本文摘录总结与极客时间——《Java 业务开发常见错误 100 例》
现代编程语言一般都会提供各种数据结构的实现,供我们开箱即用。比如 Java 中就提供了集合类的各种实现,其中List 列表集合是最重要也是所有业务代码都会用到的。所以,今天我们就从数组转换到 List 集合、对 List 进行切片操作、List 搜搜的性能问题等几个方面着手,聊聊最可能出现的问题。
使用 Arrays.asList 把数组转换为 List 的三个坑Arrays.asList 方法可以吧数组一键转换为 List, 但其实没这么简单。接下来,就让我们看看其中的缘由:
int[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
log.info("list:{} size:{} class:{}", list, list.size(), list.get(0).getClass());
但这样初始化的 List 并不是我们期望包含了 3 个数字的 List。通过 日志可以发现,这个 List 其实包含了是一个 int 数组,整个 List 的个数是 1,元素类型是整数数组。
12:50:39.445 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - list:[[I@1c53fd30] size:1 class:class [I
我们可以进入源码,发现 Arrays 在自己类的内部实现了一个 ArrayList,并且,我们的数组的类型是 int,Java 只能够将 int 装箱为 Integer,不可能把 int 数组装箱为 Integer 数组。ArraysList.asList 方法传入的是一个泛型 T 类型可变参数,最终 int 数组整体作为一个对象成为了泛型类型 T:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
解决方案是使用 Java8 的 Stream 来装箱转换:
int[] arr1 = {1, 2, 3};
List<Integer> list = Arrays.stream(arr1).boxed().collect(Collectors.toList());
log.info("list:{} size:{} class:{}", list, list.size(), list.get(0).getClass());
修改后的代码得到的结果是:
13:10:57.373 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - list:[1, 2, 3] size:3 class:class java.lang.Integer
所以我们得到的第一个结论是:不能直接使用 Arrays.asList 来转换基本类型数组。
好的,那么我们现在得到了一个正确的 List,那么是否可以直接无所顾虑的使用了呢?
现在我们把 int 数组替换为 String 数组,将原始字符串数组的第二个字符修改为 4,然后为 List 增加一个字符串 5,这个操作可行吗?
String[] arr = {"1", "2", "3"};
List list = Arrays.asList(arr);
arr[1] = "4";
try {
list.add("5");
} catch (Exception ex) {
ex.printStackTrace();
}
log.info("arr:{} list:{}", Arrays.toString(arr), list);
可以看到,日志里有一个UnsupportedOperationException,为 List 新增字符串 5 的操作失败了,而且把原始数组的第二个元素从 2 修改为 4 后,asList 获得的 List 中的第二个元素也被修改为 4 了。
这里又引出了两个坑,Arrays.asList 返回的 List 不支持增删操作。由于返回的对象是Arrays 的内部类 ArrayList。ArrayList 内部类继承自 AbstractList 类,并没有覆写父类的 add 方法,而父类中 add 方法的实现,就是抛出 UnsupportedOperationException。
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable
{
private final E[] a;
ArrayList(E[] array) {
a = Objects.requireNonNull(array);
}
...
@Override
public E set(int index, E element) {
E oldValue = a[index];
a[index] = element;
return oldValue;
}
...
}
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
...
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
}
第三个坑,对原始数组的修改会影响到我们获取的那个 List。看到上面的源码,Arrays 的内部 ArrayList 其实是直接使用了原始的数组。修复方案是用 new ArrayList 的方式。
业务开发常常会用到 List 做切片处理,即去除其中部分元素构成一个新的 List,但是 subList 方法返回的子 List 不是一个普通的 ArrayList,是会和原始 List 相互影响的,一个不注意,就会导致 OOM。
如下图代码所示:
private static List<List<Integer>> data = new ArrayList<>();
private static void oom() {
for (int i = 0; i < 1000; i++) {
List<Integer> rawList = IntStream.rangeClosed(1, 100000).boxed().collect(Collectors.toList());
data.add(rawList.subList(0, 1));
}
}
初看可能觉得这段代码没什么,这就只是 data 变量里面最终保存的只是 1000 个具有 1 个元素的 List,不会占用很大空间,但程序运行不久就会出现 OOM:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3181)
at java.util.ArrayList.grow(ArrayList.java:265)
出现 OOM 的原因是,循环中的 1000 个具有 10 万个元素的 List 始终得不到回收,因为它始终被 subList 方法返回的 List 强引用。那么,这是为什么呢?别急,继续看它的其他特性。
首先初始化一个包含数字 1 到 10 的 ArrayList,然后通过调用 subList 方法取出 2、3、4;随后删除这个 SubList 中的元素数字 3,并打印原始的 ArrayList;最后为原始的 ArrayList 增加一个元素数字 0,遍历 SubList 输出所有元素:
List<Integer> list = IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toList());
List<Integer> subList = list.subList(1, 4);
System.out.println(subList);
subList.remove(1);
System.out.println(list);
list.add(0);
try {
subList.forEach(System.out::println);
} catch (Exception ex) {
ex.printStackTrace();
}
运行代码:
[2, 3, 4]
[1, 2, 4, 5, 6, 7, 8, 9, 10]
java.util.ConcurrentModificationException
at java.util.ArrayList$SubList.checkForComodification(ArrayList.java:1239)
at java.util.ArrayList$SubList.listIterator(ArrayList.java:1099)
at java.util.AbstractList.listIterator(AbstractList.java:299)
at java.util.ArrayList$SubList.iterator(ArrayList.java:1095)
at java.lang.Iterable.forEach(Iterable.java:74)
现象是:
- 原始 List 中数字 3 被删除了,说明删除子 List 中的元素影响到了原始 List
- 尝试为原始 List 增加数字 0 之后再遍历子 List,会出现ConcurrentModificationException。
我们看到 ArrayList 的源码分析一下:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected transient int modCount = 0;
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, offset, fromIndex, toIndex);
}
private class SubList extends AbstractList<E> implements RandomAccess {
private final AbstractList<E> parent;
private final int parentOffset;
private final int offset;
int size;
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
public E set(int index, E element) {
rangeCheck(index);
checkForComodification();
return l.set(index+offset, element);
}
public ListIterator<E> listIterator(final int index) {
checkForComodification();
...
}
private void checkForComodification() {
if (ArrayList.this.modCount != this.modCount)
throw new ConcurrentModificationException();
}
...
}
}
- ArrayList 维护了一个 modCount 的字段,表示集合结构性修改的次数。这里的结构性修改,指的是影响 List 大小的操作,所以 add 方法就会改变 modCount 的值。
- 21-24 的 subList 方法可以看到,获取的 List 其实是内部类 SubList。
- 26-39 可以发现,这个 SubList 的 parent 字段就是原始的 List。初始化的时候没有把原始的 List 中的元素复制到独立的变量中,那么可以认为 SubList 是原始 List 的视图,对 SubList 的操作就是对原始 List 的操作,那么这里就强引用了,所以大量保存这样的 SubList 会导致 OOM。
- 47-55 遍历 SubList 的时候会先获得迭代器,比较原始 ArrayList modCount 的值和 SubList 当前 modCount 的值,而我们是先 add 原始 List,然后去遍历的 SubList,这样肯定会判等失败抛出异常。
这里是有两种解决方案的:
//方式一:
// 重新使用 new ArrayList
List<Integer> subList = new ArrayList<>(list.subList(1, 4));
//方式二:
// 对于 Java 8 使用 Stream 的 skip 和 limit API 来跳过流中的元素,以及限制流中元素的个数,同样可以达到 SubList 切片的目的。
List<Integer> subList = list.stream().skip(1).limit(3).collect(Collectors.toList());
- 使用数据结构不考虑平衡时间和空间
定义一个 Order 类:
@Data
@NoArgsConstructor
@AllArgsConstructor
static class Order {
private int orderId;
}
随后定义一个 包含 elementCount 和 loopCount 两个参数的 listSearch 方法,初始化一个具有 elementCount 个订单对象的 ArrayList,循环 loopCount 次搜索这个 ArrayList,每次随机搜索一个订单号:
private static Object listSearch(int elementCount, int loopCount) {
List<Order> list = IntStream.rangeClosed(1, elementCount).mapToObj(i -> new Order(i)).collect(Collectors.toList());
IntStream.rangeClosed(1, loopCount).forEach(i -> {
int search = ThreadLocalRandom.current().nextInt(elementCount);
Order result = list.stream().filter(order -> order.getOrderId() == search).findFirst().orElse(null);
Assert.assertTrue(result != null && result.getOrderId() == search);
});
return list;
}
随后,定义另一个 mapSearch 方法,从一个具有 elementCount 个元素的 Map 中循环 loopCount 次查找随机订单号。Map 的 Key 是订单号,Value 是订单对象:
private static Object mapSearch(int elementCount, int loopCount) {
Map<Integer, Order> map = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toMap(Function.identity(), i -> new Order(i)));
IntStream.rangeClosed(1, loopCount).forEach(i -> {
int search = ThreadLocalRandom.current().nextInt(elementCount);
Order result = map.get(search);
Assert.assertTrue(result != null && result.getOrderId() == search);
});
return map;
}
我们知道,搜索 ArrayList 的时间复杂度是 O(n),而 HashMap 的 get 操作的时间复杂度是 O(1)。所以,要对大 List 进行单值搜索的话,可以考虑使用 HashMap,其中 Key 是要搜索的值,Value 是原始对象,会比使用 ArrayList 有非常明显的性能优势。
int elementCount = 1000000;
int loopCount = 1000;
StopWatch stopWatch = new StopWatch();
stopWatch.start("listSearch");
Object list = listSearch(elementCount, loopCount);
System.out.println(ObjectSizeCalculator.getObjectSize(list));
stopWatch.stop();
stopWatch.start("mapSearch");
Object map = mapSearch(elementCount, loopCount);
stopWatch.stop();
System.out.println(ObjectSizeCalculator.getObjectSize(map));
System.out.println(stopWatch.prettyPrint());
可以看到,仅仅是 1000 次搜索,listSearch 方法耗时 3.3 秒,而 mapSearch 耗时仅仅 108 毫秒。
的确,如果业务代码中有频繁的大 ArrayList 搜索,使用 HashMap 性能会好很多。类似,如果要对大 ArrayList 进行去重操作,也不建议使用 contains 方法,而是可以考虑使用 HashSet 进行去重。说到这里,还有一个问题,使用 HashMap 是否会牺牲空间呢?
为此,我们使用第三方工具打印ArrayList 和 HashMap 的内存占用,可以看到 ArrayList 占用内存 21M,而 HashMap 占用的内存达到了 72M,是 List 的三倍多。

所以,如果考虑到内存吃紧的情况下,我们就需要考虑到时间与空间之间的平衡关系。
- 第二个误区,过于迷信可教书的大 O 时间复杂度
不知道你之前有没有看到 linkedList 作者说的:
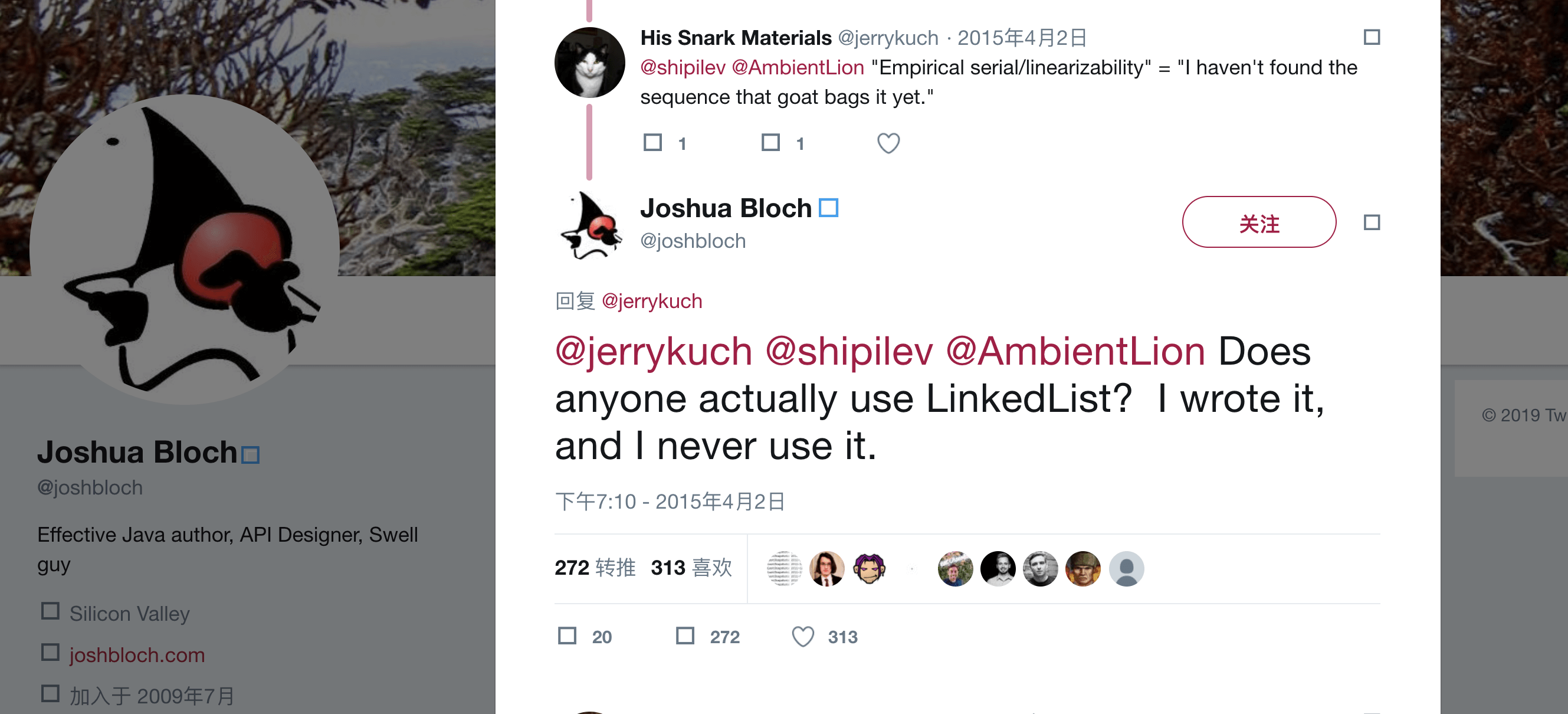
首先我们知道 ArrayList 在随机访问方面是优于 linkedlist,这是母庸质疑的,你可以测试一下 10 万个元素下的随机访问耗时。
但仅仅是随机访问优于 linkedList 吗?
int elementCount = 100000;
int loopCount = 100000;
StopWatch stopWatch = new StopWatch();
stopWatch.start("linkedListGet");
linkedListGet(elementCount, loopCount);
stopWatch.stop();
stopWatch.start("arrayListGet");
arrayListGet(elementCount, loopCount);
stopWatch.stop();
System.out.println(stopWatch.prettyPrint());
StopWatch stopWatch2 = new StopWatch();
stopWatch2.start("linkedListAdd");
linkedListAdd(elementCount, loopCount);
stopWatch2.stop();
stopWatch2.start("arrayListAdd");
arrayListAdd(elementCount, loopCount);
stopWatch2.stop();
System.out.println(stopWatch2.prettyPrint());
运行结果可能会让你大跌眼镜。在随机访问方面,我们看到了 ArrayList 的绝对优势,耗时只有 11 毫秒,而 LinkedList 耗时 6.6 秒,这符合上面我们所说的时间复杂度;但,随机插入操作居然也是 LinkedList 落败,耗时 9.3 秒,ArrayList 只要 1.5 秒:
---------------------------------------------
ns % Task name
---------------------------------------------
6604199591 100% linkedListGet
011494583 000% arrayListGet
StopWatch '': running time = 10729378832 ns
---------------------------------------------
ns % Task name
---------------------------------------------
9253355484 086% linkedListAdd
1476023348 014% arrayListAdd
翻看 LinkedList 源码发现,插入操作的时间复杂度是 O(1) 的前提是,你已经有了那个要插入节点的指针。但,在实现的时候,我们需要先通过循环获取到那个节点的 Node,然后再执行插入操作。前者也是有开销的,不可能只考虑插入操作本身的代价:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
这可能也应了作者的话,虽然 LinkedList 是我写的但我从来不用,有谁会真的用吗?