可视化表单建模是低代码/零代码平台的核心功能,业内对该功能有多种叫法:电子表单、表单可视化、表单驱动、表单引擎等,该组件主要由表单设计器、表单解析引擎、表单存储引擎三个部分构成,而表单解析引擎取决于表单存储引擎的技术方案,本文重点介绍表单设计器和表单存储引擎的技术方案选型。
一、表单设计器 1、FormMakingFormMaking基于 Vue 的可视化表单设计器,赋能企业实现低代码开发模式;帮助开发者从传统枯燥的表单代码中解放出来,更多关注业务,快速提高效率,节省研发成本。
FormMaking使用基于 Vue 2.0 的桌面端组件库 Elemnet ,使用广泛,扩展方便。
http://form.making.link/
2、Variant Form
VForm是一款基于Vue 2/Vue 3的低代码表单,支持Element UI、iView两种UI库,定位为前端开发人员提供快速搭建表单、实现表单交互和数据收集的功能。
VForm 3是一款基于Vue 3.x的低代码表单,支持Element PlusUI库,定位为前端开发人员提供快速搭建表单、实现表单交互和数据收集的功能。VForm 3全称为Variant Form 3,寓意为灵活的、动态的、多样化的Vue 3.x低代码表单。VForm 3由表单设计器VFormDesigner和表单渲染器VFormRender两部分构成,VFormDesigner通过拖拽组件方式生成JSON格式的表单对象,VFormRender负责将表单JSON渲染为Vue组件。
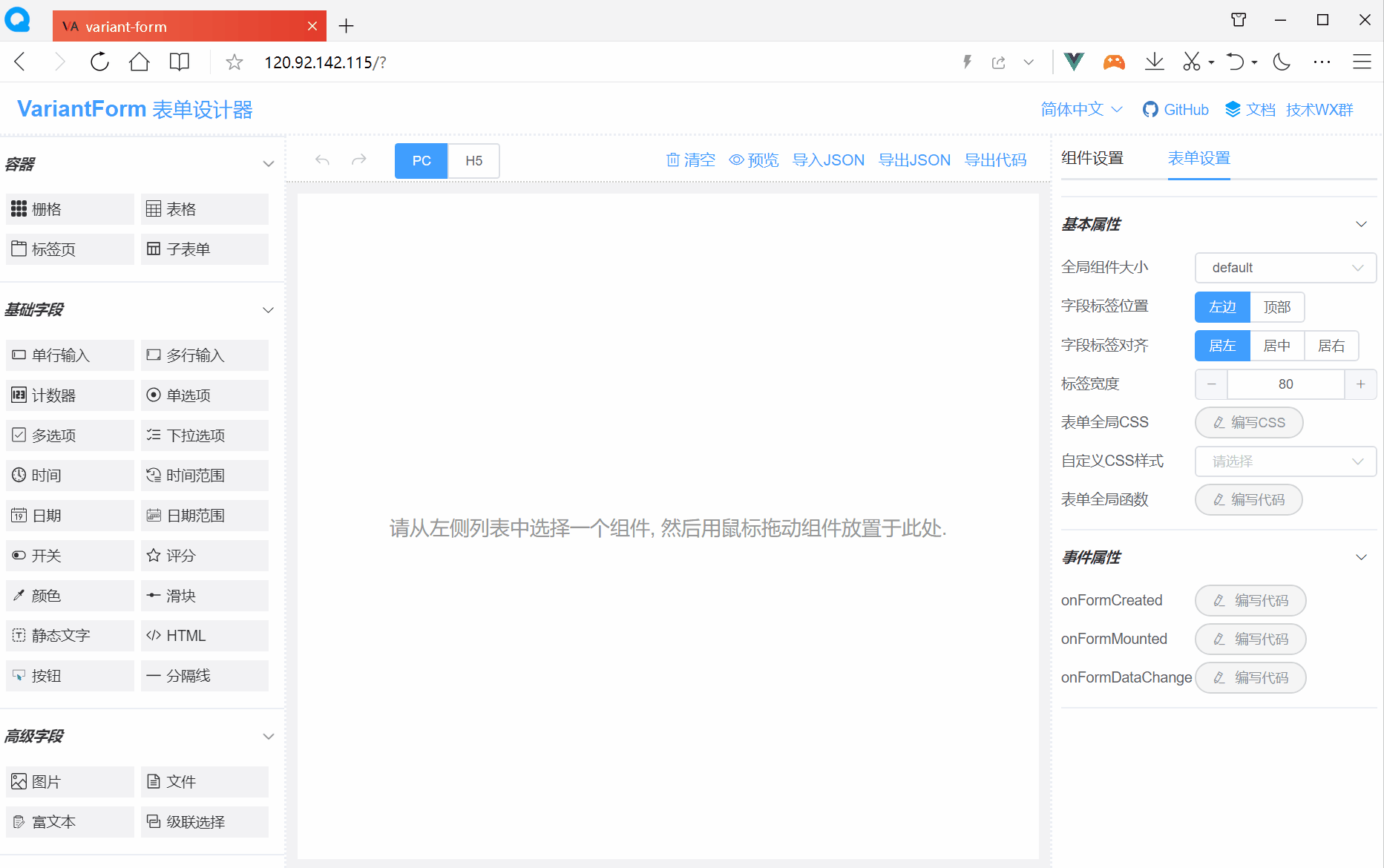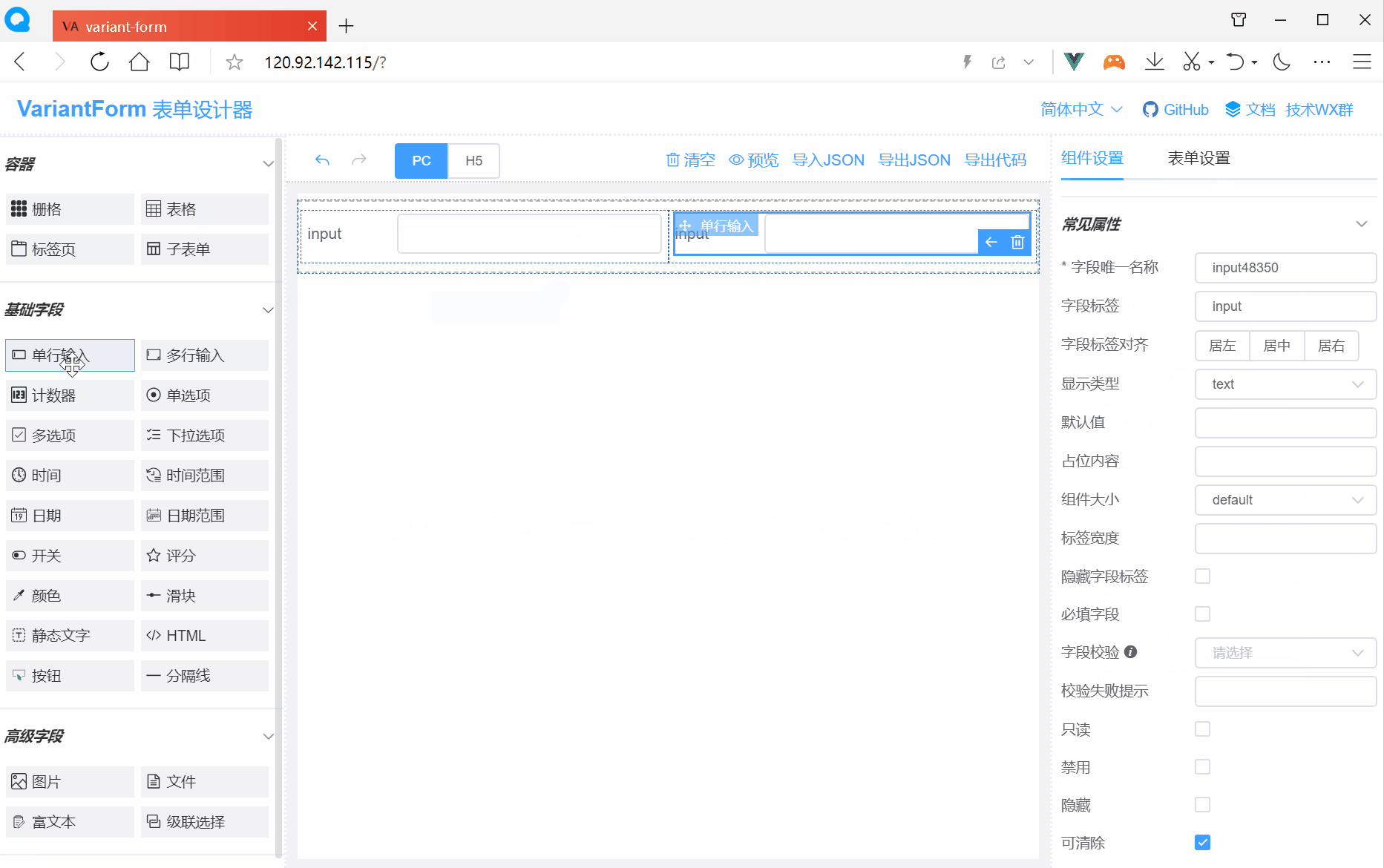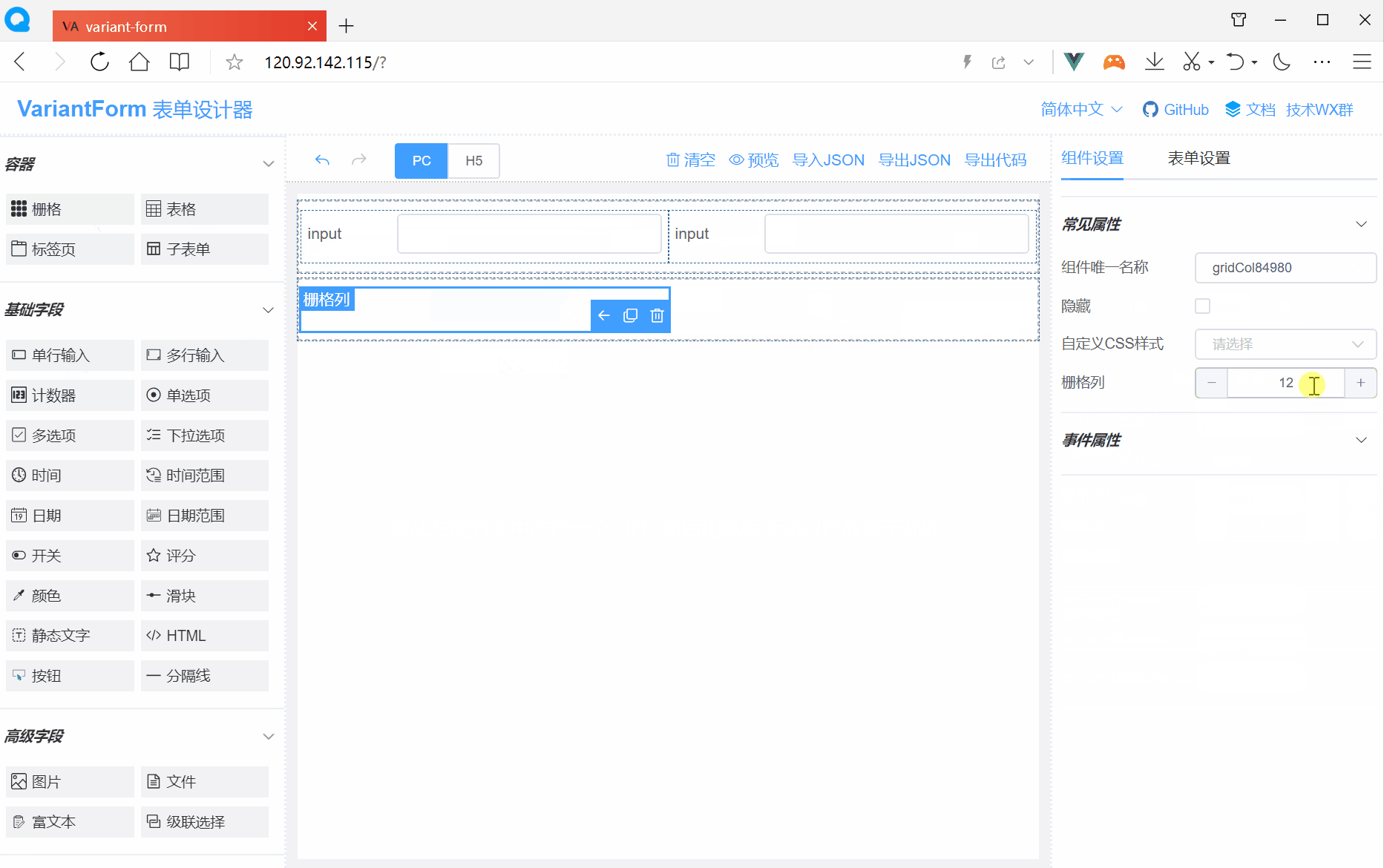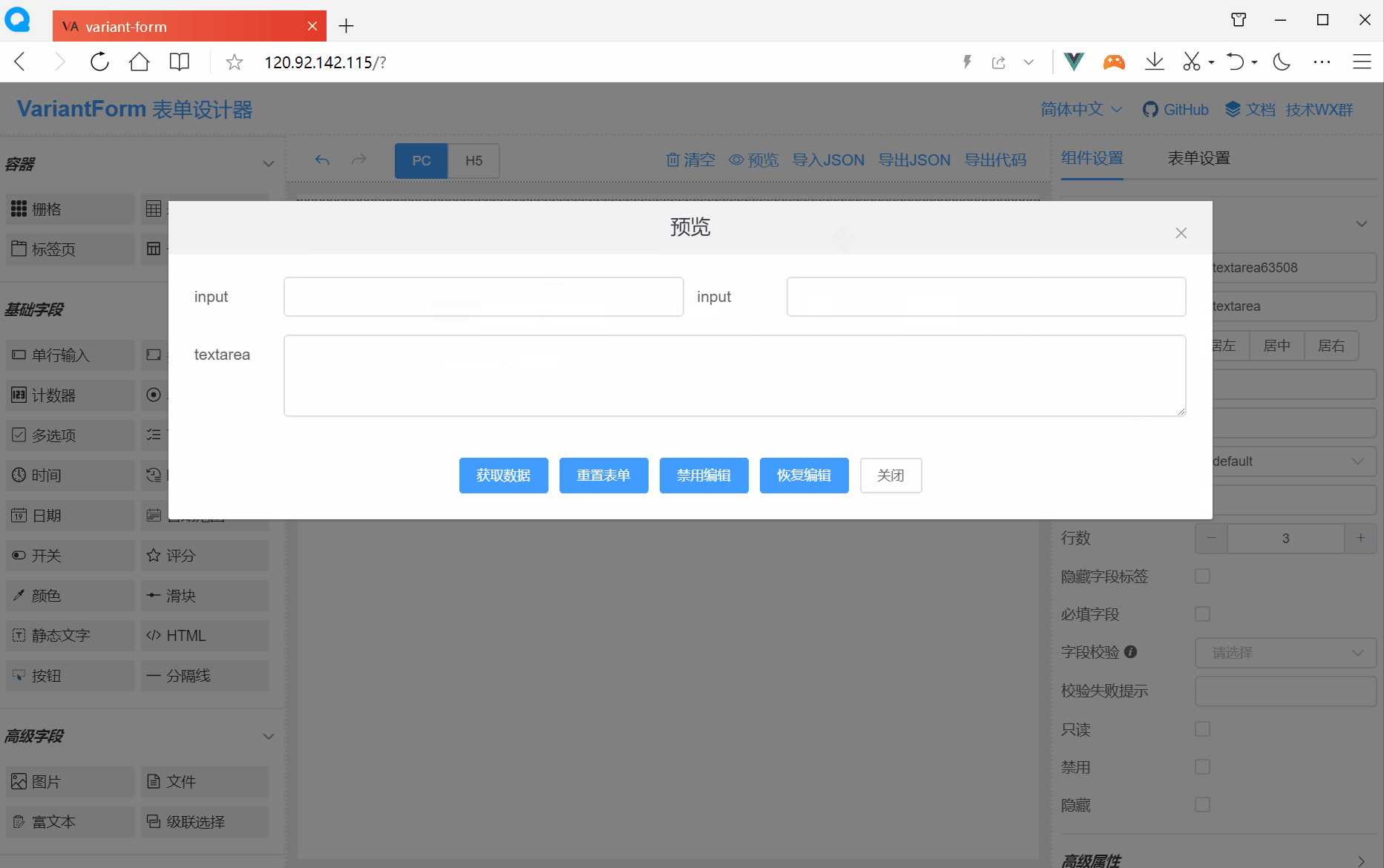
https://www.vform666.com/
3、k-form-design
基于vue2和ant-design-vue实现的表单设计器,样式使用less作为开发语言,主要功能是能通过简单操作来生成配置表单,生成可保存的JSON数据,并能将JSON还原成表单,使表单开发更简单更快速。
4、form-create
form-create 是一个可以通过 JSON 生成具有动态渲染、数据收集、验证和提交功能的表单生成组件。支持3个UI框架(、、),并且支持生成任何 Vue 组件。内置20种常用表单组件和自定义组件,再复杂的表单都可以轻松搞定。
二、表单存储引擎
低代码平台需要支持用户存储自定义数据,因为每个应用所需的表、字段、以及关系都是不一样的。自定义数据存储是后端低代码最重要的功能,使用什么方案将直接影响这个产品的适用范围,目前我们已知有4种方案,每种都有自己的优缺点。
方案 1:直接使用关系型数据库这个方案的原理是将数据模型的可视化操作转成数据库 DDL,比如添加了一个字段,系统会自动生成表结构变更语句:
ALTER TABLE 'blog' ADD 'title' varchar(255) NULL;
这个方案的优点是:
- 可满足企业级复杂应用系统需求,比如:ERP、MES、MOM等,这类业务系统对数据有强一致性、强约束的要求。
- 所有方案里唯一支持直连外部数据库,可以对接已有系统,利用企业现有IT资产,历史数据好迁移。
- 性能高和灵活性强,因为可以使用高级 SQL,也方便与BI、报表、数据可视化系统对接。
- 开发人员容易理解,因为和专业开发是一样的,让开发人员更容易上手。
该方案的缺点是:
- 需要账号有创建用户及 DDL权限,如果有安全漏洞会造成严重后果,有些公司内部线上帐号没有这个权限,导致无法实现自动化变更。
- 实现成本较高,需要实现表单引擎动态实体功能,要支持不同数据库的各种方言,比如oracle、mysql、达梦DB等。
- DDL 执行时会影响线上性能,比如 MySQL 5.6 之前的版本在一个大数据量的表中添加索引字段会,执行DDL时尽量避开业务高峰期操作。
- 部分数据库不支持 DDL 事务,比如 MySQL 8 之前的版本,导致一旦在执行过程中出错将无法恢复。
尽管这个方案有缺点,这些缺点通过一些机制或管理手段可以规避,重要的是该方案的优点很突出,因此国内大部分低代码平台选择了这个方案,因为能支持企业级复杂应用需求、继承现有数据资产是非常重要的。
方案 2:使用文档型数据库
文档型数据库不需要预先定义表结构,因此它很适合用来存储用户自定义数据,这个方案实现起来比较简单,以 MongoDB 为例,可以这样做:
- 用户创建一个自定义表的时候,系统就自动创建一个 collection,所有这个表的数据都存在这个 collection 里。
- 用户新增字段的时候,就随机分配一个 fileId,后续对这个字段的操作都自动映射到这个 fileId 上,用 fileId 的好处是用户重命名字段后还能查找之前的数据,因为所有数据查询底层都基于这个 fileId。
- 查询的时候先找到对应的 collection,再通过 meta 信息查询字段对应的 fileId,使用这个 fileId 来获取数据。
这个方案的优点是实现简单,用户体验可以做得更好,是目前大部分零代码平台的选择,使用这个方案的产品也很好识别,只要看一下它的私有部署文档,如果有要求装 MongoDB 就肯定是。明道云低代码平台就是基于MongoDB的实现方案。
这个方案有显著缺点:
- 难以满足企业级复杂业务系统需求,在国内还没有听说哪个企业的PDM、ERP、MES等系统是基于MongoDB实现的。
- 无法支持外部数据库,数据是孤岛,外部数据接入只能通过导入的方式。
- MongoDB 在国内发展缓慢,接受度依然很低。
- 2018年10月,MongoDB宣布其开源许可证将从GNU AGPLv3,切换到SSPL,AGPL和SSPL是一种非常不友好的开源协议,对其生态发展造成影响,不满足国内部分企业自主可控要求,同时存在法律风险。
- 不支持高级 SQL 查询,难以满足ERP类业务OLTP复杂强事务SQL操作。
它的最大特点是界面编辑和数据存储是统一的,当你拖入文本框到页面后就会自动创建对应的字段,不需要先创建数据模型再创建界面,因此用起来更简单。
方案 3:使用关系型数据库行转列
这是很多可扩展平台里使用的技术,比较典型的是 WordPress,它的扩展性很强,装个扩展就能变成电商网站。而整个 WordPress 只有 个表,它是怎么做到的?方法是靠各种 meta 表,比如用于扩展文章的 wp_postmeta 表结构如下:
CREATE TABLE wp_postmeta (
meta_id bigint(20) unsigned NOT NULL auto_increment,
post_id bigint(20) unsigned NOT NULL default '0',
meta_key varchar(255) default NULL,
meta_value longtext,
PRIMARY KEY (meta_id),
KEY post_id (post_id),
KEY meta_key (meta_key)
) DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
其中的关键就是 meta_key 和 meta_value 这两个字段,相当于将数据库当 KV 存储用了,因此可以任意扩展字段名及值。
这个方案的优点是实现简单,但缺点也很明显:
- 查询性能低,如果有 10 个字段就要查 10 行。
- 无法支持 SQL 高级查询,因为数据是按行存的。
这个方案主要用于成熟项目的扩展,比如在 CRM 产品中允许用户扩展字段,但因为性能较低,并不适合通用低代码平台。
方案 4:使用关系数据库宽表
早期数据库不支持 JSON 字段的时候,有些开发者会预留几个列来给用户扩展自定义属性,比如在表里加上 ext1、ext2、ext3 字段,让用户可以存 3 个定制数据,基于这个原理我们可以进一步扩展,通过预留大量列来实现应用自定义存储。
这个方案最早出现在 ,具体细节可以阅读它技术文档:https://developer.salesforce.com/wiki/multi_tenant_architecture。
实现它有两个关键点:元数据、预留列,这里简单说明一下原理,首先系统预先创建一个 500 列的表,比如就叫 data:

也可以创建更多,但注意有的数据库对列的数量有限制,比如 MySQL 最多是 列。
上面的 data 表里主要有 4 类字段:
- tenant_id 是租户 id,用于隔离不同租户
- table_id 是自定义表的 id
- uuid 是具体这一行数据的 id
- 后面的 value0 到 value500 都是预留的列,用于存储实际数据,一般使用变长字符串类型。当用户给这个表新增一个字段的时候,怎么知道这个字段放哪?这就需要另一个用于描述字段信息的元数据表,比如增加一个「标题」字段时,使用另一个 table_fields 表来描述这个字段的信息,示例如下:

在这个 table_fields 表里:
- tenant_id 和 table_id 和前面一样。
- field_id 对应的是给这个「标题」字段分配的 id。
- value_index 对应前面那个 data 表里预览列的位置,比如这个值是 0,就意味着 value0 列被分配给了这个「标题」字段。
- name 用来存名称,type 用来标识类型,这样查询和写入数据的时候,首先从这里查询 value_index 是什么,然后再去前面那个预留列的表中查询对应列的值。
要完全实现这个方案还有很多细节问题得解决,由于篇幅原因这里不详细介绍,感兴趣可以阅读前面提到的 技术白皮书,这里列举其中几个问题:
- 因为存储只能是字符串,所以对于日期、数字等其他类型,因此读取的时候需要根据类型使用数据库里的函数进行转换,比如 STR_TO_DATE。
- 需要单独处理唯一性功能,因为这个数据表是所有租户共用的,没法设置表级别的唯一性索引,这时就需要新建一个表来单独做,坏处是数据多份容易产生不一致,需要在所有更新操作都加事务。
- 需要单独处理索引功能,同样是因为字段是字符串,因此没法直接在 data 表里加索引,如果数据存储的是数字,排序就是错的,为了解决这个问题需要另外创建一个一个包含常见字段的索引表,数据更新的时候。
- 自增字段需要自己实现。
- 元数据信息需要缓存,不然每次查询前都需要先查询元数据信息,然后再去查询真正的数据。
这个方案比前面几个方案的优点是:
- 比起第一种原生数据库表方案,它不需要 DDL 操作,不容易出问题,更适合 SaaS 产品。
- 比起第二种文档型数据库方案,它的存储使用更为成熟的关系型数据库,相关的运维工具多。
- 比起第三种行代替列方案,它的查询性能好,因为是读取一行数据。
但它也有许多缺点:
- 无法支持 SQL 所有功能,这类产品虽然在用传统数据库,也支持使用 SQL,但这个 SQL 有很大的限制,不能直接使用SQL管理工具进行数据操作管理,也很难满足企业级复杂业务系统需求。
- 数据泄露风险高,因为所有租户的数据都存在一张表里,而数据库都不支持行级别权限的账号,所以意味着所有租户其实共享一个数据库账号,只要有某个功能的查询漏了加租户过滤就能查到所有租户数据。相比之下前面提到的原生表及文档型数据库方案都能直接使用数据库自带的账号进行有效隔离。
- 整体实现成本高,其中很多细节需要处理好,比如保证数据一致性,因为为了实现唯一性、索引等功能需要拷贝数据,更新的时候要同时更新。
我认为这个方案适合某些业务领域SaaS 类产品,可适用的业务领域不多,不具备通用性,我不看好这个方案在国内的发展。Salesforce 的成功不单单是技术,跟当时的所处的IT环境、行业选择、产品定位、商务推广等多个方面都有关系。
专注云原生、低代码、流程引擎研发和应用。免费体验环境:http://www.yunchengxc.com