pd.read_csv("../data/user_info.csv", index_col="name") #假设csv里包含这几列: name, age, birth, sex data="name,age,birth,sex\nTom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male" print(data) pd.read_csv(StringIO(data))#从 StringIO 对象
data="name,age,birth,sex\nTom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male"
print(data)
pd.read_csv(StringIO(data))#从 StringIO 对象中读取。
data = "name|age|birth|sex~Tom|18.0|2000-02-10|~Bob|30.0|1988-10-17|male"
pd.read_csv(StringIO(data), sep="|", lineterminator="~") #自定义字段之间的分隔符
pd.read_csv(StringIO(data), sep="|", lineterminator="~", dtype={"age": int}) # 自己指定数据类型
data="Tom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male"
pd.read_csv(StringIO(data), names=["name", "age", "birth", "sex"]) csv文件并没有标题,我们可以设置参数 names 来添加标题。
pd.read_csv(StringIO(data), usecols=["name", "age"]) # 只读取部分列
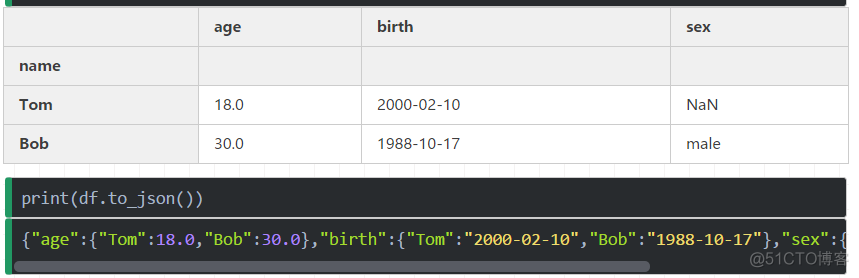
print(user_info.to_json()) #将dataframe转成json字符串
格式类型
数据描述
Reader
Writer
text
CSV
read_csv
to_csv
text
JSON
read_json
to_json
text
HTML
read_html
to_html
text
clipboard
read_clipboard
to_clipboard
binary
Excel
read_excel
to_excel
binary
HDF5
read_hdf
to_hdf
binary
Feather
read_feather
to_feather
binary
Msgpack
read_msgpack
to_msgpack
binary
Stata
read_stata
to_stata
binary
SAS
read_sas
binary
Python Pickle
read_pickle
to_pickle
SQL
SQL
read_sql
to_sql
SQL
Google Big Query
read_gbq
to_gbq
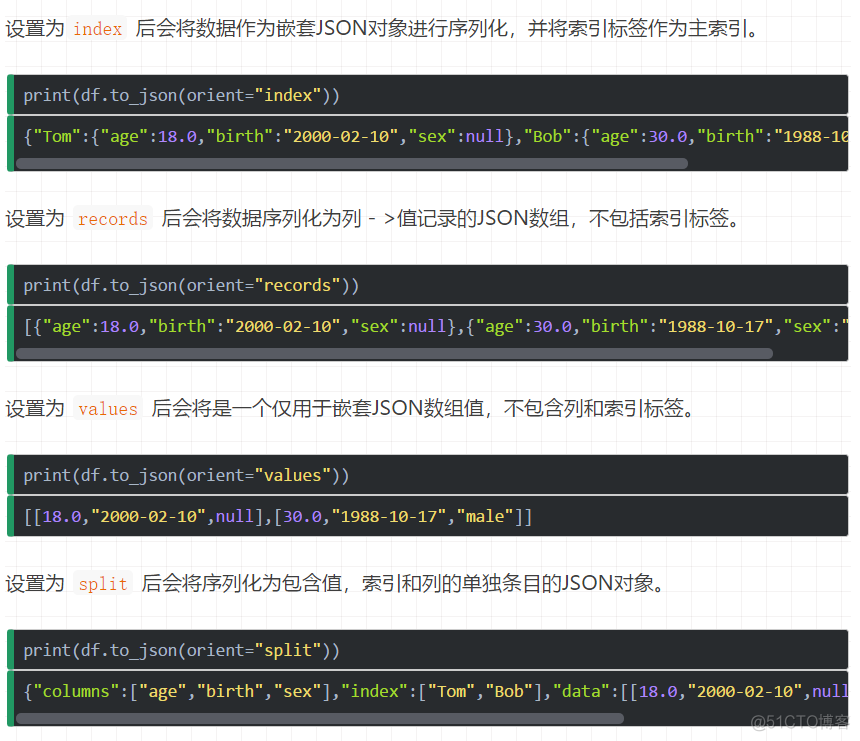
to_json
split
字典像索引 - > [索引],列 - > [列],数据 - > [值]}
records
列表像{[列 - >值},…,{列 - >值}]
index
字典像{索引 - > {列 - >值}}
columns
字典像{列 - > {索引 - >值}}
values
只是值数组
【文章转自迪拜服务器 http://www.558idc.com/dibai.html处的文章,转载请说明出处】