三月初来的上海,遇到了疫封城。大家都待在家里,在家待着可以远程办公的还可以,没有远程办公权限的,比如我除了打游戏外也没有其他的事情可以做了。无意中打开了全民k歌发现好友都挺喜欢唱歌的,就没事的点开了几个好友的,朋友们唱的都挺好的,越听越想听。但是每次都得点开别人的主页听歌,难免有些尴尬。“要是可以将这些拉到本地多好啊…………”有了这样的一个念头,说干就干………………
1.分析网页
都知道哈,要想爬取某一个网站的数据,第一步并不是写代码。而是需要通过浏览器、抓包工具啥的对目标网页进行分析,全民k歌也是一样
1.1登陆全民k歌
全民k歌的主页长这个样子 可以看到啥也没有啊,咋办呢?一头雾水,啥也不说了,先打开好友的主页看一下。于是我打开了一个朋友的主页
可以看到啥也没有啊,咋办呢?一头雾水,啥也不说了,先打开好友的主页看一下。于是我打开了一个朋友的主页 可以发现有数据了,此时我们就可以尝试着打开网页的源代码先看一下有没有我们想要的信息数据。
可以发现有数据了,此时我们就可以尝试着打开网页的源代码先看一下有没有我们想要的信息数据。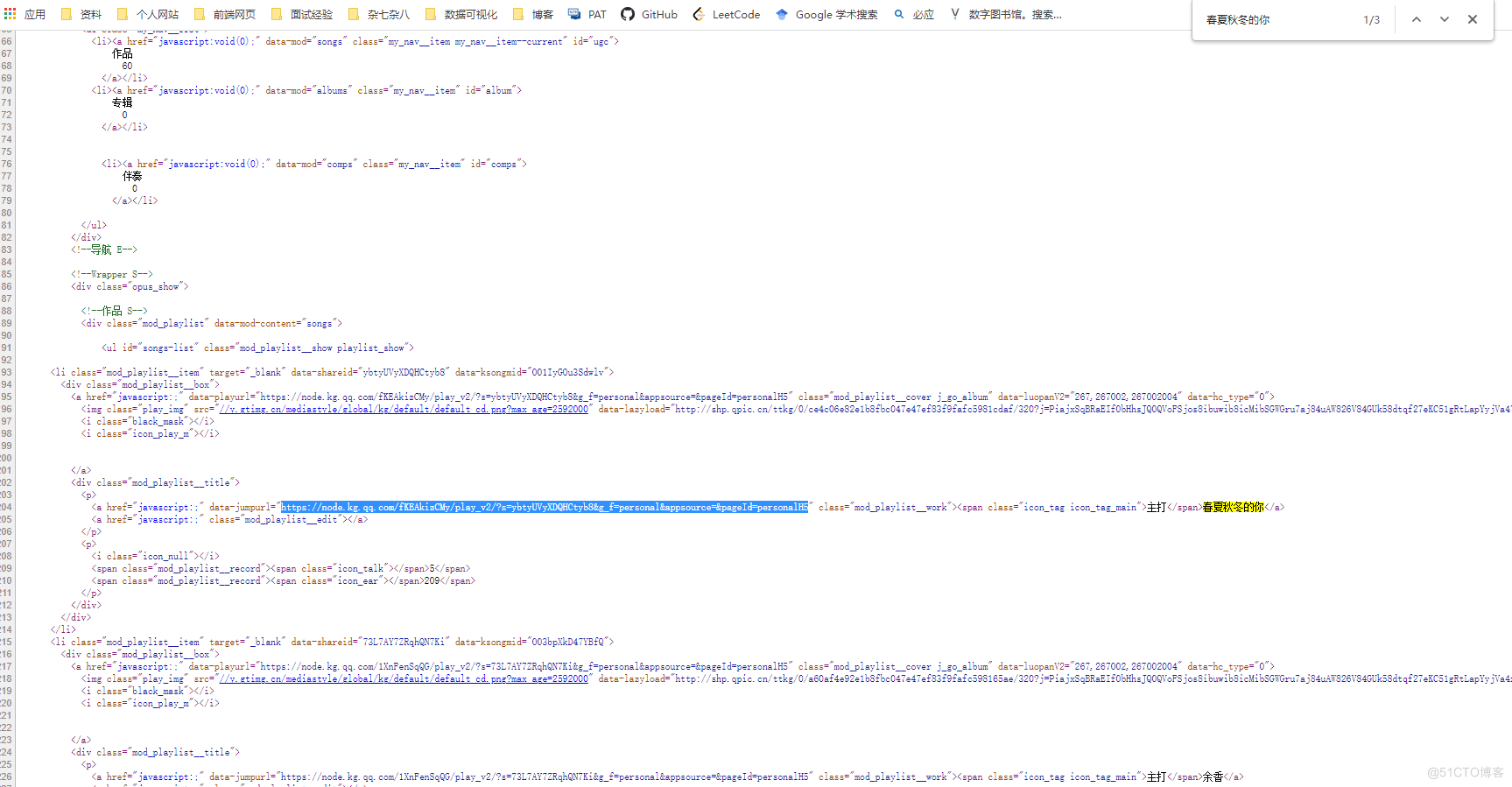 在网页的源代码中搜索一个作品,比如这里搜索“春夏秋冬的你”,可以看到在网页的源代码中有三条数据,还有几条网页的链接,这里我们可以发现data-jumpurl所对应的链接```html/xmlhttps://node.kg.qq.com/fKEAkizCMy/play_v2/?s=ybtyUVyXDQHCtyb8&g_f=personal&appsource=&pageId=personalH5
在网页的源代码中搜索一个作品,比如这里搜索“春夏秋冬的你”,可以看到在网页的源代码中有三条数据,还有几条网页的链接,这里我们可以发现data-jumpurl所对应的链接```html/xmlhttps://node.kg.qq.com/fKEAkizCMy/play_v2/?s=ybtyUVyXDQHCtyb8&g_f=personal&appsource=&pageId=personalH5
第二个好友的主页信息为:```html/xmlhttps://kg.qq.com/node/personal?uid=609c9c862228378937&shareUid=63999f802d378e&chain_share_id=UCvDIkYj1zIWyNZCq9KMG4HPVp6p1IoFyhjNVtdC9Yw&pageId=homepage_guest
我们可以看到,实际上这两个链接的差别就再uid和shareid上,所以我们可以大胆的试,将第二个好友的主页链接的uid换成第一个好友的uid看一下,发现是可以访问到第一个好友的主页的  所以这里就可以断定访问哪一个主页是通过uid来控制的。 #### 2.2歌曲信息的url 在上面的查看网页源代码的过程中,我们可以发现,具体到哪一首歌的链接是嵌入在网页的源代码中的,但是在主页上所展示的信息并不是完整的,仅仅是展示了一小部分而已。 这里怎么办呢,怎样才能够让主页的信息展示的更加的全面呢? 这里的话,我在手机上输入对应得链接就是可以看到完整得歌曲数据得,对于电脑的浏览器要怎样才可以像手机一样的,这里我采用的是将浏览器源代码的检查界面的格式设置为手机的样式  这样的话往下滑就可以看到又数据加载进来了 这里我们应该就可以意识到了,其实这里的页面的音乐数据是通过动态加载的方式进行的。所以,这里我们需要将浏览器切换到network上面,可以看到这里有很多信息,我们打开一个看一下  打开一看,就是我们需要找的那些歌曲名字以及链接  所以说这个链接我们是需要拿下来的, ```html/xml https://node.kg.qq.com/fcgi-bin/kg_ugc_get_homepage?outCharset=utf-8&from=1&nocache=1652856459444&format=json&type=get_uinfo&start=2&num=10&share_uid=639f9b862028378b37&g_tk=5381&g_tk_openkey=5381对应的头信息也可以拿下来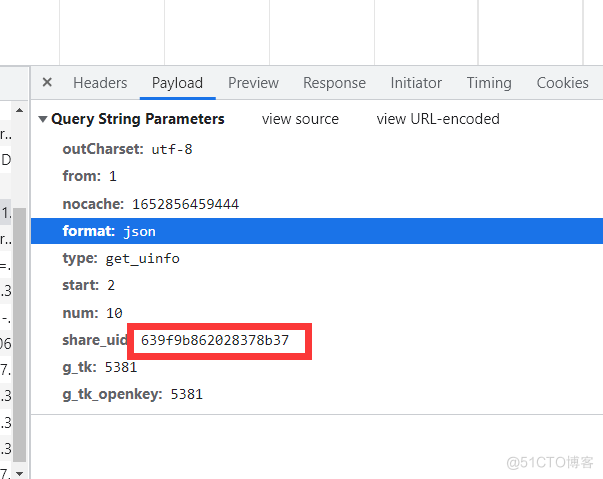 可以看出来,share_id所对应的就是主页的uid同时我们还可以看到,start写的是2,然后我们给它改为1,可以发现就首页的信息,而num呢,是对应得每一次加载数据的数据量。这里的10,也就是说,每一次展示10条数据。其实这里的shareid就是每一个具体歌曲界面的一个唯一标识
可以看出来,share_id所对应的就是主页的uid同时我们还可以看到,start写的是2,然后我们给它改为1,可以发现就首页的信息,而num呢,是对应得每一次加载数据的数据量。这里的10,也就是说,每一次展示10条数据。其实这里的shareid就是每一个具体歌曲界面的一个唯一标识
2.3具体歌曲网页分析
可以看到一首歌的url为:```html/xmlhttps://kg.qq.com/node/NtmjrPr3oI/play_v2/?s=ybtyUVyXDQHCtyb8&g_f=personal&appsource=&pageId=personalH5
s后面刚好是每一首歌的shareid,到这里思路就很清晰了, ## 3.整理思路,编写代码 #### 3.1思路整理 第一步我们需要通过,主页信息获取到好友的uid,再通过uid拼接到下图的shareid下面,就可以获取到好友的歌曲数据信息了  我们可以通过request请求网页  可以看到,歌曲的信息都再网页中,所以我们需要写正则进行匹配,匹配到歌曲的shareid和title即可。 歌曲的shareid是用来进行拼接具体每一首的访问网页, 拿到没一首的访问数据之后,我们还需要拼接出获取源文件的链接,这里也需要使用正则匹配出src对应的链接 ```python obj = re.compile(r'<audio.*?src="(?P<link>.*?)">', re.S)之后便可以进行下载了
4.源代码
源代码如下:
import requests import re import os import time from selenium.webdriver import Chrome from selenium.webdriver.chrome.options import Options url="https://node.kg.qq.com/fcgi-bin/kg_ugc_get_homepage?" param={ "outCharset": "utf-8", "from": "1", "nocache": "1652758394305", "format": "json", "type": "get_uinfo", "start": "1", # 起始的页数 "num": "15", # 每一次访问多少的数据 "share_uid": "639e9f8d2629378e3d", # 更换为需要爬取好友的uid就可以了 "g_tk": "5381", "g_tk_openkey": "5381" } # share_uid放的是uid才可以 head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" " AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/100.0.4896.127 Safari/537.36"} username="" # 拿到用户的名字 total=0 # 拿到total用于计算后面需要循环多少次进行拿到歌单 # get请求的数据是params resp=requests.get(url,params=param,headers=head) print(resp.text) # 拿到第start页的数据 obj1=re.compile(r'.*?"nickname": (?P<nickname>.*?),' r'.*?"ugc_total_count": (?P<total>.*?),',re.S) res1=obj1.finditer(resp.text) for it in res1: username=it.group("nickname") print(username) total=int(it.group("total")) print(total) print("用户名为:",username) print("用户作品:",total) # print(type(total)) # print(type(username)) obj2=re.compile(r'.*?"shareid": "(?P<shareid>.*?)".*?"title": "(?P<title>.*?)",',re.S) res2=obj2.findall(resp.text) print(res2) print(res2[0]) # print(len(res2)) # print(res2[0][0]) # 取到shareid # print(res2[0][1]) # 取到title歌曲的名字 resp.close() for i in range(len(res2)): # base_url="https://node.kg.qq.com/play?s=" # print(res2[i][0],res2[i][1]) # 拿到每一首歌的播放界面 url_first=base_url+str(res2[i][0]) # print(url_first) # 创建以下载用户名音乐作品的文件夹 # os.mkdir('SKY') opt = Options() opt.add_argument("--headless") opt.add_argument("--disable-gpu") web = Chrome(options=opt) web.get(url_first) # 拼接好每一首歌的url time.sleep(1) s = web.page_source obj = re.compile(r'<audio.*?src="(?P<link>.*?)">', re.S) result = obj.finditer(s) for it in result: # 打印下载链接 print("第"+str(i+1)+"首歌曲下载链接:"+it.group("link")) download_url = it.group("link") resp = requests.get(download_url) # ('./name/嘉宾.m4a' with open("./test/"+res2[i][1]+".m4a", 'wb') as f: f.write(resp.content) resp.close() # resp.close()5.运行
运行效果如下
 就可以听啦!!!!!笔者能力有限,在表达方面可能有不明确的地方,还请多多包涵!!!
就可以听啦!!!!!笔者能力有限,在表达方面可能有不明确的地方,还请多多包涵!!!