1.python爬虫介绍 2.准备工作 比如新建项目命名为douban,然后新建个spider.py的python 文件 写入: def main(a): print("hello",a) main(2) if __name__=="__main__": #当程序执行时 #调用函数 main(1) 输出如下:
1.python爬虫介绍
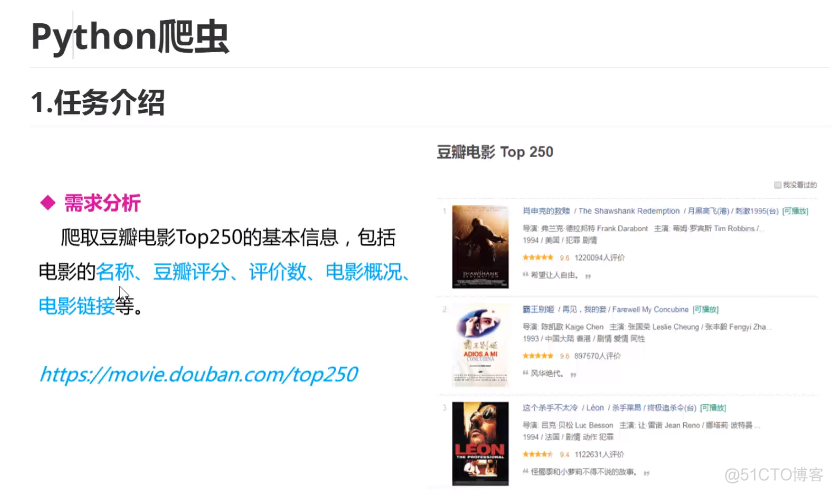

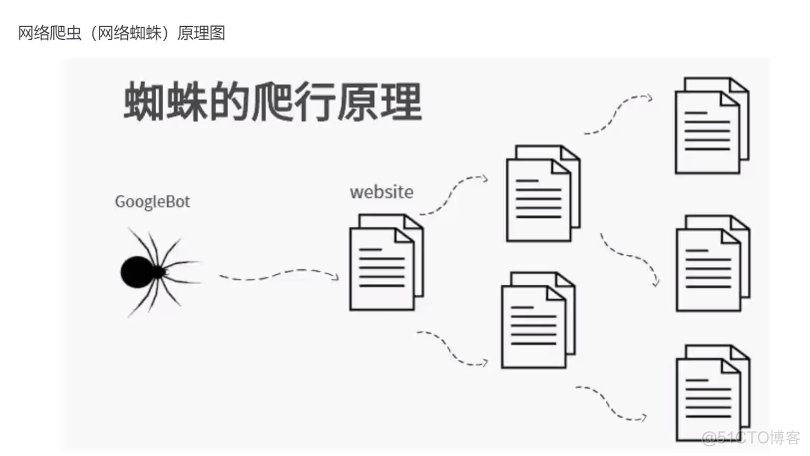
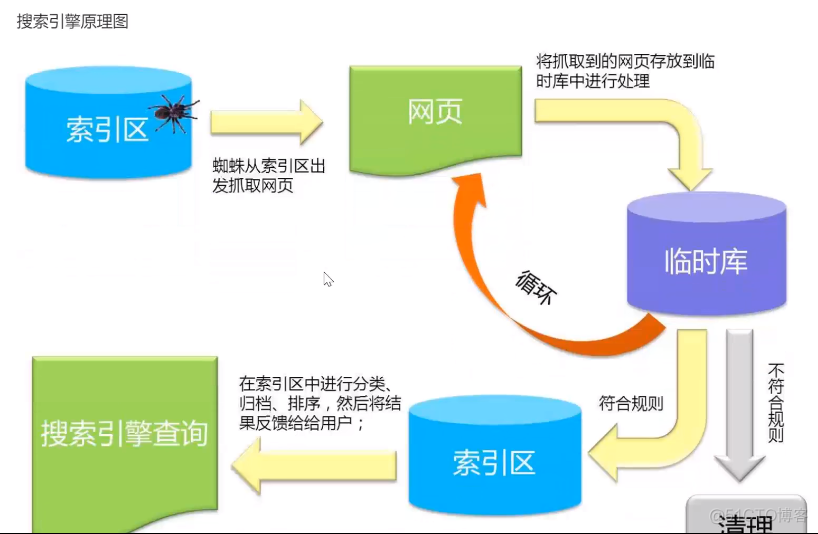

2.准备工作
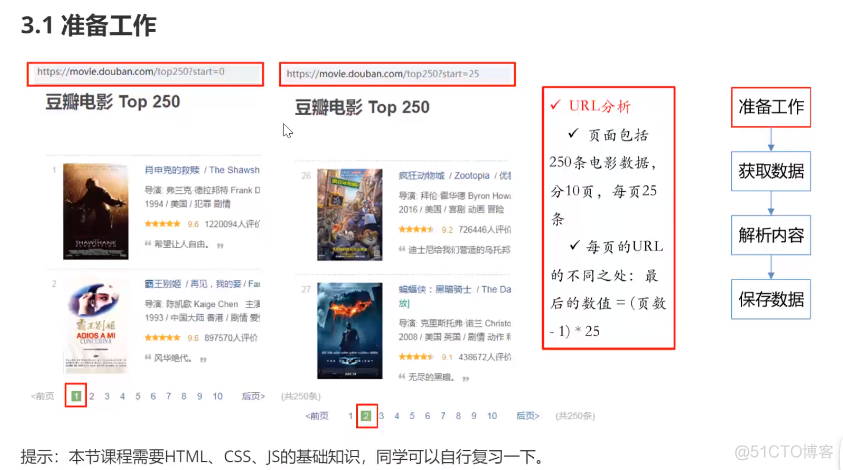

比如新建项目命名为douban,然后新建个spider.py的python 文件
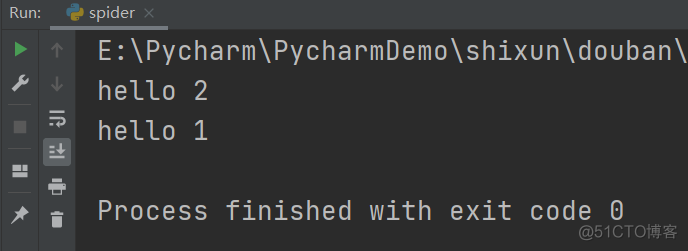
写入:
def main(a):print("hello",a)
main(2)
if __name__=="__main__": #当程序执行时
#调用函数
main(1)
输出如下:

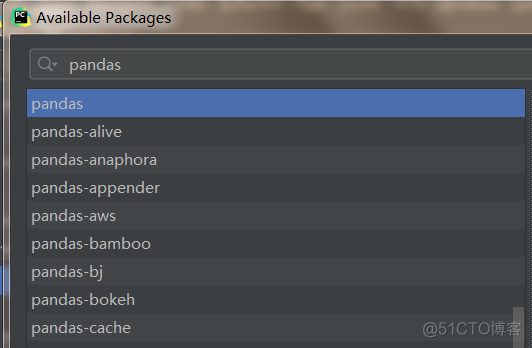
File->Settings->Project:你的项目名(这里是douban )->Python:Interpreter
点击下面+号,搜索栏搜索即可:比如要安装pandas,再点击下面的Install Package即可。
3.构建流程
接着在上述文件中继续写入以下代码:


# @Time : 2020/12/16 0016 下午 7:09
# @Author :东南大学软件学院陈洋
# @File :spider.py
# @Software :PyCharm
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行sqlite数据库操作
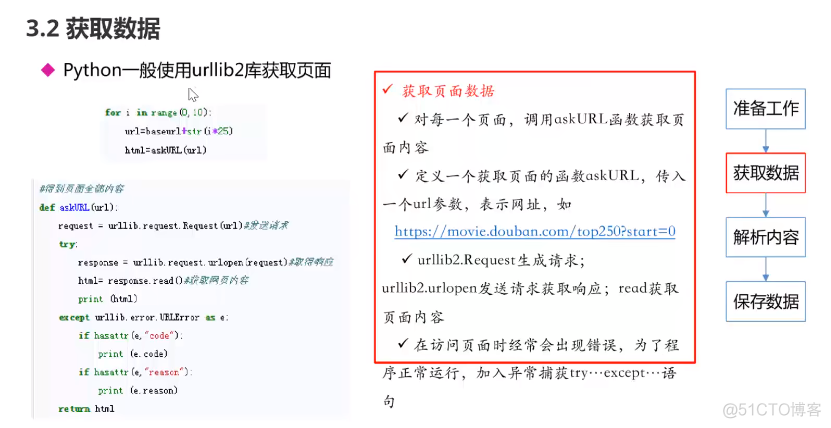
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls"
#3.保存数据
saveData(savepath)
#爬取网页
def getData(baseurl):
datalist=[]
# 2.逐一解析数据
return datalist
#3.保存数据
def saveData(savepath):
print("save....")
if __name__=="__main__": #当程序执行时
#调用函数
main()
View Code
4.补充urllib(这里只是为了测试,源码参考以下视频)
注意:headers一定要包含浏览器一些头部信息才行
更多内容见视频讲解:
https://www.bilibili.com/video/BV12E411A7ZQ?p=18