前阵子网上看到有人写爬取妹子图的派森代码,于是乎我也想写一个教程,很多教程都是调用的第三方模块,今天就使用原生库来爬,并且扩展实现了图片鉴定,图片去重等操作,经过了爬站验证,稳如老狗,我已经爬了几万张了,只要你硬盘够大。
前端,被一个 img标签包起来 <img src="https://mtl.gzhuibei.com/images/img/10431/5.jpg" alt= 直接正则匹配
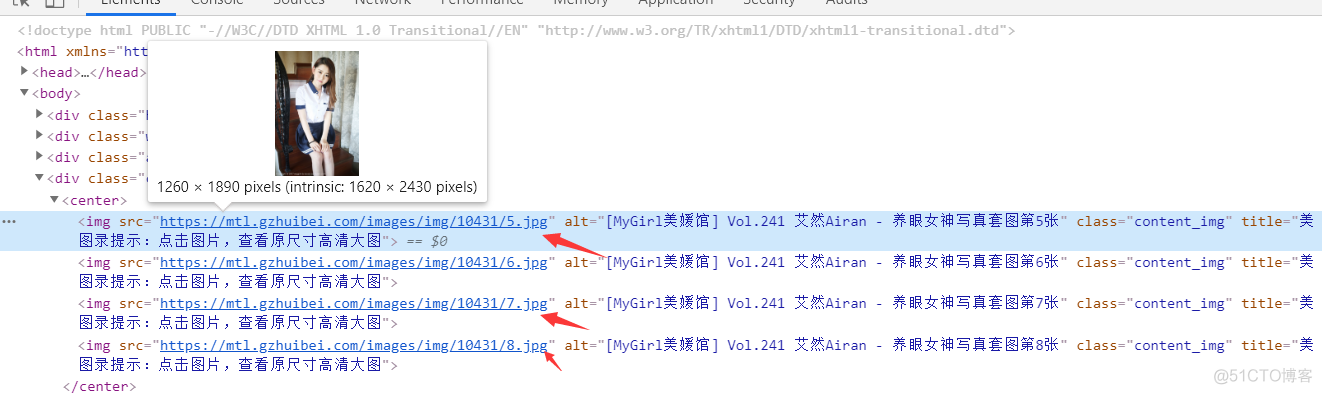
先来生成页面链接,代码如下
# 传入参数,对页面进行拼接并返回列表def SplicingPage(page,start,end):
url = []
for each in range(start,end):
temporary = page.format(each)
url.append(temporary)
return url
接着使用内置库爬行
# 通过内置库,获取到页面的URL源代码def GetPageURL(page):
head = GetUserAgent(page)
req = request.Request(url=page,headers=head,method="GET")
respon = request.urlopen(req,timeout=3)
if respon.status == 200:
html = respon.read().decode("utf-8")
return html
最后正则匹配爬取,完事了。代码自己研究一下就明白了,太简单了,
page_list = SplicingPage(str(args.url),2,100)for item in page_list:
respon = GetPageURL(str(item))
subject = re.findall('<img src="([^"]+\.jpg)"',respon,re.S)
for each in subject:
img_name = each.split("/")[-1]
img_type = each.split("/")[-1].split(".")[1]
save_name = str(random.randint(1111111,99999999)) + "." + img_type
print("[+] 原始名称: {} 保存为: {} 路径: {}".format(img_name,save_name,each))
urllib.request.urlretrieve(each,save_name,None)
也可以通过外部库提取。
from lxml import etreehtml = etree.HTML(response.content.decode())
src_list = html.xpath('//ul[@id="pins"]/li/a/img/@data-original')
alt_list = html.xpath('//ul[@id="pins"]/li/a/img/@alt')
一些请求头信息,用于绕过反爬虫策略
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25"

运行结果,就是这样,同学们,都把裤子给我穿上!好好学习!

接着我们来扩展一个知识点,如何使用Python实现自动鉴别图片,鉴别黄色图片的思路是,讲图片中的每一个位读入内存然后将皮肤颜色填充为白色,将衣服填充为黑色,计算出整个人物的像素大小,然后计算身体颜色与衣服的比例,如果超出预定义的范围则认为是黄图,这是基本的原理,实现起来需要各种算法的支持,Python有一个库可以实现 pip install Pillow porndetective 鉴别代码如下。
>>> test=PornDetective("c://1.jpg")
>>> test.parse()
c://1.jpg JPEG 1600×2400: result=True message='Porn Pic!!'
<porndetective.PornDetective object at 0x0000021ACBA0EFD0>
>>>
>>> test=PornDetective("c://2.jpg")
>>> test.parse()
c://2.jpg JPEG 1620×2430: result=False message='Total skin percentage lower than 15 (12.51)'
<porndetective.PornDetective object at 0x0000021ACBA5F5E0>
>>> test.result
False
鉴定结果如下,识别率不是很高,其实第一张并不算严格意义上的黄图,你可以使用爬虫爬取所有妹子图,然后通过调用这个库对其进行检测,如果是则保留,不是的直接删除,只保留优质资源。
他这个库使用的算法有一些问题,如果照这样来分析,那肚皮舞之类的都会被鉴别为黄图,而且一般都会使用机器学习识别率更高,这种硬编码的方式一般的还可以,如果更加深入的鉴别根本做不到,是不是黄图,不能只从暴露皮肤方面判断,还要综合考量,姿势,暴露尺度,衣服类型,等各方面,不过这也够用,如果想要在海量图片中筛选出比较优质的资源,你可以这样来写。
from PIL import Imageimport os
from porndetective import PornDetective
if __name__ == "__main__":
img_dic = os.listdir("./meizitu/")
for each in img_dic:
img = Image.open("./meizitu/{}".format(each))
width = img.size[0] # 宽度
height = img.size[1] # 高度
img = img.resize((int(width*0.3), int(height*0.3)), Image.ANTIALIAS)
img.save("image.jpg")
test = PornDetective("./image.jpg")
test.parse()
if test.result == True:
print("{} 图片大赞,自动为你保留.".format(each))
else:
print("----> {} 图片正常,自动清除,节约空间,存着真的是浪费资源老铁".format(each))
os.remove("./meizitu/"+str(each))
妹子图去重,代码如下,这个代码我写了好一阵子,一开始没思路,后来才想到的,其原理是利用CRC32算法,计算图片hash值,比对hash值,并将目录与hash关联,最后定位到目录,只删除多余的图片,保留其中的一张,这里给出思路代码。
import zlib,osdef Find_Repeat_File(file_path,file_type):
Catalogue = os.listdir(file_path)
CatalogueDict = {} # 查询字典,方便后期查询键值对对应参数
for each in Catalogue:
path = (file_path + each)
if os.path.splitext(path)[1] == file_type:
with open(path,"rb") as fp:
crc32 = zlib.crc32(fp.read())
# print("[*] 文件名: {} CRC32校验: {}".format(path,str(crc32)))
CatalogueDict[each] = str(crc32)
CatalogueList = []
for value in CatalogueDict.values():
# 该过程实现提取字典中的crc32特征组合成列表 CatalogueList
CatalogueList.append(value)
CountDict = {}
for each in CatalogueList:
# 该过程用于存储文件特征与特征重复次数,放入 CountDict
CountDict[each] = CatalogueList.count(each)
RepeatFileFeatures = []
for key,value in CountDict.items():
# 循环查找字典中的数据,如果value大于1就存入 RepeatFileFeatures
if value > 1:
print("[-] 文件特征: {} 重复次数: {}".format(key,value))
RepeatFileFeatures.append(key)
for key,value in CatalogueDict.items():
if value == "1926471896":
print("[*] 重复文件所在目录: {}".format(file_path + key))
if __name__ == "__main__":
Find_Repeat_File("D://python/",".jpg")
来来来,小老弟,我们去探讨一下技术,学好技术,每天都开荤
爬虫最终代码:
import os,re,random,urllib,argparsefrom urllib import request,parse
# 随机获取一个请求体
def GetUserAgent(url):
UsrHead = ["Windows; U; Windows NT 6.1; en-us","Windows NT 5.1; x86_64","Ubuntu U; NT 18.04; x86_64",
"Windows NT 10.0; WOW64","X11; Ubuntu i686;","X11; Centos x86_64;","compatible; MSIE 9.0; Windows NT 8.1;",
"X11; Linux i686","Macintosh; U; Intel Mac OS X 10_6_8; en-us","compatible; MSIE 7.0; Windows Server 6.1",
"Macintosh; Intel Mac OS X 10.6.8; U; en","compatible; MSIE 7.0; Windows NT 5.1","iPad; CPU OS 4_3_3;"]
UsrFox = ["Chrome/60.0.3100.0","Auburn Browser","Safari/522.13","Chrome/80.0.1211.0","Firefox/74.0",
"Gecko/20100101 Firefox/4.0.1","Presto/2.8.131 Version/11.11","Mobile/8J2 Safari/6533.18.5",
"Version/4.0 Safari/534.13","wOSBrowser/233.70 Baidu Browser/534.6 TouchPad/1.0","BrowserNG/7.1.18124",
"rident/4.0; SE 2.X MetaSr 1.0;","360SE/80.1","wOSBrowser/233.70","UCWEB7.0.2.37/28/999","Opera/UCWEB7.0.2.37"]
UsrAgent = "Mozilla/5.0 (" + str(random.sample(UsrHead,1)[0]) + ") AppleWebKit/" + str(random.randint(100,1000)) \
+ ".36 (KHTML, like Gecko) " + str(random.sample(UsrFox,1)[0])
UsrRefer = str(url + "/" + "".join(random.sample("abcdef23457sdadw",10)))
UserAgent = {"User-Agent": UsrAgent,"Referer":UsrRefer}
return UserAgent
# 通过内置库,获取到页面的URL源代码
def GetPageURL(page):
head = GetUserAgent(page)
req = request.Request(url=page,headers=head,method="GET")
respon = request.urlopen(req,timeout=3)
if respon.status == 200:
html = respon.read().decode("utf-8") # 或是gbk根据页面属性而定
return html
# 传入参数,对页面进行拼接并返回列表
def SplicingPage(page,start,end):
url = []
for each in range(start,end):
temporary = page.format(each)
url.append(temporary)
return url
if __name__ == "__main__":
urls = "https://www.meitulu.com/item/{}_{}.html".format(str(random.randint(1000,20000)),"{}")
page_list = SplicingPage(urls,2,100)
for item in page_list:
try:
respon = GetPageURL(str(item))
subject = re.findall('<img src="([^"]+\.jpg)"',respon,re.S)
for each in subject:
img_name = each.split("/")[-1]
img_type = each.split("/")[-1].split(".")[1]
save_name = str(random.randint(11111111,999999999)) + "." + img_type
print("[+] 原始名称: {} 保存为: {} 路径: {}".format(img_name,save_name,each))
#urllib.request.urlretrieve(each,save_name,None) # 无请求体的下载图片方式
head = GetUserAgent(str(urls)) # 随机弹出请求头
ret = urllib.request.Request(each,headers=head) # each = 访问图片路径
respons = urllib.request.urlopen(ret,timeout=10) # 打开图片路径
with open(save_name,"wb") as fp:
fp.write(respons.read())
except Exception:
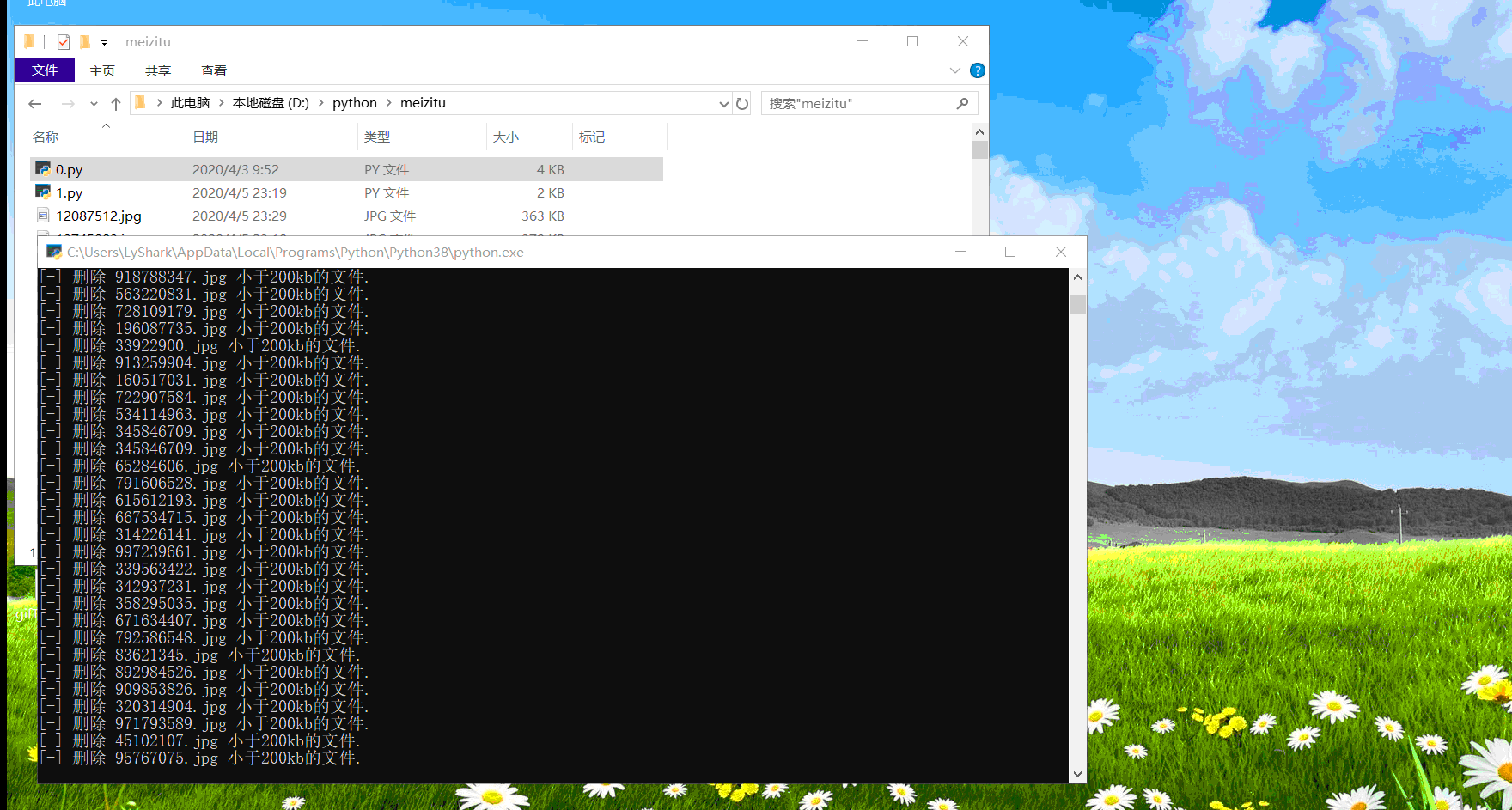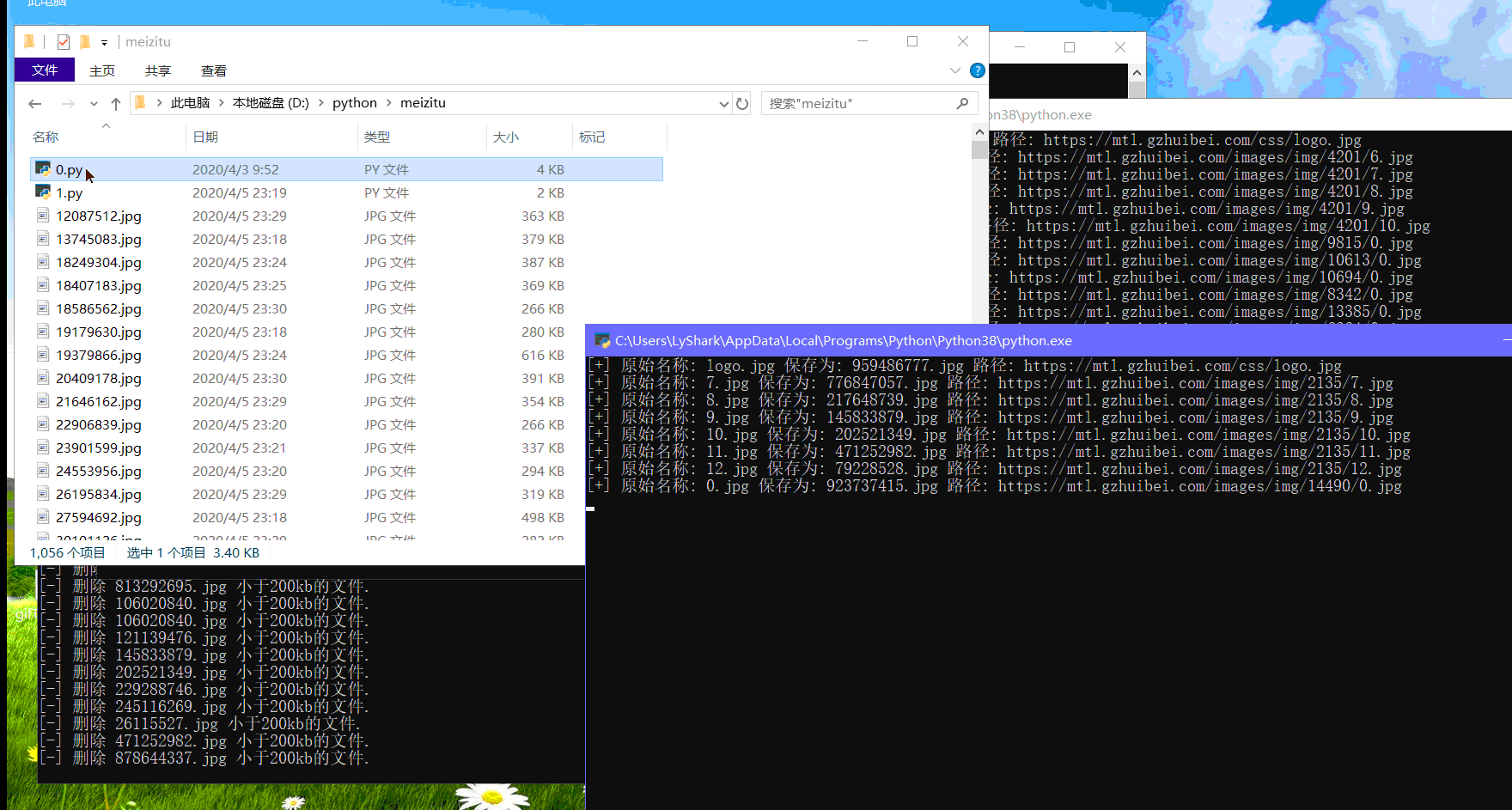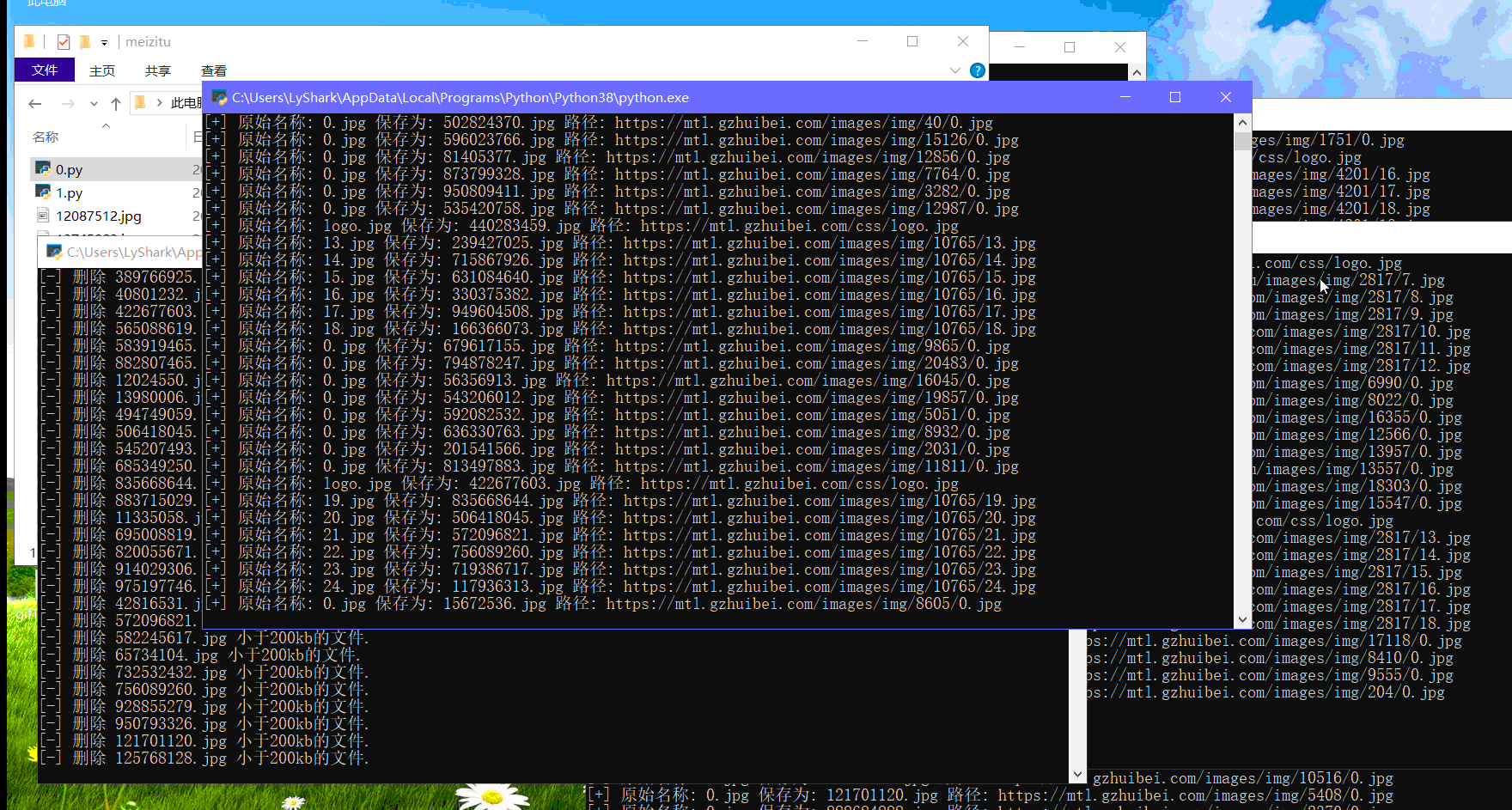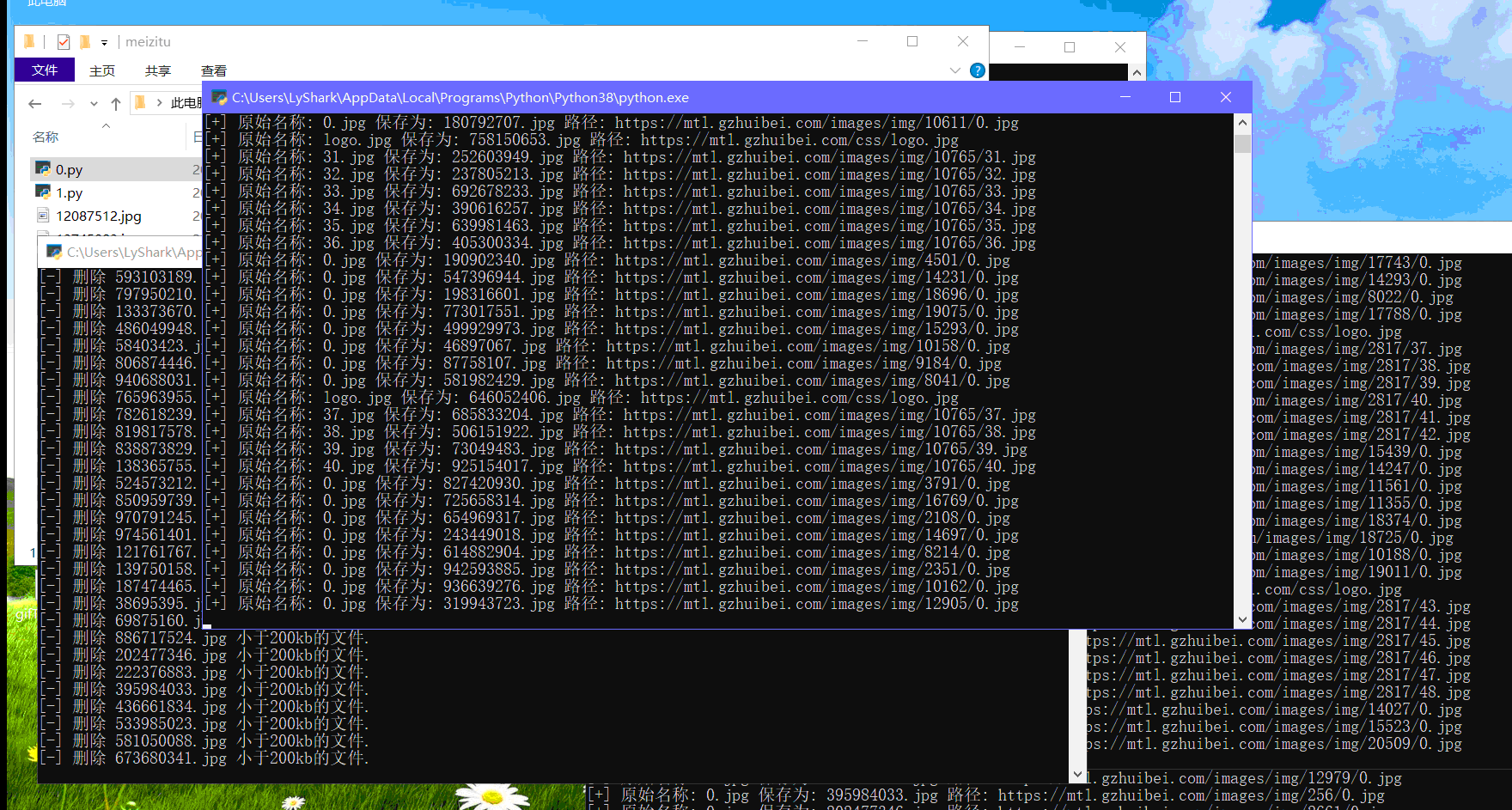
# 删除当前目录下小于100kb的图片
for each in os.listdir():
if each.split(".")[1] == "jpg":
if int(os.stat(each).st_size / 1024) < 100:
print("[-] 自动清除 {} 小于100kb文件.".format(each))
os.remove(each)
exit(1)
最后的效果,高并发下载(代码分工明确:有负责清理重复的,有负责删除小于150kb的,有负责爬行的,包工头非你莫属)今晚通宵
上方代码还有许多需要优化的地方,例如我们是随机爬取,现在我们只想爬取其中的一部分妹子图,所以我们需要改进一下,首先来获取到需要的链接,找首先找所有A标签,提取出页面A标题。
import requests
if __name__ == "__main__":
get_url = []
urls = requests.get("https://www.meitulu.com/t/youhuo/")
soup = BeautifulSoup(urls.text,"html.parser")
soup_ret = soup.select('div[class="boxs"] ul[class="img"] a')
for each in soup_ret:
if str(each["href"]).endswith("html"):
get_url.append(each["href"])
for item in get_url:
for each in range(2,30):
url = item.replace(".html","_{}.html".format(each))
with open("url.log","a+") as fp:
fp.write(url + "\n")
接着直接循环爬取就好,这里并没有多线程,爬行会有点慢的
from bs4 import BeautifulSoupimport requests,random
def GetUserAgent(url):
UsrHead = ["Windows; U; Windows NT 6.1; en-us","Windows NT 5.1; x86_64","Ubuntu U; NT 18.04; x86_64",
"Windows NT 10.0; WOW64","X11; Ubuntu i686;","X11; Centos x86_64;","compatible; MSIE 9.0; Windows NT 8.1;",
"X11; Linux i686","Macintosh; U; Intel Mac OS X 10_6_8; en-us","compatible; MSIE 7.0; Windows Server 6.1",
"Macintosh; Intel Mac OS X 10.6.8; U; en","compatible; MSIE 7.0; Windows NT 5.1","iPad; CPU OS 4_3_3;"]
UsrFox = ["Chrome/60.0.3100.0","Auburn Browser","Safari/522.13","Chrome/80.0.1211.0","Firefox/74.0",
"Gecko/20100101 Firefox/4.0.1","Presto/2.8.131 Version/11.11","Mobile/8J2 Safari/6533.18.5",
"Version/4.0 Safari/534.13","wOSBrowser/233.70 Baidu Browser/534.6 TouchPad/1.0","BrowserNG/7.1.18124",
"rident/4.0; SE 2.X MetaSr 1.0;","360SE/80.1","wOSBrowser/233.70","UCWEB7.0.2.37/28/999","Opera/UCWEB7.0.2.37"]
UsrAgent = "Mozilla/5.0 (" + str(random.sample(UsrHead,1)[0]) + ") AppleWebKit/" + str(random.randint(100,1000)) \
+ ".36 (KHTML, like Gecko) " + str(random.sample(UsrFox,1)[0])
UsrRefer = str(url + "/" + "".join(random.sample("abcdef23457sdadw",10)))
UserAgent = {"User-Agent": UsrAgent,"Referer":UsrRefer}
return UserAgent
url = []
with open("url.log","r") as fp:
files = fp.readlines()
for i in files:
url.append(i.replace("\n",""))
for i in range(0,9999):
aget = GetUserAgent(url[i])
try:
ret = requests.get(url[i],timeout=10,headers=aget)
if ret.status_code == 200:
soup = BeautifulSoup(ret.text,"html.parser")
soup_ret = soup.select('div[class="content"] img')
for x in soup_ret:
try:
down = x["src"]
save_name = str(random.randint(11111111,999999999)) + ".jpg"
print("xiazai -> {}".format(save_name))
img_download = requests.get(url=down, headers=aget, stream=True)
with open(save_name,"wb") as fp:
for chunk in img_download.iter_content(chunk_size=1024):
fp.write(chunk)
except Exception:
pass
except Exception:
pass

咳咳,快!派森扶我起来,我还能学挖掘机技术,未完待续。。。
版权声明:本博客文章与代码均为学习时整理的笔记,文章 [均为原创] 作品,转载请 [添加出处] ,您添加出处是我创作的动力!