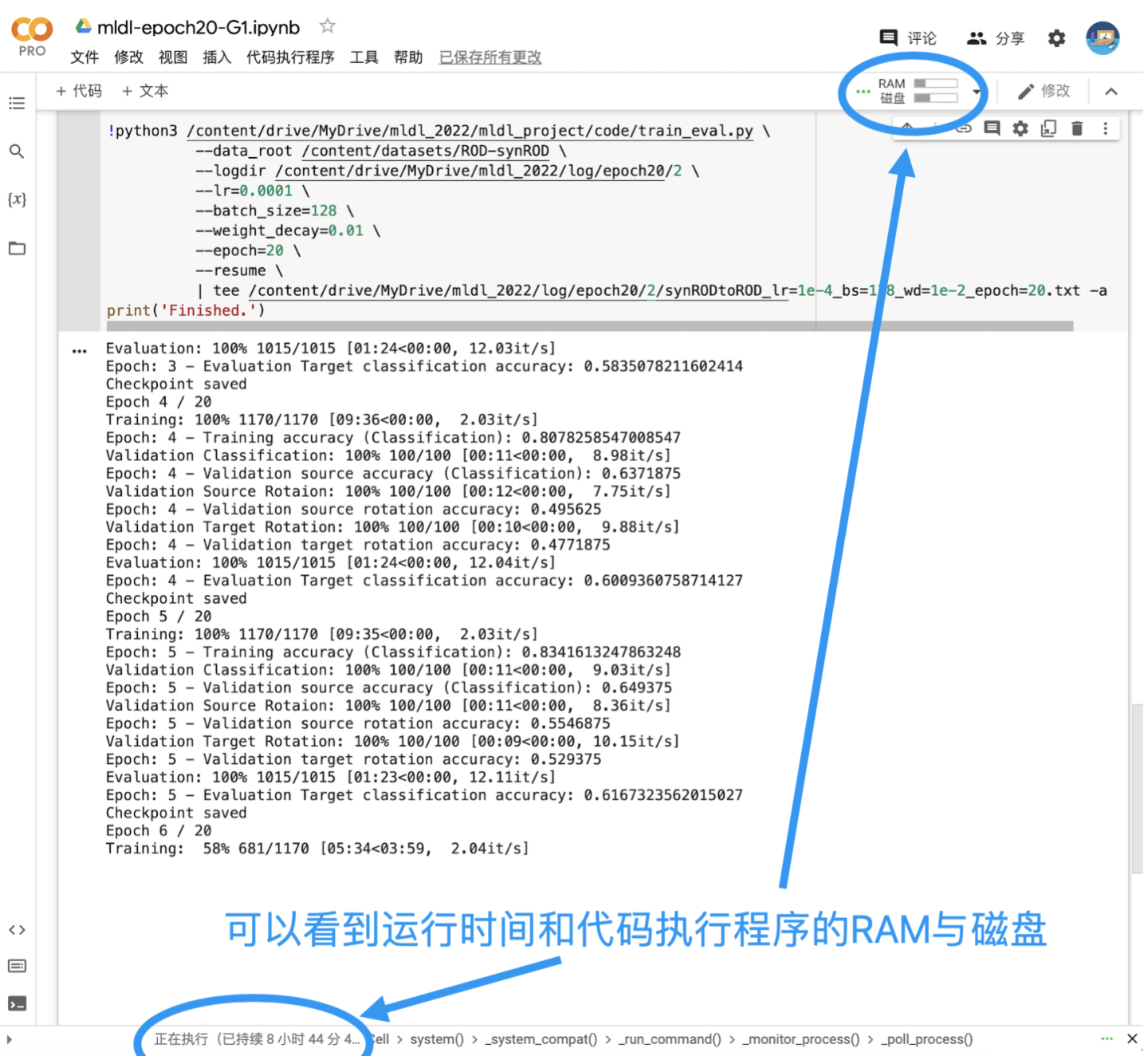 正常情况
正常情况
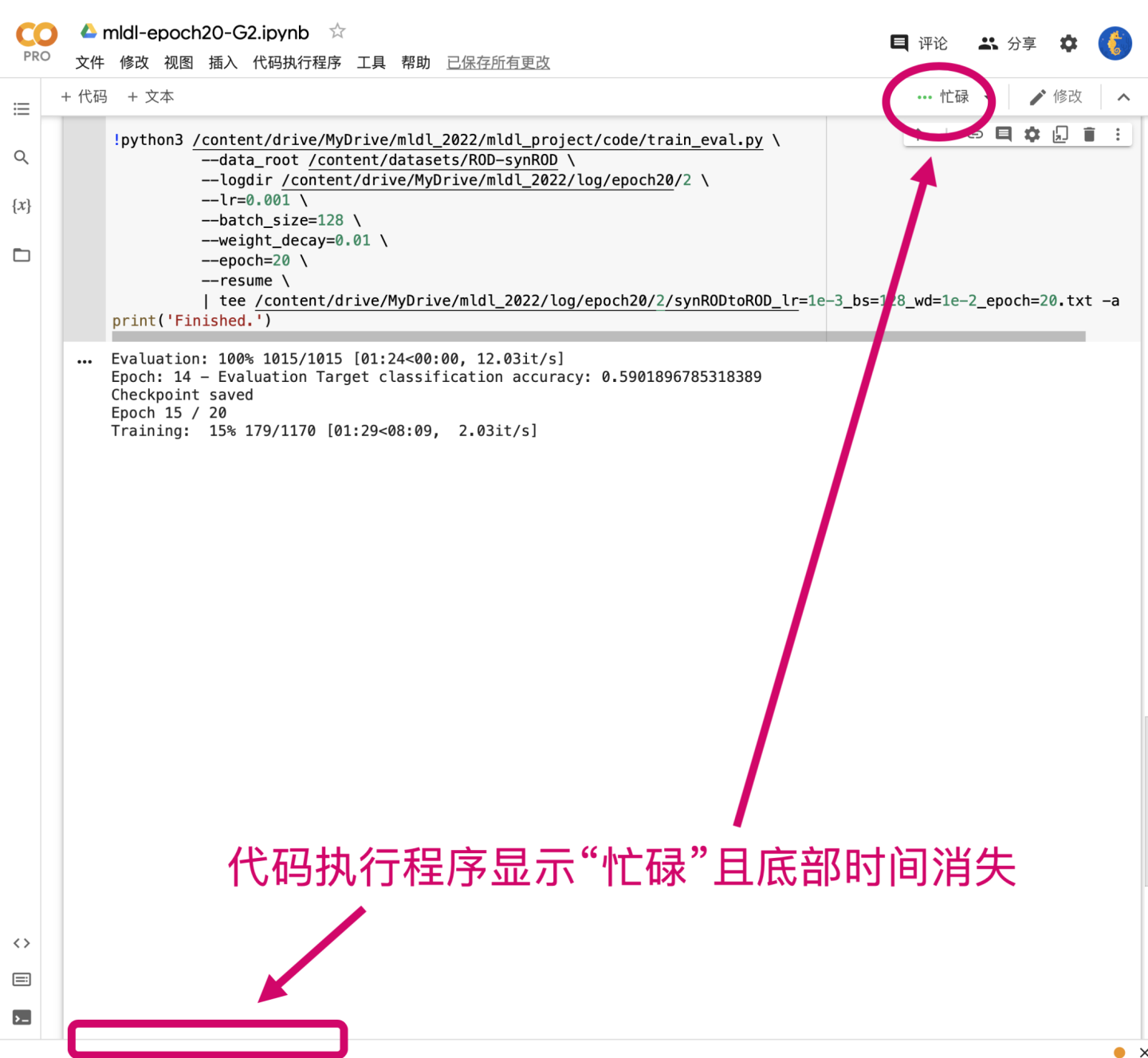 忙碌状态
如何合理使用资源?
忙碌状态
如何合理使用资源?
- 将训练过后的模型日志和其他重要的文件保存到谷歌云盘,而不是本地的实例空间
- 运行的代码必须支持“断点续传”能力,简单来说就是必须定义类似checkpoint功能的函数;假设我们一共需要训练40个epochs,在第30个epoch掉线了之后模型能够从第30个epoch开始训练而不是从头再来
- 仅在模型训练时开启GPU模式,在构建模型或其他非必要情况下使用None模式
- 在网络稳定的情况下开始训练,每隔一段时间查看一下训练的情况
- 注册多个免费的谷歌账号交替使用
# 克隆仓库到/content/my-repo目录下 !git clone https://github.com/my-github-username/my-git-repo.git %cd my-git-repo !./train.py --logdir /my/log/path --data_root /my/data/root --resume2. 克隆git仓库到实例空间或云盘,把主程序中的代码用函数封装,然后在notebook中调用这些函数
from train import my_training_method my_training_method(arg1, arg2, ...)由于笔记本默认的路径是"/content",因此可能需要修改系统路径后才能直接导入
import sys sys.path.append('/content/my-git-repo') # 把git仓库的目录添加到系统目录3. 克隆git仓库到实例空间或云盘,把原来的主程序模块直接复制到笔记本中 类似于第二种方法,需要将git仓库路径添加到系统路径,否则会找不到导入的模块 如何处理简单项目? 如果只有几个轻量的模块,也不打算使用git进行版本管理,则直接上传到实例空间即可
 五、实例演示
下面以我在这个学期完成的项目为例,向大家完整展示Colab的使用过程。PS:真不是推销自己的项目,而是目前我只做了这一个项目(ಥ_ಥ)
云盘链接:https://drive.google.com/drive/folders/1-4z_Y38jMmIZNe5sNzbF1Le1Kv_ugFcd?usp=sharing
点击以后就可以在谷歌云盘的“与我共享”看到这个文件夹"zhihu_colab",将这个文件夹的快捷方式添加到自己的云盘即可(右键文件夹“将快捷方式添加到云盘”,选择“我的云端硬盘”)
文件夹"zhihu_colab"中包含了数据集"ROD-synROD.tar"和代码"mldl_project"(以及这部分我写的notebook)
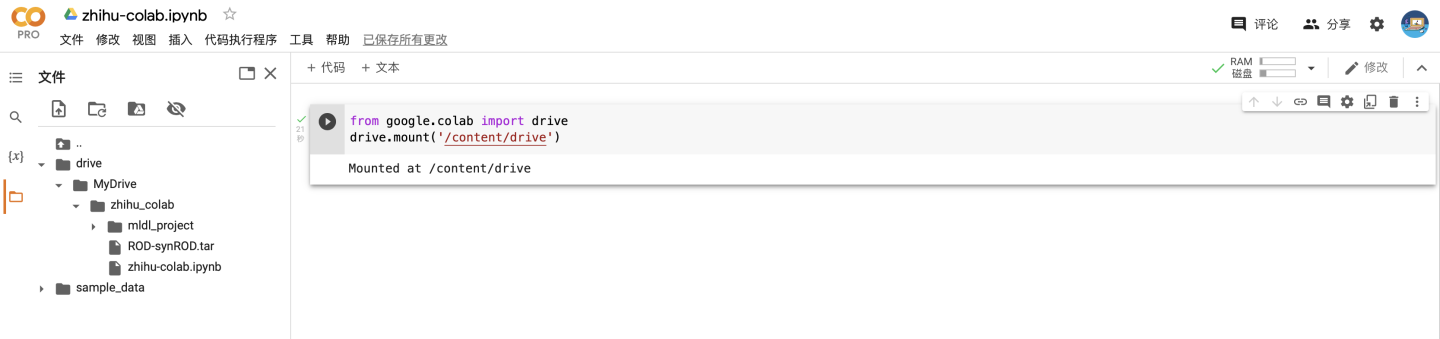
首先加载自己的谷歌云盘
五、实例演示
下面以我在这个学期完成的项目为例,向大家完整展示Colab的使用过程。PS:真不是推销自己的项目,而是目前我只做了这一个项目(ಥ_ಥ)
云盘链接:https://drive.google.com/drive/folders/1-4z_Y38jMmIZNe5sNzbF1Le1Kv_ugFcd?usp=sharing
点击以后就可以在谷歌云盘的“与我共享”看到这个文件夹"zhihu_colab",将这个文件夹的快捷方式添加到自己的云盘即可(右键文件夹“将快捷方式添加到云盘”,选择“我的云端硬盘”)
文件夹"zhihu_colab"中包含了数据集"ROD-synROD.tar"和代码"mldl_project"(以及这部分我写的notebook)
首先加载自己的谷歌云盘
from google.colab import drive drive.mount('/content/drive')加载成功以后(可以点一下刷新按钮)就可以看到云盘在实例空间中出现了 谷歌云盘默认的加载路径是"/content/drive/MyDrive"
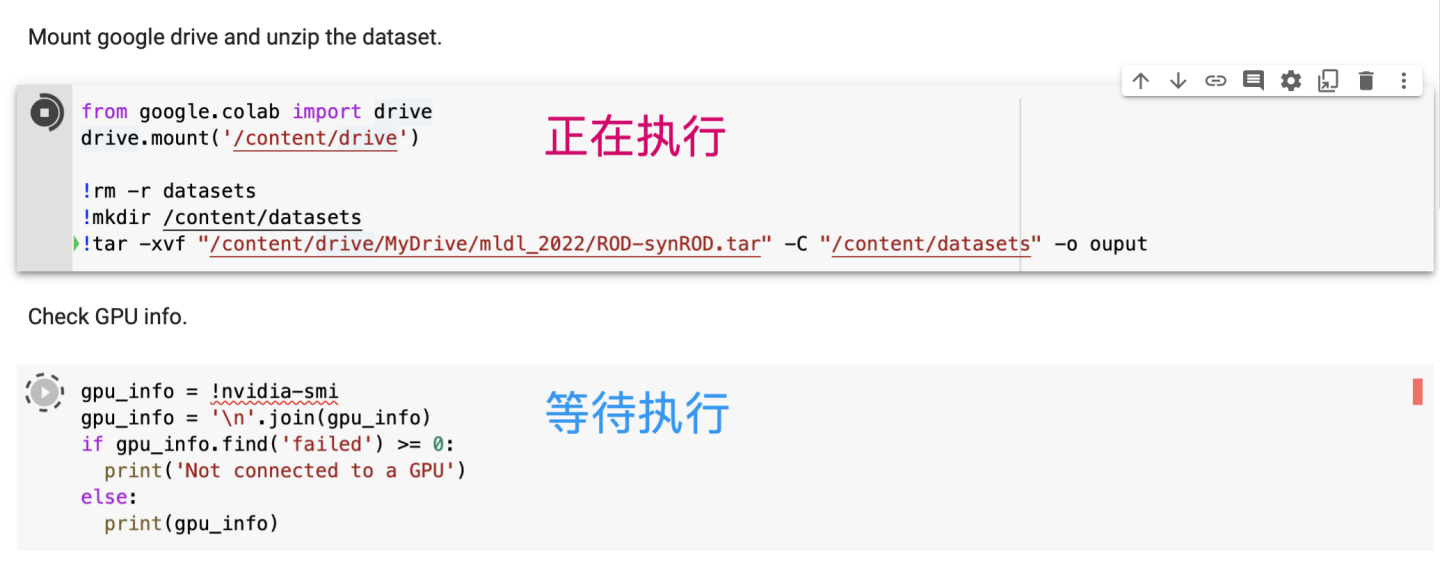
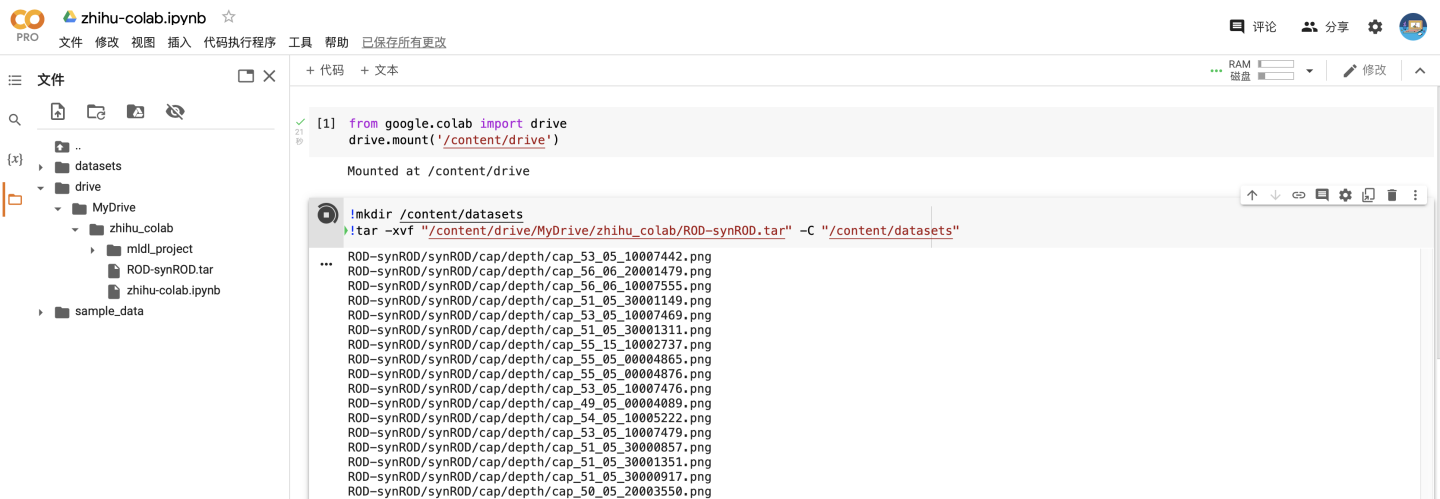
 在当前目录下("/content")创建一个叫datasets的文件夹,并将"zhihu_colab"中的数据集解压到这个文件夹
在当前目录下("/content")创建一个叫datasets的文件夹,并将"zhihu_colab"中的数据集解压到这个文件夹
!mkdir /content/datasets !tar -xvf "/content/drive/MyDrive/zhihu_colab/ROD-synROD.tar" -C "/content/datasets"
 查看一下自己分到的GPU是什么,具体的信息很长,只要看中间显卡部分就行了。
查看一下自己分到的GPU是什么,具体的信息很长,只要看中间显卡部分就行了。
gpu_info = !nvidia-smi gpu_info = '\n'.join(gpu_info) if gpu_info.find('failed') >= 0: print('Not connected to a GPU') else: print(gpu_info)
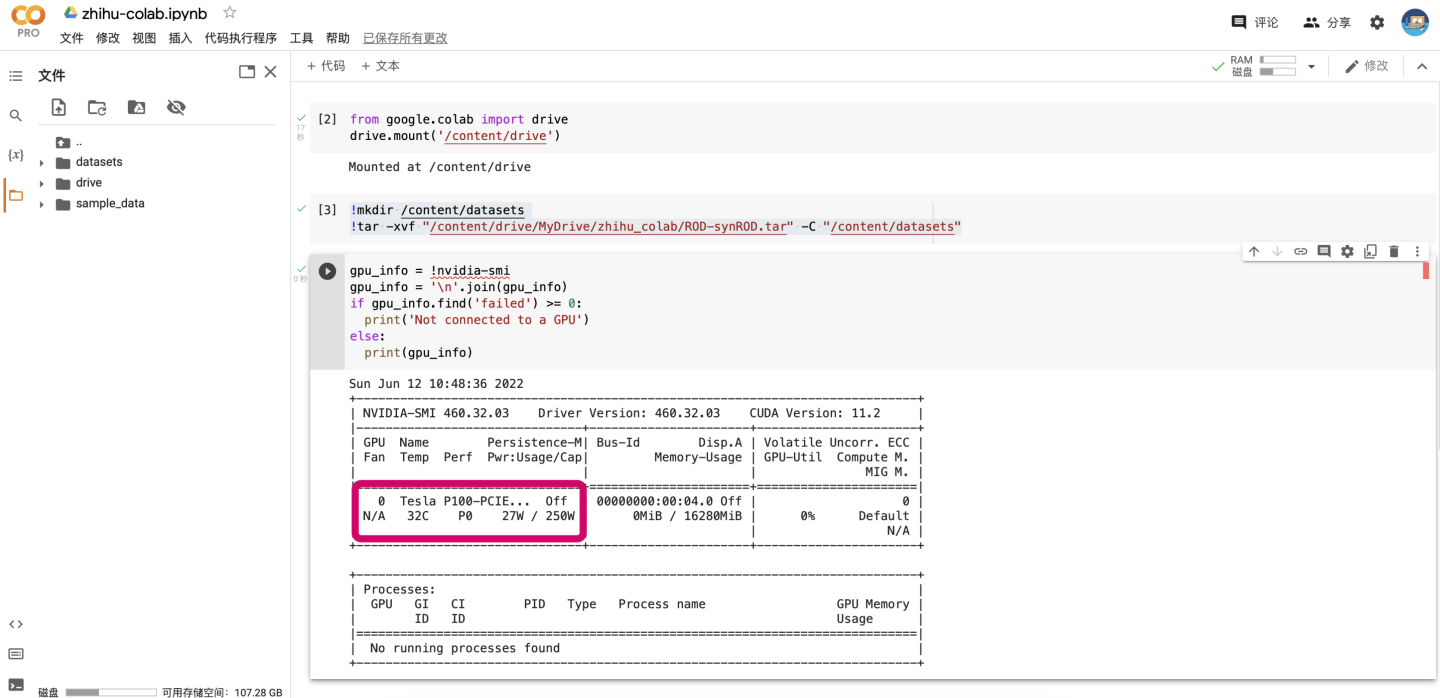 哇哦,我们作为高贵的Pro用户果然分到了最好的P100
哇哦,我们作为高贵的Pro用户果然分到了最好的P100