一、参数化讲解
1.unittest和pytest参数化对比:
pytest与unittest的一个重要区别就是参数化,unittest框架使用的第三方库ddt来参数化的
而pytest框架:
- 前置/后置处理函数fixture,它有个参数params专门与request结合使用来传递参数,也可以用parametrize结合request来传参
- 针对测试方法参数化就直接使用装饰器@pytest.mark.parametrize来对测试用例进行传参。
2.参数化目的:
- 参数化,就是把测试过程中的数据提取出来,通过参数传递不同的数据来驱动用例运行。其实也就是数据驱动的概念
- 当测试用例只有测试数据和期望结果不一样,但操作步骤是一样的时,可以用参数化提高代码复用性,减少代码冗余


# 三个用例都是加法然后断言某个值,重复写三个类似的用例有点冗余
def test_1():
assert 3 + 5 == 9
def test_2():
assert 2 + 4 == 6
def test_3():
assert 6 * 9 == 42
# 参数化优化之后的代码
@pytest.mark.parametrize("test_input, expected", [("3+5", 8), ("2+4", 6), ("6*9", 42)])
def test_eval(test_input, expected):
print(f"测试数据{test_input},期望结果{expected}")
assert eval(test_input) == expected
if __name__ == '__main__':
pytest.main()
参数化举例
3.参数化实际应用举例
Web UI自动化中的开发场景,比如是一个登录框:
二、pytest针对测试用例的参数化 @pytest.mark.parametrize
@pytest.mark.parametrize(argnames, argvalues, indirect=False, ids=None, scope=None)- argnames:参数名称,字符串格式,多个参数用逗号隔开,如:"arg1,arg2,arg3"
- argvalues:参数值,需要与argnames对应,元组或列表,如:[ val1,val2,val3 ],如果有多个参数例,元组列表一个元组对应一组参数的值,如:@pytest.mark.parametrize("name,pwd", [("yy1", "123"), ("yy2", "123"), ("yy3", "123")])
- indirect:默认为False,代表传入的是参数。如果设置成True,则把传进来的参数当函数执行,而不是一个参数,详见xxoo
- ids:自定义测试id,字符串列表,ids的长度需要与测试数据列表的长度一致,标识每一个测试用例,自定义测试数据结果的显示,为了增加可读性
1.单个参数
@pytest.mark.parametrize() 装饰器接收两个参数,一个参数是以字符串的形式标识用例函数的参数,第二个参数以列表或元组的形式传递测试数据
import pytest# 待测函数
def add(a, b):
return a + b
# 单个参数的情况
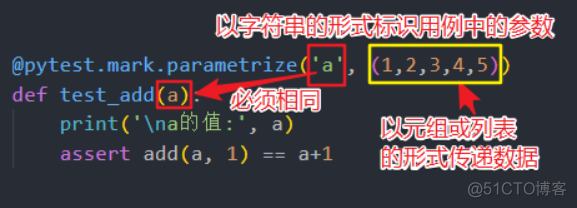
@pytest.mark.parametrize('a', (1,2,3,4,5))
def test_add(a): # => 作为用例参数,接收装饰器传入的数据
print('\na的值:', a)
assert add(a, 1) == a+1
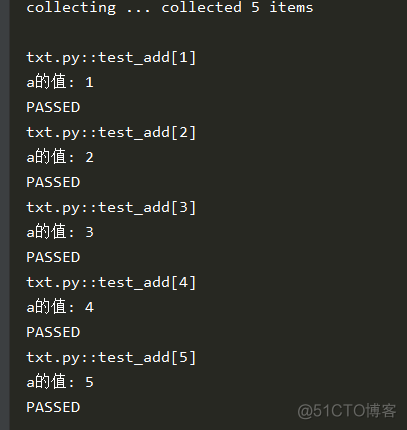
结果:
2.多个参数
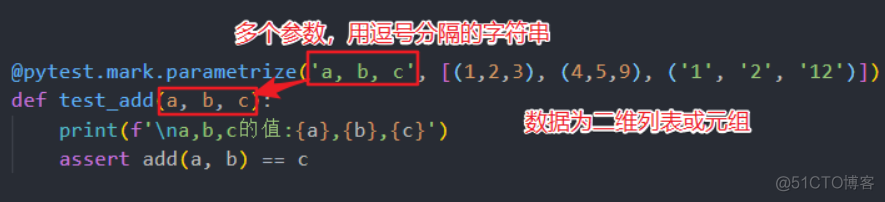
多个参数,@pytest.mark.parametrize()第一个参数依然是字符串, 对应用例的多个参数,用逗号分隔
# 多个参数的情况@pytest.mark.parametrize('a, b, c', [(1,2,3), (4,5,9), ('1', '2', '12')])
def test_add(a, b, c):
print(f'\na,b,c的值:{a},{b},{c}')
assert add(a, b) == c
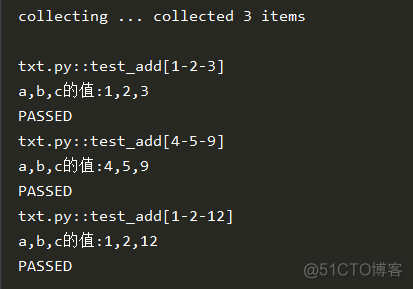
结果:
3.整个测试类参数化
测试类的参数化,其实际上也是对类中的测试方法进行参数化。
类中的测试方法的参数必须与@pytest.mark.parametrize()中的标识的参数个数一致
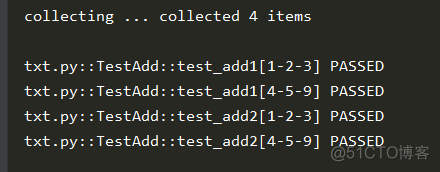
参数化测试类会作用于每个测试方法,比如下面两个用例,参数化了两条数据,那么就会执行 4 次
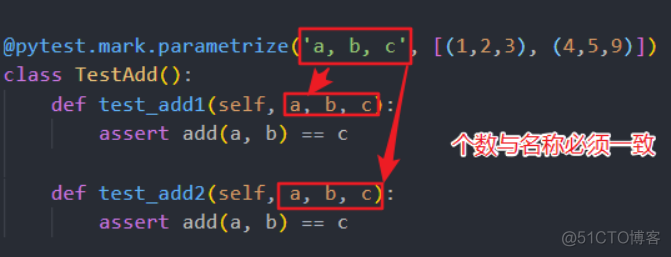
# 测试类参数化@pytest.mark.parametrize('a, b, c', [(1,2,3), (4,5,9)])
class TestAdd():
def test_add1(self, a, b, c):
assert add(a, b) == c
def test_add2(self, a, b, c):
assert add(a, b) == c
结果:
4.多个参数化叠加相乘
在实际测试中,有的场景多条件查询,比如登录有2个条件,名字有两种密码有四种情况,如果要全部覆盖,则是2*4==8种情况。
这种情景,人工测试一般是不会全部覆盖的,但在自动化测试中,只要你想,就可以做到。如下示例:
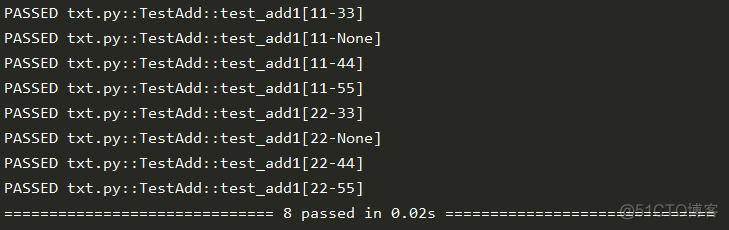
import pytestclass TestAdd():
@pytest.mark.parametrize('pwd', [33,None,44, 55])
@pytest.mark.parametrize('name', [11, 22,])
def test_add1(self, name, pwd):
print(f'name:{name} pwd:{pwd}')
结果:
5.ids 自定义测试id
通过上面的运行结果,我们可以看到,为了区分参数化的运行结果,在结果中都会显示数据组合而成的名称。
测试结果会自动生成测试id,自动生成的id短小还好说,如果数据比较长而复杂的话,那么就会很难看。
@pytest.mark.parametrize() 提供了 ids 参数来自定义显示结果,就是为了好看易读
ids的长度需要与测试数据列表的长度一致
和fixture的ids参数一样的,可以参考fixture的ids
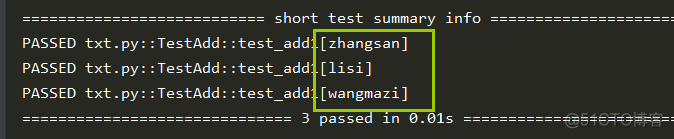
import pytestclass TestAdd():
@pytest.mark.parametrize('name,pwd', [(10,11),(20,21),(30,31)],ids=(['zhangsan','lisi','wangmazi']))
def test_add1(self, name, pwd):
print(f'name:{name} pwd:{pwd}')
结果:
三、indirect=True parametrize与request结合使用给fixture传参
fixture自身的params参数可以结合request来传参,详见fixture的其他参数介绍章节,当然也可以用parametrize来参数化代替params
indirect=True参数,目的是把传入的ss_data当做函数去执行,而不是参数
如果测试方法写在类中,则@pytest.mark.parametrize的参数名称要与@pytest.fixture函数名称保持一致
应用场景:
- 为了提高复用性,我们在写测试用例的时候,会用到不同的fixture,比如:最常见的登录操作,大部分的用例的前置条件都是登录
- 假设不同的用例想登录不同的测试账号,那么登录fixture就不能把账号写死,需要通过传参的方式来完成登录操作
1.单个参数
import pytestseq = [1, 2, 3]
@pytest.fixture()
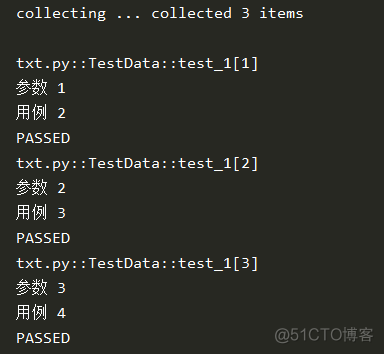
def ss_data(request):
print("\n参数 %s" % request.param)
return request.param + 1
class TestData:
@pytest.mark.parametrize("ss_data", seq, indirect=True)
def test_1(self, ss_data):
print("用例", ss_data)
结果:
2.多个参数
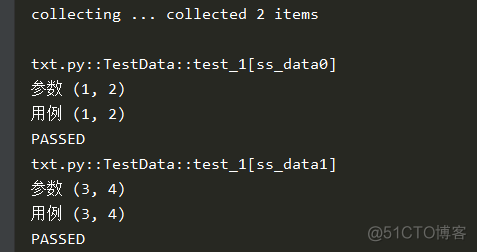
@pytest.fixture()def ss_data(request):
print(f"\n参数 {request.param}")
return request.param
class TestData:
# @pytest.mark.parametrize("ss_data", seq) # 用这个你会发现fixture根本不会执行,因为默认把ss_data当成简单参数执行了而不是函数
@pytest.mark.parametrize("ss_data", seq, indirect=True)
def test_1(self, ss_data):
print("用例", ss_data)
结果:
3.多个fixture和多个parametrize叠加
import pytestseq1 = [1, 2, 3]
seq2 = [4, 5, 6]
@pytest.fixture()
def get_seq1(request):
seq1 = request.param
print("seq1:", seq1)
return seq1
@pytest.fixture()
def get_seq2(request):
seq2 = request.param
print("seq2:", seq2)
return seq2
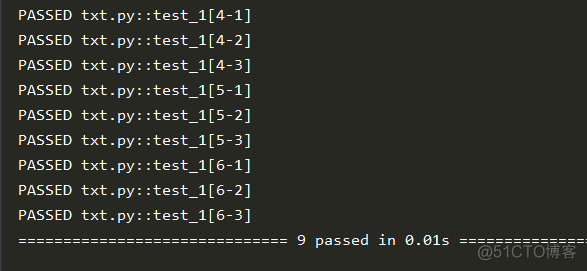
@pytest.mark.parametrize("get_seq1", seq1, indirect=True)
@pytest.mark.parametrize("get_seq2", seq2, indirect=True)
def test_1(get_seq1, get_seq2):
print(get_seq1, 11)
print(get_seq2, 22)
结果:
参考:
全栈测试开发日记
小菠萝