
前面我们剖析了Redisson的源码,主要分析了Redisson实现Redis分布式锁的15问,理清了Redisson是如何实现的分布式锁和一些其它的特性。这篇文章就来接着剖析Zookeeper分布式锁的实现框架Curator的源码,看看Curator是如何实现Zookeeper分布式锁的,以及它提供的哪些其它的特性。
Curator框架是封装对于zk操作的api,其中就包括了对分布式锁的实现,当然Curator框架也包括其它的功能,分布式锁只是Curator的一部分功能。
本文的目录跟Redisson文章的目录比较相似,主要是为了方便大家对比redis和zk分布式锁的实现。如需要Redisson源码剖析的文章,请关注微信公众号 三友的java日记,回复 Redisson 即可。
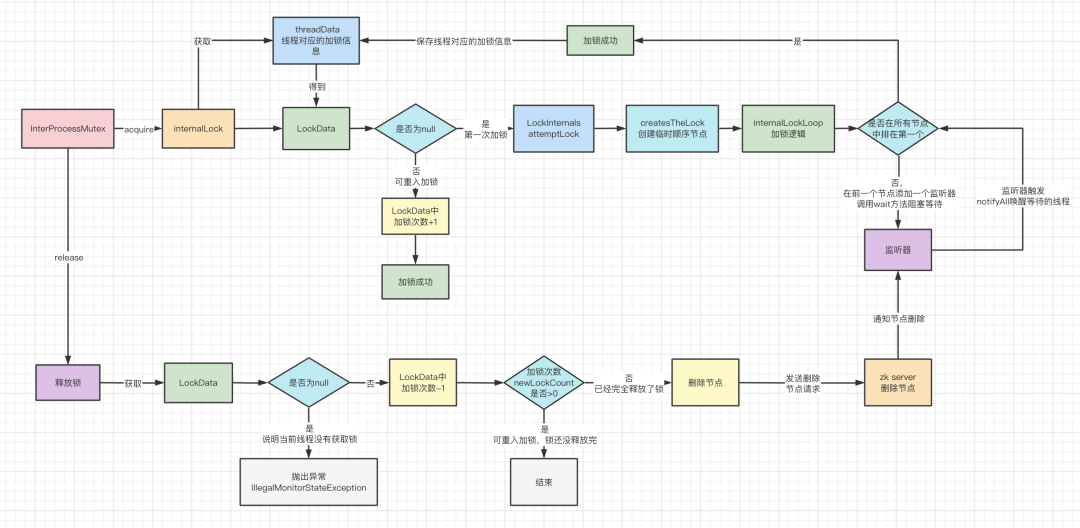
一、ZK分布式锁实现原理实现Zookeeper分布式锁,主要是基于Zookeeper的临时顺序节点来实现的。
当客户端来加锁的时候,会先在加锁的节点下建立一个子节点,这个节点就有一个序号,类似 lock-000001 ,创建成功之后会返回给客户端所创建的节点,然后客户端会去获取这个加锁节点下的所有客户端创建的子节点,当然也包括自己创建的子节点。拿到所有节点之后,给这些节点进行排序,然后判断自己创建的节点在这些节点中是否排在第一位,如果是的话,那么就代表当前客户端就算加锁成功了,如果不是的话,那么就代表当前客户端加锁失败。
加锁失败的节点并不会不停地循环去尝试加锁,而是在自己创建节点的前一个节点上加一个监听器,然后就进行等待。当前面一个节点释放了锁,就会反过来通知等待的客户端,然后客户端就加锁成功了。
为什么需要在前一个节点加个监听器?
假设有很多客户端来加锁,然后加锁失败的都对前一个节点加一个监听。那么一旦第一个加锁成功的客户端线程释放了锁,那么被唤醒的就是第二个客户端线程,第二个客户端线程就会加锁成功,执行完任务之后就释放了锁,那么就会唤醒第三个客户端线程,第三个客户端线程加锁成功,执行完任务之后就释放了锁,唤醒第四个客户端线程,以此类推,所以每次释放锁都会唤醒下一个节点,这样每个加锁的线程都会加锁成功,所以监听器的作用是唤醒加锁失败阻塞等待的客户端。
二、为什么使用临时顺序节点下面介绍一下临时节点、持久化节点、顺序节点的特性。
1)临时节点
临时节点,指的是节点创建后,如果创建节点的客户端和 Zookeeper 服务端的会话失效(例如断开连接),那么节点就会被删除。
2)持久化节点
持久化节点指的是节点创建后,即使创建节点的客户端和 Zookeeper 服务端的会话失效(例如断开连接),节点也不会被删除,只有客户端主动发起删除节点的请求,节点才会被删除。
3)有序节点
有序节点,这种节点在创建时会有一个序号,这个序号是自增的。有序节点既可以是有序临时节点,也可以是有序持久化节点。
从上面节点的特性可以知道,临时节点相比持久节点,最主要的是对会话失效的情况处理不一样,如果使用临时节点的话,如果客户端发生异常的话,没有来得及主动释放锁,就能避免锁无法释放导致死锁的情况。因为一旦客户端异常,那么客户端和服务端之间的会话就会失效,然后临时节点就会被删除,这样就释放了锁;而持久化节点在由于会话失效无法被删除,那么就不会去释放锁,这样就会产生死锁的问题。
从这里可以看出redis和zk防止死锁的实现是不同的,redis是通过过期时间来防止死锁,而zk是通过临时节点来防止死锁的。
为什么使用顺序节点?其实为了防止羊群效应。如果没有使用顺序节点,假设很多客户端都会去加锁,那么加锁就会都失败,都会对加锁的节点加个监听器,那么一旦锁释放,那么所有的加锁客户端都会被唤醒来加锁,那么一瞬间就会造成很多加锁的请求,增加服务端的压力。
所以综上,临时顺序节点是个比较好的选择。
三、加锁的逻辑是如何实现的前面关于ZK分布式锁实现原理已经说过了,接下来就来看一下代码的实现。
加锁的使用方法如下,接下来几节会着重讲解这段代码背后的逻辑
acquire方法的实现
acquire方法会去调用internalLock方法,传入超时时间 -1 和单位 null,也就代表了如果加锁不成功会一直阻塞直至加锁成功,不会超时。
internalLock方法会先去获取当前线程,然后从threadData中获取当前线程对应的LockData,这里面封装了加锁的信息和次数,是实现可重入锁的关键,当然第一次加锁这里肯定是没有的,会继续下走 internals.attemptLock 加锁。
attemptLock方法
先通过driver的createsTheLock去创建节点。
从这里看出,创建的节点类型是临时顺序节点,创建成功之后,就会返回当前创建的节点。
节点创建成功之后,会调用internalLockLoop方法来加锁。
通过getSortedChildren方法获取排好序的子节点,然后获取当前的节点名称,再通过 driver.getsTheLock判断当前的节点有没有加锁成功,返回一个PredicateResults判断的结果,这里面存的就是否加锁成功的信息。
第一次加锁,那么到这里就加锁成功了。之后就会封装一个LockData对象,放入threadData 的map中。
加锁的流程如下图:
上文加锁的时候提到了,当第一次加锁成功之后,会往threadData放入该加锁的线程对应的LockData。
LockData主要封装了当前线程、加锁的次数、加锁的节点。
此时如果第二次来加锁,那么就会从threadData中获取到加锁的信息,然后将加锁次数加1,就代表了加锁成功,然后直接返回。
所以可重入加锁的实现很简单,就是在客户端中判断有没有加过锁,加过的话就将加锁次数累加1,压根就跟服务端没有交互。
注意Redisson可重入加锁的实现跟的Curator是不一样的,Redisson的加锁次数是存在Redis的服务端的,而Curator是存在客户端的。
前面加锁的逻辑主要是说了加锁成功的情况,这里就来说一下加锁失败的情况。
继续来看internalLockLoop方法。
前面说过,判断有没有加锁成功,会返回一个PredicateResults,这里面包含了有没有加锁成功的信息,同时如果没有加锁成功,就会返回需要监听的节点,也就是当前创建的节点的前一个节点。
所以没有加锁成功,就会走else的逻辑,对上一个节点加一个监听器 watcher
然后就会调用 wait 方法,进行等待。
当前一个节点被删除了,也就是释放了锁,那么就会回调这个监听器watcher的方法。
所以,这个watcher的作用就是调用notifyAll方法唤醒调用wait方法的线程,这样线程就会继续尝试加锁,因为是在一个while的循环中。
六、如何实现阻塞等待一定时间还未加锁成功就放弃加锁可通过下面这个方法来实现实现阻塞等待一定时间还未加锁成功就放弃加锁。
boolean acquire(long time, TimeUnit unit) throws Exception
这个方法相比不指定等待时间的方法最主要的区别就是加锁失败之后,调用的阻塞的方法不一样。当不指定超时时间就会调用wait()方法,不会传入等待时间,不被唤醒就会一直阻塞;指定超时时间的时候,就会调用wait(long timeout)指定等待的时间,这样如果等待时间一到,线程就会醒过来,然后再次尝试加锁,一旦加锁失败,就会放弃加锁。
释放锁release方法
释放锁其实很简单,就是拿出当前线程对应的LockData,如果没有,就说明当前线程没有加过锁,就会抛出异常,所以Curator就是通过这个判断来防止其它线程释放了自己线程加的锁。
如果加锁了,那么LockData就不会为null,然后将加锁次数递减1,得到newLockCount,代表了剩下的加锁次数。
-
如果newLockCount > 0,说明锁没释放完,有可重入加锁,然后什么事都不干,直接返回了。
-
如果newLockCount < 0,就抛异常,但是一般不会出现。
-
剩下的一种情况就是newLockCount == 0 ,说明锁已经完完全全释放完了,然后通过internals.releaseLock删除加锁的节点。
服务端删除节点之后,就会通知监听该节点的客户端,然后客户端就会回调watcher监听器,唤醒阻塞等待的线程,线程被唤醒后再进行一次判断就能加锁成功。
到这里,就讲完了加锁和释放锁的过程,整个加锁和释放锁的过程就如下图所示。
其实使用临时顺序节点实现的分布式锁就是公平锁。所谓的公平锁就是加锁的顺序跟成功加锁的顺序是一样的。
因为节点的顺序就是被唤醒的顺序,所以也就是加锁的顺序,所以天生就是公平锁。
九、如何实现读写锁读写锁使用如下。
创建节点的时候,节点的内容中会有一个标记来代表当前节点加的是什么类型的锁。
当需要加写锁时,需要判断自己创建的节点是否排在第一位,如果是就能加锁成功,所以一旦前面有节点,不论前面加是读锁还是写锁,那么都是加锁失败,实现了读写互斥和写写互斥。当然写锁和读锁都是可以重入加锁的。
当需要加读锁的时候,会去判断自己创建节点的前面有没有写锁,如果没写锁,那么说明前面加的都是读锁,那么读锁就能加锁成功,读读不互斥,如果前面有写锁,那么就加锁失败(自己加的写锁除外),读写互斥。
十、如何实现批量加锁批量加锁的意思就是同时加几个锁,只有这些锁都算加成功了,才是真正的加锁成功。
Redisson也实现了批量加锁的功能,Redisson的实现通过RedissonMultiLock类实现的,RedissonMultiLock会去遍历需要加的锁,然后每个都加成功之后才算加锁成功。Curator是封装了InterProcessMultiLock类来实现的批量加锁的,那么InterProcessMultiLock如何实现的呢?
使用代码如下。
InterProcessMultiLock的acquire的方法实现。
从这里可以看出,InterProcessMultiLock也是遍历传入的锁,然后每个锁都加锁成功了,InterProcessMultiLock才算加锁成功。
所以从这里可以看出,跟Redisson实现的批量加锁的实现思想上基本是一样的,都是遍历加锁。
十一、ZK分布式锁和Redis分布式锁到底该选谁这是一个比较常见的面试题。
redis分布式锁:
-
优点:性能高,能保证AP,保证其高可用,
-
缺点:正如Redisson的那篇文章所言,主要是如果出现主节点宕机,从节点还未来得及同步主节点的加锁信息,可能会导致重复加锁。虽然Redis官网提供了RedLock算法来解决这个问题,Redisson也实现了,但是RedLock算法其实本身是有一定的争议的,有大佬质疑该算法的可靠性;同时因为需要的机器过多,也会浪费资源,所以RedLock也不推荐使用。
zk分布式锁:
-
优点:zk本身其实就是CP的,能够保证加锁数据的一致性。每个节点的创建都会同时写入leader和follwer节点,半数以上写入成功才返回,如果leader节点挂了之后选举的流程会优先选举zxid(事务Id)最大的节点,就是选数据最全的,又因为半数写入的机制这样就不会导致丢数据
-
缺点:性能没有redis高
所以通过上面的对比可以看出,redis分布式锁和zk分布式锁的侧重点是不同的,这是redis和zk本身的定位决定的,redis分布式锁侧重高性能,zk分布式锁侧重高可靠性。所以一般项目中redis分布式锁和zk分布式锁的选择,是基于业务来决定的。如果你的业务需要保证加锁的可靠性,不能出错,那么zk分布式锁就比较符合你的要求;如果你的业务对于加锁的可靠性没有那么高的要求,那么redis分布式锁是个不错的选择。
最后,希望通过这两篇文章,让大家对于zookeeper分布式锁和redis分布式锁的实现有个更好的认识。如需要Redisson源码剖析的文章,请关注微信公众号 三友的java日记,回复 Redisson 即可。
往期热门文章推荐
-
有关循环依赖和三级缓存的这些问题,你都会么?(面试常问)
-
万字+28张图带你探秘小而美的规则引擎框架LiteFlow
-
7000字+24张图带你彻底弄懂线程池
-
【SpringCloud原理】OpenFeign原来是这么基于Ribbon来实现负载均衡的
-
【SpringCloud原理】Ribbon核心组件以及运行原理源码剖析
-
【SpringCloud原理】OpenFeign之FeignClient动态代理生成原理
扫码或者搜索关注公众号 三友的java日记 ,及时干货不错过,公众号致力于通过画图加上通俗易懂的语言讲解技术,让技术更加容易学习。
 【文章原创作者:武汉网站制作公司 http://www.wh5w.com提供,感恩】
【文章原创作者:武汉网站制作公司 http://www.wh5w.com提供,感恩】