目录:
- pdfminer简介
- pdfparser
简介
back to top to the end
pdfparser使用介绍
1 from pdfminer.pdfparser import PDFParser, PDFDocumentpdfparser是一个pdf解析器,里面封装了PDFParser, PDFDocument这两个我们常用的类。PDFParser从文件流中获取PDF对象;它可以通过引用set_document方法设置的PDF文档来处理间接引用;它还可读取每个PDF文件的交叉引用(xref),一般可以快速定位。由于PDF文件可能很大,通常不会立即加载。因此,PDF文档必须与PDF解析器协作,以便在处理过程中动态导入数据。
1 fp = open(path, 'rb') # 以二进制读模式打开2 praser = PDFParser(fp)
fp为文件流,这里我们使用open打开,产生一个二进制文件。parser是PDFParser的实例,fp为必传参数。parser可以使用的形式有:
Typical usage:parser = PDFParser(fp)
parser.read_xref()
parser.set_document(doc)
parser.seek(offset)
parser.nextobject()
实例化之后的分析器:
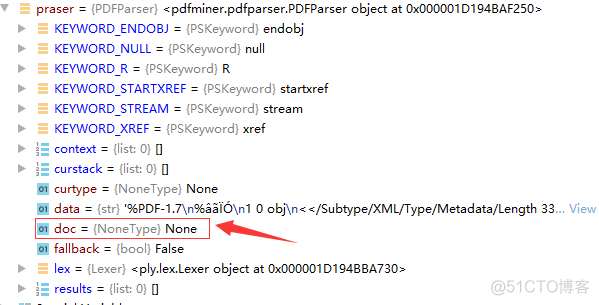
1 # 创建一个PDF文档
2 doc = PDFDocument()
doc是PDFDocument的实例化对象,现在的doc像一张白纸,类默认封装很多方法,其中部分是内部方法,供类内调用,我们可以使用的典型方法有:
Typical usage:doc = PDFDocument()
doc.set_parser(parser)
doc.initialize(password)
obj = doc.getobj(objid)1 # 连接分析器 与文档对象
2 praser.set_document(doc)
3 doc.set_parser(praser)
将doc赋给praser,就像给一只钢笔配上了笔记本,单向传参是肯定不行的,因为doc本身封装了很多方法,其本身是需要用到praser这只笔的,所以要把praser传给doc。(praser不是拼写错误,而是在代码中进行区分)
相互传参绑定之后,两个对象都发生了相应的变化,以parser为例:
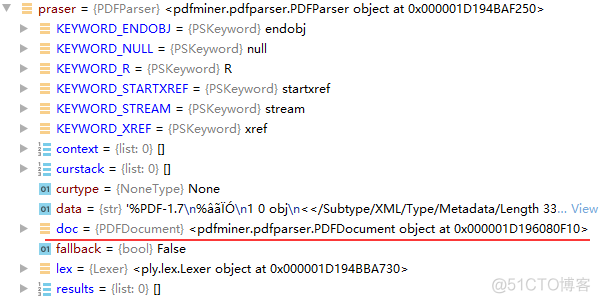
注意doc上边有一个data的字符串,我们可以发现字符串:%PDF-1.7\n ,这个意思就是当前文本的PDF版本为1.7,PDF文件的具体格式介绍请移步:PDF格式详解。
1 # 文档初始化解密2 # 没有密码 就创建一个空的字符串
3 doc.initialize()
PDF文档很多时候是加密的,为了读取相应内容,需要给电脑赋予权限,这里当然是传入密码了,若文档密码很多,可以实例化一个秘密管理器。
导入:from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
1 if not doc.is_extractable:2 raise PDFTextExtractionNotAllowed
判断是否可以将PDF文件转换成txt,不行就直接忽略,你也可以查看是否可以修改或直接print。因为在文档初始化密码时,我们生成了以下属性:
1 self.is_printable = bool(P & 4)2 self.is_modifiable = bool(P & 8)
3 self.is_extractable = bool(P & 16)
额,一般都不行啊,要是那么简单就好了。
back to top to the end
文档解析
先导入其他依赖
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreterfrom pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
PDFResourceManager:ResourceManager有助于重用共享资源,如字体和图像,这样大型对象就不会被多次分配。主要是procset、cmap、font。
LAParams:封装了常用的参数,用于参数空间的构建。
PDFPageAggregator:整合信息进行返回,类似于扫描器中的commander。LAParams实例化的参数主要是传给它,相当于指定指挥官的权限和能力。
PDFPageInterpreter:用于创建一个PDF解释器对象,里面封装了很多方法,可以根据需要进行查找。它就相当于那个扫描器。
rsrcmgr = PDFResourceManager() # 创建资源管理器,负责资源调度,有益于资源共享。laparams = LAParams() # 实例化默认参数空间
device = PDFPageAggregator(rsrcmgr, laparams=laparams) # 创建设备
interpreter = PDFPageInterpreter(rsrcmgr, device) # 创建解释器
逐页分析
我们可以通过doc.get_pages()获取一个生成器,生成器对应了PDF每一页的数据源与解析器等配置。
1 interpreter.process_page(pages.__next__())将某页的实例传入进行分析,如何返回?找设备的大脑,device是专门负责相应工作的。
1 # 接受该页面的LTPage对象2 layout = device.get_result()
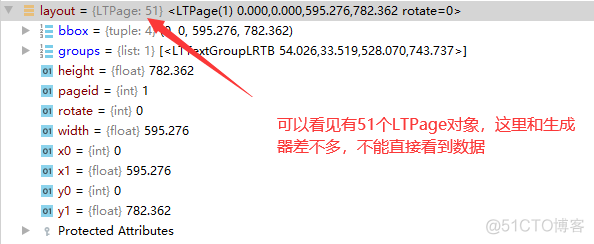
layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox、 LTFigure、
数据提取:
1 for x in layout:2 if isinstance(x, LTTextBoxHorizontal):
3 # 需要写出编码格式
4 # 解决\u8457\u5f55\u683c\u5f0f\uff1a\u67cf\u6167乱码
5 results = x.get_text().encode('raw_unicode_escape').decode('unicode_escape')
6 print('**res:**\n' + results + '-'*20) # 不同实例对象LTPage的分割
输出结果,以Page1为例:

清澈的爱,只为中国